- The paper introduces a dual-stream framework that jointly synthesizes video and action trajectories using flow-matching-based denoising.
- It employs a diffusion transformer video stream and a modified 1D U-Net action stream to achieve strict temporal and semantic coherence.
- Experimental results show that VAG pretraining boosts real-world robotic policy success rates by 20% compared to traditional two-stage methods.
VAG: Dual-Stream Video-Action Generation for Embodied Data Synthesis
Introduction and Motivation
Efficient scaling of robot foundation models is fundamentally constrained by the intensive data collection required for each new scenario or task. Although advances in visual world models have enabled high-fidelity video generation, the lack of paired action trajectories limits their direct applicability for policy learning in robotic systems. World-Action (WA) and two-stage paradigms attempt to bridge this gap, but exhibit shortcomings in cross-modal video–action alignment and efficiency. The proposed VAG framework addresses these issues by introducing a dual-stream, flow-matching-based approach for joint video and action synthesis conditioned on vision and language, enabling high-quality, synchronized, and policy-usable data generation.

Figure 1: VAG’s capabilities: training on teleoperation, joint video–action trajectory generation from an initial frame and instruction, synthetic policy training data, and real-world robot execution as a policy.
Methodology
Flow-Matching Dual-Stream Architecture
VAG leverages a dual-branch generative architecture with perfectly synchronized denoising via flow matching. The video stream, inherited from Cosmos-Predict2, predicts temporally coherent video conditioned on an initial frame and language instruction, using diffusion transformer-based denoising in the latent space. The language embedding is encoded via T5-XXL and added through cross-attention, and classifier-free guidance enhances text-video alignment.
Simultaneously, the action stream generates action sequences by conditioning on an adaptive 3D pooled global latent embedding from the video branch. This global condition, produced by non-parametric pooling across all visual spatiotemporal tokens, injects compact yet meaningful trajectory-level video context into the action denoiser. The action denoiser is a modified 1D U-Net from Diffusion Policy. This tightly-coupled joint denoising facilitates strict temporal and semantic coherence between generated video and actions, circumventing the cross-modal mismatch and error accumulation seen in two-stage approaches.
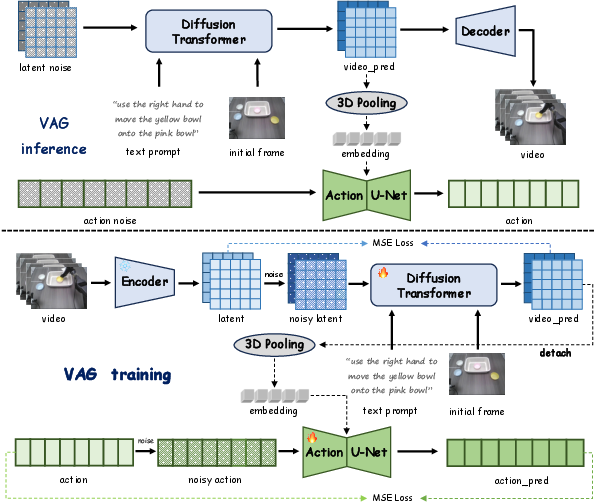
Figure 3: Overview of VAG’s generative inference and training: synchronized denoising in both the video and action streams using flow matching.
Training
Training is executed using paired video-action demonstrations and their auto-generated language instructions. The video stream is pretrained on foundation model weights to leverage robust visual priors and trained with an MSE loss over flow-matching velocities in latent space, post VAE-tokenization, and noise perturbation. The action branch, conditioned on global video embedding, also employs an MSE loss over the denoising trajectory. This configuration enforces strong cross-modal supervision at every generation step.
Experimental Results
Datasets and Baselines
Experiments cover the AgiBot real-world dataset, the LIBERO simulation suite, and a dual-arm real robot dataset. Comparisons are drawn against SOTA models: SVD, Wan2.2, Cosmos-Predict2 for video prediction; and two-stage action prediction pipelines (VAG-video + ResNet, AnyPos), as well as policy-centric VLA (π0.5).
Video Generation Quality
VAG surpasses or matches top diffusion-based video synthesis models on standard metrics (FVD, FID, LPIPS, SSIM, PSNR). VAG-produced video demonstrates strong prompt adherence and substantial long-horizon temporal coherence (approx. 10 seconds per sequence).

Figure 2: Qualitative comparison of VAG output with alternative video generation approaches for a complex manipulation prompt.
Action Trajectory Alignment and Use as Policy
Joint trajectory generation achieves lower Euclidean Distance and higher success rate than two-stage methods on both real and simulated tasks. Aligned video–action pairs enable robust simulated and real-world replay: the predicted actions track ground truth both in gross motion trend and fine-grained variation.
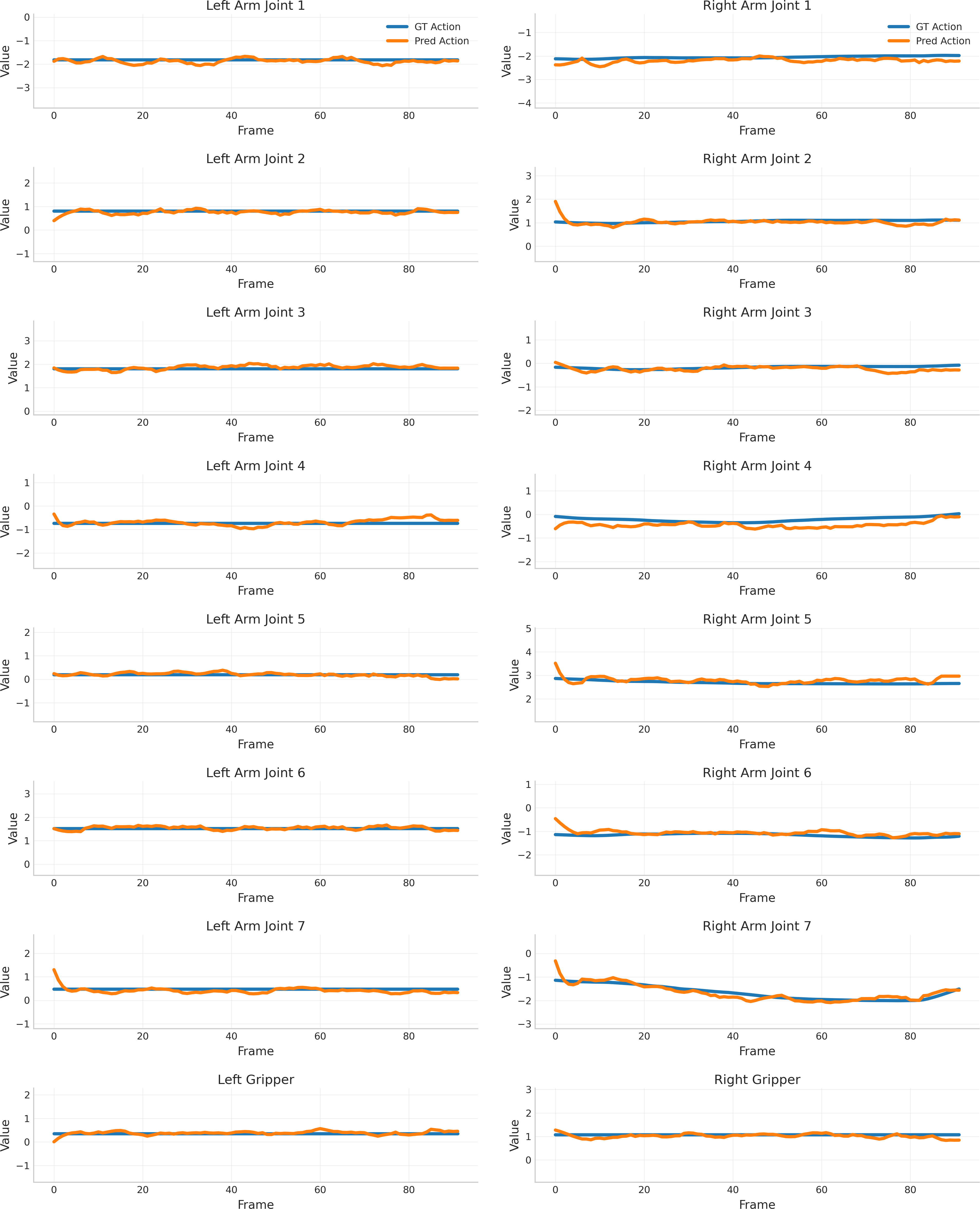
Figure 6: Alignment between predicted and ground-truth actions across all 16 robot DoFs for a real-world grasping task.

Figure 4: Visualizations of generated sequences and trajectory replay in the LIBERO simulation environment.
Synthetic Data for Policy Pretraining
VAG-generated data, when used to pretrain downstream VLA policies, accelerates real-world policy convergence and increases success rate on transfer tasks from 35% to 55% (+20% absolute). This demonstrates that high-fidelity synthetic video-action sequences measurably improve exploration and generalization.

Figure 5: Real-world VLA policy success rates before and after VAG-based synthetic pretraining.
Direct Deployment: Serving as a World-Action Policy
Deploying joint video–action outputs from VAG directly as open-loop policies on a dual-arm manipulator, across left, right, and bimanual scenarios, produced coherent robot behaviors tightly matching the generated video, validating practical executability of the model’s generative policy.

Figure 7: Representative deployment examples showing input frames, generated video, predicted action trajectory, and real robot execution.
Implications and Future Directions
Practical Implications: VAG forms an end-to-end pipeline from data collection (via teleoperation) to policy evaluation (via generated trajectory replay) that is robust to distributional shifts and supports scalable data augmentation for embodied agents. It avoids inefficiencies and cross-modal drift typical in two-stage systems, producing high-quality data for both offline and online reinforcement learning frameworks.
Theoretical Implications: This architecture embodies a key shift toward joint generative modeling of sensory and control signals for embodied AI, suggesting that tight coupling and global cross-modal context induction are crucial for structured robotic data synthesis. The use of adaptive pooling (without additional learnable parameters) for global context transfer between modalities contributes a practical, generalizable design pattern for cross-modal generation architectures.
Limitations and Future Research: The principal limitation is the asymmetric conditioning—action generation is video-aware, but video generation is not reciprocally modulated by actions, potentially constraining inter-modal alignment. Addressing this via bidirectional conditioning, extending DiT capacity to the action stream, and scaling to more challenging, unstructured environments are promising next steps.
Conclusion
VAG presents a unified, scalable, and effective approach for joint video–action synthesis in robot learning. By tightly aligning video and action across multimodal trajectories using synchronized, flow-matching-based denoising, VAG outperforms multi-stage and single-modal baselines on both prediction and policy-learning tasks. These results position VAG as a practical engine for embodied data synthesis and pave the way for more robust, simulation-to-real transfer and rapid policy generalization in embodied AI systems (2604.09330).