- The paper presents a novel Chain-of-Structured-Thought pipeline that extracts query-specific structured data to enhance accuracy and reduce hallucinations in long-document QA.
- It details a two-stage fine-tuning process—Supervised Fine-Tuning and Group Relative Policy Optimization—that enables compact SLMs to rival larger LLMs in performance.
- Empirical results demonstrate significant improvements in structured data extraction accuracy, process verification, and latency reduction, ensuring robust deployment in high-stakes domains.
Chain-of-Structured-Thought and Efficient SLM Fine-Tuning for Long-Document QA
Problem Statement and Motivating Insights
LLMs are increasingly deployed for long-document question answering (QA) and data analytics, but direct end-to-end reasoning over lengthy, noisy, multiformat corpora is error-prone and challenging—these settings expose deficiencies in high-stakes domains where faithfulness, interpretability, and verifiability are required. The paper “Long-Document QA with Chain-of-Structured-Thought and Fine-Tuned SLMs” (2603.29232) addresses these limitations by arguing for a structured reasoning interface: extract explicit, query-specific tables, graphs, or structured records that distill the provenance and correctness of the answer.
This approach is motivated by strong empirical evidence (Figure 1) showing that LLMs are brittle when reasoning over unstructured, dispersed evidence but succeed when structured data is available—even when both tasks are handled by advanced models. Extracting well-typed structured data thus improves accuracy and enables routine verification, supporting higher-level desiderata: correctness, auditability, and generalization.
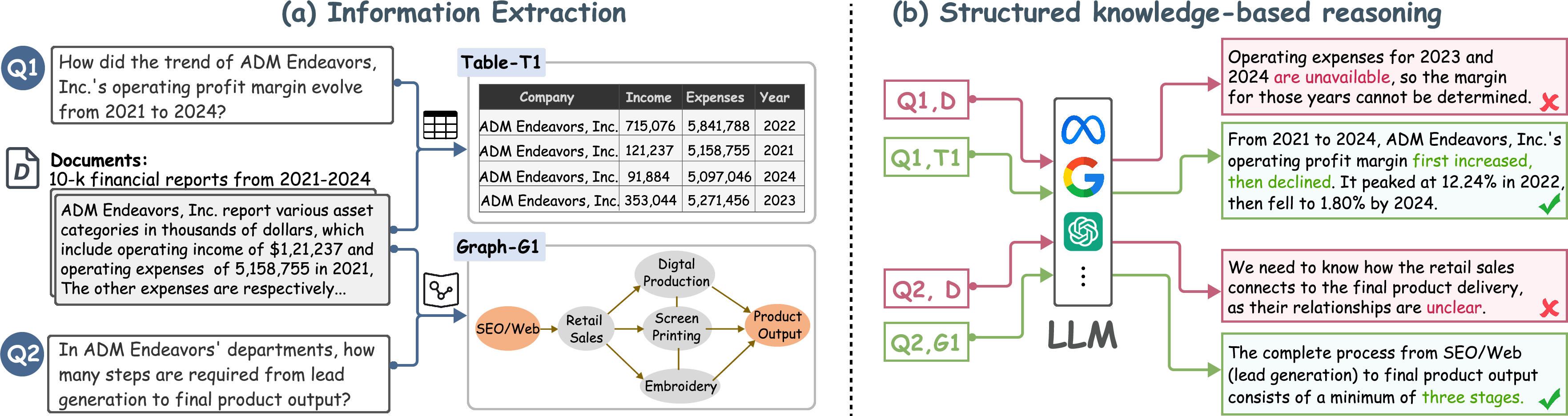
Figure 1: Structured data extraction for queries increases reliability and accuracy compared to unstructured, free-form reasoning over long documents.
The LiteCoST Framework: Architecture and Algorithms
Chain-of-Structured-Thought (CoST)
The first pillar of the framework is the Chain-of-Structured-Thought (CoST). CoST moves beyond naively prompting LLMs to produce direct answers, which often results in hallucinations or format errors (Figure 2), by adopting a schema-aware, structured prompting technique. For each question and supporting document set, CoST dynamically induces a minimal schema (table, graph, etc.) tailored to the query semantics, then guides a high-capacity LLM through step-wise extraction: structure analysis, trace generation, automated quality verification, and iterative refinement.
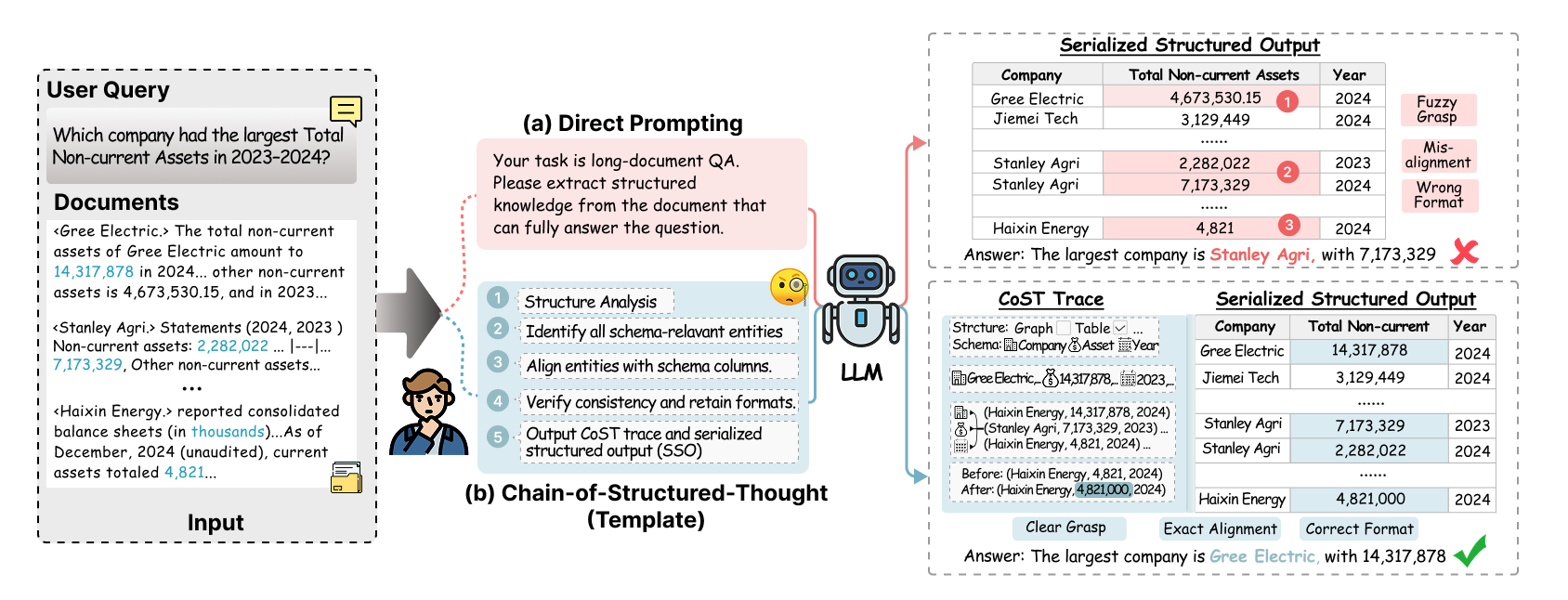
Figure 2: (a) Direct LLM prompting leads to hallucinations/format drift; (b) the CoST pipeline integrates structured guidance to yield auditable outputs.
The LLM is explicitly required to output both (i) a serialized structured artifact (SSO)—fully normalized, aligned representations containing only relevant entities and units—and (ii) an auditable “trace” detailing the extraction and normalization steps. This template-driven supervision renders provenance explicit and enables subsequent fine-tuning and verification.
SLM Adaptation via SFT and GRPO
To address the practical shortcomings of LLM-centric solutions (high cost, privacy, and latency), the second pillar—SLM adaptation—fine-tunes compact models (3B/7B parameters) to emulate CoST-style reasoning. The fine-tuning procedure is two-stage (Figure 3):
- Supervised Fine-Tuning (SFT): The SLM is instructed on CoST-generated traces and SSOs to internalize schema/format discipline, step-level reasoning, and correct serialization.
- Group Relative Policy Optimization (GRPO): SLMs are optimized via reinforcement learning to further refine extraction skill, employing dual-level reward signals:
- Outcome Reward: Encourages format compliance and answer accuracy (semantic and structural alignment to ground truth, LLM-judged).
- Process Reward: Densely rewards faithful, step-by-step extraction aligned with ground-truth reasoning traces, using LLM judgment as a consistency metric.
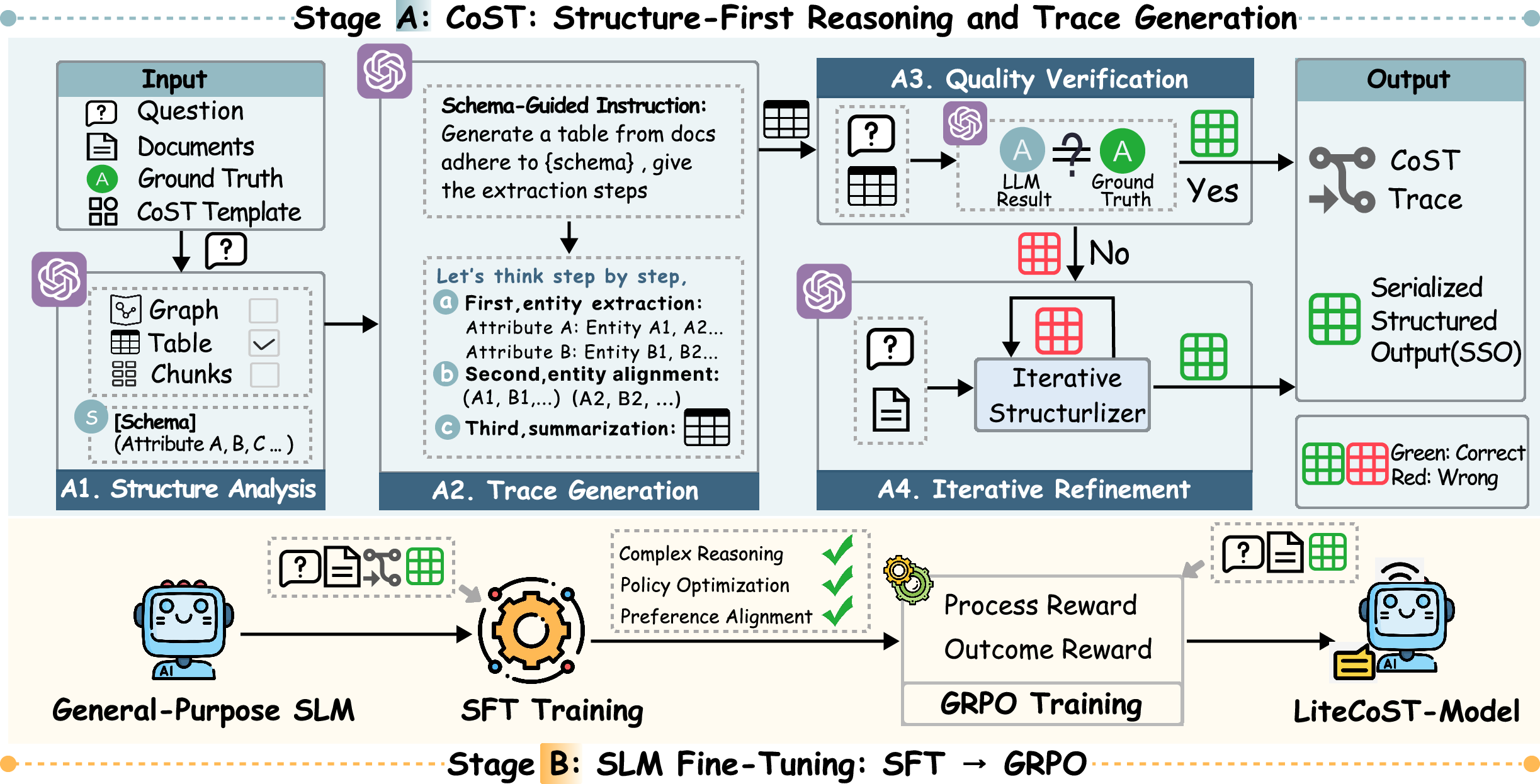
Figure 3: LiteCoST architecture—Stage (1) CoST generation and (2) SLM adaptation via SFT and GRPO with detailed reward composition.
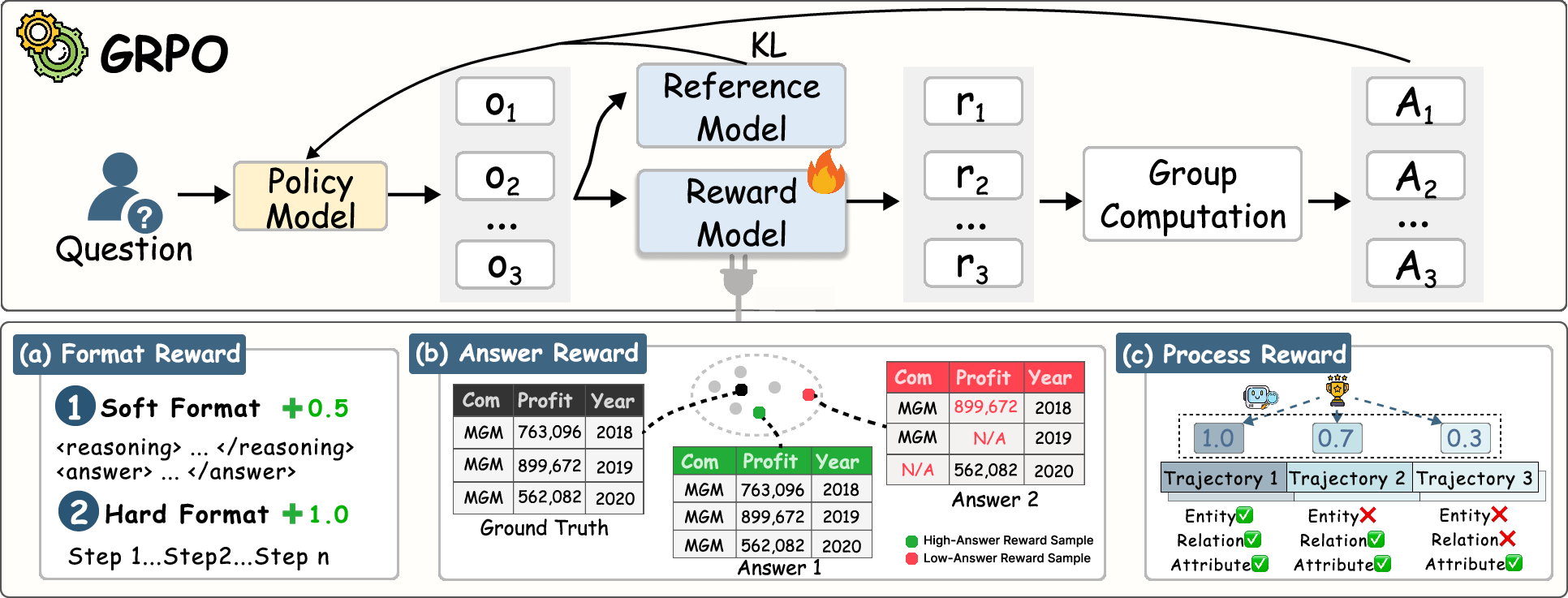
Figure 4: The GRPO pipeline leverages group-relative advantages over sampled generations with multi-factor (format, answer, process) rewards.
Empirical Results
The framework is evaluated on the Loong multi-domain long-document QA benchmark, with structured data extraction accuracy and perfect-rate (PR) as primary metrics. Both SLMs and LLMs are compared under diverse tasks (Spotlight Locating, Comparison, Clustering, Chain-of-Reasoning).
- Impact of Structure on Reasoning: Structured data (CoST-generated) consistently improves model accuracy and reliability compared to direct QA over long documents, with LLM scores and PR gains up to +12.4 and +0.10 on various backbones (Figure 5).
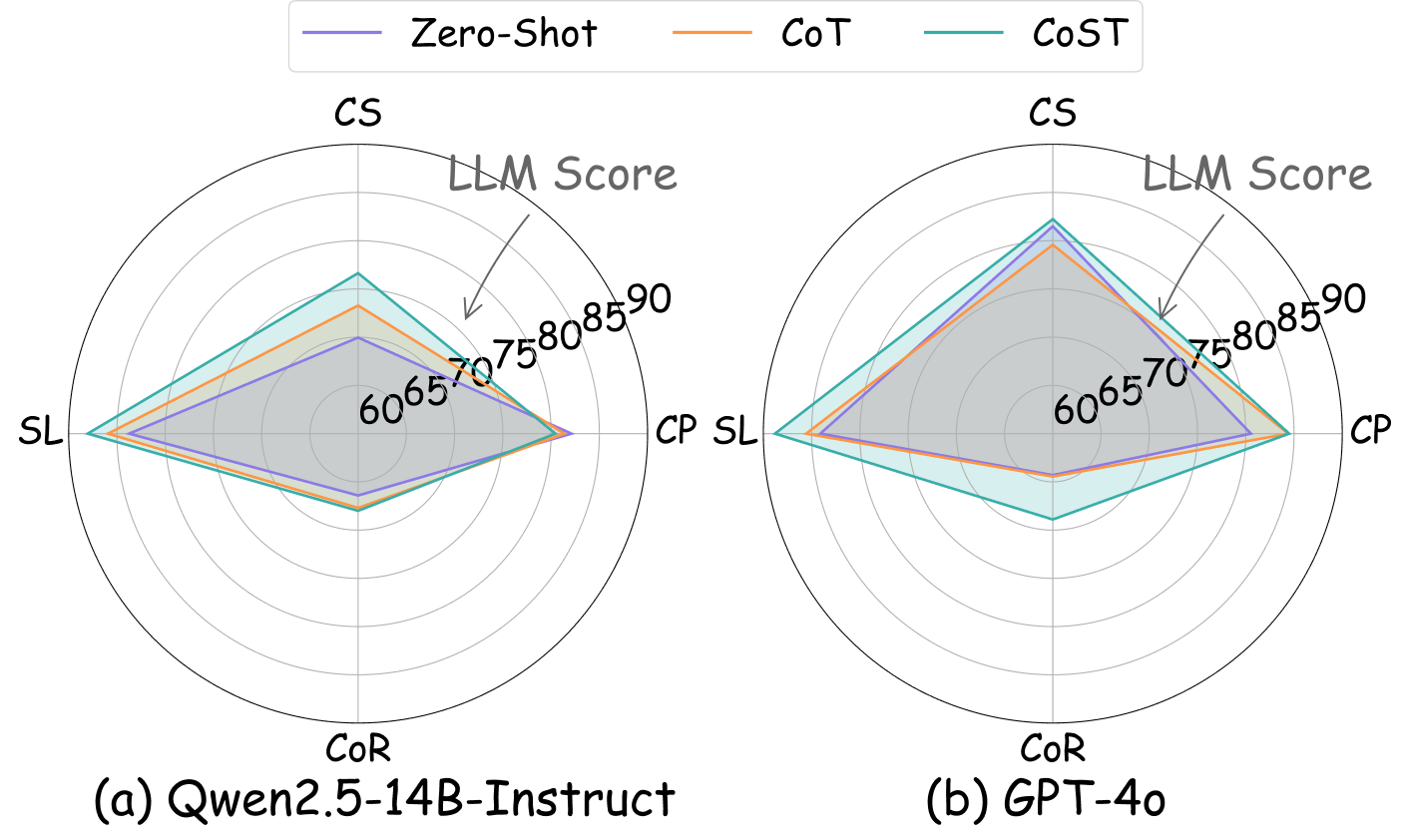
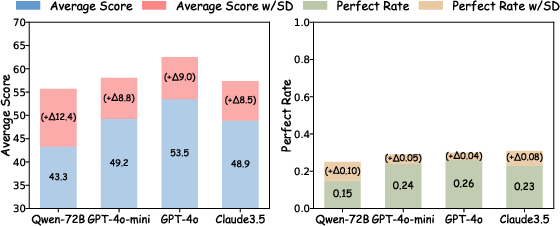
Figure 5: Left—Task breakdown with structured prompting; Right—gains in reasoning metrics when using CoST-generated structured data versus unstructured context.
- Effectiveness of SLM Fine-Tuning: LiteCoST-tuned LLaMA-3B and Qwen-7B models deliver delta improvements of +27.6/+17.8 points in accuracy and +0.29/+0.22 in PR over untuned bases—both variants rival or surpass LLMs with 7–200B parameters, narrowing the accuracy gap with a 2–4× latency reduction compared to GPT-4o and DeepSeek-R1.
- Comparison to State-of-the-Art IE Systems: LiteCoST delivers substantial gains over ODIE, IEPile, StructBench, and StructRAG; RL-enhanced SLMs yield a further 6–15 points of gain and up to +0.46 in PR versus prior modular extraction systems.
Generalization and Robustness
LiteCoST demonstrates strong generalization across legal and scientific (open-domain) long-document QA benchmarks:
- In the legal domain (Loong-Legal), the 3B and 7B LiteCoST models outperform LLMs with far larger scales, showing average score improvements up to +15 and achieving best-in-class results.
- On the LongBench benchmark (single and multi-document QA), CoST-guided LLMs outperform non-structured prompts by up to +7.1 F1, while LiteCoST SLMs match or exceed GPT-4o on NarrativeQA, Qasper, and HotpotQA, verifying transferability and robustness.
Practical Implications and Prospects
LiteCoST provides a cost-effective paradigm for scalable, accurate QA and information extraction from long and complex documents, suitable for privacy-sensitive or resource-limited settings (on-prem deployment). The step-wise, verifiable approach grounds answers in explicit provenance, promoting trust and routine auditability—critical in finance, law, and science.
The architectural decoupling—using LLMs for one-off high-quality supervision, then distilling both outcome and process knowledge into SLMs—efficiently bridges the quality-latency tradeoff. Strong reinforcement learning rewards (especially process-level consistency) are shown to be essential for high-fidelity information extraction and robust, schema-aware generalization.
Theoretical Implications and Future Directions
The work highlights failure modes of end-to-end LLM reasoning (omissions, hallucination, format drift) and demonstrates that schema-first, traceable extraction mitigates these fundamentally. Future developments are likely to combine structured-reasoning templates with more advanced self-verification; adapt similar techniques for vision or multi-modal QA; and push RL reward modeling for more granular coverage and trace alignment. Continued advances are expected in reward modeling for process supervision, synthetic data generation for rare schemas, and rapid domain adaptation as more annotated corpora become available.
Conclusion
The Chain-of-Structured-Thought and LiteCoST framework offer a compelling approach for accurate, auditable long-document QA by extracting query-conditioned structured representations and efficiently fine-tuning SLMs through supervised and reinforcement signals. This work shows that carefully crafted schema-guided supervision, when distilled into compact models, can rival large-scale LLMs both in empirical effectiveness and computational efficiency, furthering progress toward deployable, verifiable, and robust AI for complex unstructured data domains.
(2603.29232)