- The paper shows that although DeepSeek-R1 data achieves lower SFT loss, its divergent reasoning patterns lead to inferior generalization compared to convergent gpt-oss-120b trajectories.
- The token-level analysis reveals that a thicker tail of high-loss tokens in gpt-oss-120b data correlates with critical deductive steps, enhancing model learning.
- The study demonstrates that filtering out redundant, branching reasoning steps can improve model accuracy by up to 5.1% on mathematical benchmarks.
Reasoning Patterns, Redundancy, and Generalization in Long Chain-of-Thought SFT
Introduction
This paper interrogates the effect of reasoning patterns in teacher-generated Chain-of-Thought (CoT) trajectories on the generalization capabilities of student LLMs during supervised fine-tuning (SFT), focusing on mathematical benchmarks. Leveraging a tightly controlled experimental protocol, the authors compare two widely used sources of CoT supervision signals—DeepSeek-R1-0528 and gpt-oss-120b—using strictly verified trajectories for identical problem sets. The analysis reveals a counterintuitive decoupling: lower SFT training loss does not correspond to better generalization when the underlying trajectories embody divergent, highly exploratory reasoning, as seen in DeepSeek-R1-0528, in contrast to more convergent, deductive patterns prevalent in gpt-oss-120b data. This observation motivates a comprehensive investigation of the structural and behavioral attributes of the reasoning data, culminating in a proposed filtering intervention that significantly enhances downstream reasoning generalization.
Empirical Foundations: Decoupling of SFT Loss and Generalization
The study employs four distinct base models (Qwen2.5-7B, Qwen2.5-32B, Llama3.1-8B, Qwen3-8B) fine-tuned on equivalent, correct CoT trajectories from both teachers. Rigorous evaluation on mathematical reasoning tasks (MATH500, AIME24/25, BeyondAIME, HMMT25), controlling for length and training steps, exposes consistent generalization superiority of the gpt-oss-120b-based models—even as the corresponding SFT loss is higher than for DeepSeek-R1 (see Figure 1).
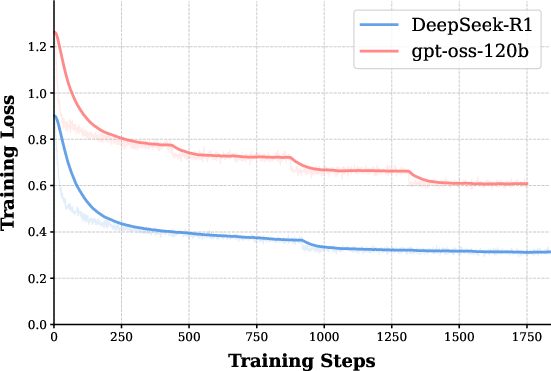
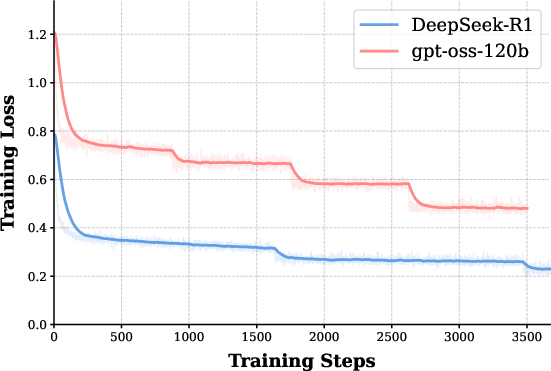
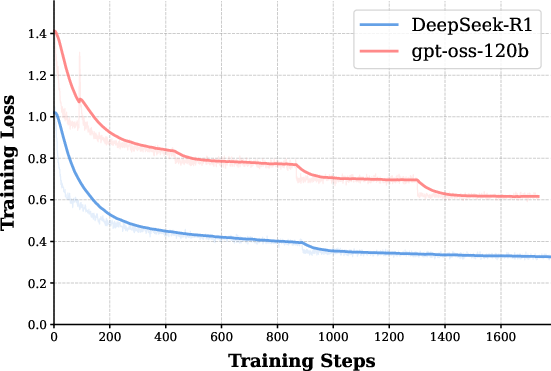
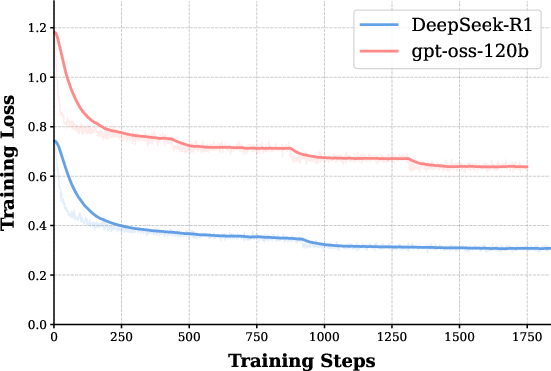
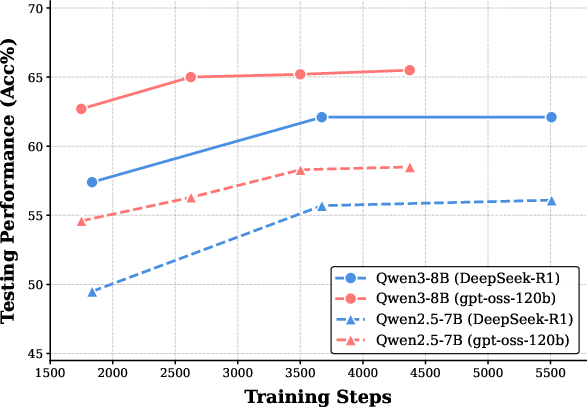
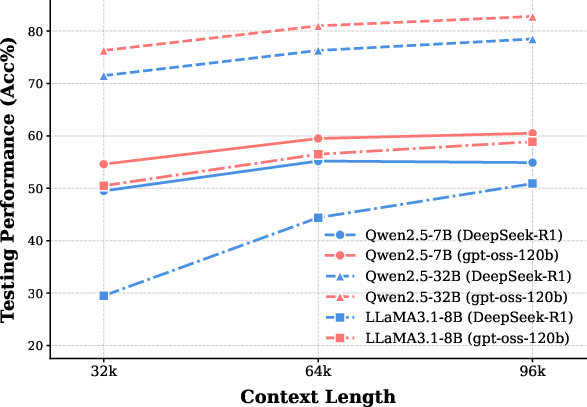
Figure 1: SFT training loss curves for Qwen2.5-7B; DeepSeek-R1 data drives the loss to lower values than gpt-oss-120b.
Despite significantly lower training losses for DeepSeek-R1-tuned students, these models demonstrate notably inferior accuracy across benchmarks. The phenomenon is robust across architectures, context limits, and even when prolonging training to ensure saturation. The findings rule out undertraining and length truncation as confounders: what matters is not merely getting the answer right, but the structural and semantic properties of the reasoning paths that guide the model's internalization.
Token-Level Analysis: Long-Tail Signal Distribution
Decomposition of token-level losses indicates that SFT optimization is driven by a minority of high-loss tokens, primarily reflecting structural transitions or pivotal logical steps, rather than routine computational operations. This long-tail phenomenon persists post-SFT:
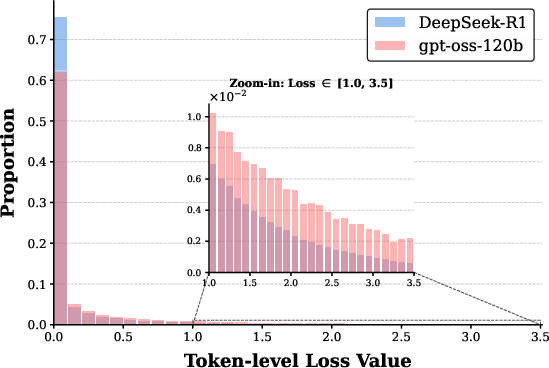
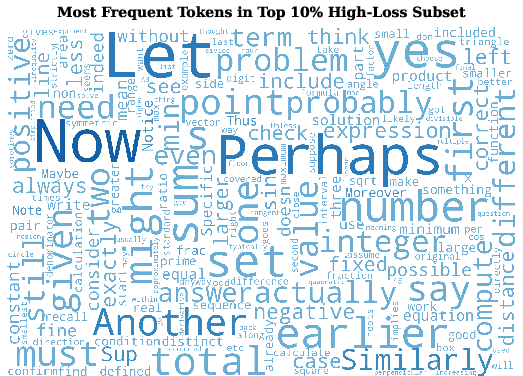

Figure 2: Qwen3-8B’s token-level loss distribution after SFT; the long tail reflects critical reasoning transitions, with gpt-oss-120b data displaying a thicker tail.
DeepSeek-R1-0528 data inflates the head of the loss distribution with non-informative, “routine” tokens. The concentration of high-loss (thus cognitively salient) tokens is lower in DeepSeek-R1, diluting the training signal necessary for robust logical generalization. Analysis of token semantics underscores that in gpt-oss-120b data, difficult tokens are associated with convergent deductions (e.g., "Thus", "yields"), while DeepSeek-R1’s difficult tokens more often trigger detours or speculative branches (e.g., "Perhaps", "Another", "Alternatively").
Structural Patterns and Behavior: Branching Versus Deduction
At the trajectory level, reasoning step annotation (using a coarse taxonomy: Propose, Deduce, Verify, Backtrack) reveals that DeepSeek-R1 heavily privileges divergent, branching exploration at the expense of sustained deduction:
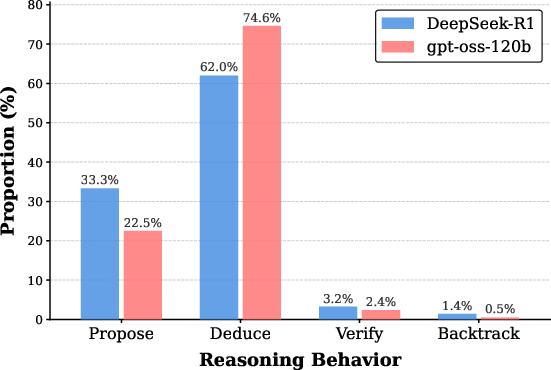
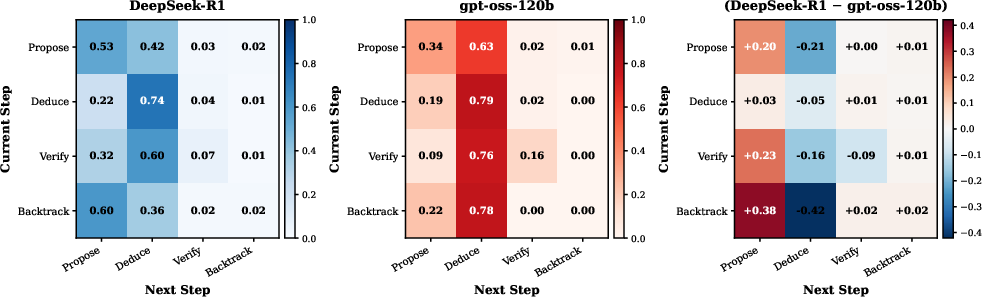
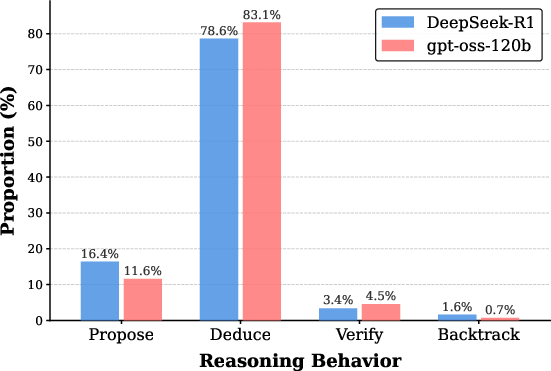
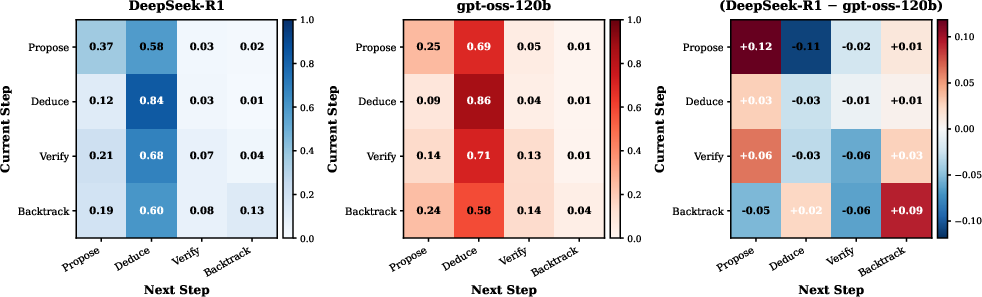
Figure 3: Distribution of reasoning behavior types in the training data; DeepSeek-R1 exhibits an elevated Propose ratio.
This divergent bias is quantifiable in both behavior proportions and transition matrices; DeepSeek-R1 shows frequent Propose→Propose transitions, while gpt-oss-120b is marked by extended Deduce chains. Critically, SFT transfers these higher-order patterns—models distilled on divergent data inherit the tendency to branch excessively, expending context budget on unproductive exploratory segments, which function as structural redundancy and impair convergence on correct answers.
Redundancy Diagnostics: Random Deletion Ablations
To directly probe this redundancy, the authors perform random deletion of reasoning steps in the supervision data. Performance is robust—or, in some cases, even improved—when up to 10–20% of DeepSeek-R1 steps are deleted, whereas similar manipulation of gpt-oss-120b data degrades accuracy sharply. This asymmetry substantiates that DeepSeek-R1's exploratory branches are, from a learning standpoint, often functional deadweight.
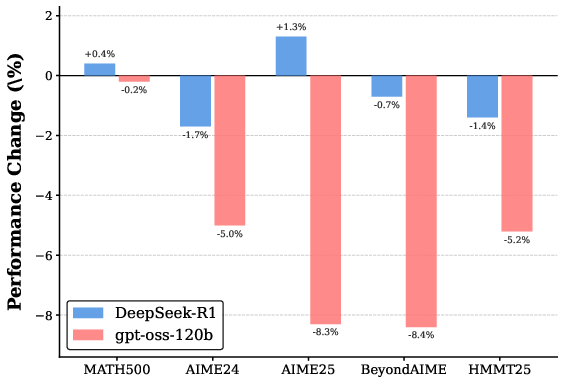
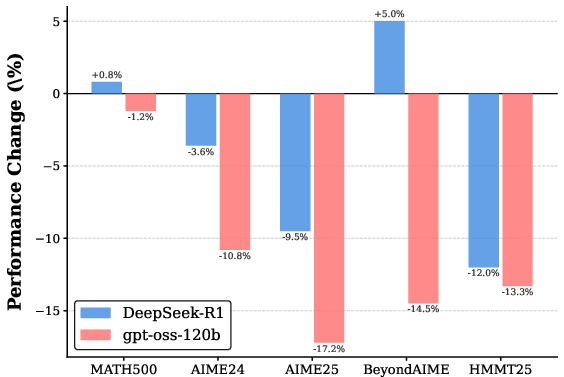
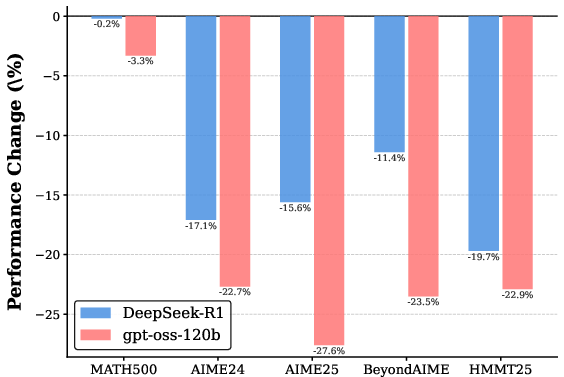
Figure 4: Performance change for Qwen3-8B on five benchmarks after deleting 10% of reasoning steps per trajectory, highlighting robustness of DeepSeek-R1-tuned models to such perturbation.
Data Filtering Interventions: Empirical Efficacy
Building on these insights, the authors propose supervised data filtering strategies targeting high-redundancy trajectories (as estimated via behavior proportions or step counts relative to paired gpt-oss-120b traces). Removing the top quantiles of most branching trajectories yields consistent, sometimes substantial improvements—up to 5.1% accuracy gain on AIME25 and 3.6% averaged across five tasks, with ablation controls demonstrating that gains are not simply an effect of reducing sequence length.
Theoretical and Practical Implications
This systematic study brings structural transparency to the long-CoT distillation pipeline. Theoretical implication: reasoning generalization is determined not by raw answer correctness or local loss, but by the inductive biases embedded in the higher-order topology of reasoning traces. Practically, careful curation—emphasizing deep, convergent trajectories and filtering out frequent branching—yields more effective student models, even when the underlying trajectory labels remain equally “correct” (per SFT verification).
The findings intersect with emergent lines of research in the graph-theoretic analysis of LLM reasoning (2604.01702) and reinforce the value of structural, not just semantic alignment in teacher-student SFT. For model builders, the work provides actionable heuristics: select SFT trajectories not solely based on answer correctness, but optimizing for deduced chains with minimal exploratory redundancy, thereby promoting efficient generalization and scalable reasoning.
Future Directions
While the study is focused on mathematical domains, its methodological apparatus—including step-level annotation, Markov transition modeling, and redundancy-regularized SFT—stands to inform broader classes of reasoning tasks such as code generation, scientific question answering, and agentic decision making. Generalization to new domains and additional LRM architectures is indicated as an important future direction.
Conclusion
This work articulates, via rigorous behavioral and structural analysis, that the reasoning patterns within CoT supervision data are major determinants of generalization in Long CoT SFT. Divergent, branching-heavy exploration—despite enabling lower SFT loss and answer correctness—is antithetical to robust logical generalization. Strategic filtering of redundancy produces models that are more deductive and generalize better, offering concrete advances for distillation protocols in LLM development.