ASI-Evolve: AI Accelerates AI
Abstract: Can AI accelerate the development of AI itself? While recent agentic systems have shown strong performance on well-scoped tasks with rapid feedback, it remains unclear whether they can tackle the costly, long-horizon, and weakly supervised research loops that drive real AI progress. We present ASI-Evolve, an agentic framework for AI-for-AI research that closes this loop through a learn-design-experiment-analyze cycle. ASI-Evolve augments standard evolutionary agents with two key components: a cognition base that injects accumulated human priors into each round of exploration, and a dedicated analyzer that distills complex experimental outcomes into reusable insights for future iterations. To our knowledge, ASI-Evolve is the first unified framework to demonstrate AI-driven discovery across three central components of AI development: data, architectures, and learning algorithms. In neural architecture design, it discovered 105 SOTA linear attention architectures, with the best discovered model surpassing DeltaNet by +0.97 points, nearly 3x the gain of recent human-designed improvements. In pretraining data curation, the evolved pipeline improves average benchmark performance by +3.96 points, with gains exceeding 18 points on MMLU. In reinforcement learning algorithm design, discovered algorithms outperform GRPO by up to +12.5 points on AMC32, +11.67 points on AIME24, and +5.04 points on OlympiadBench. We further provide initial evidence that this AI-for-AI paradigm can transfer beyond the AI stack through experiments in mathematics and biomedicine. Together, these results suggest that ASI-Evolve represents a promising step toward enabling AI to accelerate AI across the foundational stages of development, offering early evidence for the feasibility of closed-loop AI research.
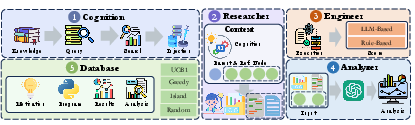
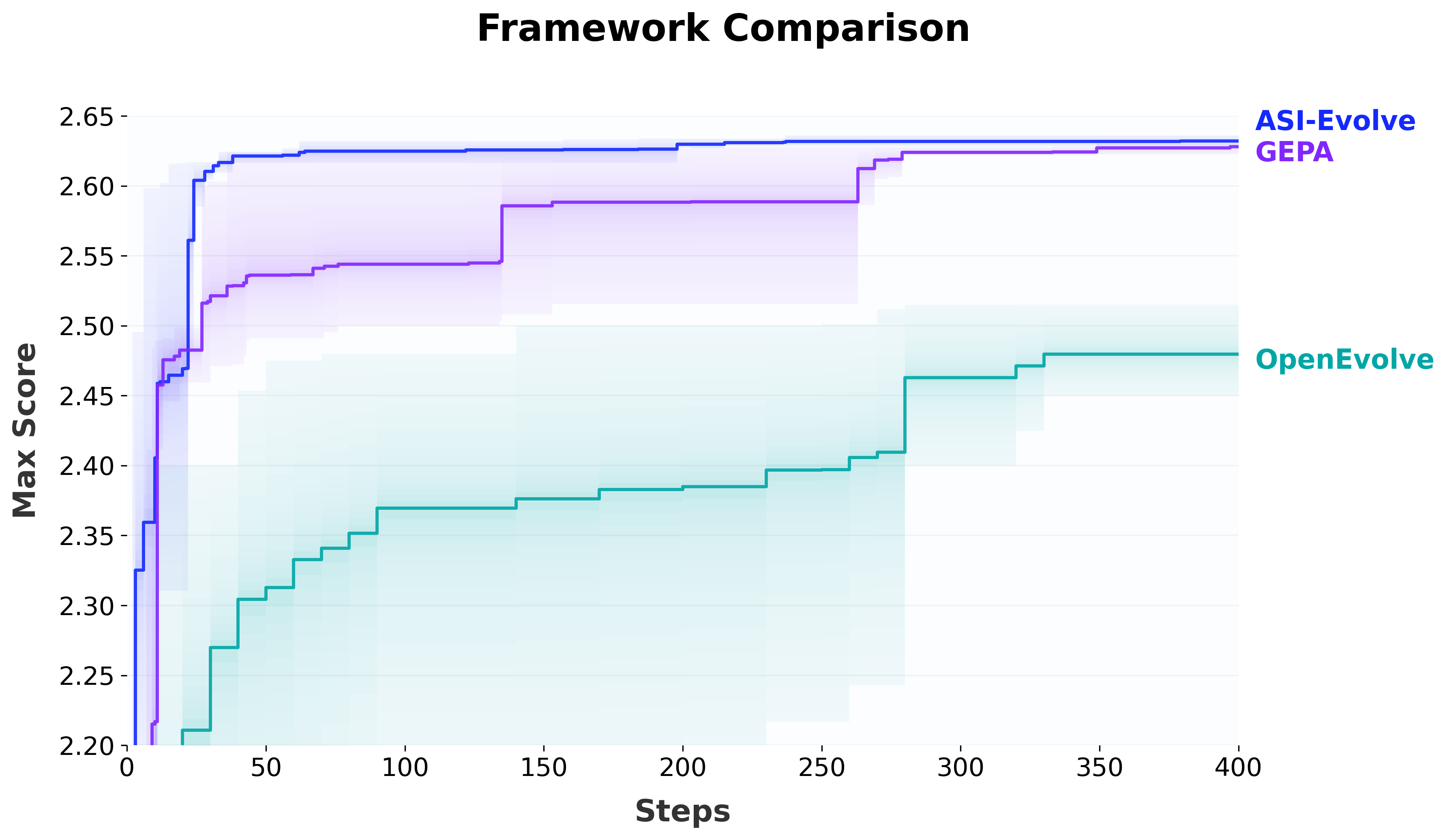
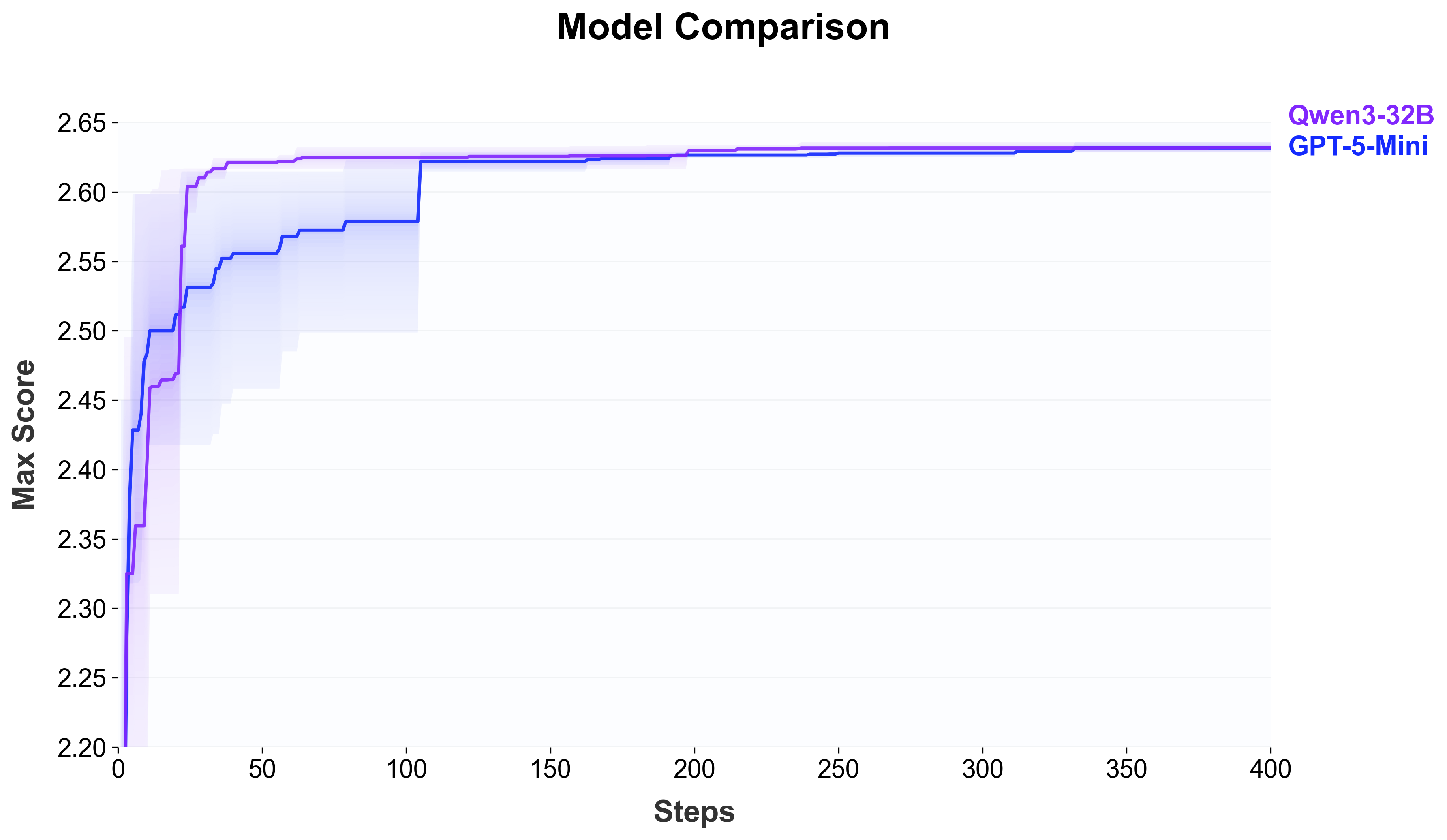

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
ASI‑Evolve: AI that helps build better AI
Overview
This paper introduces ASI‑Evolve, a system where artificial intelligence helps run real scientific research to make AI itself better. Think of it like a tireless research team that can read papers, design ideas, run experiments, learn from mistakes, and try again—over and over—until it discovers better ways to build and train AI models.
What questions did the paper ask?
The authors wanted to know:
- Can an AI system run long, complicated research cycles (not just quick tests) to improve AI?
- Can the same system discover new ideas in three big areas that shape how good AI becomes: the data we train on, the model designs we use, and the way we train models?
- Can this “AI-for-AI” approach work beyond AI, in areas like math and biomedicine?
How did they do it?
The system works in a loop that mirrors how human scientists work: learn → design → experiment → analyze → repeat. The twist is that the loop is run by AI “agents” and supported by tools that help it remember and grow.
Here’s the idea in everyday language:
- Scientific research on AI is hard for three main reasons:
- It’s expensive and slow to test ideas (training big models takes lots of time and GPUs).
- There are too many choices to try (huge “search space” of designs, data filters, and training tricks).
- The feedback is messy (results are not a single score; you get many charts and logs that are hard to interpret).
To handle this, ASI‑Evolve includes:
- A Cognition Base: like a well-organized library of human knowledge—papers, tips, and lessons learned—so the system doesn’t start from zero each time.
- A Researcher: an AI that proposes a new idea or code change based on past attempts and what it learned from the library.
- An Engineer: an AI that runs the experiment safely and efficiently, with early checks to stop broken or wasteful runs.
- An Analyzer: an AI that reads the long logs and numbers from the run and writes a short, useful summary of what worked and what didn’t.
- A Database: the lab notebook that stores ideas, code, results, and lessons so future attempts get smarter.
Analogy: Imagine a cooking competition where the chef (Researcher) invents a recipe, the kitchen staff (Engineer) cooks it while avoiding disasters, the food critic (Analyzer) explains why it tasted good or bad, and a bookshelf (Cognition Base) holds the best cooking wisdom. After each round, the team learns and tries a better recipe.
What did they find?
They tested ASI‑Evolve on three tough, real research problems that usually require lots of human effort.
- Model architecture design (how the AI model is built)
- Focus: Invent faster attention layers (the part of a model that decides what words or tokens to focus on) that are efficient for long inputs.
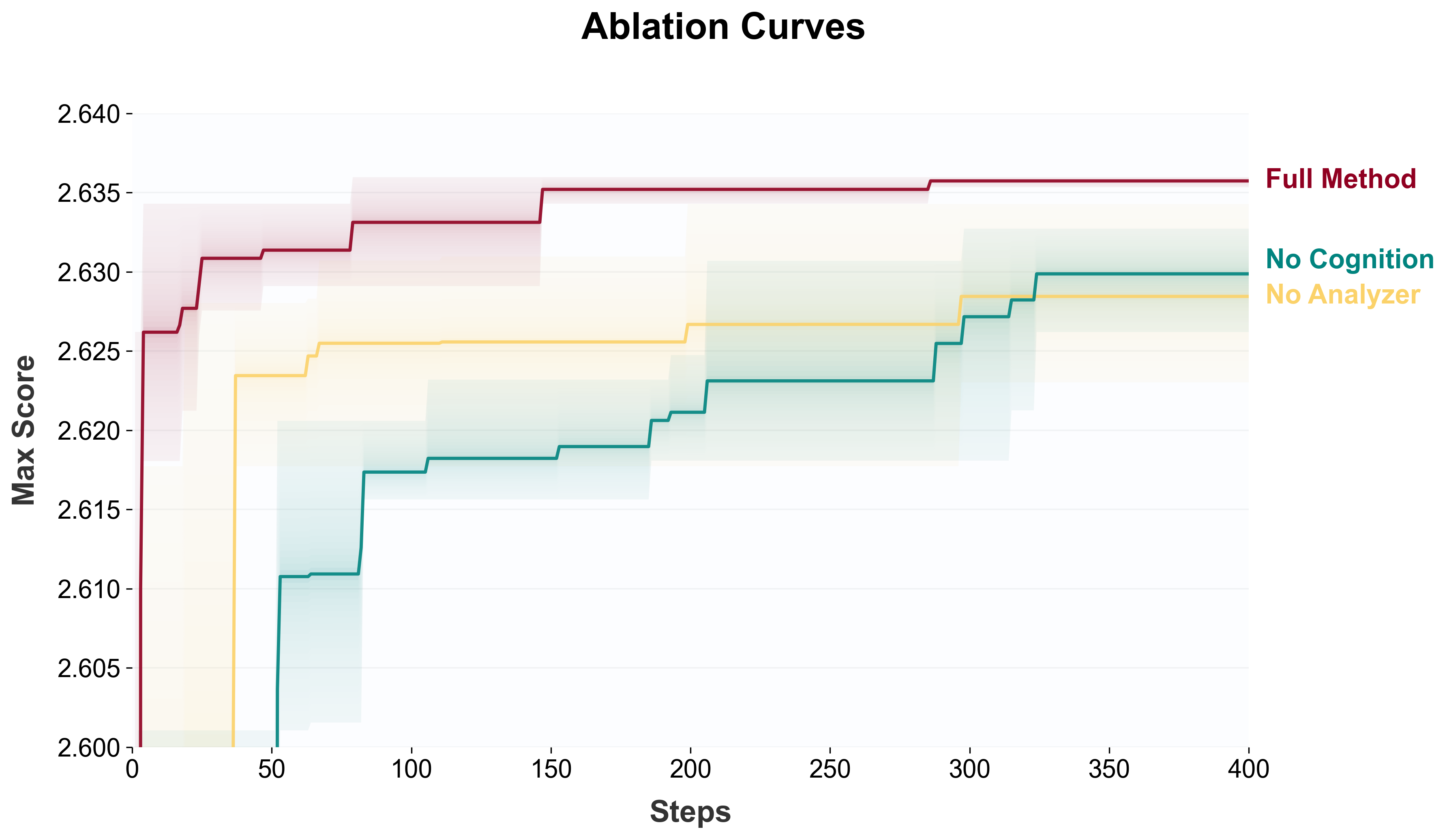
- Result: The system created 105 model designs that beat a strong human-designed baseline called DeltaNet. The best one improved by almost 3 times more than recent hand-crafted improvements. These designs also worked well on new tests they weren’t trained on, which suggests the ideas are robust.
- Why it matters: Better, more efficient model designs can make AI faster and cheaper without losing smarts.
- Pretraining data curation (how we clean and prepare the training data)
- Focus: Automatically design cleaning strategies for massive text datasets (removing junk like broken HTML, duplicates, and formatting noise while keeping valuable content).
- Result: The evolved cleaning pipeline boosted average benchmark scores by +3.96 points, with big jumps on knowledge-heavy tests (e.g., MMLU improved by over 18 points).
- Why it matters: Cleaner data leads to smarter models. Automating this saves huge amounts of expert time and improves quality at scale.
- Training algorithm design (how we teach the model)
- Focus: Improve reinforcement learning (RL) methods used to fine-tune LLMs, starting from a popular baseline called GRPO.
- Result: The system found new training algorithms that beat GRPO by large margins on hard math benchmarks—for example, +12.5 points on AMC32 and +11.67 on AIME24.
- Why it matters: Better training rules make models learn more effectively from feedback, which can translate into stronger reasoning and problem-solving.
Bonus findings:
- Speed and reliability: The system uses early checks to stop bad runs, debugging tools to fix crashes, and an AI judge to assess code quality and novelty when simple scores aren’t enough.
- Beyond AI: Early tests show the approach also helps in other sciences, like improving drug–target prediction in biomedicine.
Why is this important?
- It’s the first time a single, unified AI system has shown meaningful advances across all three pillars of AI development—data, model designs, and training methods.
- It shows that “closed-loop” AI research—where AI runs the whole cycle and learns from itself—can work on long, costly, and complex problems, not just small toy tasks.
- It points toward a future where AI speeds up scientific discovery in many fields, not only in AI.
Limitations and what’s next
- The experiments are expensive; training and testing big ideas still require lots of compute.
- The system doesn’t automatically produce low-level, hardware-optimized code (like custom GPU kernels), so real-world speedups might still need human engineering.
- AI judgements (like the AI-as-a-judge scores) help, but they’re not perfect and should be used carefully with solid measurements.
Takeaway
ASI‑Evolve is like an AI research lab that never sleeps. By reading, trying, testing, and learning in cycles—and by remembering what works—it discovered better model parts, better data-cleaning recipes, and better training rules. This is an encouraging step toward AI that can help invent the next generation of AI, and potentially accelerate discoveries in other sciences too. The authors have also open-sourced the system so others can build on it.
Knowledge Gaps
Below is a single, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Framework/reproducibility: Specify the exact LLMs (model names/versions), prompts, decoding params (temperature, top-p), and seed control used by Researcher/Engineer/Analyzer; release prompt templates and logs to enable strict reproducibility.
- Compute transparency: Quantify total GPU hours, wall-clock time, and energy/carbon cost per task and overall; report sample efficiency (improvements per GPU-hour) to assess practicality.
- Statistical robustness: Report variance across multiple seeds and runs, with confidence intervals and significance tests, rather than single best numbers.
- Fitness design sensitivity: Provide sensitivity analysis to fitness weighting (rule-based metrics vs LLM-as-a-Judge) and normalization (e.g., sigmoid vs linear), including how these choices affect convergence and diversity.
- LLM-as-a-Judge calibration: Measure correlation between judge scores and expert human ratings; probe prompt sensitivity and susceptibility to “gaming”; ablate judge use to quantify its causal impact on outcomes.
- Analyzer fidelity: Validate the Analyzer’s distilled insights against raw logs via expert review; quantify hallucination/error rates and their downstream effect on search quality.
- Cognition base governance: Detail curation criteria, update cadence, and quality control for cognition entries; study how outdated/incorrect priors bias search and how to detect/correct such drift.
- Contamination checks: Perform rigorous contamination audits between the cognition base, training data, and evaluation benchmarks (e.g., MMLU, CSQA), including exact/fuzzy-matching analyses and report leakage-adjusted results.
- Retrieval mechanism limits: Ablate embedding models, retrieval depth, and negative sampling; evaluate retrieval precision/recall and the effect of noisy or off-topic cognition entries on search trajectories.
- Early rejection risks: Quantify false-negative rates of quick tests/timeouts that might discard promising candidates; study adaptive thresholds to mitigate premature pruning.
- Sampling policy guidance: Provide head-to-head, quantitative ablations of UCB1, greedy, random, MAP-Elites across tasks; offer practical guidelines for policy selection as a function of search-space and feedback characteristics.
- Convergence and stopping criteria: Define and empirically test stopping rules (e.g., improvement plateaus, novelty stagnation); analyze diminishing returns over long horizons.
- Safety and security: Describe sandboxing for executing generated code, dependency isolation, and protections against malicious or unsafe code; report any security incidents/failures encountered.
- Human effort accounting: Clarify the extent of human intervention (e.g., cognition-base curation, pipeline maintenance, failure triage), including time spent and impact on outcomes.
- Cross-framework baselines: Conduct controlled, same-task comparisons against leading agentic/evolutionary frameworks (e.g., AlphaEvolve, FunSearch, OpenEvolve) to isolate contributions beyond problem selection.
- Knowledge accumulation metrics: Introduce metrics that quantify “cognition evolution” (e.g., increasing retrieval utility, reduced redundant failures, insight reuse rate) to substantiate the claim of evolving cognition.
- Multi-objective optimization: Replace or augment scalar fitness with Pareto-front analysis across accuracy, wall-clock speed, memory, and cost; study trade-offs explicitly rather than aggregating into a single score.
- Robustness to feedback noise: Stress-test the loop under noisy/shifted evaluation sets and fluctuating training dynamics; use bootstrap/perturbed dev sets to assess stability of search decisions.
- Generalization beyond AI: Provide broader, deeper experiments outside AI/ML (more than one biomedical task), with domain-specific baselines, dataset details, and statistically robust comparisons.
- Open-source completeness: Ensure that the released repo includes full training/evaluation scripts, data processing code, cognition base snapshots (with licenses), and experiment manifests to enable end-to-end replication.
- Architecture search — wall-clock efficiency: Report kernel-level and end-to-end throughput/latency, memory footprint, and numerical stability of discovered architectures; evaluate on hardware-optimized kernels (e.g., CUDA/Triton) to assess practical deployability.
- Architecture search — confound controls: Verify that improvements are not due to hidden hyperparameter or training-schedule changes; provide strict ablations where only the attention mechanism differs.
- Architecture search — dev set size: The exploration stage uses small dev sets (e.g., 500 samples); test larger/more diverse dev splits and show that exploration fitness predicts final large-scale performance.
- Architecture search — seed variability: Report variability across seeds for 20M/340M/1.3B models to ensure gains are consistent and not due to lucky draws.
- Data curation — evaluation depth: The Analyzer inspects 50 (original, cleaned) pairs per iteration; test whether this small sample yields reliable strategy selection by increasing sample sizes and adding human raters for inter-rater reliability.
- Data curation — recipe parity: Document and equalize tokenizer, deduplication, sampling/mixing, and training hyperparameters across corpora; rule out confounds when attributing gains to curation strategies.
- Data curation — domain/language breadth: Strategies were derived on academic categories; evaluate transfer to general web content, code, low-resource languages, and noisy domains.
- Data curation — contamination audits: For large MMLU gains, perform benchmark-specific contamination checks of Nemotron-CC and the curated outputs; rerun evaluations on decontaminated splits.
- RL algorithm design — training horizon: Extend beyond 150–300 steps; assess stability over long training, late-stage performance, and sample efficiency under fixed budgets.
- RL algorithm design — generality: Test evolved algorithms across non-math RLHF/RLAIF tasks (dialogue, safety, coding) and different reward models to assess robustness and brittleness.
- RL algorithm design — full specification: The description of Algorithm B is truncated; provide complete mathematical definitions, pseudocode, and hyperparameters to enable reproduction.
- RL algorithm design — safety/behavioral impacts: Analyze KL behavior, reward hacking, response diversity, and alignment/safety regressions introduced by new advantage/clipping mechanisms.
- Circle-packing benchmark details: Provide thorough experimental settings, compute budgets, and variance for the claimed SOTA-level results in 17 rounds; show fairness vs prior frameworks under identical constraints.
- Failure mode catalog: Document common failure patterns (e.g., mode collapse, overfitting to judge preferences, brittle code edits) and mitigation strategies learned by the system.
- Scalability w.r.t. agent LLM capability: Study how outcomes change with weaker/stronger agent models (open vs closed) to understand capability requirements and cost–benefit trade-offs.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings and methods can be used today across sectors, with notes on potential tools/workflows and key assumptions that affect feasibility.
- Autonomous pretraining data curation for large-scale corpora (software/AI, education, healthcare, finance)
- What to do: Deploy the paper’s ASI-Evolve loop to design category-specific cleaning strategies (e.g., remove HTML/templating artifacts, deduplicate, normalize formatting while preserving domain-relevant content), then integrate those strategies into existing data pipelines.
- Why it matters: The paper reports +3.96 average benchmark points over a strong baseline and very large gains on knowledge-intensive tasks (e.g., +18 points on MMLU), indicating better data quality translates to stronger models under the same training budget.
- Tools/workflows: Use the open-source ASI-Evolve repo to (1) build a cognition base of known data issues, (2) generate/evaluate strategies on sampled documents, (3) iterate strategies with Analyzer feedback, and (4) productionize rules in Spark/Beam/Airflow ETL jobs.
- Assumptions/dependencies: Requires labeled or proxy evaluation signals (including LLM-as-a-judge) that reflect downstream quality; appropriate data governance/PII handling; compute/storage for iterative sampling and evaluation.
- Drop-in efficient sequence modeling via evolved linear-attention layers (software/AI, edge/embedded, robotics)
- What to do: Integrate the discovered adaptive routing linear-attention modules (e.g., PathGateFusionNet, FusionGatedFIRNet) as alternatives to baseline attention in codebases where long-context or low-latency inference is critical.
- Why it matters: The best evolved architectures exceed a strong human baseline (DeltaNet) and rival/beat recent human-designed alternatives while retaining O(N) complexity, implying potential for lower cost or longer contexts in production.
- Tools/workflows: Package evolved layers as PyTorch modules; run A/B tests on representative inference/training workloads; pair with profiling and kernel-level optimization passes (e.g., PyTorch 2.x compile, Triton).
- Assumptions/dependencies: Paper notes no bespoke CUDA kernels were generated; wall-clock gains depend on backend optimization; task transferability requires re-validation on target domains and model scales.
- Optimized RL algorithms for LLM post-training (software/AI, education, coding assistants)
- What to do: Incorporate evolved policy-gradient variants (e.g., Pairwise Asymmetric Optimization, Budget-Constrained Dynamic Radius) into RLHF/RLAIF pipelines to improve reasoning-heavy benchmarks or reduce variance/instability.
- Why it matters: The paper shows large deltas over GRPO on math reasoning (e.g., +12.5 on AMC32, +11.67 on AIME24), suggesting better reward utilization and stability can accelerate capability gains.
- Tools/workflows: Swap loss/advantage modules in existing RL pipelines (TRL, custom PPO/GRPO code), use Analyzer to monitor stability/credit assignment, and gate deployment with safety/guardrail policies.
- Assumptions/dependencies: Gains were demonstrated on math tasks; verify on target domains (dialogue, coding, safety); maintain reward-model quality; ensure robustness against reward hacking/overfitting.
- Cognitive knowledge base for R&D acceleration (industry/academia R&D)
- What to do: Build a project-specific cognition base (papers, design docs, prior postmortems) and retrieve it to condition code/experiment generation, reducing cold-start and rediscovery of known pitfalls.
- Why it matters: The paper shows faster “climb” and better sustained progress when priors and distilled experience are injected into the loop.
- Tools/workflows: Embed and index domain docs; wire retrieval into agent prompts; continuously write Analyzer reports back as “experience” items for future rounds.
- Assumptions/dependencies: Quality and coverage of priors matter; embeddings/retrieval must be tuned to the domain; human curation still valuable to prevent knowledge base drift.
- Automated experiment analysis for multi-metric training runs (MLOps, academia)
- What to do: Use the Analyzer to convert noisy logs (loss curves, per-benchmark scores, throughput, error traces) into compact, decision-ready reports with causal hypotheses and next-step suggestions.
- Why it matters: Cuts experimentation overhead and speeds up decision-making in long-horizon training (architecture search, RL, data curation).
- Tools/workflows: Integrate with MLFlow/W&B artifact stores or logging sinks; store reports in a searchable database for future retrieval.
- Assumptions/dependencies: Analyzer accuracy depends on LLM capability and access to full logs; requires reliable, structured logging and evaluation harnesses.
- Agentic research workflow for long-horizon experimentation (industry/academia)
- What to do: Adopt the Researcher–Engineer–Analyzer loop to automate iterations: propose diffs, run static checks, early reject weak candidates, auto-debug errors, and sample promising seeds via UCB1/greedy/MAP-Elites.
- Why it matters: Demonstrated ability to sustain progress under costly, weakly supervised research loops (data, architecture, algorithms).
- Tools/workflows: Integrate with CI/CD (GitHub Actions), job schedulers (SLURM/K8s), and experiment trackers; enforce timeouts and safety checks.
- Assumptions/dependencies: Requires GPU budget and robust sandboxing; success hinges on reliable evaluation metrics; human-in-the-loop oversight recommended for safety and cost control.
- Biomedical modeling uplift via architecture evolution (healthcare/biomed)
- What to do: Apply architecture evolution to domain models (e.g., drug–target interaction), using domain-specific cognition bases and fitness grounded in AUROC/AUPR on cold-start splits.
- Why it matters: The paper reports +6.94 AUROC in cold-start DTI, suggesting cross-domain potential beyond NLP.
- Tools/workflows: Build biomed cognition base (domain papers, known pitfalls), integrate with standard bio ML pipelines (DeepChem, PyTorch Geometric), and add domain-specific validation (e.g., scaffold splits).
- Assumptions/dependencies: Clinical relevance requires external validation; data access/compliance constraints; interpretability and safety are critical for deployment.
- Task-complexity planning with Scientific Task Length (policy, program management, academia)
- What to do: Use the L_task = ⟨execution cost, search space complexity, feedback complexity⟩ framework to scope automation investments, evaluation protocols, and compute budgets for agentic systems.
- Why it matters: Provides a common lens to triage which research tasks can be automated now versus which need more scaffolding or supervision.
- Tools/workflows: Incorporate L_task scoring into internal review templates and grant/procurement processes.
- Assumptions/dependencies: Requires calibration with historical project data; benefits from community consensus to standardize comparisons.
Long-Term Applications
These opportunities build on the framework but require further research, scaling, integration, or validation before broad deployment.
- Autonomous AI research labs (“closed-loop” AI-for-AI) (industry/academia)
- Vision: End-to-end automation across data, architectures, algorithms with persistent cognition and Analyzer-guided iteration, accelerating capability development and reducing cycle time.
- Enablers: Larger model agents, better tool-use and codegen reliability, more faithful evaluation and safety monitors, cost-efficient compute scheduling.
- Dependencies/risks: Substantial compute; risk of metric gaming; need for robust governance, reproducibility, and red-teaming.
- Cross-domain scientific discovery (biomedicine, materials, climate)
- Vision: Apply the loop to hypothesis generation and model/experiment design in wet-lab or simulation-heavy fields (e.g., DTI, materials design, climate forecasting).
- Enablers: Domain-specific cognition bases, lab robotics/LIMS integration, closed-loop experiment execution with structured feedback.
- Dependencies/risks: Data scarcity/quality; experimental cost; safety/ethical oversight; regulatory approvals.
- Hardware–software co-design and kernel-level optimization (semiconductors/HPC)
- Vision: Extend from mechanism design to low-level kernel generation/tuning (CUDA/Triton/TVM), closing the “wall-clock efficiency” gap noted in the paper.
- Enablers: Verified codegen for kernels, auto-profiling, and differentiable cost models that reflect real hardware constraints.
- Dependencies/risks: Correctness and numerical stability; vendor-specific toolchains; risk of generating unsafe/inefficient kernels without strong guards.
- Continual enterprise corpus governance and compliance (all data-heavy sectors)
- Vision: Always-on data curation agents that evolve rules as content and regulations change, with auditable cognition and Analyzer reports.
- Enablers: Streaming ETL integration, policy-as-code, alignment with legal/compliance teams.
- Dependencies/risks: Evolving privacy/PII standards; auditability and versioning; minimizing inadvertent bias amplification.
- Sector-tailored RL/control policy evolution (robotics, energy, finance)
- Vision: Evolve RL objectives/advantages and constraints for robotic manipulation, grid control, or trading, using domain simulators and safety envelopes.
- Enablers: High-fidelity simulators, risk-aware rewards, and human-in-the-loop review.
- Dependencies/risks: Sim-to-real gaps; safety and regulatory constraints (e.g., financial risk, grid stability); need for interpretable policies.
- Education and training: evolving curricula and assessment generation (education/edtech)
- Vision: Use the loop to curate domain-specific learning materials and refine assessment strategies, with Analyzer feedback on learning outcomes.
- Enablers: Cognition bases from syllabi/standards; evaluation with student performance analytics.
- Dependencies/risks: Pedagogical validity; fairness and bias; privacy of learner data.
- Standards, auditing, and policy for agentic research systems (policy, governance)
- Vision: Establish protocols for logging, analyzing, and certifying AI-generated research artifacts (code, datasets, algorithms) using Analyzer outputs for traceability.
- Enablers: Community-agreed schemas for experiment metadata; reference evaluations for long-horizon tasks.
- Dependencies/risks: Industry buy-in; balancing transparency with IP; preventing perverse incentives and leaderboards that encourage metric gaming.
- Personal and team research copilots (knowledge workers)
- Vision: Lightweight versions of the loop to iteratively improve code, data workflows, or analyses for individuals and small teams, learning from local “cognition bases.”
- Enablers: Tight IDE/CI integrations; affordable on-device or cloud agents; privacy-preserving embeddings.
- Dependencies/risks: Data leakage concerns; need for robust guardrails; varying effectiveness across domains without high-quality priors.
Glossary
- Ablation studies: Targeted experiments that remove or alter components to assess their contribution to overall performance. "We further validate the effectiveness of Asi-Evolve through targeted comparisons and ablation studies."
- Agentic framework: A system design that empowers autonomous agents to plan, act, and iterate toward goals. "we present Asi-Evolve, an agentic framework for AI-for-AI research"
- Agentic systems: AI systems that exhibit autonomous, goal-directed behavior with planning and acting capabilities. "recent agentic systems have shown strong performance on well-scoped tasks with rapid feedback"
- AI-for-AI: The use of AI systems to automate or accelerate the research and development of AI itself. "we present Asi-Evolve, an agentic framework for AI-for-AI research"
- Advantage estimation: In policy gradient methods, computing how much better an action performed compared to a baseline to guide updates. "Algorithm A (Pairwise Asymmetric Optimization) introduces a comparative advantage estimation"
- AUROC: Area Under the Receiver Operating Characteristic curve; a metric summarizing binary classifier performance across thresholds. "where the evolved architecture achieves a 6.94-point AUROC improvement in cold-start generalization scenarios."
- Causal mask: An attention mask that prevents information flow from future tokens to enforce causality in sequence models. "verifying complexity bounds, chunk-wise structure, and causal mask correctness."
- Circle packing task: A benchmark problem involving arrangement of circles without overlap, used to evaluate search/evolution frameworks. "On the circle packing task used as a shared benchmark across evolutionary frameworks"
- Closed-loop: A research process that continuously feeds outcomes back into subsequent iterations for self-improvement. "offering early evidence for the feasibility of closed-loop AI research."
- Cognition base: A curated repository of human priors and accumulated insights used to guide hypothesis generation and exploration. "a cognition base that injects accumulated human priors into each round of exploration"
- Combinatorial optimization: Optimization over discrete, often vast solution spaces where the objective involves combinatorial structures. "discovered combinatorial optimization algorithms surpassing human-designed solutions."
- Cold-start: The initial phase of a system with little to no task-specific experience or data. "equipping the loop with this cognition base significantly improves cold-start climb speed and iteration efficiency"
- Chunk-wise computation: Partitioning sequences into chunks for efficient parallel processing and training. "employ chunk-wise computation patterns for efficient parallel training"
- Delta rule: An update rule that adjusts parameters in proportion to prediction error, here used as a memory path in sequence models. "across short-range, long-range, and delta-rule update paths."
- Embedding-based semantic search: Retrieving relevant items by comparing vector embeddings that capture semantic similarity. "via embedding-based semantic search; these entries are then injected"
- Entropy penalties: Regularization terms that encourage output distributions with higher entropy to avoid collapse or overconfidence. "with entropy penalties preventing mode collapse."
- Execution Cost (C_exec): The computational and engineering burden per trial, including GPU hours and code complexity. "Execution Cost (), which measures the computational resources and engineering complexity required per trial"
- Feedback Complexity (D_feedback): The difficulty of extracting actionable insights from multi-dimensional experimental outputs. "Feedback Complexity (), which measures the difficulty of extracting actionable insights from experimental outcomes"
- Fitness signal: A scalar objective used to rank or select candidates during evolutionary or search processes. "a primary scalar score that serves as the fitness signal."
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm that uses group-relative baselines for policy updates. "Using Group Relative Policy Optimization (GRPO) as the baseline"
- High-Impact Gradient Dropout: A training heuristic that stochastically drops gradients for tokens with outsized impact to reduce overfitting. "implements High-Impact Gradient Dropout, stochastically masking gradients for the most influential tokens"
- KL-penalty: A regularization term based on Kullback–Leibler divergence to constrain policy updates relative to a reference. "covering variance reduction techniques and KL-penalty modifications."
- Linear attention: Attention mechanisms with time and memory complexity linear in sequence length, often via kernelization or state compression. "designing efficient sequence models through linear attention mechanisms."
- LLM-as-a-Judge: Using a LLM to qualitatively assess and score outputs or code beyond simple metrics. "LLM-as-a-Judge qualitative scores"
- Long-horizon: Tasks that require many iterative steps with delayed, indirect, or sparse feedback. "long-horizon AI research tasks where feedback is expensive, indirect, noisy, and difficult to interpret"
- MAP-Elites island algorithm: An evolutionary strategy that maintains diverse high-performing elites across feature niches, often in isolated subpopulations (islands). "UCB1, random, greedy, and MAP-Elites island algorithm."
- Mode collapse: A failure mode where a model produces low-diversity outputs, concentrating on a few modes. "preventing mode collapse."
- Open-ended discovery: Exploration without predefined solution boundaries or fixed objectives, seeking novel and high-quality solutions. "achieve genuine open-ended discovery."
- Out-of-distribution (OOD) testing: Evaluating models on data distributions different from those seen during training. "including 6 held-out OOD test sets covering mathematics, code understanding, and multilingual tasks."
- Pairwise comparative advantage estimation: Estimating advantages by comparing a sample’s reward against others’ rewards in the same group. "introduces a comparative advantage estimation: instead of using a group mean, the advantage for a response is calculated by averaging the -normalized pairwise reward differences"
- Percentile-based normalization: Scaling values using percentile statistics (e.g., center and spread) to stabilize updates. "adopts percentile-based normalization for advantage calculation"
- Policy gradient: A class of RL methods that optimize parameters by ascending the gradient of expected reward with respect to the policy. "the system trained and evaluated a diverse array of policy gradient modifications"
- PPO clipping window: The bounds in Proximal Policy Optimization that limit the change in policy ratio per update. "the PPO clipping window "
- Pretraining data curation: Designing and applying strategies to clean and improve the quality of large-scale training corpora. "In pretraining data curation, evolved strategies produced cleaner training datasets"
- Reinforcement Learning (RL): A paradigm where agents learn to act by maximizing cumulative reward through interaction. "In reinforcement learning algorithm design, the framework derived novel optimization mechanisms"
- Scientific Task Length (L_task): An analytical framework characterizing tasks by execution cost, search space complexity, and feedback complexity. "we introduce Scientific Task Length ($L_\text{task$)} as an analytical framework"
- Search Space Complexity (S_space): The openness and dimensionality of the solution space, including how much must be discovered versus predefined. "Search Space Complexity (), which captures the complexity of the solution space the system must navigate"
- Sigmoid normalization: Rescaling scores via the sigmoid function to compress differences and modulate selection pressure. "sigmoid normalization progressively compresses rule-based score differences in later rounds"
- State space models: Sequence models that use latent state dynamics to model long-range dependencies efficiently. "150 entries extracted from 100 papers on linear attention, state space models, and efficient transformers"
- Sub-quadratic complexity: Computational complexity that grows slower than the square of input size, e.g., O(N) or O(N log N). "design novel attention layers with sub-quadratic complexity"
- UCB1: An Upper Confidence Bound algorithm for balancing exploration and exploitation in selection problems. "UCB1, random, greedy, and MAP-Elites island algorithm."
- Variance reduction techniques: Methods to decrease the variance of gradient or estimator to stabilize and improve learning. "covering variance reduction techniques and KL-penalty modifications."
- Wall-clock limits: Real-time timeouts that cap how long an experiment or run is allowed to execute. "supports early rejection via configurable wall-clock limits"
- Weakly supervised: Settings where labels or signals are noisy, indirect, or sparse rather than precise and fully labeled. "costly, long-horizon, and weakly supervised research loops"
Collections
Sign up for free to add this paper to one or more collections.