- The paper introduces user-turn generation as a probe for evaluating latent interaction awareness in LLMs, decoupling conversational follow-up quality from standard task accuracy.
- It employs temperature sweeps and controlled perturbations to examine whether generated user turns are contextually grounded, with models like Qwen3.5 showing up to 22% genuine follow-ups.
- Findings reveal that increased model scale does not ensure interaction awareness and that collaborative fine-tuning can significantly boost user-turn fidelity in multi-turn dialogues.
User-Turn Generation as a Probe of Interaction Awareness in LLMs
Introduction
The paper "Beyond the Assistant Turn: User Turn Generation as a Probe of Interaction Awareness in LLMs" (2604.02315) introduces a behavioral probe for assessing the interaction awareness of LLMs. The authors argue that standard evaluation paradigms, which focus solely on the assistant turn (i.e., the model's response to user input), fail to capture whether LLMs internalize and anticipate conversational consequences. The work proposes user-turn generation: after an assistant response is produced, the model continues generation under the user role. The quality of these user turns—specifically, whether they constitute genuine follow-ups to the preceding assistant output—serves as an operationalization of interaction awareness. This approach shifts the evaluation lens from single-turn task success to assessing the model's capacity for dialogue progression and user-side reasoning.
Methodological Framework
User-turn generation is formalized as follows: given a conversation context consisting of a user query q and an assistant response a, the model is prompted to produce a user turn u in response to the entire conversation [q;a]. The investigation targets whether u is a contextually grounded reaction to a, as opposed to degenerate behaviors such as restating q, continuing as the assistant (identity drift), or emitting irrelevant queries. The authors explicitly distinguish their probe from user simulation research, focusing instead on uncovering latent interaction-aware behaviors encoded by the model's weights.
Interaction awareness is operationalized through a robust LLM-based evaluator. This judge model assesses each generated user turn for contextual grounding and assigns a binary label—genuine follow-up or not—supplemented by fine-grained failure labels (e.g., previous_turn_restate, assistant_turn_restate, meta_planning). The evaluation covers 11 open-weight models (Qwen3.5, gpt-oss, GLM-4.7) on a suite of five verifiable datasets (math reasoning, instruction following, QA) and two multi-turn conversational datasets, providing both breadth and the opportunity to measure the decoupling between task performance and conversational interaction awareness.
Empirical Findings
Task Accuracy and Interaction Awareness Are Decoupled
Empirical analysis reveals an explicit dissociation between conventional task accuracy and interaction awareness. As visualized in Figure 1, there is negligible correlation between strong task benchmarks (e.g., GSM8K accuracy scaling from 41% to 96.8% in Qwen3.5) and the ability to produce plausible user turns, which remains near zero at greedy decoding for most model sizes and families. In several cases, smaller or less accurate models yield higher grounded follow-up rates, underscoring the independence of interaction awareness from overall model scale or answer correctness.
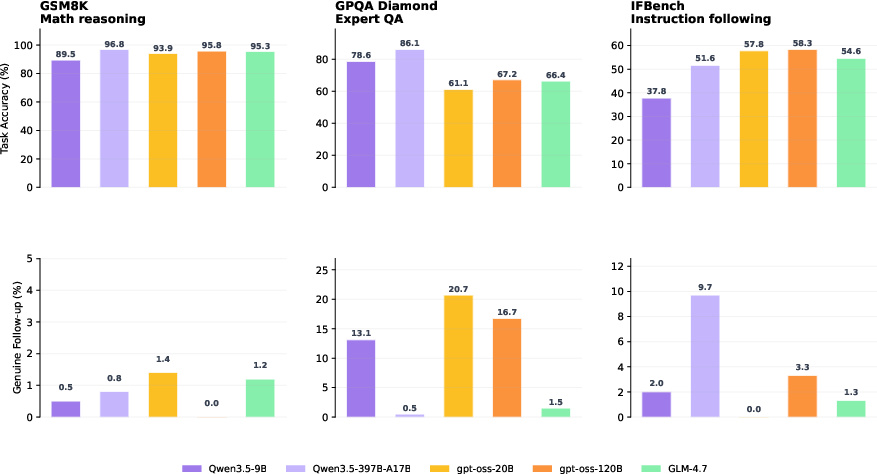
Figure 1: Task accuracy and follow-up rates are uncorrelated across model families, revealing that high assistant accuracy does not imply behavioral interaction awareness.
Interaction Awareness Is Latent and Contextual
The paper systematically examines the model's generation distribution via temperature sweeps. At deterministic T=0, genuine follow-up rates are nearly zero; as temperature increases, latent interaction awareness surfaces, predominantly in Qwen3.5 and GLM-4.7 (e.g., Qwen3.5-27B reaches up to a0 follow-up on GSM8K at a1), while remaining recalcitrant in gpt-oss on specific datasets. This result demonstrates that interaction awareness is present in the model's probability distribution but is not positioned at the mode under standard sampling strategies.

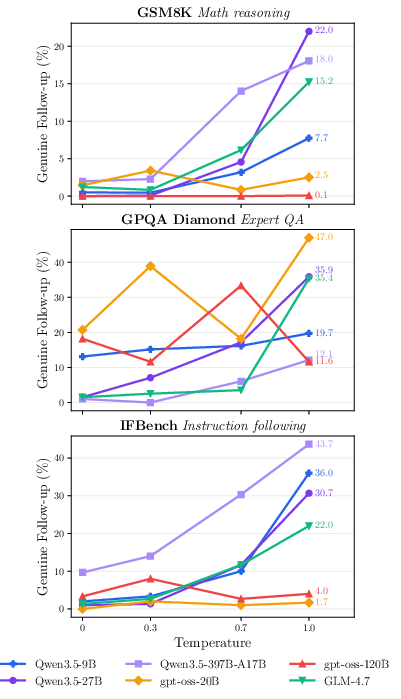
Figure 2: User-turn generation setup (left) and temperature-dependent emergence of genuine follow-ups across models (right); higher temperature exposes latent interaction awareness.
Scaling, Training, and Family-Level Effects
Analysis within the Qwen3.5 family shows no monotonic improvement in follow-up rates with increased parameter count, despite near-linear scaling in assistant accuracy. Interaction awareness emerges sporadically and is dataset- and configuration-dependent, challenging the assumption that increased scale or task-centric training objectives inherently lead to better user-proxy fidelity.
Post-training interventions yield marked differences: supervised finetuning on multi-turn collaboration data significantly boosts genuine follow-up rates (to a2–a3), though sometimes at the cost of task accuracy. Reinforcement learning with multi-turn conversational rewards provides more moderate gains in interaction awareness while maintaining baseline accuracy. These outcomes suggest that interaction awareness is not only measurable but trainable given explicit multi-agent or collaboration-oriented objectives.
Perturbation Sensitivity
Controlled perturbation experiments (e.g., truncating assistant answers, appending explicit questions) validate the probe's causal grounding. Models with higher sensitivity to conversational context (notably gpt-oss and GLM-4.7) significantly increase follow-up rates under these perturbations, while Qwen3.5 models often remain invariant. Perturbation responsiveness further illuminates qualitative differences in how model families encode and utilize conversational history.
Taxonomy of Failure Modes
Extensive annotation reveals that low interaction awareness manifests primarily as systematic failure modes, rather than as random output noise. Qwen3.5 predominantly produces prompt restatements, gpt-oss often replicates the assistant answer under the user header (identity leakage), and GLM-4.7 exhibits frequent meta-planning as a user. This taxonomy indicates that training recipes and data composition, rather than model size, are the principal determinants of interaction-aware behavior.
Implications and Future Directions
The user-turn generation probe demonstrates that mainstream LLM training optimizes for assistant competence without necessarily instilling an internal model of user-side dialogue progression. As a result, large models deployed in multi-agent or interactive settings may lack reliable behavior when repurposed as user proxies or evaluated under multi-turn requirements.
For self-play, collaborative RL, or robust evaluation suites, there is a critical need to design training regimes and objectives that propagate user-side conversational signals into the learned weights. The probe developed in this work provides a direct axis for evaluating such improvements and for identifying family- or recipe-level weaknesses.
Going forward, further research can extend this approach by integrating richer user simulation environments, alternative interaction-aware objectives, and probing the alignment between internal model representations and observable dialogue behaviors. Investigating transfer to multilingual, code, or long-horizon settings, and developing best-of-N generation or reranking schemes incorporating user-turn metrics, constitutes a promising direction for improving the deployment fidelity of LLMs in dynamic conversational environments.
Conclusion
This study establishes user-turn generation as a diagnostic tool for measuring interaction awareness in LLMs, highlighting a crucial behavioral dimension overlooked by assistant-only benchmarks. The decoupling from task accuracy, family- and training-specific idiosyncrasies, and positive response to collaborative interventions collectively demonstrate both the limitations of current LLM training and pathways to more interaction-capable systems. The probe reorients evaluation toward conversational consequence modeling—essential for robust, adaptive AI agents operating beyond single-turn contexts.
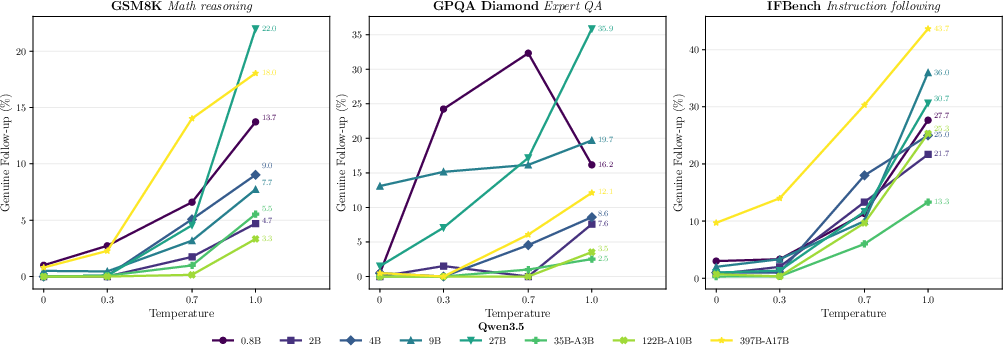
Figure 3: Temperature-dependent emergence of genuine user-turn follow-ups across the Qwen3.5 family reveals latent interaction awareness but no monotonic scaling with size.
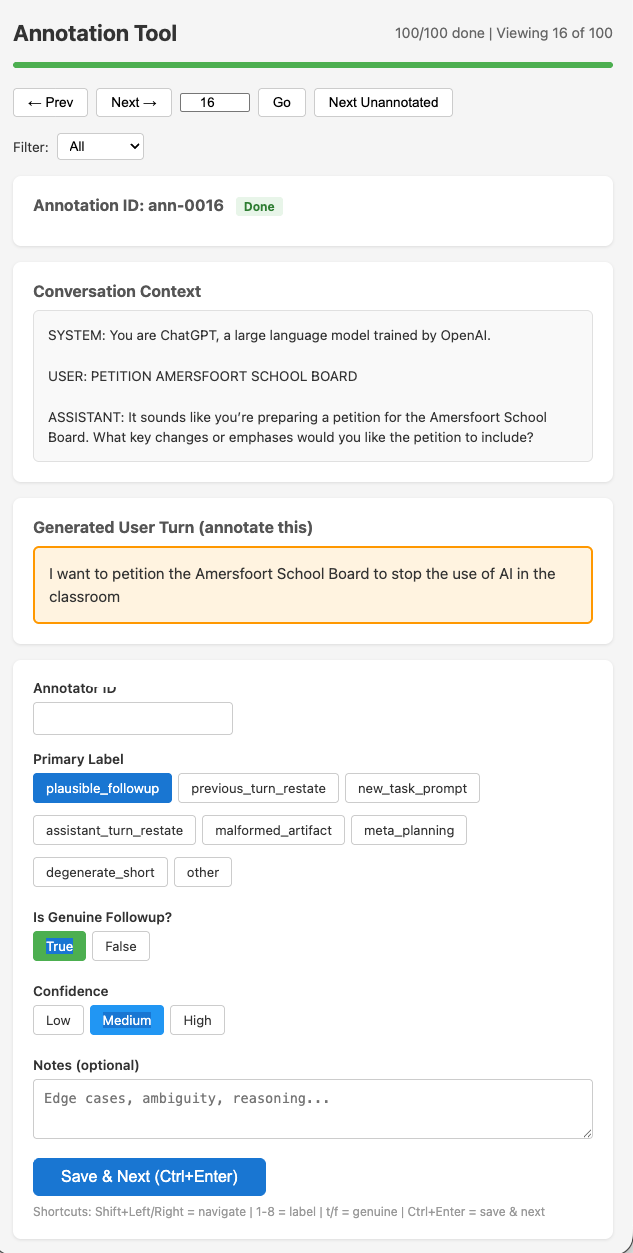
Figure 4: The manual annotation tool for validating LLM-based evaluation of conversational follow-ups enables high-quality human-model agreement measurement.

