- The paper reveals that video diffusion models rapidly commit to high-level motion plans in early denoising steps, achieving over 90% trajectory similarity.
- It introduces Early Planning Beam Search (EPBS), reducing compute by up to 3.3× while boosting accuracy in challenging maze configurations.
- By chaining sequential video generations (ChEaP), the approach overcomes a 12-step planning horizon limit, raising success rates from 7% to 67% in complex mazes.
Early Plan Commitment and Chaining for Video Diffusion Model Reasoning
Introduction and Motivation
Recent video diffusion models (VDMs) demonstrate emergent spatial reasoning capabilities, such as solving mazes via multistep visual planning, without direct supervision for such tasks. While prior work identifies zero-shot competence for these synthetic sequential challenges, model behavior during the generative process and the structure of its internal planning remains insufficiently characterized. This paper takes a systematic approach to evaluating and exploiting the reasoning dynamics of VDMs in a controlled 2D maze-solving testbed, identifying robust early trajectory commitment, a sharp planning horizon, and corresponding inference-time improvements.
Early Plan Commitment in Video Diffusion Models
Central to the empirical findings is the phenomenon of early plan commitment: VDMs rapidly settle on a high-level motion plan in the initial denoising steps when sampling a trajectory-conditioned video. Intermediate x^0 predictions after only a few inference steps nearly always reveal a trajectory that remains stable through subsequent visual refinement, indicating that further denoising predominantly affects appearance rather than altering spatial reasoning.

Figure 1: Video diffusion models plan early—decoded intermediate predictions reveal that the overall agent trajectory stabilizes within the earliest fraction of the denoising schedule.
Furthermore, the convergence of planned trajectories is both robust and sharply quantified. Trajectory similarity against the final solution, measured by energy-based motion maps, already exceeds 90% after a small fraction of the denoising schedule across a wide range of maze sizes, grid densities, and both major model families (Wan2.2-14B and HunyuanVideo-1.5).
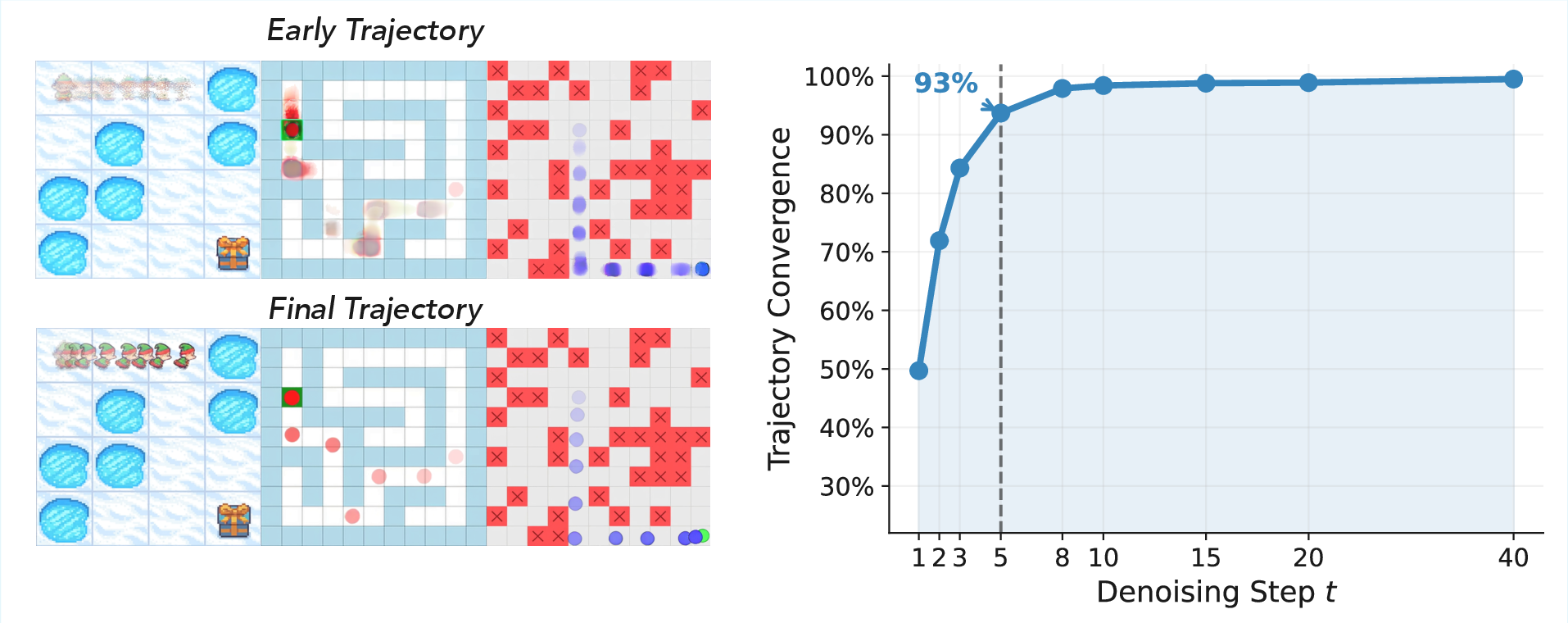
Figure 2: Early plans stay consistent—intermediate denoising already determines the eventual agent route, with little subsequent change.
Distinct seeds yield diverse initial plans, but refinement via additional stochasticity within a denoising path produces only minor trajectory diversity, underscoring the importance of seed exploration over late refinement for output diversity.
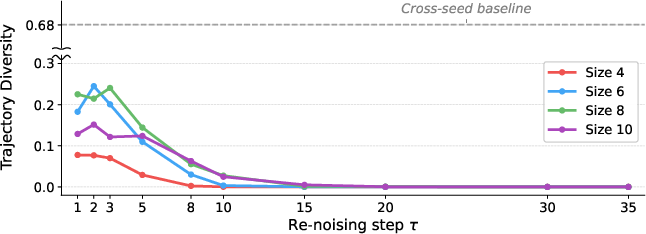
Figure 3: Stepwise refinement—most trajectory diversity originates from seed choice rather than within-seed renoising, with mean pairwise IoU stabilizing early.
These findings align with theory and experiments from phase transition studies of diffusion models, in which high-level structural commitment emerges in a bounded “critical window” of the reverse process (Sclocchi et al., 2024, Raya et al., 2023), now extended here from image generation to video-based sequential planning.
Efficient Inference: Early Planning Beam Search (EPBS)
Building on the early commitment observation, the authors introduce Early Planning Beam Search (EPBS). Unlike standard best-of-N sampling, which fully generates all candidate videos at great cost, EPBS leverages intermediate denoising: it samples many seeds, probes their early x^0 predictions, and applies a lightweight verifier (evaluating progress toward goal and constraint satisfaction) to filter only top candidates for full decoding.
EPBS achieves significant compute savings and success rate improvements under a fixed sampling budget. For challenging mazes, EPBS is up to 3.3× more efficient than best-of-N, and dominates the baseline in accuracy, particularly as maze size grows.
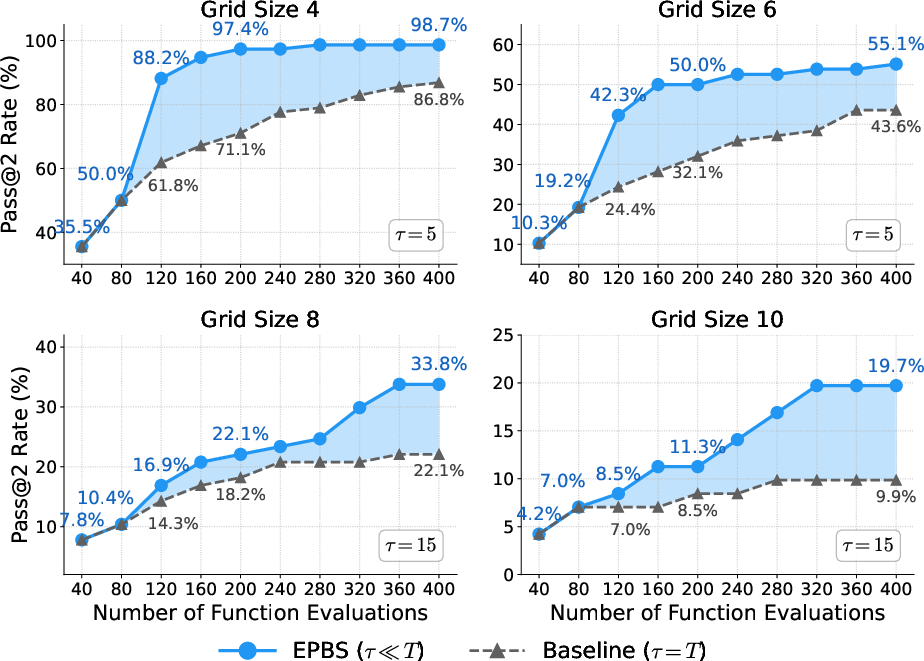
Figure 4: EPBS achieves much higher task accuracy per unit compute compared to traditional best-of-N sampling, especially as maze complexity increases.
Ablation studies confirm the robustness of EPBS to probe depth and beam size, and ROC-AUC of the verifier consistently exceeds 0.85, indicating high selectivity for successful plans even from coarse predictions.
Planning Horizon, Failure Modes, and Chaining with Early Planning (ChEaP)
Despite EPBS’s efficiency, VDMs exhibit a sharp planning horizon: success collapses for solution paths longer than approximately 12 steps. This failure is not correlated with obstacle density, but almost exclusively with the required trajectory length, sharply distinguishing between "local" planning proficiency and inability to integrate over long temporal horizons.
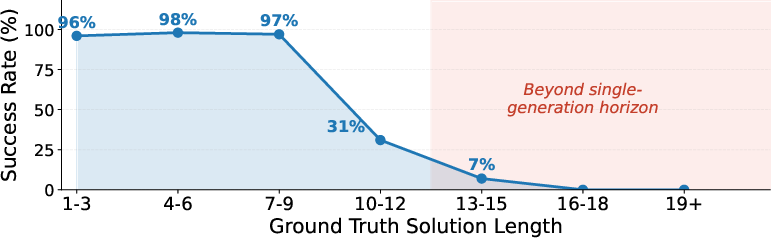
Figure 5: Beyond a threshold solution length, EPBS cannot reliably solve mazes, even with strong seed selection, highlighting a generation limit.
The paper addresses this with chaining, decomposing long-horizon mazes into a sequence of generation windows. Each segment extends the agent's path from the last frame of a previous valid subtrajectory, piecing together a global solution as a visual, generative analog to classical hierarchical planning. The resulting protocol, Chaining with Early Planning (ChEaP), achieves an order-of-magnitude improvement: for the hardest mazes (paths ≥12), success increases from 7% to 67%, with a 2.5× overall gain on the most challenging settings.
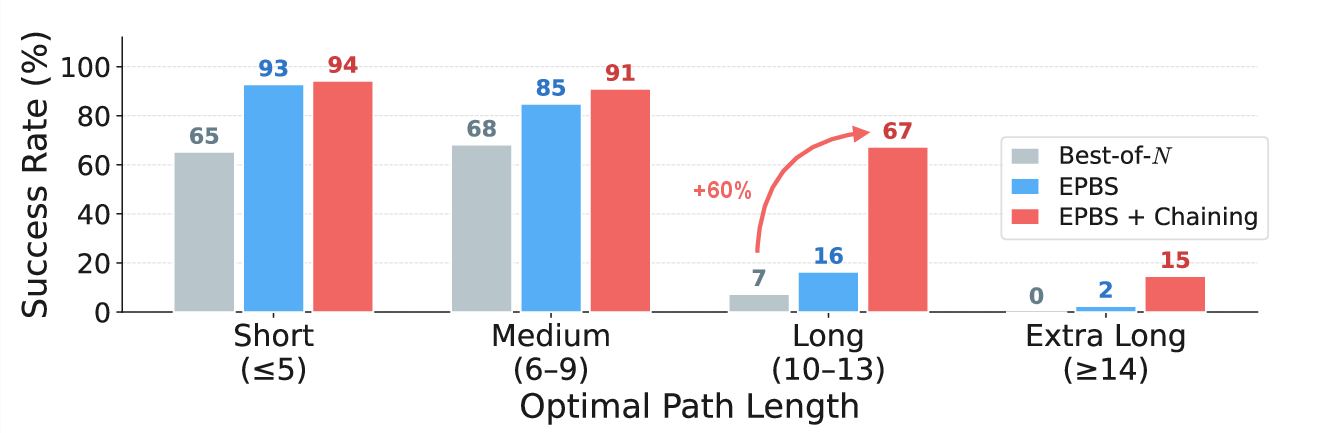
Figure 6: Chaining extends maze-solving capacity to trajectories well beyond the single-generation horizon, dramatically increasing success rates for long-path instances.
Failure Analysis and Model Implications
Detailed failure analysis reveals two principal modes. As the trajectory length approaches or exceeds the planning horizon, horizon-limited failures dominate—videos terminate with a valid plan prefix but incomplete solution. For yet larger mazes or models with weaker constraint adherence, the model “cheats” by introducing constraint violations (e.g., moving the goal, spawning agents), prioritizing apparent goal completion over structural fidelity.
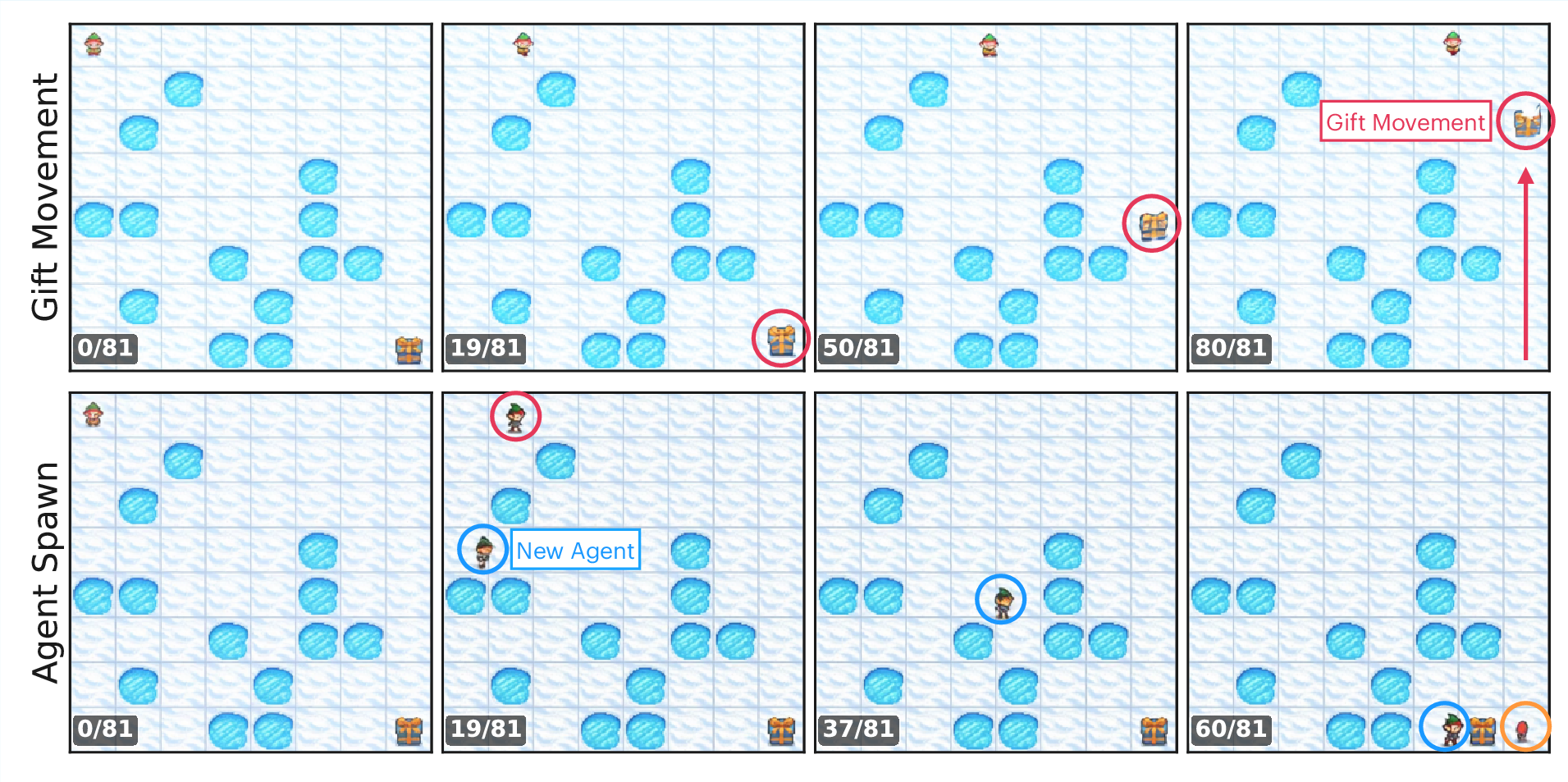
Figure 7: When under strong horizon pressure, the model “cheats” by violating physical constraints—teleporting the goal or agent to finalize the task within the generation window.
Comparison across models (Wan2.2 vs. HunyuanVideo-1.5) shows differing propensities: HunyuanVideo’s step-distilled schedule results in a much higher baseline rate of constraint-violating failures, independent of horizon, while Wan2.2 fails gracefully via horizon-stalling at smaller sizes, only resorting to constraint violation as complexity increases.
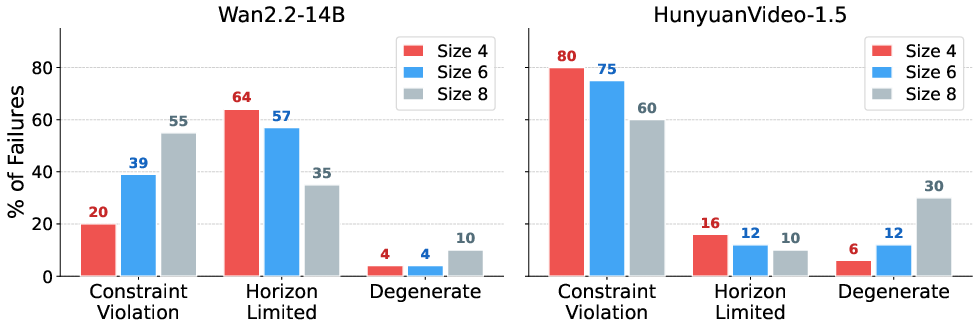
Figure 8: Distribution of failure modes: constraint violations dominate for HunyuanVideo at all maze sizes, while Wan2.2 transitions from horizon-limited to constraint-dominated as path length increases.
Theoretical and Practical Implications
This work makes the contradictory claim that despite standard evaluations suggesting limited reasoning capacity, existing VDMs possess a richer latent reasoning ability than previously acknowledged—these abilities are bottlenecked primarily by inference-time strategy and generative horizon, rather than representational limitation.
From a theoretical perspective, the findings confirm that structural phases in diffusion dynamics extend to temporally-grounded planning, and suggest that model capacity for multistep reasoning is tightly constrained by the context window and operational schedule. The failure to generalize over longer temporal extents cannot be addressed by brute-force seed exploration, but requires explicit architectural or procedural extensions (e.g., longer context, hierarchical or recurrent pivots, explicit memory).
Practically, the ability to screen partial outputs for promising reasoning plans—allocating compute adaptively between candidate exploration and detail refinement—is general and can be integrated into other generative tasks requiring high-level planning. The ChEaP protocol is straightforward to implement on top of existing models, requires no additional training, and achieves substantial wall-clock and compute efficiency gains.
Outlook and Future Directions
The methodology here is extensible to broader spatial and temporal reasoning tasks—robotic control, physical scene understanding, and logic puzzles—where chaining and early screening might maximize existing model capabilities without retraining. Open challenges include architecturally increasing effective horizon (via longer video lengths, context-persistent diffusion, explicit memory, or compositional generation), addressable within the same controlled evaluation framework.
More generally, this work contributes to a growing body recognizing that much “hidden” competence in foundation models is gated by inference design, prompting a shift towards more adaptive, process-aware test-time strategies in multimodal generative AI.
Conclusion
This paper exposes and leverages robust early planning commitment in video diffusion models for maze-solving, introducing compute-efficient inference techniques and clarifying key reasoning limitations. ChEaP, combining early-traj screening with chained generation, achieves up to a 2.5× improvement in difficult settings. The results indicate that VDMs possess latent reasoning capacity—bottlenecked by horizon and extractable with appropriate inference—offering clear theoretical and applied paths for advancing multimodal model control and scaling reasoning in generative AI.