- The paper introduces RRPO, a reinforcement learning framework that aligns RAG reranking with the LLM's end-task performance using a deterministic reference baseline.
- It optimizes answer quality by integrating LLM feedback through reward signals based on metrics like EM, F1, and hit rates.
- Extensive experiments across datasets and architectures demonstrate robust, scalable improvements, validating RRPO’s generalizability in RAG pipelines.
Reinforcement Learning Alignment for RAG Rerankers Using LLM Feedback
Introduction
This paper presents ReRanking Preference Optimization (RRPO), a reinforcement learning (RL)-based framework designed to address the persistent misalignment between standard reranker training objectives and the true utility of retrieval-augmented generation (RAG) systems. Traditional rerankers in RAG pipelines are typically supervised using static, retrieval-centric relevance labels, fundamentally decoupled from the downstream LLM generation process. This decoupling results in document selections that maximize conventional IR metrics but do not necessarily optimize for the LLM’s factual accuracy or answer quality. RRPO closes this gap by directly aligning reranker optimization with the LLM’s end-task performance, using the LLM itself as a reward signal and eliminating dependency on human-provided relevance annotations.
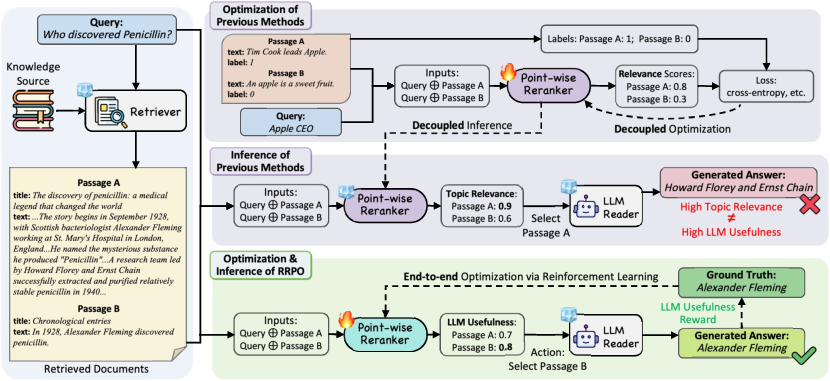
Figure 1: Overview comparison of standard reranking methods versus the RRPO framework, emphasizing end-task alignment with the LLM reader.
Methodology
RRPO formalizes the document reranking process as a finite-horizon Markov Decision Process (MDP). At each RL time step, the agent (parametrized reranker fθ) selects one document from the candidate pool, sequentially constructing the set of k top-ranked documents. The action space at each step is dynamically reduced, and selection probabilities are computed from reranker-generated scores via a softmax.
Critically, the quality of each intermediate document set is assessed by the downstream LLM reader, which generates responses conditionally and is evaluated against ground truth with a reward function Rlm constructed from EM, F1, and hit metrics. This reward formulation tightly couples reranker actions to final answer quality rather than static topical relevance.
A core technical innovation is the reference-anchored deterministic baseline for advantage estimation, bypassing the instability of critic-based baselines common in PPO for RLHF. At every state, the deterministic baseline V(st) is computed by executing a greedy rollout of a strong reference reranker, producing an anchor against which observed RL trajectories are compared. Updates to the reranker’s policy are then regularized by both PPO’s clipped objective and an adaptive KL penalty, ensuring stable learning and preventing policy collapse.
Experimental Results
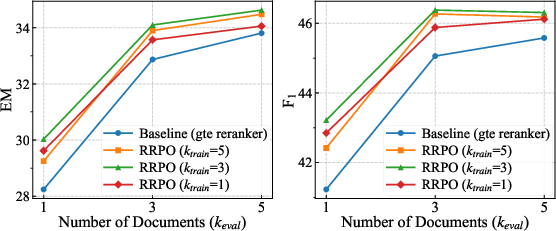
Empirical validation spans HotpotQA, AmbigNQ, 2WikiMultiHopQA, MusiQue, and experiments with varying prompt templates and LLM readers. The RRPO framework yields consistent, statistically significant improvements in both EM and F1 across these settings.
Key quantitative results include:
The ablation studies reveal that intermediate training interaction depths (ktrain=3 for HotpotQA) strike an optimal balance between context sufficiency and noise from excessive context windows. RRPO also retains its advantage when the LLM supervisor is replaced by smaller models (e.g., Qwen2.5-3B), supporting claims of label efficiency.
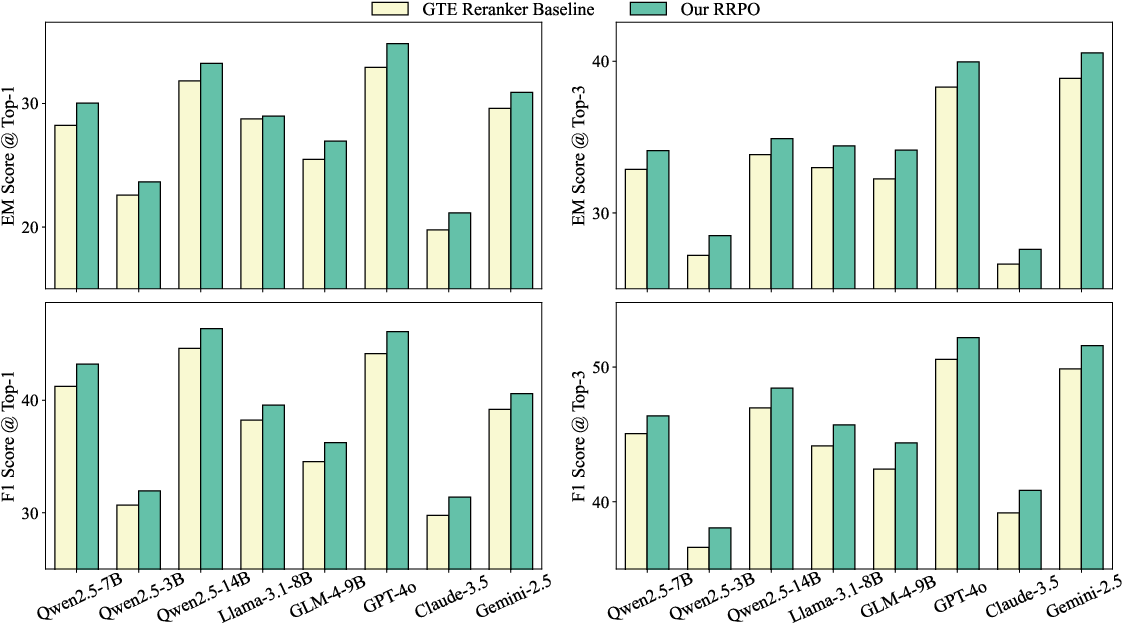
Figure 3: Generalization of RRPO-trained reranker to various LLM readers on HotpotQA, showing robustness and transferability across both open and closed-source models.
Comparative analysis with listwise bandit baselines and classic PPO critic-based RL shows that RRPO’s sequential decision process coupled with a deterministic reference baseline is essential for reliably boosting multi-hop answer quality rather than simply optimizing for one-off retrieval hits.
Theoretical and Practical Implications
The central theoretical contribution is the operationalization of reranking as a sequential RL problem with anchored advantage estimation, tightly integrating retrieval and generation. By optimizing for context utility—as measured by the LLM’s downstream answer quality—RRPO enforces alignment unattainable via static supervision. The reference-anchor mechanism provides a stable, off-policy baseline, which is critical in noisy, sparse reward environments characteristic of RAG pipelines.
Practically, RRPO establishes a scalable alternative to human-annotated reranker fine-tuning, with experiments demonstrating strong generalization to new prompt formats, new LLM architecture families, and increased robustness to supervisor noise. The paradigm is strictly additive and orthogonal to other retrieval improvements, such as query expansion modules like Query2Doc.
Limitations and Future Directions
RRPO is fundamentally limited by the initial retriever's recall: reranking cannot compensate if relevant documents are not present in the candidate set. Future developments may focus on extending preference optimization to jointly train both retrievers and rerankers, hierarchical document selection, or incorporating richer forms of reward modeling, potentially including interaction-level user or LLM feedback for iterative correction.
Additionally, the framework could be adapted for reinforcement learning from noisy or adversarial reward signals, or extended to integrate with emerging multi-agent retrieval-generation architectures. The plug-and-play nature of RRPO supports integration in real-world RAG pipelines, but scaling reward inference with massive LLMs remains computationally challenging.
Conclusion
RRPO provides a principled RL framework for reranker optimization in RAG, tightly aligning retrieval with task-specific generative utility as measured by the downstream LLM. Through sequential reward-based training with a reference-anchored baseline, RRPO demonstrates efficient, robust, and generalizable performance improvements without the need for human-labeled data or unstable parametric critics. Its practical advantages as a reader-aligned, label-efficient, and architecture-agnostic reranker render it a substantial advance in task-aware RAG pipeline construction.