- The paper introduces a candidate-level reward allocation mechanism using Shapley values to resolve free-riding in multi-candidate LLM training.
- It employs a polynomial-time computation (O(K^2)) to ensure unbiased gradient updates and improved convergence over traditional RLHF methods.
- Empirical results across summarization, code suggestion, and recommendation tasks demonstrate enhanced model performance and training stability.
ShapE-GRPO: Shapley-Enhanced Reward Allocation for Multi-Candidate LLM Training
Introduction and Motivation
The emergence of multi-candidate generation scenarios—such as recommendation, brainstorming, code suggestion, and summarization—has stressed the limitations of traditional RLHF protocols that assign scalar rewards at the sequence or set level. Methods like Group Relative Policy Optimization (GRPO) provide a single feedback signal for all candidates in a response, leading to noisy gradients and inefficient exploration. The lack of granular credit assignment enables uninformative candidates to "free-ride" on the reward obtained by high-utility candidates, which both slows down convergence and distorts the optimization landscape for LLMs acting as recommenders.
ShapE-GRPO introduces a principled allocation mechanism for set-level reward signals based on the Shapley value from cooperative game theory. This approach explicitly accounts for the permutation-invariant semantics of candidate sets (e.g., the set of movie recommendations is typically unordered), and provides unbiased and theoretically sound candidate-level reward assignments. The proposed framework also addresses computational tractability concerns by exploiting reward function structure, enabling exact Shapley value computation with O(K2) complexity where K is the number of candidates.
Methodology: Candidate-Level Shapley Value Decomposition
ShapE-GRPO models each candidate in the LLM-generated set as a "player" in a cooperative game, where the set-level reward (e.g., maximum user satisfaction over recommendations) forms the value of the coalition. The credit to each candidate is determined by its expected marginal contribution over all permutations—i.e., its Shapley value:
ϕi=S⊆C∖{ci}∑K!∣S∣!(K−∣S∣−1)![R(S∪{ci})−R(S)]
This allocation aligns with fundamental Shapley properties: efficiency, symmetry, additivity, and the null player axiom. Importantly, when the reward is permutation-invariant (e.g., R({c1,…,cK})=maxiR(ci) in click-through tasks), the candidate-level Shapley values are both semantically justified and efficiently computable. In practice, ShapE-GRPO broadcasts the candidate's Shapley value equally to its constituent tokens, while the non-candidate reasoning segment of the output receives the usual set-level reward.
This reward broadcast is then plugged into the RL post-training objective. Specifically, the advantage term for LLM policy optimization is reweighted by these candidate-level Shapley values, eliminating the free-rider problem endemic to GRPO and Winner-Takes-All baselines, and yielding more discriminative gradients. Under mild assumptions of candidate length balance, the total reward allocation remains unbiased relative to the set-level reward, preserving the global optimization trajectory.
Theoretical Properties
ShapE-GRPO maintains several key theoretical invariants:
- Unbiasedness: If candidate tokens have matched lengths, the aggregate candidate-level Shapley rewards sum (after appropriate scaling) matches the original set-level reward; the optimization objective remains unbiased.
- No Free-Riding: The null player property ensures that candidates making zero marginal contribution (e.g., a suggestion never clicked or a wrong code snippet) receive zero or negative reward signals. This design strictly prohibits positive reinforcement for non-contributory candidates.
- Polynomial Complexity: For typical reward functions in LLM recommendation (max or binary, for instance), exact Shapley values are computed with only O(K2) floating-point operations, compared to the exponential complexity in generic cooperative games.
- Permutation Invariance: Rewards are robust to the ordering of candidates, aligning with practical deployments where the candidate set is unordered.
These properties collectively constitute a mathematically rigorous credit assignment strategy for post-training LLMs in set-valued feedback environments.
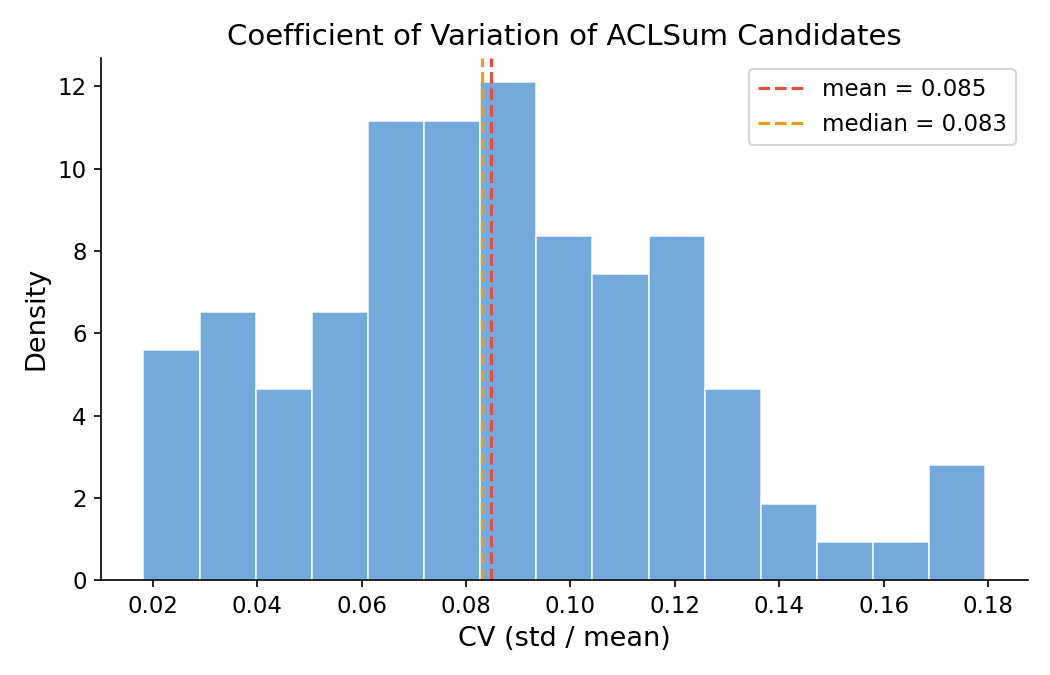
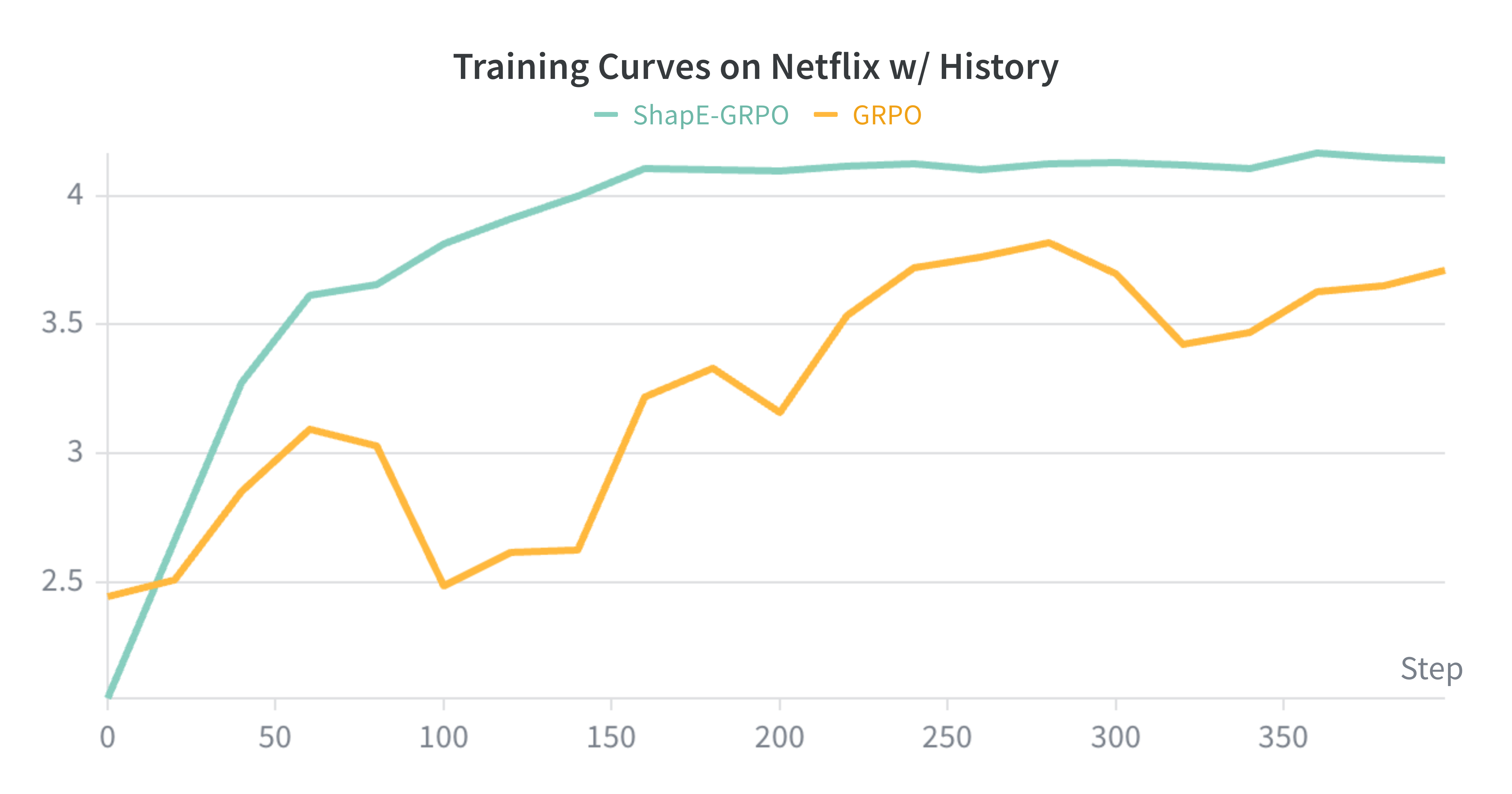
Figure 2: (Left) Candidate length coefficient of variation (CV) distributions for summarization; (Right) Training curves on Netflix recommendations—ShapE-GRPO converges faster and with more stability than GRPO.
Empirical Evaluation
Experimental Design
Experiments are conducted on Qwen3-8B and Llama3.1-8B-Instruct across three core settings:
- Aspect-Based Scientific Summarization (ACLSum): Multi-candidate summaries, reward from LLM-as-judge protocol (GPT-5.2) normalized to [0,1].
- Data Science Code Suggestion (DS-1000): Four candidate solutions per prompt, binary reward (success if any passes tests).
- Movie Recommendation (Netflix): Four candidate recommendations per user, explicit user history as context, reward is ground-truth rating.
Ablations include comparison to GRPO and Winner-Takes-All reward assignment. For Netflix, variants with and without user history are included. Evaluation measures are reward averages on held-out sets.
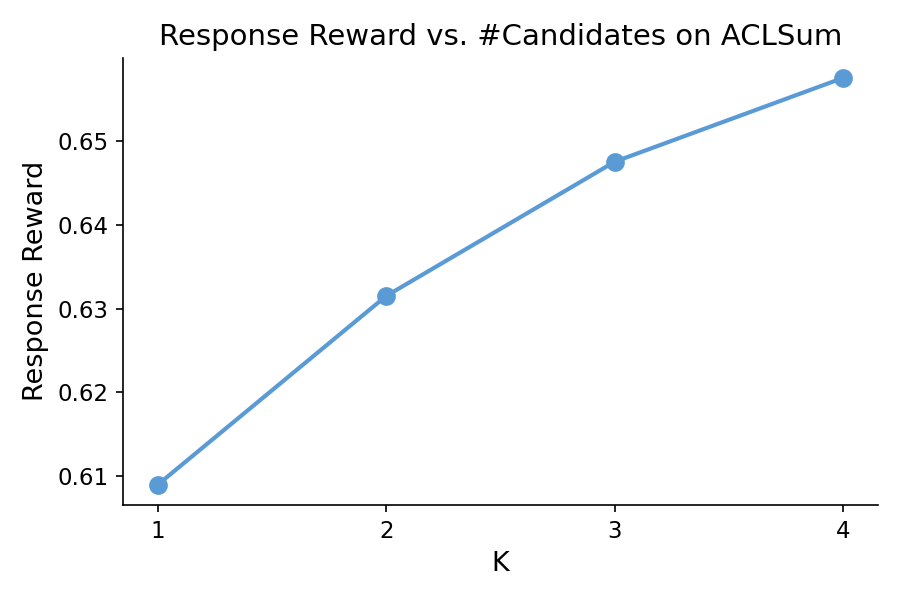
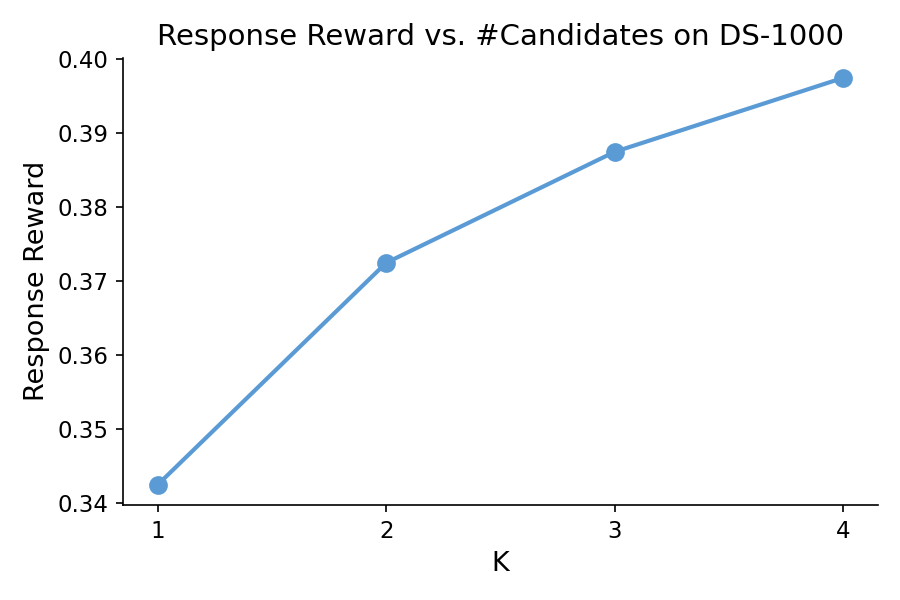
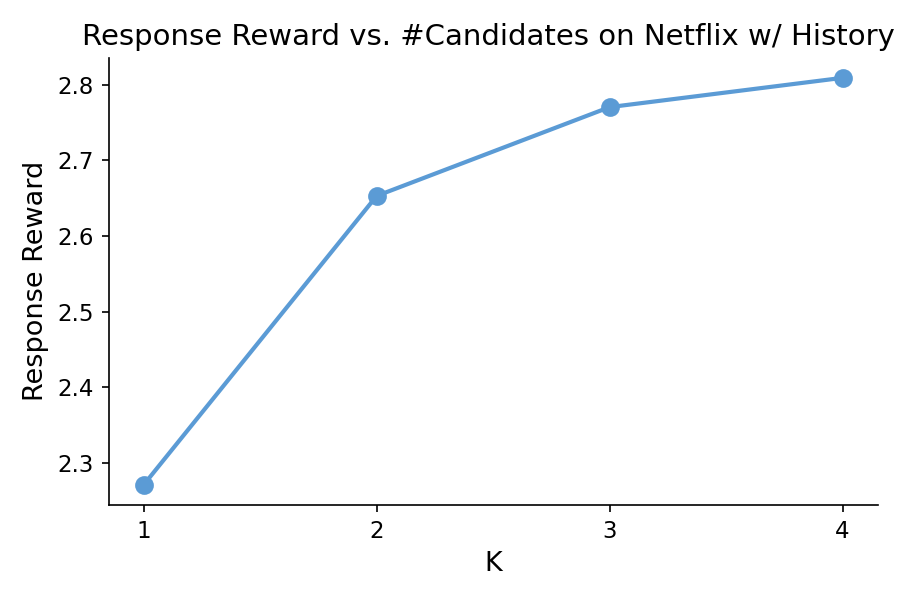
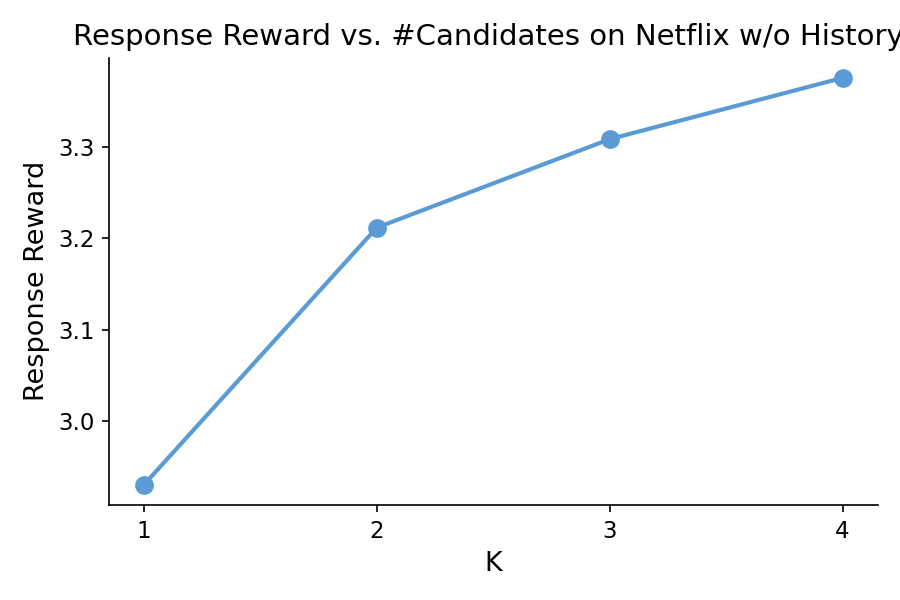
Figure 1: Response reward as a function of the number of candidates across datasets using Qwen3-8B, illustrating diminishing returns as K increases.
Main Results
ShapE-GRPO yields consistent advancement over both standard GRPO and WTA across all tasks. Notably:
- ACLSum: ShapE-GRPO improves from 0.658 (GRPO) to 0.672; Winner-Takes-All actually falls below the baseline (0.642).
- DS-1000: From 0.465 (GRPO) to 0.510 (ShapE-GRPO).
- Netflix w/ history: Substantial lift from 3.710 (GRPO) to 4.141 (ShapE-GRPO) on the normalized rating scale.
- Training Dynamics: On Netflix, ShapE-GRPO converges in about 160 steps (compared to 240 for GRPO), and exhibits much lower reward variance across checkpoints (see Figure 2, right).
Such empirical findings robustly support the claim that fine-grained, coalition-aware reward assignment at the candidate level both accelerates post-training convergence and yields stronger, more stable models for real-world RLHF tasks with set-valued feedback.
Theoretical and Practical Implications
The adoption of ShapE-GRPO carries several downstream consequences:
- RLHF for Set-Level Metrics: Many real-world tasks (shopping, movie recommendation, brainstorming, code suggestion) benefit from set-level feedback, not sequence-level. Traditional pipelines are sample-inefficient and bias-prone in these domains; ShapE-GRPO closes this gap.
- Diversity and Exploration: By aligning the reward with marginal utility, the algorithm implicitly encourages diverse candidate outputs; adding a redundant candidate yields little or negative reward, guiding the model to expand coverage.
- Computational Scalability: The polynomial runtime for candidate-level Shapley computation means ShapE-GRPO is deployable for online and large-scale scenarios—this is not generally true for token-wise Shapley allocation.
- Generalization: Experiments on models with and without access to user history underline difficulties with long-context utilization. Methods like ShapE-GRPO may synergize with architectural enhancements for context compression or retrieval-augmented generation.
- Axiomatic Soundness: Strong theoretical guarantees prevent reward allocation pathologies (free-riding, reward hacking), making the method principled for practical integration into RLHF, RL-augmented recommendation, and ideation systems.
Future Directions
Open research questions include exploration of alternative coalition value measures (e.g., instrumental value), application to unsupervised and gradient-based reward estimation protocols, and extension to scenarios with partial or noisy reward models. Analyzing interaction with techniques for long-context understanding and inference within LLMs is also of interest.
Conclusion
ShapE-GRPO provides a mathematically principled, computationally efficient, and empirically validated mechanism for reward allocation in multi-candidate LLM post-training (2603.29871). By exploiting cooperative game theory and the permutation-invariant structure of set-level feedback, it addresses core deficiencies of sequence-level RLHF and establishes a new baseline for efficient, robust, and scalable LLM-as-a-recommender pipelines. These findings motivate broader adoption of coalition-aware reward design and open up new lines of inquiry on advanced credit assignment for RL-based training of generative models.