- The paper introduces GAM, a hierarchical graph-based agentic memory framework that decouples fast context encoding from semantic consolidation.
- The technique utilizes dynamic state transitions and graph-guided multi-factor retrieval to enhance long-term context retention and mitigate memory loss.
- Empirical evaluations demonstrate GAM's superior performance in temporal reasoning and multi-hop tasks while maintaining robustness under segmentation noise.
Hierarchical Graph-based Agentic Memory for LLM Agents: Technical Overview and Analysis
Long-range coherence and context retention remain critical impediments to deploying LLM agents in longitudinal, open-domain scenarios. Existing Unified Stream-based Memory Systems optimize for high-frequency context updates by directly appending new information into an active stream. However, such architectures are inherently susceptible to memory loss (the isolation and eventual forgetting of semantically distinct nodes) and semantic drift (the spurious merging or distortion of unrelated topics over time), ultimately leading to memory contamination and suboptimal agent consistency. Conversely, Discrete Structured Memory methods—such as static knowledge graphs—offer improved stability but lack agility in dynamically evolving environments, resulting in representations that fail to capture conversational progression.
The GAM (Graph-based Agentic Memory) framework directly addresses this conflict between plasticity (online adaptability) and stability (knowledge robustness) by explicitly decoupling fast context encoding from semantic consolidation, using hierarchical graph-based structures and dynamically triggered state transitions.
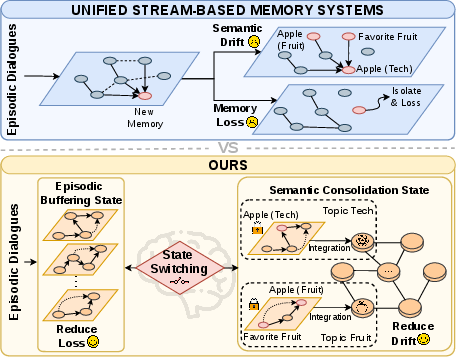
Figure 1: Unified stream-based memory updates (top) lead to memory loss and semantic drift; GAM (bottom) introduces state switching to minimize these phenomena via isolation and consolidation.
Hierarchical Memory Architecture
GAM’s memory system consists of three key components:
- Global Topic Associative Network (Gtopic): A persistent, graph-structured memory where each node corresponds to a high-level semantic cluster (or "topic") and edges denote semantic relations (scored via prompt-driven LLM calls).
- Local Event Progression Graph (Gevent): A rapidly mutating, append-only temporary buffer for atomic dialogue events (utterances or actions) and their causal/temporal links.
- Cross-layer Associations (Ecross): Index links connecting consolidated topic nodes to archived event subgraphs, ensuring episodic evidence remains accessible for future retrieval.
This structural separation provides strict write isolation and prevents temporary noise from corrupting long-term knowledge until semantic divergence justifies an update.
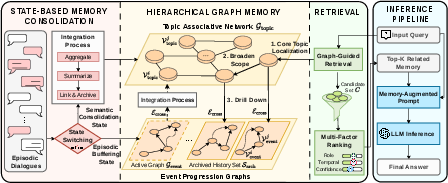
Figure 2: The GAM architecture: (left) state transitions triggered by detected topic boundaries; (center) separation of global topic graph and local event graphs; (right) graph-guided multi-factor retrieval.
State-based Memory Consolidation Mechanism
GAM models the conversational memory lifecycle as a finite-state system. For each input, it buffers new events in Gevent (Episodic Buffering State) until a semantic boundary (proxy for substantial topic shift) is detected. Semantic change detection is not tied to arbitrary window sizes but is implemented via prompt-driven LLM discrimination over buffered content, triggered sparsely (session breaks, natural pauses, buffer overflow).
Upon positive detection, the system transitions to the Semantic Consolidation State:
- Summarizes buffered events via LLM into a dual-component node:
- csum: Abstract summary for high-level reasoning.
- craw: Concatenated verbatim evidence.
- Integrates the new node into Gtopic via coarse-to-fine top-k candidate retrieval (embedding-based), followed by LLM-based semantic edge scoring over this subset only.
- After integration, the event graph snapshot is archived and cross-linked to the topic node, and the active buffer is reset.
This design ensures atomic, semantically-complete units enter long-term memory and minimizes risk of contamination or premature merging.
Graph-guided Multi-factor Retrieval
GAM retrieval operates in three stages:
- Semantic Anchoring/Expansion: Top-k relevant topic nodes are identified by vector similarity to the query. Their first-order semantic neighbors are also considered, leveraging graph structure for latent association discovery.
- Structural Drill-Down: Cross-layer links allow the agent to access the archived event subgraphs supporting each anchor node, ensuring episodic granularity.
- Multi-factor Re-ranking: Candidates are ranked by a base semantic probability (cross-encoder similarity) modulated by multiplicative boosting on three signals:
- Temporal alignment
- Role (speaker/interlocutor) congruence
- Intrinsic confidence (validated at encoding)
Hyperparameters (βtime, βrole, Gevent0) are tuned for stability, showing low sensitivity in empirical analysis.
This method supports precise, efficient retrieval—and addresses the chronic spurious match issues of naive similarity-based methods.
Empirical Evaluation and Ablation
GAM is evaluated on two benchmarks: LoCoMo (long open-domain dialogue, multi-category reasoning) and LongDialQA (multi-party TV script dialogue). Across all LLM backbones (Llama-3.2-3B, Qwen2.5-7B/14B, GPT-4o-mini), GAM achieves the highest or second-highest F1/BLEU-1 performance for nearly all categories, with the most substantial gains on Temporal and Multi-hop reasoning. Notably, on LoCoMo with Qwen2.5-7B, GAM outperforms Mem0 by 18% on Temporal F1.
Fixed window/session-based baselines underperform, confirming the importance of semantic-boundary-triggered consolidation for both accuracy and context coherence.
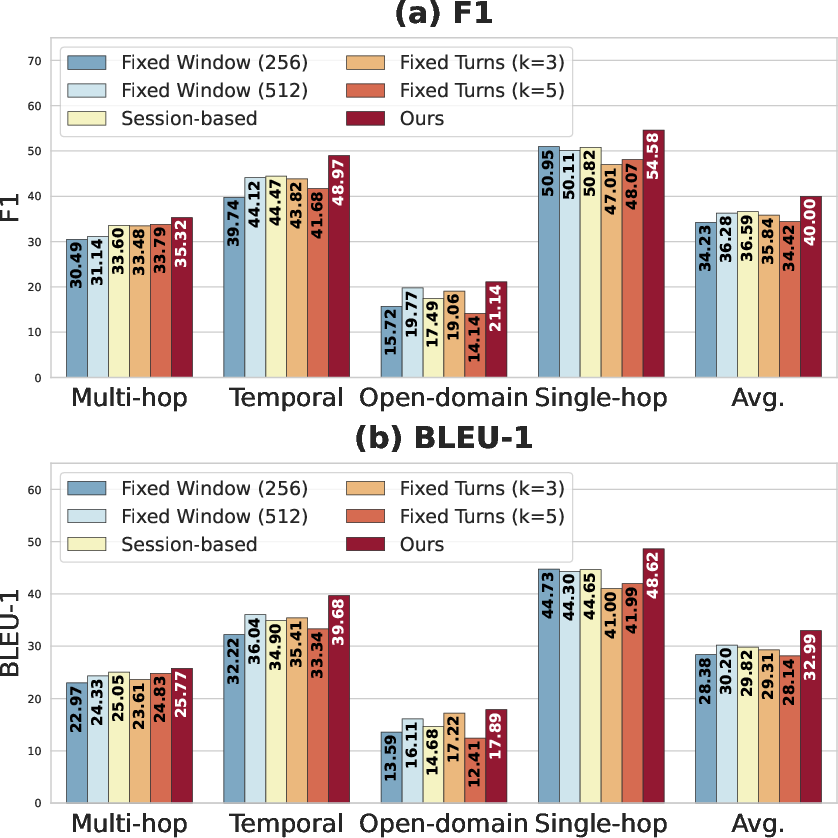
Figure 3: GAM's semantic-boundary-induced partitioning significantly outperforms all heuristic strategies across multiple reasoning metrics.
Robustness analysis under heavy segmentation noise (up to 40% artificial errors in topic boundaries) shows minimal degradation, with F1 scores remaining substantially ahead of fixed window/session alternatives.
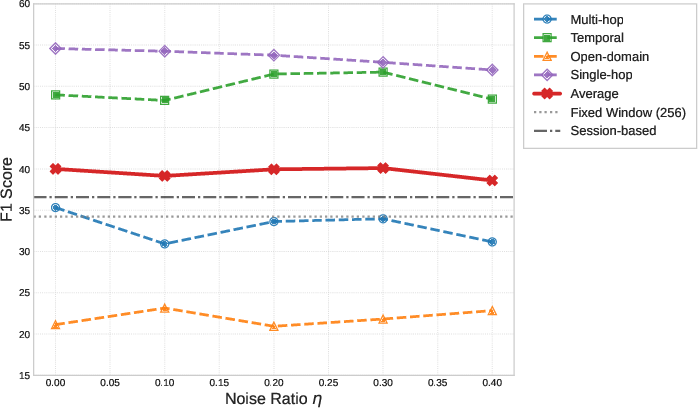
Figure 4: GAM exhibits strong resilience to boundary detection noise, indicating robust global memory organization.
Efficiency analysis demonstrates that GAM achieves the lowest token consumption per query—with only a minor increase in latency compared to the fastest baseline—while delivering higher accuracy. Ablation validates the necessity of each architectural component (topic network, event graph, semantic state switching mechanism [SSM], multi-factor retrieval).
Sensitivity and Hyperparameter Analysis
Parameter sweeps for the retrieval boosting factors and retrieval set size Gevent1 confirm insensitivity and flat optima, with Gevent2 balancing context diversity and computational cost.
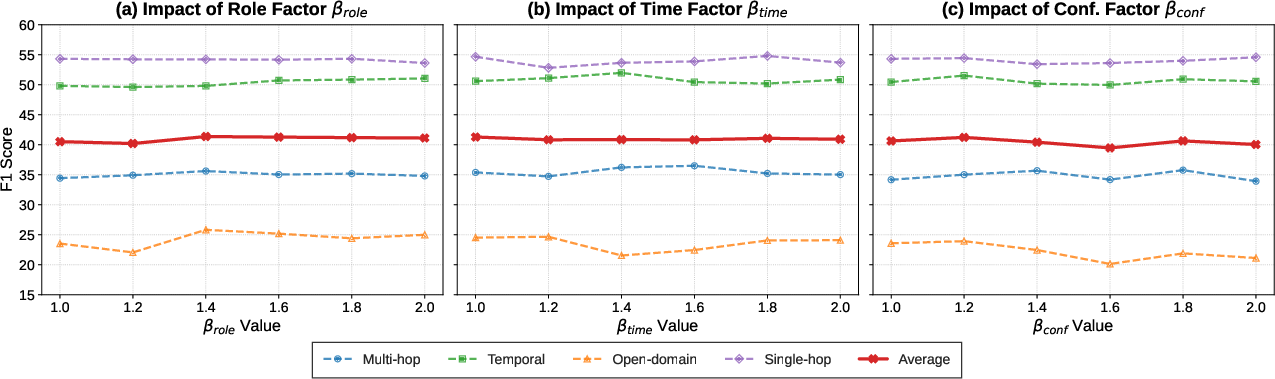
Figure 5: Retrieval modulation factors exhibit broad performance plateaus, indicating robust retrieval tuning.
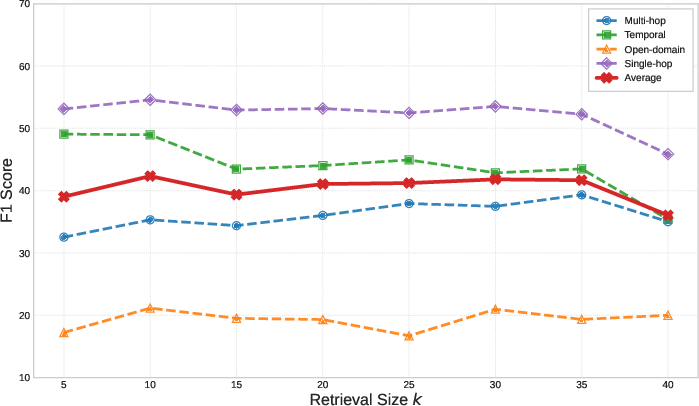
Figure 6: Varying retrieval set size Gevent3—performance peaks at Gevent4, after which further increases add noise.
Theoretical and Practical Implications
GAM advances agentic memory architecture by enforcing a clean separation of rapid context acquisition and stable semantic consolidation through dynamically-detected boundaries and hierarchical storage. This both models core principles in human cognition (buffering and consolidation reminiscent of sleep-dependent memory) and provides a scalable, practical substrate for text-based agents.
Practically, GAM offers:
- Improved robustness to conversational noise, conflicting themes, and speaker switching (critical for real-world deployment, e.g., conversational assistants, digital tutors).
- A graph substrate amenable to user interpretability, fine-grained editing, branch pruning, or selective redaction—essential for privacy, safety, and regulatory compliance.
From a theoretical perspective, the demonstrated stability under segmentation noise and model scale suggests the underlying memory organization is architecture driven, not reliant on beamwidth or backbone capacity.
Future Developments
Current implementation is text-only, limiting applicability in increasingly multimodal interaction settings. Extension to native multimodal memory nodes (text, audio, visual) is a logical continuation and would enable fine-grained context encoding across complex signals, making the architecture suitable for embodied AI and rich media agents. The explicit state-based boundary detection framework also suggests a route to improved privacy control and adaptive memory retention policies, especially if augmented with user-defined constraints and auditing hooks.
Conclusion
GAM establishes a hierarchical, graph-based memory paradigm that structurally resolves the trade-off between stability and plasticity in LLM agents. The combination of dynamic state transitions, semantic-boundary-triggered consolidation, and multi-factor retrieval yields superior long-term reasoning, memory robustness, and computational efficiency. While current limitations center on unimodality, the framework provides a strong, extensible foundation for robust, interpretable, and scalable agent memory in complex, evolving environments.