- The paper presents a unified world-action model that integrates explicit 3D depth, video, and action generation via a modular, cross-attention transformer.
- It introduces a depth-to-video-to-action causal cascade that significantly improves planning accuracy and safety for autonomous driving.
- Ablation studies demonstrate that combining geometric grounding with LLM-powered reasoning yields state-of-the-art performance on Navsim benchmarks.
Geometry-Grounded World–Action Modeling for Autonomous Driving: An Expert Analysis of DriveDreamer-Policy
Introduction and Motivation
DriveDreamer-Policy addresses major deficiencies in unified World–Action Models (WAMs) for autonomous driving: the lack of explicit geometric grounding and the requirement for interpretable, causally structured future imagination. Prior WAMs have largely focused on 2D appearance-based or latent representations, often at the expense of actionable safety-critical context such as 3D geometry and explicit depth. This work introduces a modular architecture that leverages a LLM to encode language instructions, multi-view observations, and action context, coupled with three diffusion-based generative experts: a pixel-space depth generator, a latent-space video generator, and an action planner. The model's hallmark is its causally ordered information flow—depth → video → action—which ensures geometric knowledge scaffolds both future video imagination and downstream planning.
Model Architecture
DriveDreamer-Policy's system structure couples LLM-mediated perception and reasoning with three modality-specific generative experts mediated through cross-attention over dedicated query slots. The architecture enforces a causal attention mask, such that video queries read depth context, and action queries aggregate both depth and video context. This is operationalized as fixed-size depth, video, and action query tokens injected into the transformer backbone. The model admits flexible operation, supporting planning-only, imagination-augmented planning, and full offline world/simulation generation modes.
The depth generator is a pixel-space diffusion transformer trained with a conditional flow-matching objective. Conditioning is injected via cross-attention from the LLM's depth query embeddings, supporting explicit 3D world modeling. The video generator is a latent-space diffusion transformer, grounded both in current visual observations (via VAE encoding and a CLIP-based visual condition) and in the LLM's video query embeddings, the latter inheriting upstream geometric context. The action generator is a lightweight diffusion transformer mapping noise trajectories to action sequences, conditioned on action query embeddings formed by LLM integration of all available context.
DriveDreamer-Policy demonstrates strong performance on Navsim v1/v2, surpassing or equaling the best-in-class models across all considered planner and generative metrics. Critical results include 89.2 PDMS on Navsim v1 and 88.7 EPDMS on Navsim v2, setting a new empirical benchmark for unified world–action methods under comparable input regimes and computational budgets.
For future video generation, the model achieves an FVD of 53.59, outperforming PWM's 85.95—a substantial margin validating the integration of explicit depth priors. In depth prediction, DriveDreamer-Policy records an AbsRel of 8.1 and δ1 of 92.8, outperforming both zero-shot and fine-tuned backbone models serving as initializations.
Ablation studies reveal that training with both depth and video (“depth+video+action”) produces maximum gains in planning robustness, evidencing that depth serves as an indispensable scaffold for physically consistent imagination and safe decision making. Joint learning (with causal conditioning) consistently enhances video FVD and trajectory planning (PDMS), with additional capacity (more query slots) further improving downstream performance.
Qualitative Analysis
Spatially stable depth and video generations, as depicted in the results, visually confirm coherent geometric structure and scene dynamics compatible with human driving patterns (Figure 1).
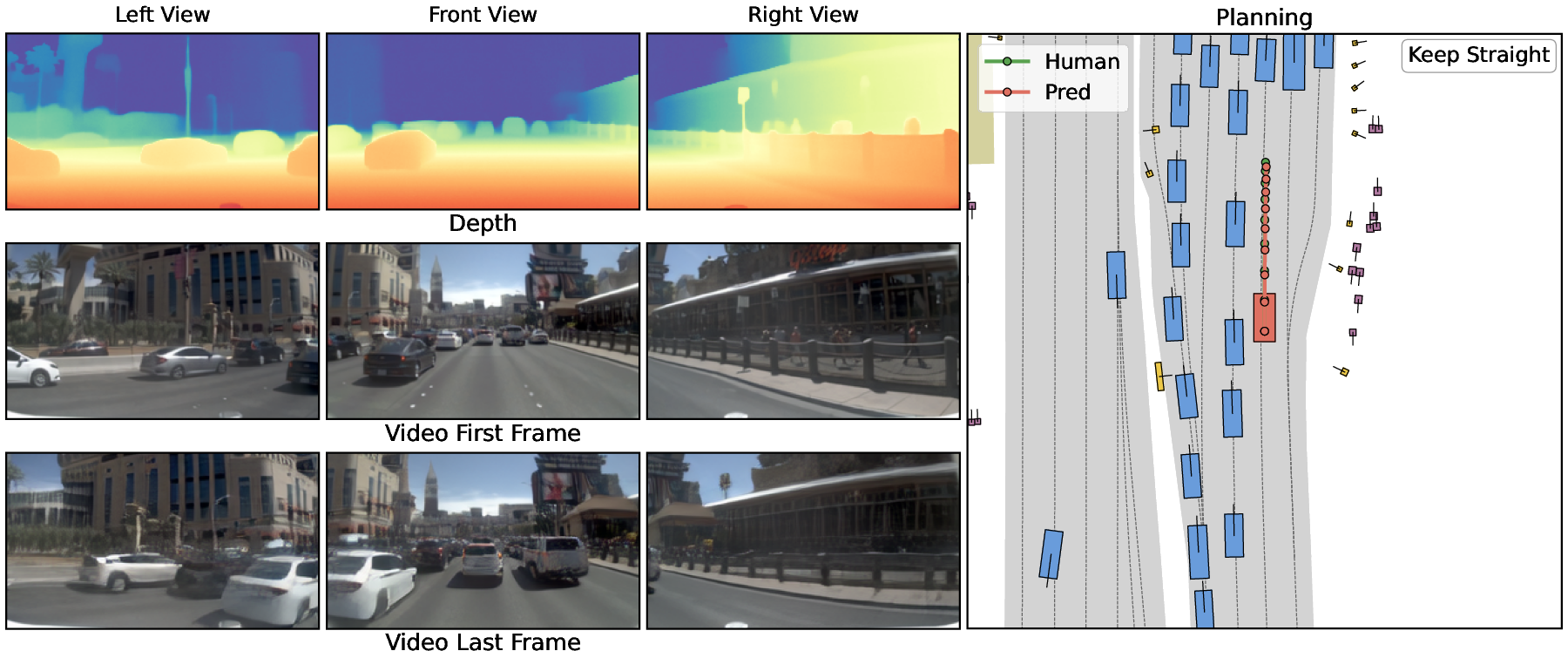
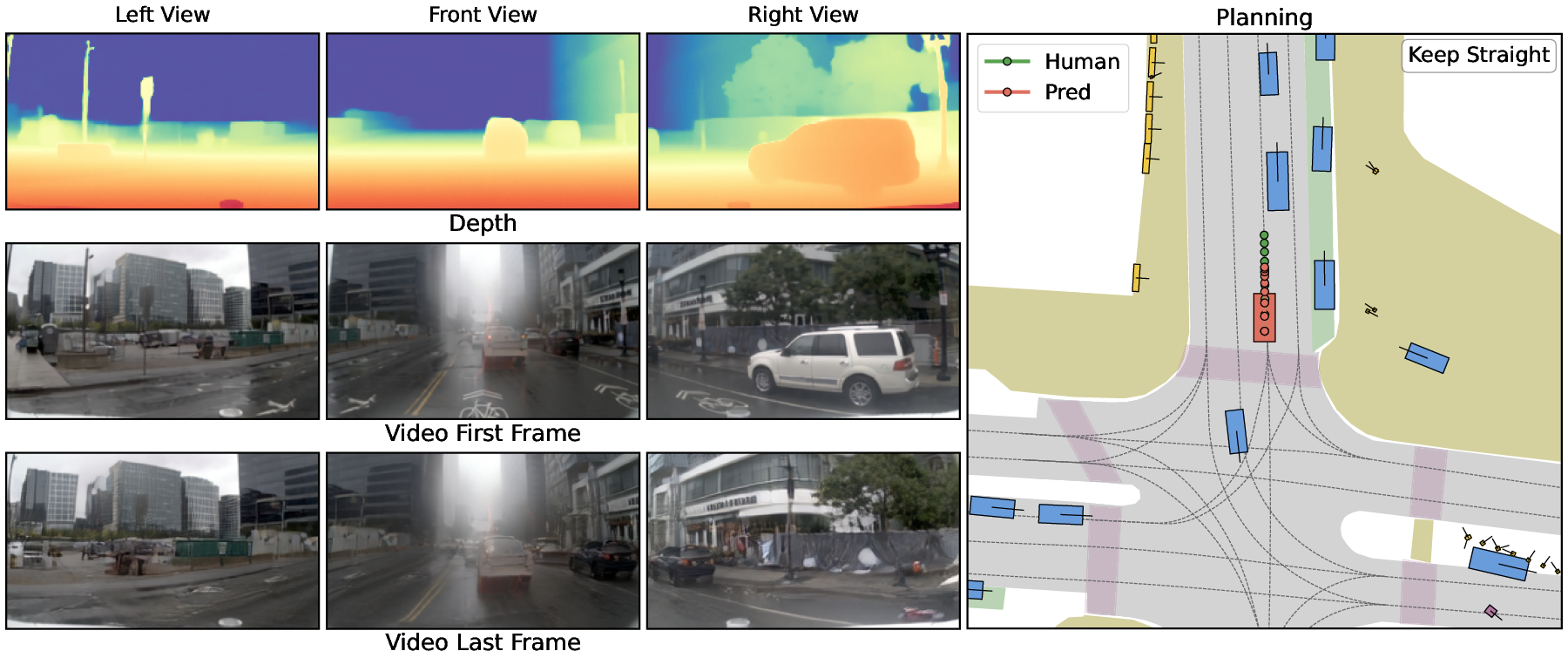
Figure 1: Model outputs remain spatially and temporally stable; imagined depth, future video, and planned trajectories are well-aligned with ground-truth human driving trajectories.
Ablation visualizations expose the tangible benefits of each modality: action-only baselines are prone to unsafe behaviors (drift, erratic recovery), while incremental addition of depth and video regularizes trajectories, enhances collision avoidance, and supports closer adherence to expert driving policy (Figure 2).
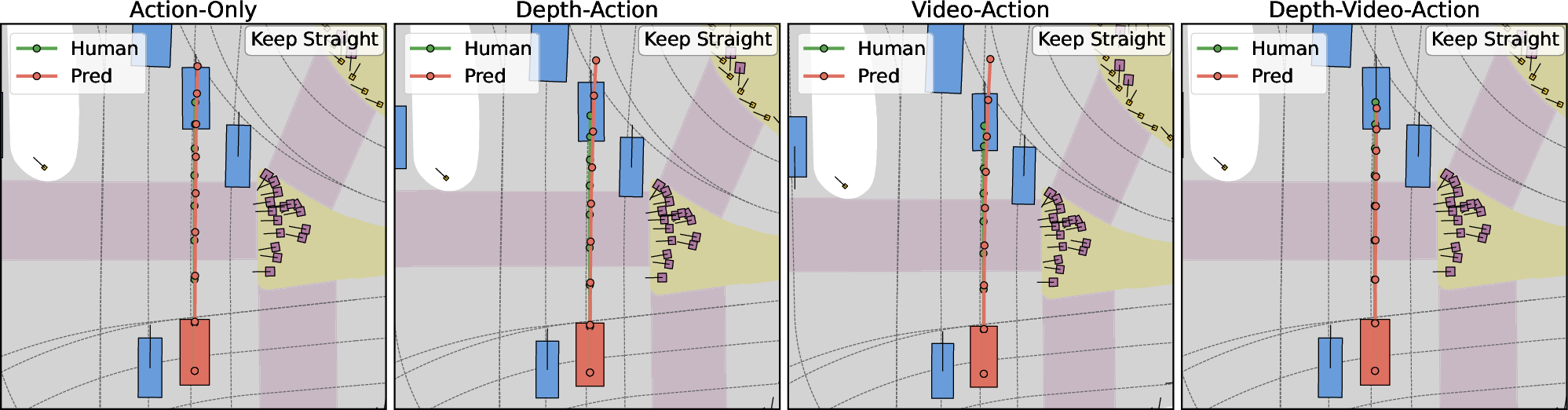
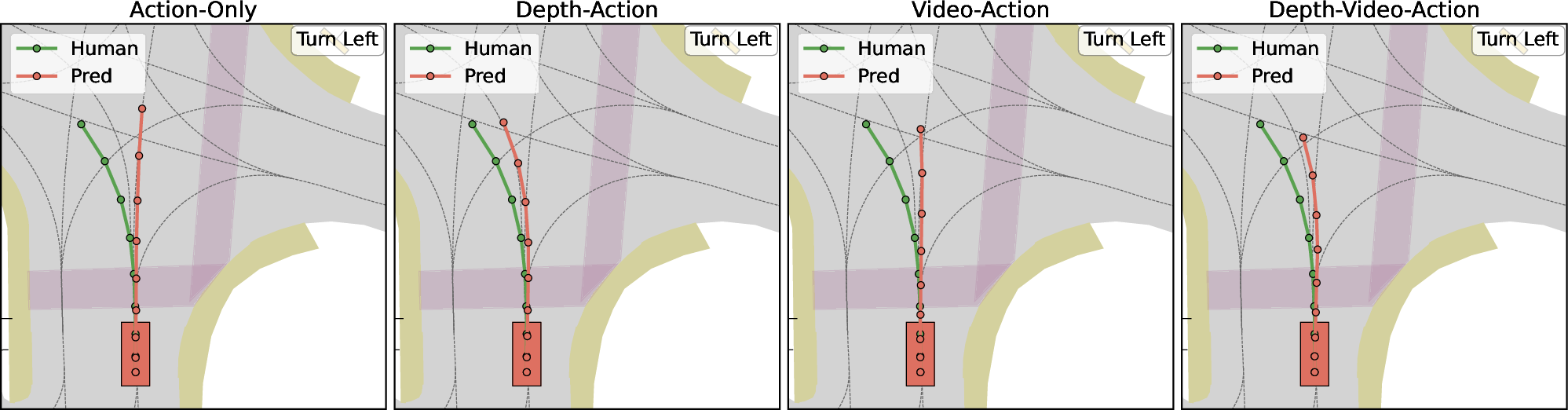
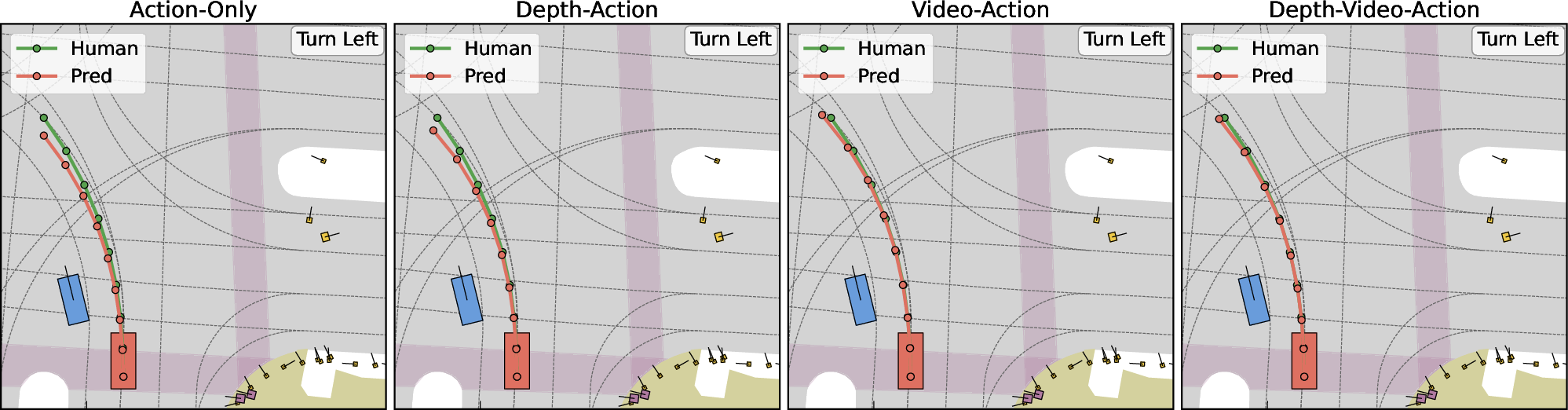
Figure 2: Comparing Action-only, Depth-Action, Video-Action, and Depth-Video-Action; incorporating explicit world cues (depth, video) yields substantially improved trajectory safety and alignment.
Implications and Future Directions
The introduction of explicit geometric grounding in unified world–action models marks a critical advance for safety-critical autonomous driving policy synthesis. By conditioning planning not only on 2D appearance or latent rollouts, but on physically meaningful 3D structure and its evolution, DriveDreamer-Policy substantially improves reliability and interpretability—key desiderata for real-world deployment. The modular, slot-based architecture permits controlled compute, isolation of generative routines for ablation or transfer, and selective invocation of imagination rollouts, supporting both efficient real-time planning and high-fidelity simulation/data generation.
Pragmatically, the demonstrated performance gains—robust safety margins, reduced planning error, improved video generation—strongly motivate broader adoption of geometry-in-the-loop architectures in both academic and industrial AV stacks. Theoretically, this work raises questions for future research: the optimal modality fusion path, how best to expand causally conditioned expert branches (e.g., semantic maps, occupancy grids), and how to scale such systems to longer horizons or higher-capacity LLMs with minimal additional cost.
Conclusion
DriveDreamer-Policy exemplifies the integration of LLM reasoning, explicit geometric scaffolding, and causally structured generative modeling for autonomous driving. Joint depth, video, and action generation in a depth → video → action cascade, implemented via modular cross-attention transformers, yields state-of-the-art results across planning and world simulation tasks. These results affirm the importance of geometry-aware imagination in unifying perception, prediction, and policy, and set a new baseline for further exploration of compositional and causally guided WAMs for embodied autonomous systems (2604.01765).

