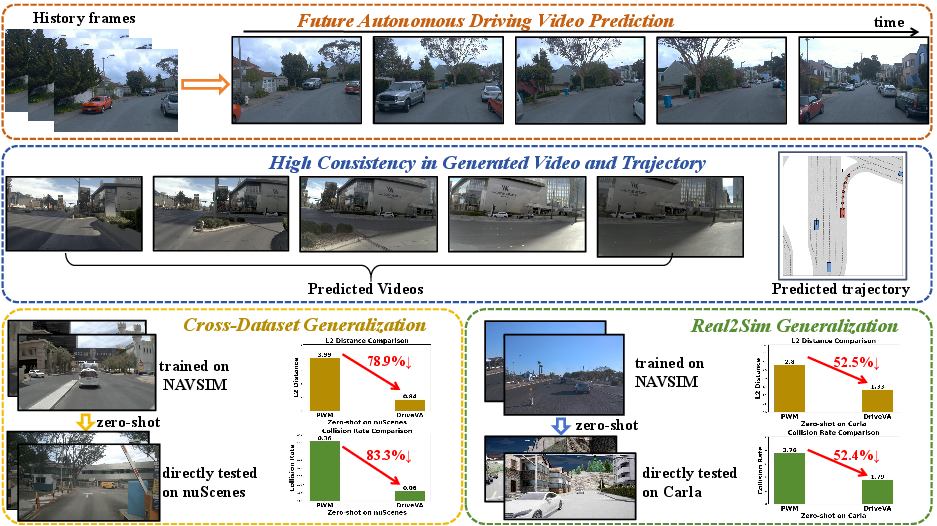
- The paper introduces DriveVA, a unified generative world model that simultaneously predicts future video and action trajectories for robust zero-shot autonomous driving.
- It employs a diffusion transformer backbone and conditional flow matching to ensure tight spatiotemporal alignment between imagined scenes and planned maneuvers.
- Empirical evaluations demonstrate significant reductions in L2 error and collision rates under cross-domain conditions, outperforming existing baselines in closed-loop scenarios.
Unified Video-Action World Models for Robust Zero-Shot Autonomous Driving: DriveVA
Introduction and Motivation
End-to-end generalization in autonomous driving systems across novel scenarios, diverse sensor domains, and environmental variations is a central challenge, largely due to the rarity and unpredictability of long-tail driving events and domain shift. Prevailing Vision-Language-Action (VLA) approaches leverage large-scale vision-language priors but are limited by their predominantly static-image pretraining and the lack of robust spatiotemporal modeling, resulting in suboptimal transfer to closed-loop planning and impaired zero-shot robustness. World model-based planning methods provide multi-modal future scene prediction and planning capabilities but typically employ decoupled visual imagination and trajectory generation. This architectural disconnect leads to poor alignment between generated videos and predicted actions, undermining planning reliability under distribution shifts.
In "DriveVA: Video Action Models are Zero-Shot Drivers" (2604.04198), a unified generative world model is introduced, referred to as DriveVA, which enables joint decoding of future visual and action rollouts, thereby aligning planned ego motion with generated future scenes and enhancing transfer and robustness for autonomous driving.
Model Architecture and Methodology
DriveVA leverages a DiT-based (Diffusion Transformer) backbone, initializing with spatiotemporal priors from a large-scale video generation model (Wan2.2-TI2V-5B), and integrates text and visual modalities in a causal VAE latent space to enable joint video-trajectory rollout for planning.
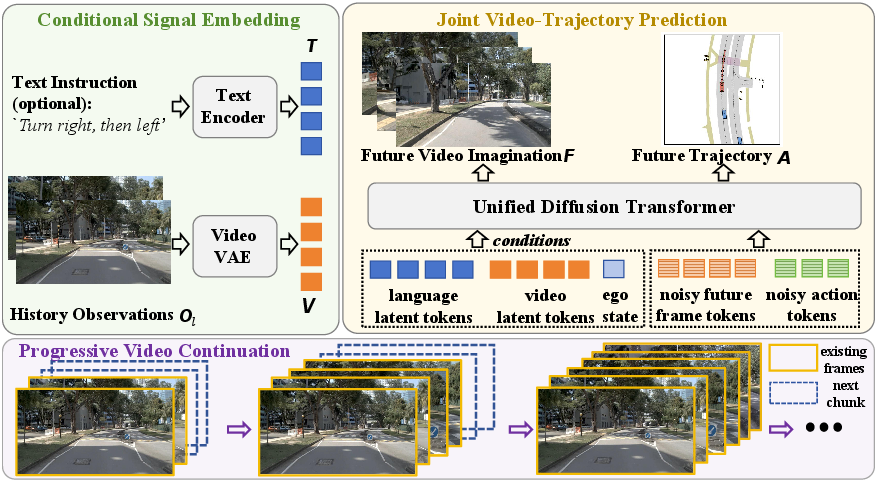
Figure 1: The DriveVA pipeline encodes historical observations, current velocities, and language instructions into a joint latent representation, enabling unified video and action generation via a diffusion transformer.
The model receives as conditional input a fixed-length buffer of previous egocentric video frames, language instructions, and instantaneous ego state (velocity components) (see Figure 1). History observations are encoded with the video VAE into latent tokens; the language instruction is encoded by a frozen text encoder. The DiT decoder jointly predicts the future video latent sequence and a sequence of action tokens corresponding to planned ego trajectory. This unified generative process ensures that the predicted trajectory is directly grounded in the visual scene evolution anticipated by the model, as opposed to being optimized in a sequential or loosely-coupled pipeline.
Key design aspects:
Empirical Evaluation
DriveVA is benchmarked in both closed-loop (NAVSIM) and zero-shot cross-domain (nuScenes, Bench2Drive/CARLA) scenarios. Key quantitative results:
- On NAVSIM, DriveVA achieves a PDMS score of 90.9, outstripping both traditional end-to-end and state-of-the-art world model baselines, despite using only front-view images as input (outperforming multimodal baselines that incorporate LiDAR and additional views).
- Zero-shot transfer: When trained solely on NAVSIM and directly evaluated on nuScenes and Bench2Drive without target domain finetuning, DriveVA reduces average L2 error by 78.9% and collision rate by 83.3% (nuScenes) and by 52.5% and 52.4% (Bench2Drive) relative to PWM [zhao2025forecasting], the leading world model-planner baseline. In several cases, DriveVA surpasses in-domain finetuned baselines on nuScenes, an assertive result indicating strong intrinsic generalization from unified video-action modeling even in starkly out-of-distribution conditions.

Figure 3: In zero-shot transfer, DriveVA-predicted trajectories remain geometrically consistent with generated scene evolution, unlike PWM, which exhibits video-action mismatch (e.g., planning straight while imagining left-turn).

Figure 4: Zero-shot generalization on nuScenes—DriveVA's trajectories remain consistently aligned with anticipated visual evolution, even when evaluated under significant distributional shifts.

Figure 5: Zero-shot generalization on Bench2Drive (CARLA)—strong trajectory-video alignment is preserved, illustrating retained planning coherence under sim2real and real2sim challenges.

Figure 6: DPVO trajectory reconstructions from generated videos verify high video-action consistency in DriveVA rollouts for diverse maneuvers.
Video-Trajectory Consistency and Ablations
Central to DriveVA's performance is the enforcement of tight video-trajectory consistency throughout both training and inference. External verification with DPVO (Deep Patch Visual Odometry) demonstrates that ego trajectories, reconstructed from generated videos alone, closely match the planned trajectories produced by DriveVA, indicating that the system’s scene imagination and motion planning are geometrically and causally integrated.

Figure 7: Predicted ego trajectories strictly follow the semantic and physical cues in generated future frames, revealing coherence in long-horizon planning.
Video supervision proves essential: ablating the video loss or severing the coupling between video continuation and trajectory in rollout substantially degrades closed-loop metrics. The result underscores the necessity of dense temporal video grounding in world model-based planning and calls into question the efficacy of prior VLA models that treat video or visual context as mere auxiliary signals.
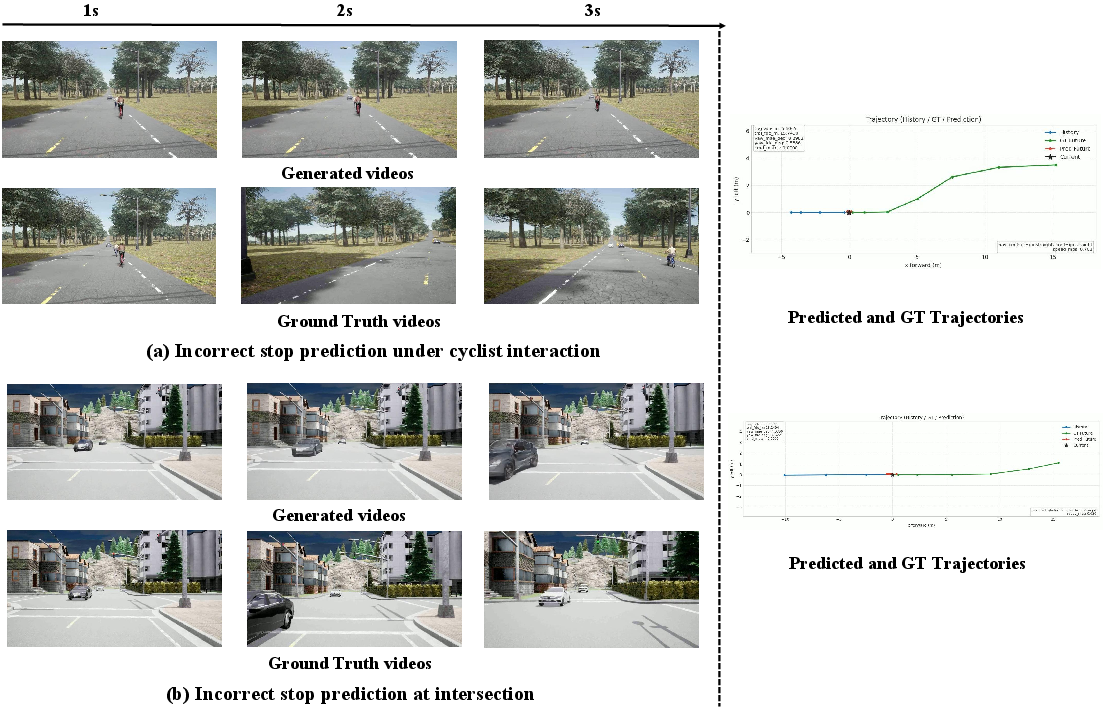
Figure 8: Failure modes illustrate that even when the predicted future diverges from ground truth (due to, e.g., prediction errors), trajectories remain consistent with imagined videos, confirming the strict coupling achieved by the unified rollout.
Comparison to Prior and Concurrent Approaches
DriveVA situates itself amidst a corpus of recent work advancing video world models, generative world simulation, and visual policy learning. Notable differences and strengths include:
- Unified Decoding: Unlike cascaded or branched approaches (e.g., DriveVLA, PWM [li2025drivevlaw0, zhao2025forecasting]), which decouple video imagination from action, DriveVA’s DiT backbone directly and jointly decodes both, eliminating video-action mismatch (see Figure 3).
- Efficient Closed-Loop Inference: Near-optimal planning performance is observed in as few as two flow-matching sampling steps at each policy update, combining computational efficiency and planning fidelity.
- Simulation-Enhanced Scalability: Joint training with simulation data (e.g., CARLA) further improves real-world generalization, highlighting the ability of synthetic corner cases to augment transferable physical priors in large-scale world models.
- Broader Implications: Experimental results confirm recent theoretical conjectures regarding the transfer benefits of spatiotemporal video priors over static vision-language foundations, particularly for scaling world model pretraining in cross-domain embodied AI [wiedemer2025video, yang2024cogvideox, brooks2024video, wan2025].
Implications and Future Directions
By empirically demonstrating that dense video-level supervision and unified video-action decoding significantly enhance closed-loop robustness and zero-shot transfer in autonomous driving, DriveVA motivates several theoretical and practical trajectories:
- World Model Scaling Laws: Results indicate that generalization benefits scale with model size and video pretraining corpus richness—a subject of active investigation for autonomous driving and embodied AI [kaplan2020scaling, li2025drivevla, wan2025]. Full end-to-end fine-tuning is preferred over partial adaptation (e.g., LoRA) to maximize transfer.
- Unified Planning Architectures: The demonstrated necessity of enforcing video-action consistency throughout rollout points to a paradigm shift in world model design, with consequences for both embodied simulation (e.g., robot manipulation, synthetic world forecasting) and policy learning (e.g., RL with world models, causal forecasting).
- Video Models as Universal Policies: The results support the stronger assertion that sufficiently expressive generative video models, when equipped with action-grounding, may serve as universal zero-shot policies across visually rich agent domains—a direction aligned with current trends in video-predictive, multi-task, and universal world models [ye2026world, liang2025video, kim2026cosmos, brooks2024video].
Conclusion
DriveVA delivers a methodologically rigorous demonstration of unified video-action world modeling for autonomous driving, providing strong empirical evidence that tight video-trajectory coupling and dense visual supervision underpin robust zero-shot generalization. Its architectural and empirical advances indicate that joint generative modeling of video and action trajectories, scaled with large video priors and paired with efficient rollout, is a critical prerequisite for closing the real-to-sim, sim-to-real, and cross-domain generalization gaps in autonomous planning. These insights are directly relevant for the design of future end-to-end embodied agents, world model pretraining regimes, and large-scale policy deployment (2604.04198).