- The paper proposes a novel method that constructs a directed skill graph to explicitly model dependencies, ensuring complete and efficient retrieval of skills.
- It combines semantic and lexical signals with reverse-aware graph diffusion to balance functional prerequisites with context budget constraints.
- Empirical results demonstrate that Graph of Skills significantly reduces token usage while improving average rewards compared to full-library and vector-based approaches.
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Introduction and Motivation
As LLM-based agents scale towards increasingly complex environments, they must efficiently retrieve and invoke skills from libraries containing thousands of tool-like components. The exponential growth of skill repositories introduces a retrieval bottleneck that flat context loading and standalone vector retrieval fail to address: indiscriminate prompt concatenation overloads context windows and increases inference cost, while embedding-based retrieval neglects functional prerequisites critical for multi-step or hierarchical tasks. "Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills" (2604.05333) proposes Graph of Skills (GoS), a system that augments the retrieval pipeline with explicit structural and dependency awareness by building and querying a directed skill graph.
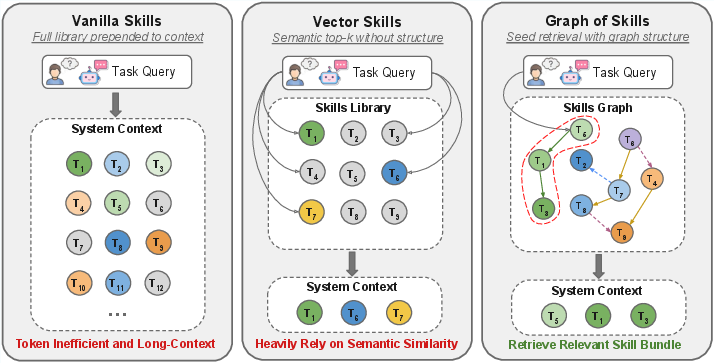
Figure 1: Conceptual comparison between flat skill loading, vector retrieval, and Graph of Skills (GoS), illustrating how GoS explicitly recovers prerequisite skills and assembles an execution bundle.
Method: Graph-Structured Skill Retrieval
GoS formalizes skill retrieval as dependency-aware, bounded selection rather than naive top-k semantic matching. The method consists of two distinct phases: offline graph construction and online structural retrieval.
Offline Graph Construction:
Skill packages are parsed into normalized executable nodes, capturing not only names and descriptions but structured I/O schemas, entrypoints, and operational constraints. Edges in the resulting multi-relational graph capture dependencies (via I/O compatibility), workflow adjacency, semantic similarity (for near-duplicates or cluster-level relations), and alternatives. Dependency edges are deterministically induced; higher-order relations are validated via sparse LLM passes over candidate pairs to balance tractability and precision. Non-dependency edges are only added via candidate pools to reduce noise and overfitting.
Online Structural Retrieval:
Given a query and tight context budget, GoS proceeds through hybrid seeding—merging both semantic (embedding-based) and lexical (token similarity) retrieval signals. Seeds form the starting distribution for a personalized, reverse-aware PageRank-style diffusion that propagates relevance through the skill graph, deliberately favoring reverse transitions (especially on dependency edges) to recover functional prerequisites even when they are semantically distant from the query. The final candidate bundle is reranked by combining stationary graph scores with local field-level evidence and hydrated in budget order for agent consumption.
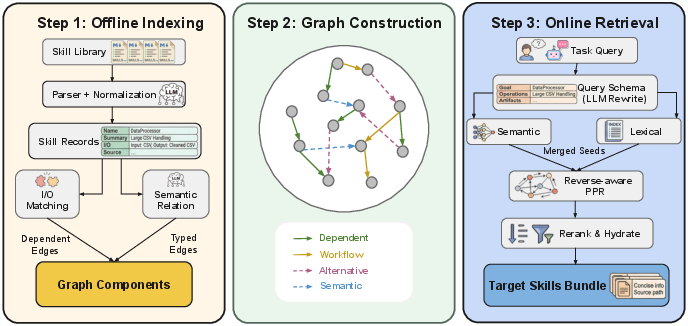
Figure 2: Overview of GoS's offline graph construction and online personalized PageRank-based structural retrieval, culminating in budgeted execution bundle formation.
Empirical Evaluation
GoS is evaluated on two benchmarks representative of high-skill-count, multi-domain environments: SkillsBench (technical tasks spanning engineering, economics, robotics, etc.) and ALFWorld (text-based embodied simulators requiring multi-step spatial manipulation). The baselines include:
- Vanilla Skills: Full library presented to the agent as prompt context, maximizing recall but saturating the context window.
- Vector Skills: Embedding-based top-k semantic retrieval.
Across three strong LLM backbones (Claude Sonnet 4.5, GPT-5.2 Codex, MiniMax M2.7), GoS consistently attains the highest average reward, the largest relative improvement being 43.6% over full-library loading on SkillsBench, while reducing input tokens by 37.8%. Vector Skills often retrieves semantically aligned but functionally incomplete bundles, especially on long-horizon tasks where the relevant prerequisites are not semantically proximal to the query.
Notably, GoS achieves these gains without sacrificing retrieval-time compression, keeping token usage and agent runtime near vector-retrieval levels. For example, on ALFWorld, GoS attains a 97.9% success rate (Claude Sonnet 4.5) with an average token count of 27,215 versus 1,524,401 for Vanilla Skills.
Ablation and Qualitative Analysis
Experiments varying the skill library size (200–2,000) under GPT-5.2 Codex demonstrate that token usage in Vanilla Skills grows linearly with repository size, while both GoS and Vector Skills constrain this growth. However, GoS retains a reward advantage at all tested scales, especially as the library exceeds several hundred skills.
Component ablations show the importance of both graph propagation and hybrid lexical-semantic seeding: removing graph propagation drops average reward by 5.1 points, while ablation of lexical/reranker components results in a 7.7 point decrease, highlighting the necessity of both structural and content-based signals for reliable coverage of task-relevant execution paths.
Qualitative trajectory analysis confirms that GoS routinely exposes compact, execution-complete bundles, accelerating agent convergence and reducing noisy context clutter. In tasks such as pedestrian traffic counting, GoS retrieves a tight, functionally coherent set of visual processing skills, whereas baselines either miss prerequisites or bury them in irrelevant context, forcing the agent to rely on inefficient search or incomplete plans.
Practical and Theoretical Implications
Practical Implications:
GoS demonstrates that explicit modeling of skill dependencies is essential in agent architectures operating over massive, heterogeneous tool repositories. By shifting the retrieval paradigm from indirect semantic proximity to structured, dependency-aware bundle assembly, GoS directly addresses both context budget constraints and planning reliability. In real-world deployments, this translates to improved agent robustness, reduced hallucination, and lower operational cost as skill repositories grow.
Theoretical Implications:
The explicit use of hybrid-seeded, reverse-aware graph diffusion extends the personalized PageRank literature into the domain of agentic skill invocation, showing that structural credit assignment is vital when semantic landscape and executable pipeline structure diverge. GoS also provides architectural evidence that the compositionally of tool use in LLM agents is not a trivial function of context exposure, but requires explicit encoding and retrieval of executable structure.
Limitations and Future Work:
The method assumes accurate offline parsing and relation induction; degradation occurs if skills are poorly specified or lack reliable I/O schemas. Currently, the graph is largely static and does not adapt online to execution traces, user feedback, or evolving skill implementations. Incorporating continual graph refinement, more nuanced reranking using feedback signals, and multimodal or cross-environment evaluation constitute immediate directions for advancement.
Conclusion
Graph of Skills represents a principled solution to the challenge of dependency-complete skill retrieval in large local repositories. Through structural retrieval grounded in executable dependency graphs, GoS outperforms both flat and vector-based approaches in relevance, compactness, and agent efficiency. These findings reinforce the need for explicit structural modeling within agent retrieval stacks as the scale and complexity of skill libraries continue to grow, and set the foundation for adaptive, online-updating retrieval layers in future agent frameworks.