- The paper introduces a modular memory system that uses coordinated small language models to manage efficient memory retrieval and consolidation for LLM agents.
- It employs a two-stage retrieval pipeline combining vector search with semantic reranking, achieving retrieval under 83 ms and improved accuracy.
- Experimental results demonstrate enhancements in F1 and semantic metrics on benchmarks like LoCoMo and DialSim, ensuring practical deployment in multi-user environments.
Lightweight Memory Architectures for LLM Agents: LightMem with SLM Coordination
Motivation and Problem Setting
LLM agents require persistent memory systems for long-horizon reasoning, maintaining consistency across dialogue turns and accumulating salient knowledge for continual learning and personalization. Conventional external memory architectures face an operational trade-off: retrieval-driven methods offer low latency but suffer from retrieval noise and limited semantic accuracy, while LLM-centric memory schemes improve correctness but incur prohibitive latency and scaling constraints during repeated online invocations. LightMem addresses this dichotomy by leveraging coordinated small LLMs (SLMs) to modularize memory retrieval and writing, thereby achieving efficient, accurate memory invocation under fixed resource budgets.
System Architecture
LightMem orchestrates memory operations using three specialized SLMs: a Controller for intent modeling and query decomposition, a Selector for semantic reranking and compression, and a Writer for efficient memory summarization and maintenance. Memory is partitioned into short-term memory (STM, session context), mid-term memory (MTM, user-specific episodic summaries with embedding, timestamp, and user tag), and long-term memory (LTM, graph-structured, de-identified semantic knowledge). User identifiers are embedded within memory entries to enforce fine-grained logical isolation and scale in multi-user environments. Online processing is strictly budgeted, employing vector-based retrieval for coverage followed by semantic filtering, while offline consolidation distills high-value MTM evidence into LTM via large-context models.
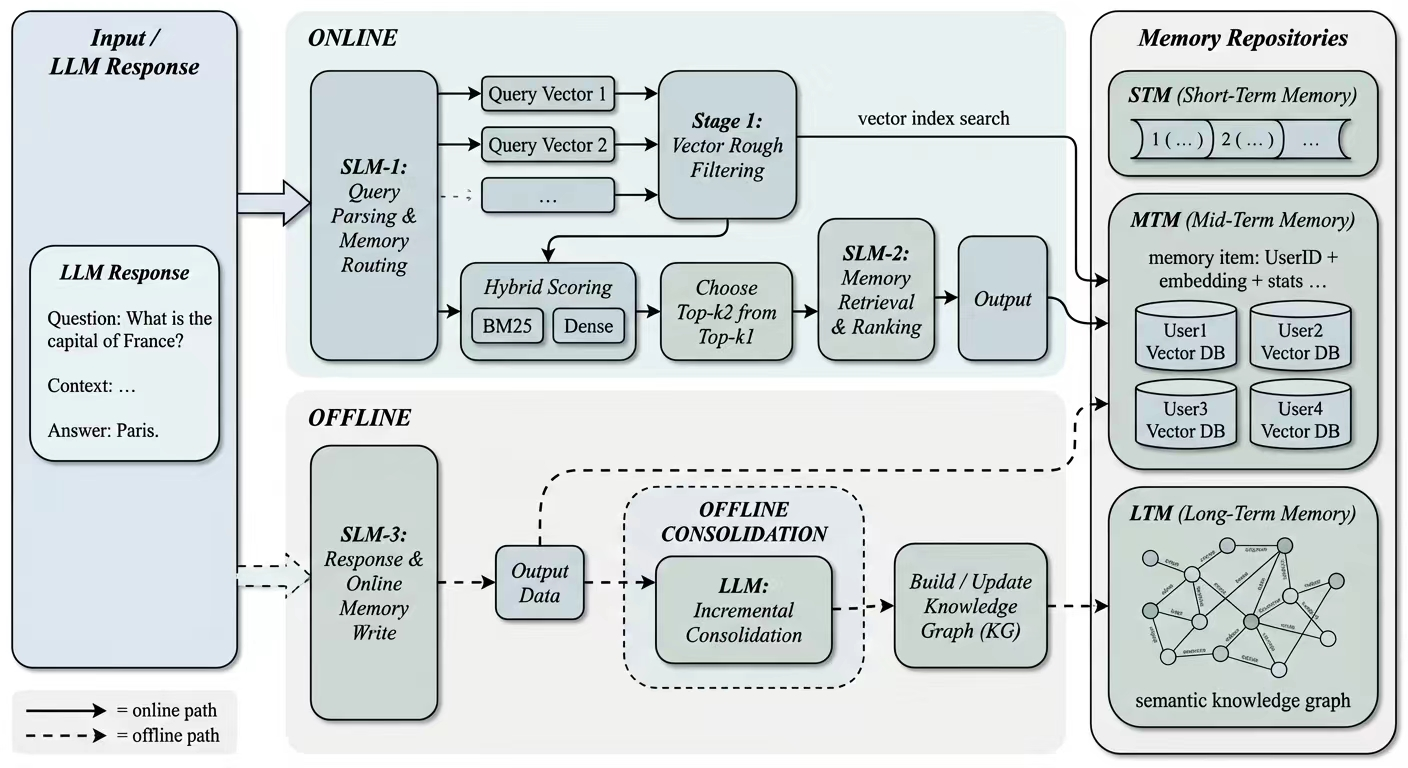
Figure 1: Multiple SLMs coordinate an online pathway for query-time routing and retrieval over STM/MTM, and an offline pathway that incrementally consolidates MTM into a graph-structured LTM.
Memory Retrieval Pipeline
The online pipeline involves a two-stage querying procedure. SLM-1 first parses user intent and decomposes input into hypothetical queries (HQs), allocating Top-K quota and imposing metadata constraints (e.g., user, temporal, type tags). SLM-2 performs Stage 1 metadata-constrained coarse retrieval, generating a candidate pool with fixed size (2K candidates), and Stage 2 semantic filtering to compress these into the most relevant Top-K selections for downstream conditioning.
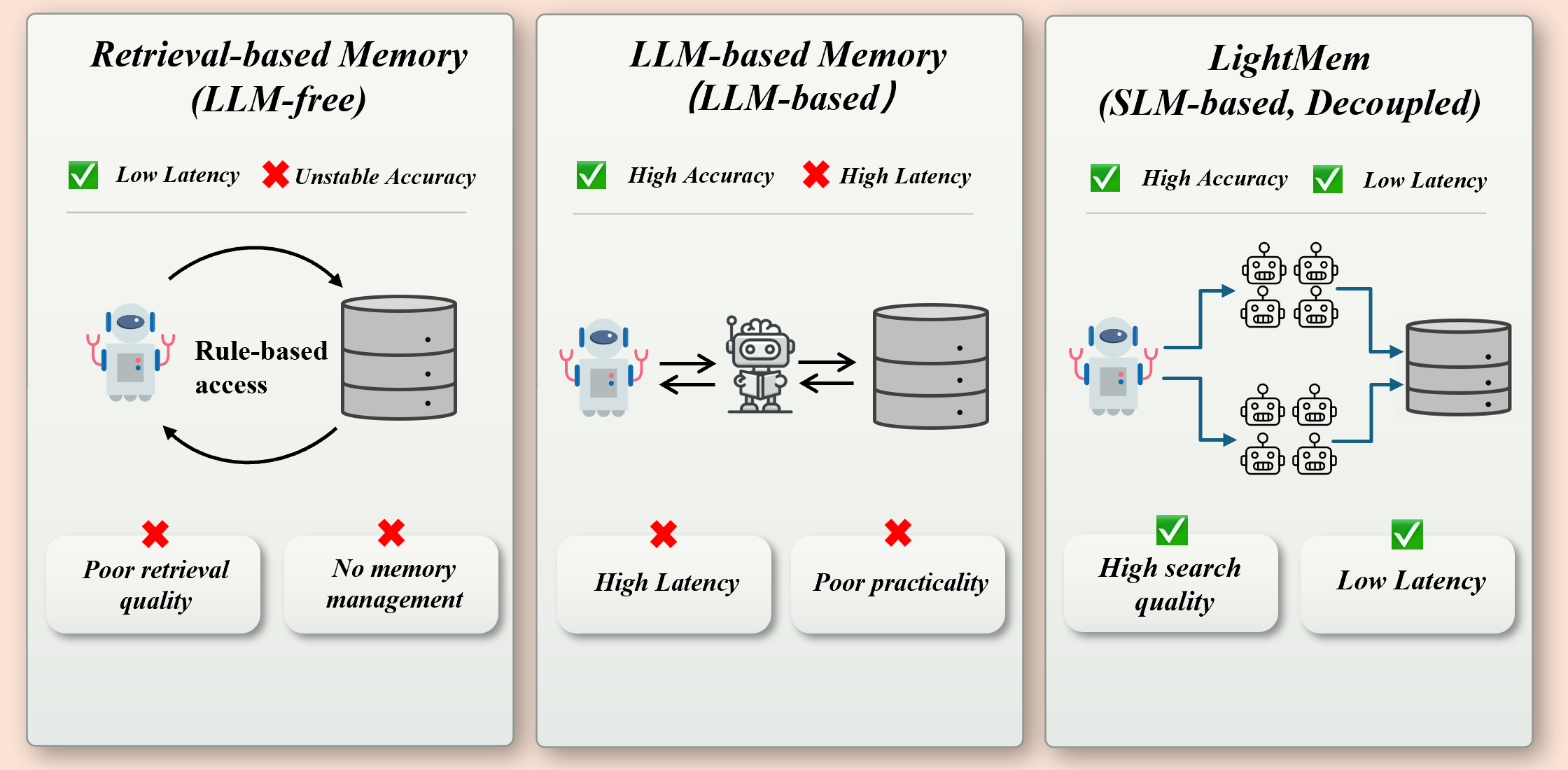
Figure 2: LightMem combines enhanced retrieval with SLMs, achieving high retrieval accuracy while significantly reducing online latency compared to retrieval-based and LLM-based memory systems.
Efficient retrieval is driven by embedding-based vector search and strict quota allocation, followed by semantic reranking in SLM-2 to maximize alignment with user intent and suppress noise. The retrieved memories are appended to the context for response generation.
Memory Writing and Consolidation
After each interaction, SLM-3 compresses user-relevant content into concise MTM summaries, merging repetitive information and resolving conflicts via temporal cues or evidence strength. MTM is bound by a capacity constraint, prompting eviction and further compression as needed. Offline, a large-context LLM periodically processes new or frequently accessed MTM entries for consolidation into LTM, abstracting episodic data into graph nodes and updating links based on semantic proximity and accumulated evidence. This decoupled design guarantees that online latency remains minimal and invariant to the size of LTM or MTM.
Experimental Results
LightMem demonstrates robust gains across a spectrum of model scales (GPT-4o, Qwen2.5, Llama-3.2) and benchmarks (LoCoMo for extended logical reasoning; DialSim for long-horizon multi-party dialogue). On LoCoMo, LightMem achieves a mean F1 improvement of approximately 2.5 points over the strongest baseline (A-MEM), with statistically significant increases for multi-hop and temporal questions and superior performance for cross-session reasoning, despite operating with an order-of-magnitude smaller effective context than full-context replay methods.
On DialSim, LightMem attains the best results across both lexical and semantic metrics, showing improvement not only in overlap-based (ROUGE, METEOR) but also in semantic similarity (SBERT rises from 19.51 to 23.40), supporting the claim of enhanced long-term semantic consistency.
LightMem also achieves substantially lower retrieval and end-to-end latency relative to LLM-driven memory architectures. Retrieval is consistently under 83 ms (P50), and end-to-end response latency is 581 ms, enabling practical deployment in realistic agent environments without sacrificing retrieval or reasoning quality.
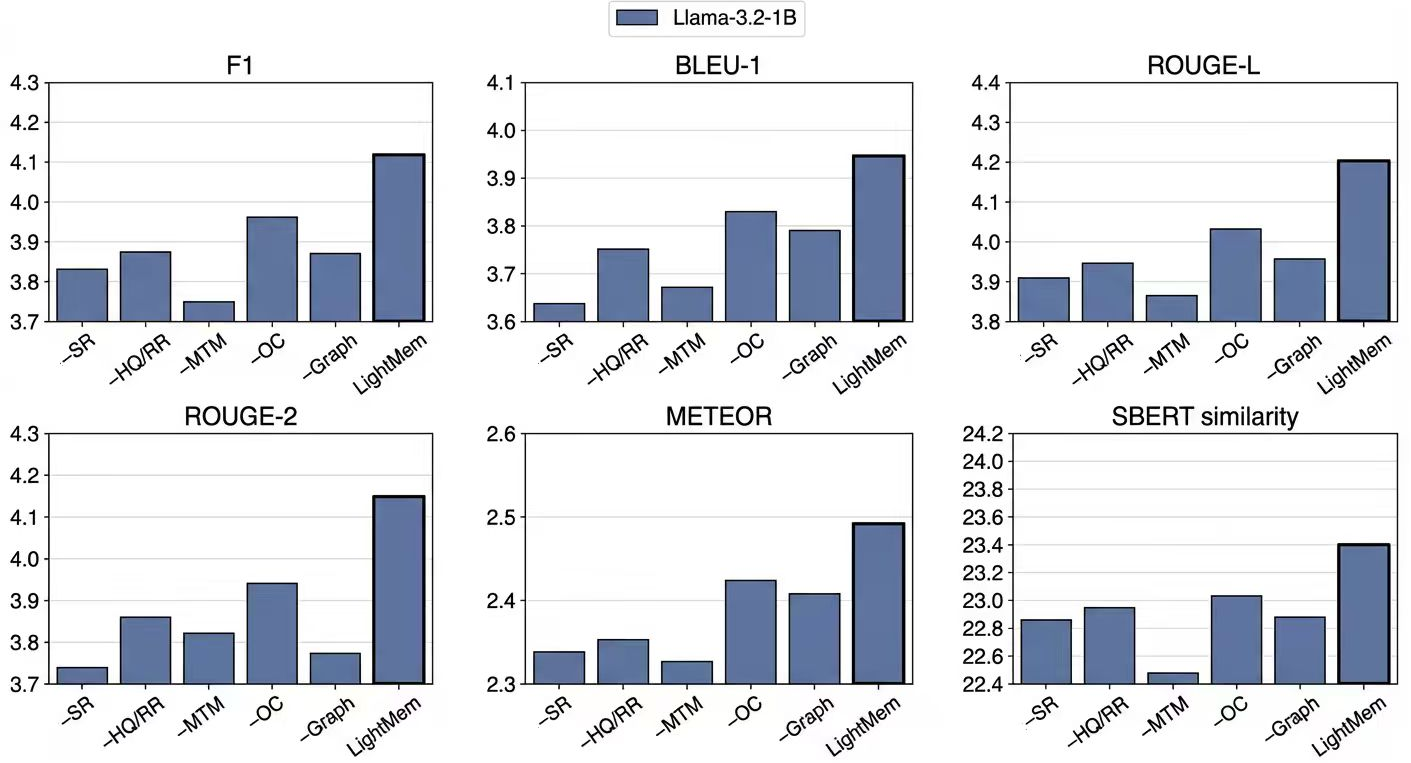
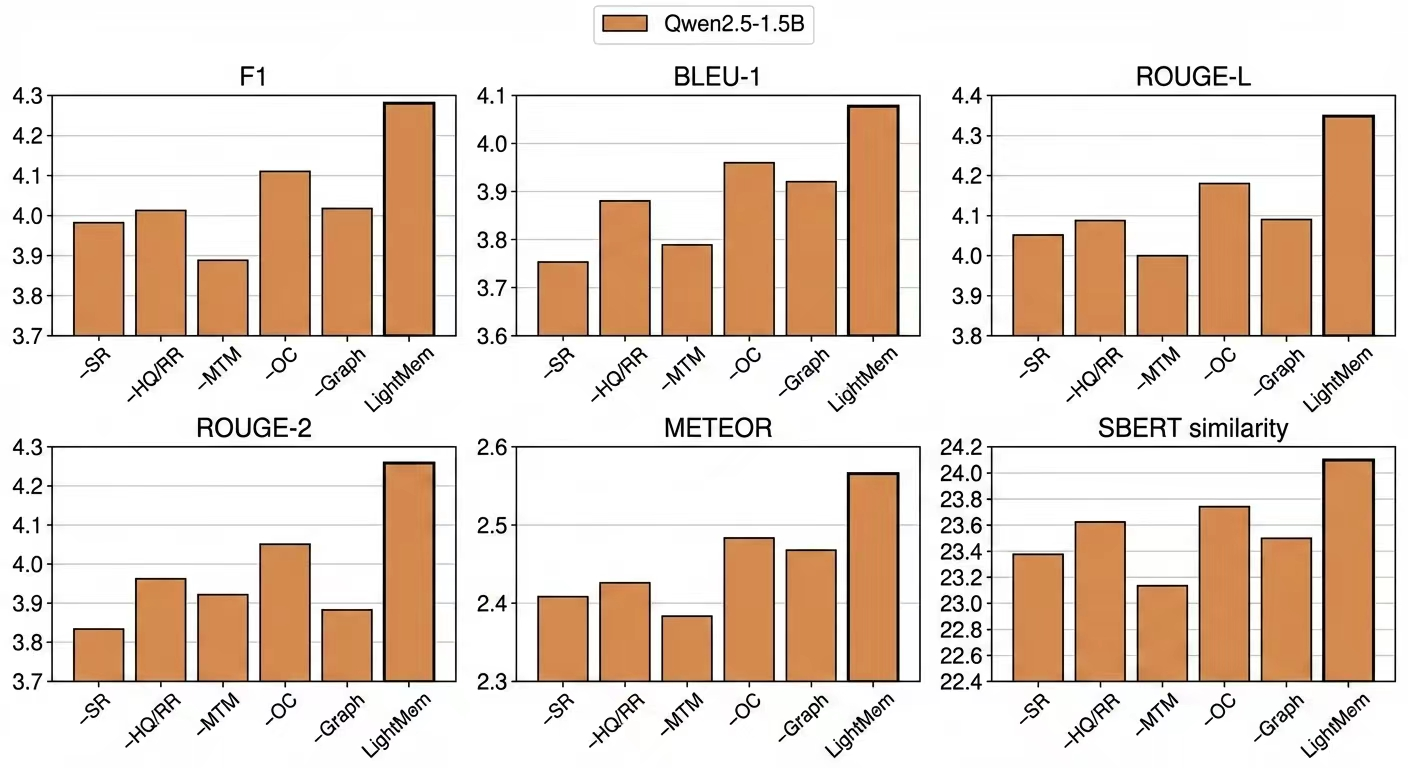
Figure 3: Ablation study on DialSim. We report F1, BLEU-1, ROUGE-L, ROUGE-2, METEOR, and SBERT similarity.
Ablation studies underscore the necessity of each architectural component: removing the semantic reranking or HQ-based routing leads to measurable declines in F1 and semantic metrics; eliminating MTM further degrades effectiveness. The graph-structured LTM is superior to flat vector stores in maintaining long-term reasoning accuracy.
Theoretical and Practical Implications
LightMem's modular SLM-driven memory pipeline enables scalable and accurate memory retrieval for LLM agents, balancing the efficiency-effectiveness trade-off inherent in existing architectures. The explicit separation of online and offline pathways, coupled with user-scoped memory and graph-based LTM consolidation, supports continual evolution, privacy, and scalable reasoning. The architecture is agnostic to backbone, suggesting broad applicability and robustness in a variety of agentic memory and planning contexts.
From a theoretical standpoint, LightMem advances agent memory as an incrementally evolvable, modular process, decoupling control and abstraction, and lays the foundation for composable memory systems in multi-agent scenarios. Practically, the low-latency online retrieval, bounded context length, and persistent graph-structured LTM enable realistic integration with interactive systems and potential deployment on resource-constrained platforms.
Future Directions
Several areas for further exploration remain: adaptive consolidation strategies, dynamic control policies, and richer abstraction mechanisms for LTM growth and maintenance. Incorporation of episodic simulation, schema-driven memory, hierarchical aggregation [aadhithya2024enhancing], or topological organization [port2022topological], as well as rigorous benchmarking on evolving agentic tasks [wei2025evo, DBLP:conf/iclr/WuWYZCY25], may yield further improvements in agent memory robustness and generalization.
Conclusion
LightMem presents a principled, low-latency, SLM-driven memory system for LLM agents, achieving both high retrieval accuracy and practical scalability. Empirical results validate its superior performance across multiple memory benchmarks, minimal latency, and robustness to varying backbone architectures. Its modular design, online-offline decoupling, and graph-based LTM consolidation establish strong implications for the future of agentic memory architectures in long-horizon, multi-user, and multi-agent reasoning environments.