- The paper presents the MLMF framework that decomposes memory into working, episodic, and semantic layers to improve long-term context retention.
- The framework achieves statistically significant gains in Success Rate, F1 scores, and retention percentages on benchmarks like LOCOMO and LOCCO.
- The ablation study shows that removing key components like semantic abstraction and adaptive gating notably degrades performance, underscoring their importance.
Multi-Layered Memory Architectures for LLM Agents: An Experimental Evaluation of Long-Term Context Retention
Architectural Overview of MLMF
The paper proposes a Multi-Layer Memory Framework (MLMF) designed to mitigate semantic drift and memory instability faced by LLM-based agents during long-horizon dialogues. MLMF systematically decomposes memory into three layers: working memory for recent utterances, episodic memory for compact session summaries, and semantic memory for persistent abstractions. Adaptive retrieval gating allows dynamic weighting among these layers based on semantic relevance, while retention regularization controls entity drift across sessions. The framework operates under bounded context constraints, achieving both computational efficiency and context stability.
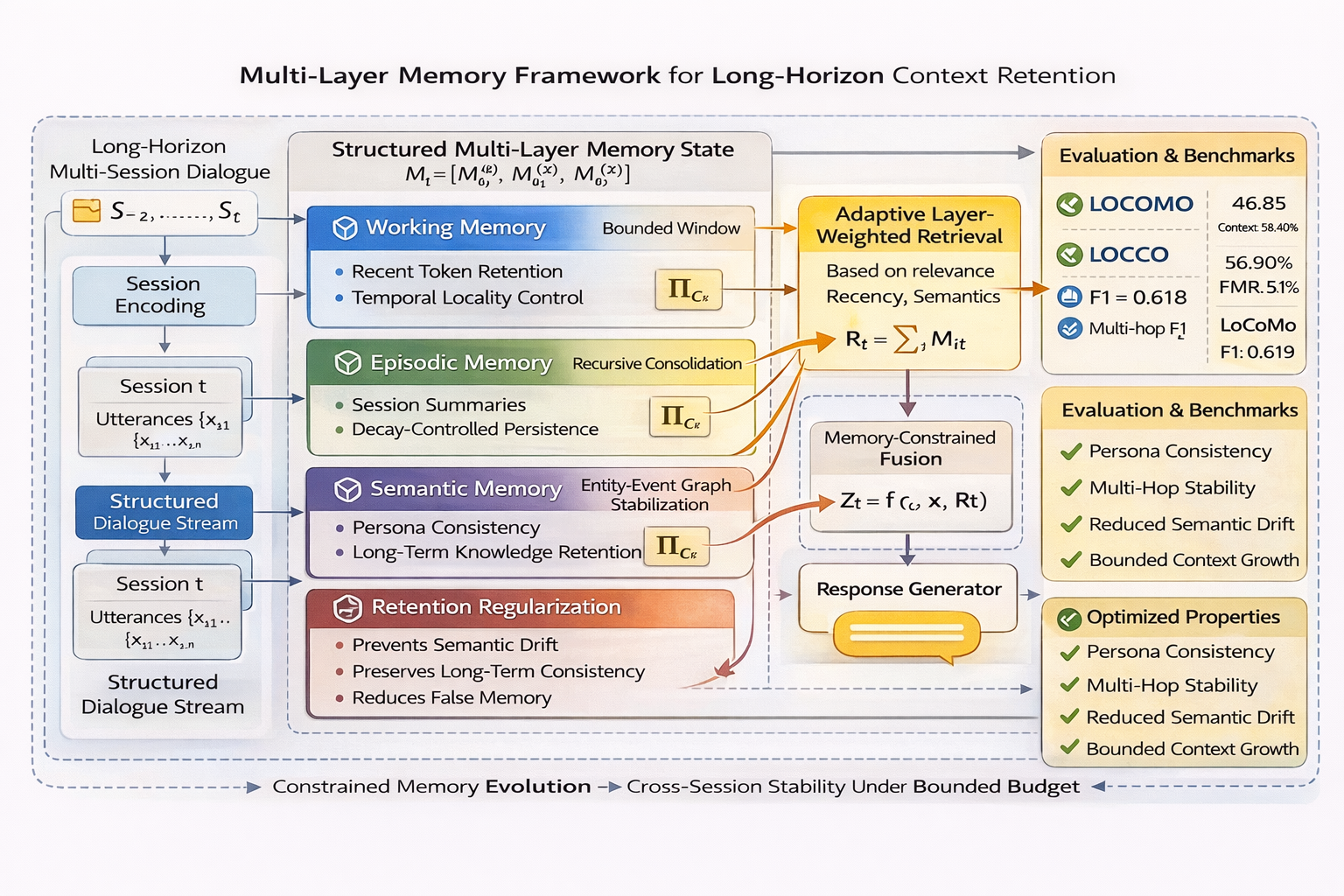
Figure 1: Descriptive overview of the MLMF showing all stages of memory consolidation, retrieval, retention, and response generation.
This architectural decomposition provides layered control over information flow, enabling separation of short-term interaction signals from persistent semantic abstractions. By structuring memory updates and recursive consolidation, MLMF prevents quadratic growth and reduces interference, allowing alignment of entity and persona representations throughout conversational history.
Experimental Setup and Key Results
Three benchmarks—LOCOMO, LOCCO, and LoCoMo—were used, covering extremely long dialogues with hundreds of turns and multi-session progression. MLMF was evaluated on standardized metrics including Success Rate, F1 (overall and multi-hop), BLEU-1, retention rates over temporal periods, false memory rate (FMR), and context utilization percentages.
MLMF outperforms prior hierarchical memory and compression-based frameworks:
- LOCOMO: Success Rate of 46.85 (vs 42.00 [hu2025hiagent]), overall F1 at 0.618, context usage reduced to 58.40%.
- LOCCO: Retention after six periods reaches 56.90% (compared to 48.25% [jia2025evaluating]), FMR reduced to 5.1% (vs 6.8% [phadke2025truth]).
- LoCoMo: Multi-hop F1 achieves 0.594 (vs 0.550 [shahevolve]), BLEU-1 increases to 0.632.
All improvements are statistically significant (p < 0.01), demonstrating superior memory stability and reasoning accuracy under constrained memory budgets.
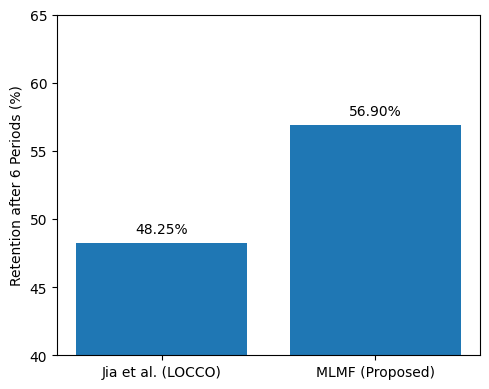
Figure 2: MLMF retains more information after six periods on LOCCO compared to parameter-based memory approaches.
In direct comparison with prior architectures—including hierarchical working memory [hu2025hiagent], multi-tier memory OS [kang2025memory], and retention-based parameter models [jia2025evaluating]—MLMF consistently delivers higher long-session retention, reasoning stability, and reduced context usage. The F1 score increases (across entity tracking and multi-hop reasoning) are evident both numerically and visually:
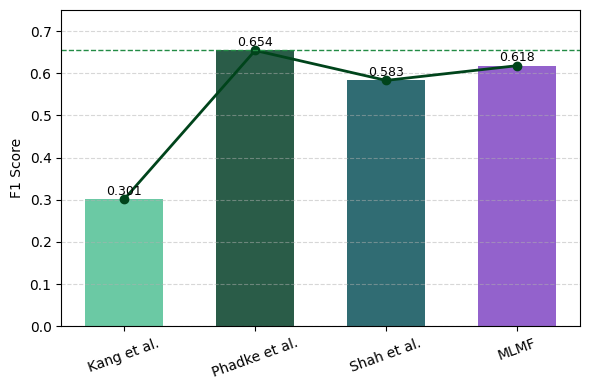
Figure 3: F1 score comparison across representative memory architectures, highlighting MLMF’s superiority over established baselines.
MLMF achieves a balance between memory consolidation and computational efficiency, seen in the faster decoding (10.4× throughput), lower false memory rates, and efficient context utilization, without the need for aggressive compression or additional computational overhead.
Ablation Study and Component Contributions
Ablation experiments isolate the contributions of semantic abstraction, episodic consolidation, adaptive gating, and retention regularization. Removing any of these modules leads to measurable degradation in F1, retention, and FMR, with semantic layer removal producing the largest drop in long-term retention. These findings empirically support the theoretical necessity of multi-layer consolidation and retention control.
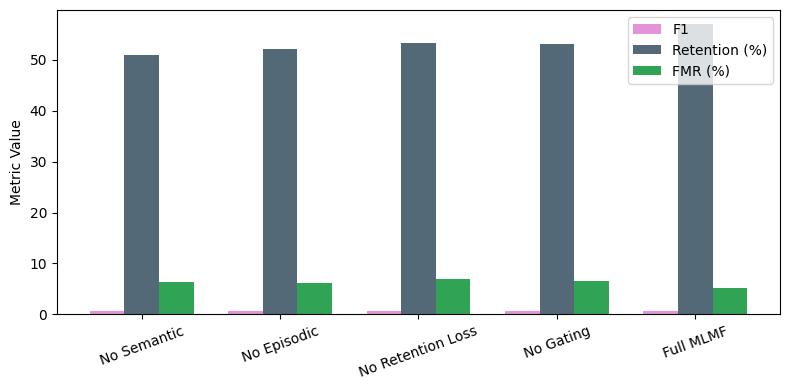
Figure 4: Ablation analysis demonstrating the critical role of each MLMF component in achieving robust F1, retention, and minimizing false memory.
Theoretical and Practical Implications
The layered structure of MLMF establishes a foundation for scalable long-term dialogue memory management, enabling sustained persona consistency and improved semantic stability in agentic interactions. Practically, this allows LLM agents to operate efficiently in real-world applications such as persistent digital assistants, long-running chatbots, and autonomous agents requiring consistent multi-session reasoning. The framework also lays theoretical groundwork for memory-aware architectures beyond simple context concatenation or flat compression, supporting structured reasoning across entities, temporal intervals, and causal relationships.
Future research can extend MLMF through integration with continual learning paradigms, multi-agent synchronization protocols, or adaptive task-aware retrieval. Utility in open-domain and high-variance conversational settings—along with domain-specific event consolidation—represents promising directions. Coupling MLMF with neurosymbolic entity tracking or explicit external memory will further enhance robust semantic abstraction in LLM agents.
Conclusion
The Multi-Layer Memory Framework introduces a hierarchical, adaptive, and regularized approach for long-term context retention in LLM agents, empirically validated across multiple benchmarks. It achieves superior retention, reasoning stability, and computational efficiency compared to prior multi-layer memory and compression-based systems. The ablation study corroborates the critical impact of semantic consolidation and retention control, with both practical and theoretical implications for designing memory-aware conversational agents. MLMF sets a precedent for structured memory evolution, laying a foundation for future architectures in scalable agentic AI systems.

