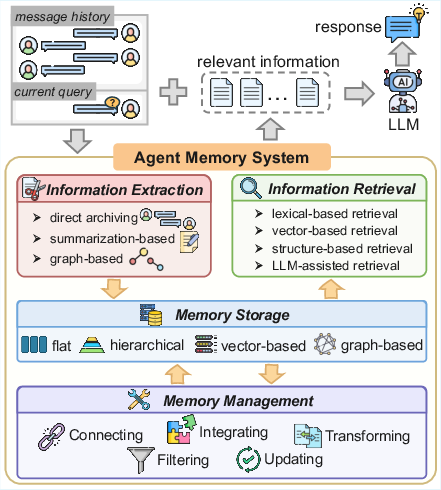
- The paper demonstrates that decomposing memory into functional components enables state-of-the-art efficiency and accuracy in LLM agents.
- It evaluates various memory architectures—from local context windows to hierarchical storage—highlighting trade-offs in scalability and retrieval performance.
- The proposed SOTA method integrates hierarchical and vector-based retrieval, achieving up to 13% F1 improvement and reduced token costs.
Modular Memory Architectures in LLM-based Agents: A Unified Framework and Systematic Evaluation
Introduction
LLM-based agents increasingly require memory mechanisms for long-horizon reasoning, self-evolution, and robust decision-making. Most contemporary architectures rely on local context windows, inherently limiting their reasoning ability over extended dialogues, multi-session interactions, and dynamic environments. This paper, "Memory in the LLM Era: Modular Architectures and Strategies in a Unified Framework" (2604.01707), systematically categorizes and evaluates recent memory methods, introducing a unified modular framework that dissects agent memory into functional components—information extraction, memory management, memory storage, and information retrieval. Furthermore, the paper provides the first comprehensive experimental analysis across two long-term conversational benchmarks and proposes a new algorithm delivering state-of-the-art (SOTA) performance with high efficiency.
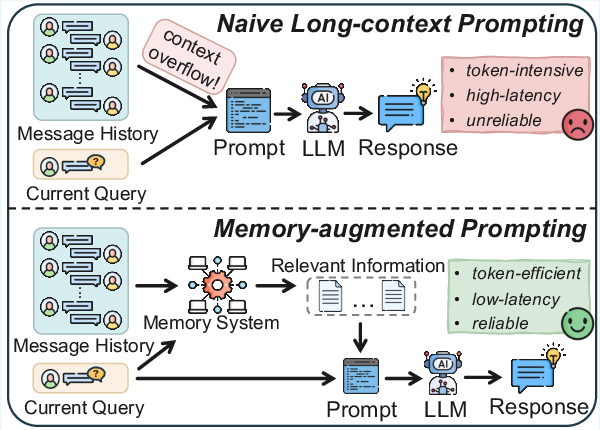
Figure 1: A high-level comparison contrasting naive long-context prompting with memory-augmented prompting for LLM-based agents.
Unified Framework for Agent Memory Systems
To synthesize advances in agentic memory, the authors propose a four-stage abstraction:
This decomposition enables disambiguation between architectural innovations and their empirical consequences, serving as an analytical foundation for benchmarking and ablation studies.
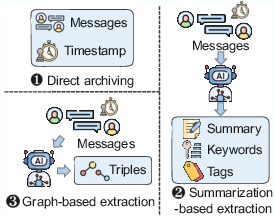
Technical Landscape: Extraction, Management, and Storage
Memory systems differ fundamentally in how agentic context is distilled:
The chosen extraction mode heavily influences downstream performance, affecting both storage efficiency and semantic fidelity.
Memory Management
Translating inspiration from biological cognition, memory management encompasses operations for coherence, redundancy reduction, and adaptability:
- Connecting: Linking semantically or temporally related experiences.
- Integrating: Abstraction and summarization to condense episodic information.
- Transforming: Hierarchical migration (e.g., from short- to long-term tiers) based on reuse and recency metrics.
- Updating: Continuous revision via rule-based, LLM-based, or fully agentic paradigms.
- Filtering: Pruning outdated or low-value records to minimize computational burden and maximize knowledge utility.
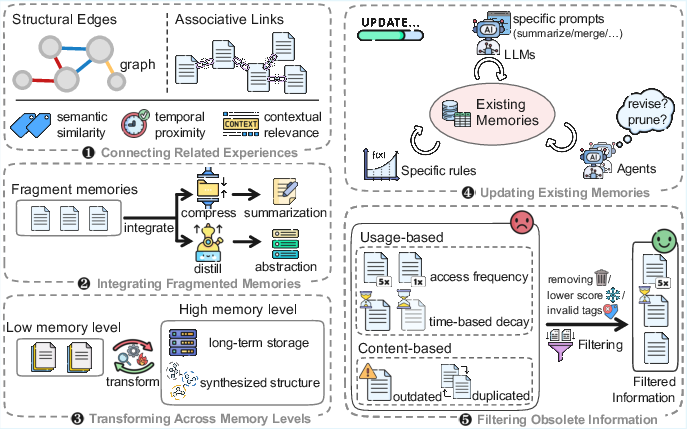
Figure 4: Workflow depicting the modular process of connection, integration, transformation, updating, and filtering in memory management.
Memory Storage
Architectural distinctions arise around storage configuration:
- Flat vs. Hierarchical: Single-level vs. multi-level arrangements, e.g., FIFO queues versus multi-tiered caches with differentiated roles for each level.
- Vector-Based: Embedding-based semantic indexing, supporting efficient top-k retrieval.
- Graph-Based: Explicit entity and event relationships, supporting advanced relational queries and multi-hop reasoning.
The choice of storage topology dictates the system's trade-off envelope between speed, recall, and reasoning depth.
Retrieval Strategies
Information retrieval from agentic memory systems adopts several paradigms:
- Lexical-based: Exact token overlap.
- Vector-based: Embedding similarity, typically with FAISS or HNSW for large-scale search.
- Structure-based: Graph traversal or hierarchical navigation for complex queries and aggregation tasks.
- LLM-assisted Retrieval: Generative re-querying or context adaptation, leveraging LLMs' reasoning for dynamic or ambiguous query resolution.
These options are not mutually exclusive and may be combined, as in hybrid retrieval routing based on query class.
Experimental Study and Comparative Analysis
The study benchmarks ten representative memory algorithms against two multi-session datasets—LOCOMO and LONGMEMEVAL. Key evaluation axes include not only F1/BLEU-1 accuracy, but also token cost (latency and resource efficiency), context scalability, position sensitivity, and LLM backbone dependence.
Findings:
- Hierarchical and Tree-based Methods: Outperform vector-only approaches, especially on multi-hop and temporal tasks, underscoring the importance of structured aggregation and variable-granularity retrieval.
- Information Fidelity: Direct or summarized archiving preserves answer accuracy; exclusive reliance on graph-extraction can cause semantic loss.
- Explicit Association / Updating: Methods lacking explicit links (e.g., MemoryBank, MemGPT) exhibit degraded performance on reasoning tasks spanning multiple sessions; contrast this with MemTree/MemOS, which maintain strong multi-session consistency.
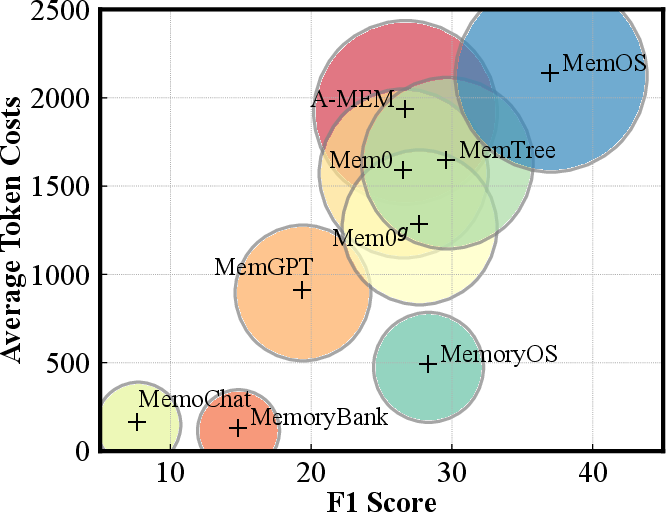
Figure 5: Visualization of the trade-off between effective performance (F1) and token costs, highlighting architectural differences in resource efficiency.
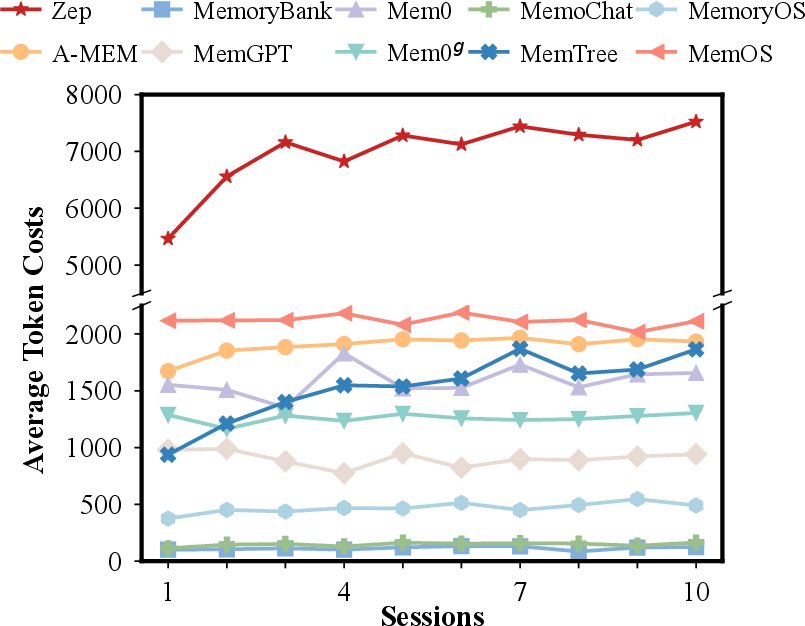
Figure 6: Breakdown of token costs per dialogue over session progression, demonstrating scalability constraints of various memory architectures.
Robustness Analyses:
- Context Scalability: All methods degrade as context size increases (more noise), but rule-based hierarchical designs (MemoryOS) degrade less than flexible agent-managed approaches.
- Position Sensitivity: All methods exhibit recency bias; hierarchies exacerbate this but can be mitigated by design choices preserving older evidence independently.
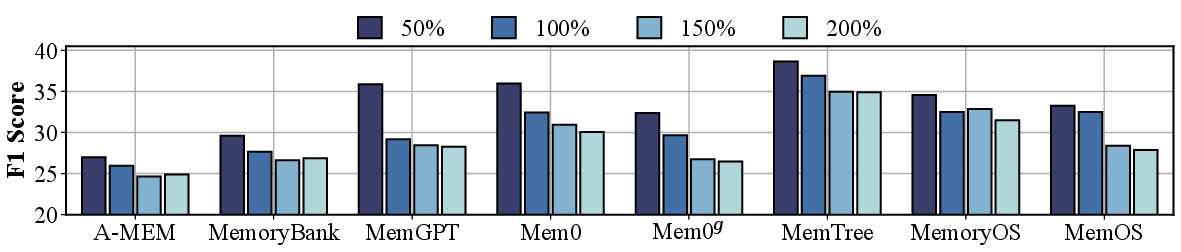
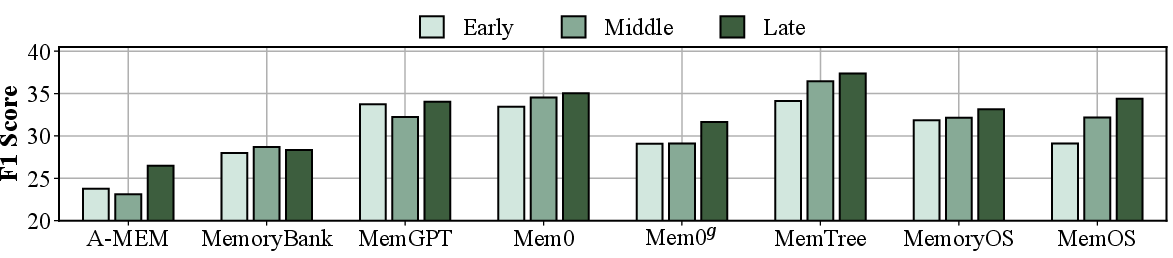
Figure 7: Context scalability under increased input scales, demonstrating the signal-to-noise limitations of different architectures.
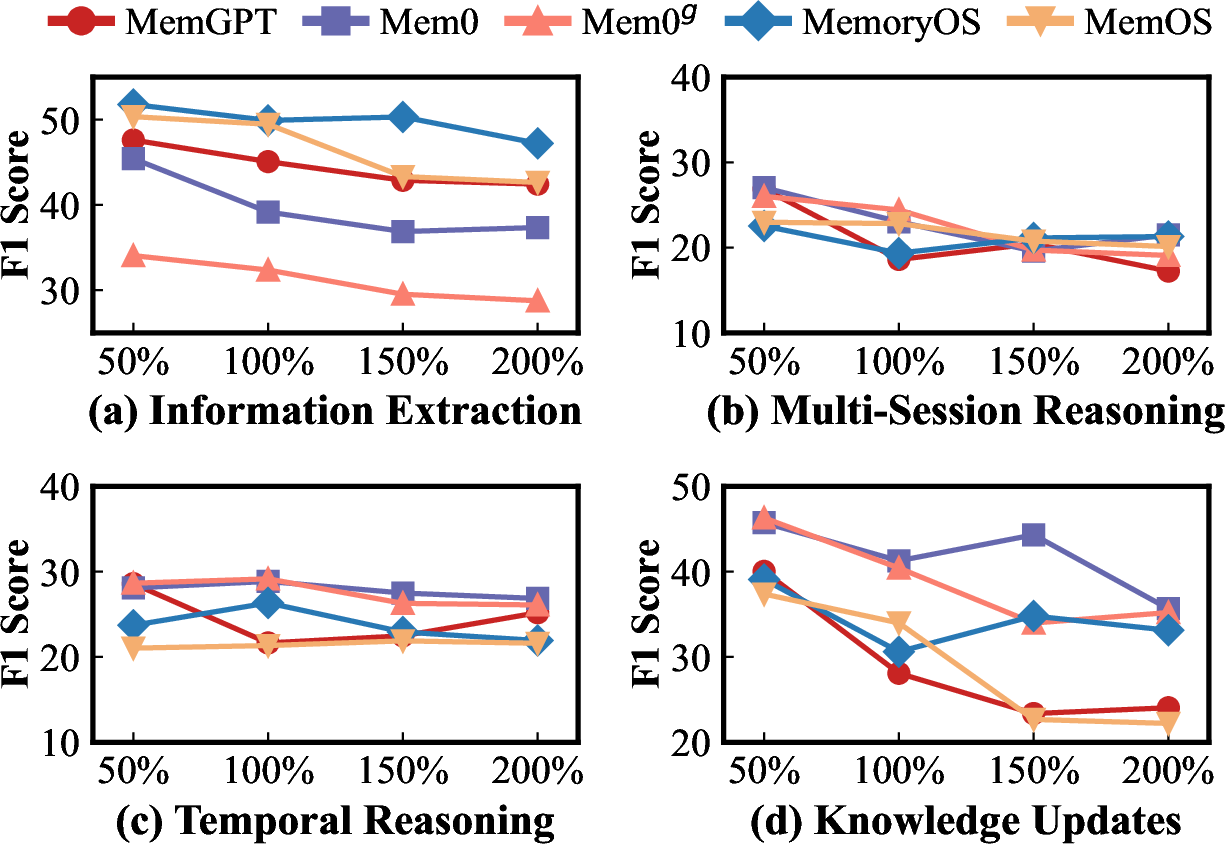
Figure 8: Comparative context scalability of memory methods across sub-tasks in LONGMEMEVAL, revealing task-specific degradation profiles.
State-of-the-Art Algorithmic Advances
The paper introduces a modular hybrid method that fuses segment-level, tree-based organization with a hierarchical short/mid/long-term store. Key design elements include:
- Short-term FIFO for immediate context continuity.
- Mid-term memory tree where each leaf represents a semantically coherent segment (not individual turns) and parents store summarized aggregates.
- Promotion to Long-term based on heat (access frequency/recency), supporting long-range retention without excessive cost.
- Dual-mode Retrieval: Combination of flat vector search, tree beam search, and standard vector search for each tier.
This approach yields:
- SOTA accuracy on both benchmarks, improving holistic F1 by up to 13% on certain categories.
- Token costs consistently below 450 per dialogue, in stark contrast to the previous best methods.
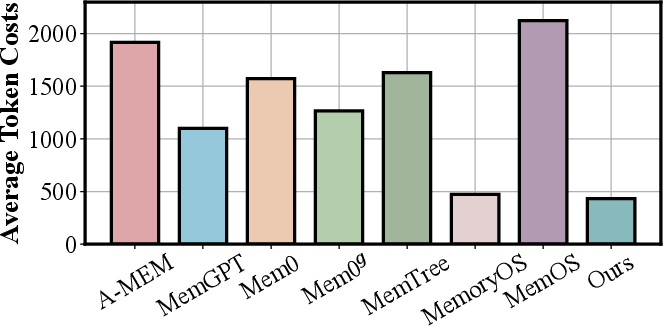
Figure 9: Token cost comparison for the newly designed SOTA method versus prior architectures, illustrating significant overhead reduction.
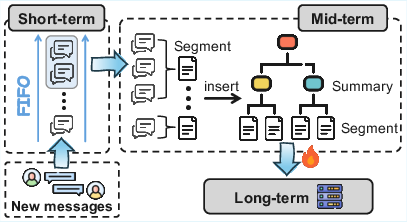
Figure 10: Architectural overview of the proposed SOTA memory system, highlighting three-level storage and dual-mode retrieval.
Implications and Theoretical Considerations
- Architectural Lessons: Hierarchical storage, explicit association, and coarse-granularity information extraction are central to scalable, accurate LLM-memory design.
- Memory Compression: There is an open challenge in compressing agentic memory in non-destructive ways that preserve historical facts while enabling recency preference and update annotation.
- Multimodal Extension: Existing paradigms are predominantly text-centric. Unified, multimodal memory mechanisms are essential for robust deployment in realistic settings.
- Retrieval Routing: Future work should address adaptive query-routing, balancing between semantic, structural, and generative retrieval strategies based on query/task characteristics.
- Benchmark Evolution: There is a clear call for memory evaluation suites that reflect the dynamic, open-ended, and multimodal nature of real-world interaction with LLM agents.
Conclusion
The paper provides the most comprehensive modular analysis and empirical comparison of agent memory architectures for LLM-based agents to date (2604.01707). The unified framework and experimental results highlight that hierarchical memory management and careful architectural modularization not only enhance accuracy and robustness but also yield order-of-magnitude improvements in computational efficiency. The SOTA method presented demonstrates that a judicious combination of structured storage, coarse-to-fine information granularity, and selective retrieval can substantially advance LLM agents' long-term reasoning abilities. The lessons and research opportunities articulated establish a well-defined roadmap for the future development of robust, efficient, and contextually adaptive memory systems in AI.