Solving Physics Olympiad via Reinforcement Learning on Physics Simulators
Abstract: We have witnessed remarkable advances in LLM reasoning capabilities with the advent of DeepSeek-R1. However, much of this progress has been fueled by the abundance of internet question-answer (QA) pairs, a major bottleneck going forward, since such data is limited in scale and concentrated mainly in domains like mathematics. In contrast, other sciences such as physics lack large-scale QA datasets to effectively train reasoning-capable models. In this work, we show that physics simulators can serve as a powerful alternative source of supervision for training LLMs for physical reasoning. We generate random scenes in physics engines, create synthetic question-answer pairs from simulated interactions, and train LLMs using reinforcement learning on this synthetic data. Our models exhibit zero-shot sim-to-real transfer to real-world physics benchmarks: for example, training solely on synthetic simulated data improves performance on IPhO (International Physics Olympiad) problems by 5-10 percentage points across model sizes. These results demonstrate that physics simulators can act as scalable data generators, enabling LLMs to acquire deep physical reasoning skills beyond the limitations of internet-scale QA data. Code available at: https://sim2reason.github.io/.



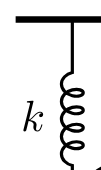











Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to teach AI to solve tough physics problems (like Physics Olympiad questions) without relying on tons of human-written practice problems. Instead, the authors use a computer physics simulator—think of it like a very accurate “video game physics engine”—to automatically create many realistic physics situations, turn those into questions with correct answers, and train an AI to reason step by step using rewards for correct solutions. They call this approach Sim2Reason.
What questions did the authors want to answer?
The authors focused on a few simple but important questions:
- Can we use physics simulators to automatically generate high‑quality practice questions for an AI, so we don’t depend on limited internet or textbook problems?
- If we train an AI only on this simulator-made data, will it still get better at real, human‑written physics problems?
- Which training methods and question types help the AI learn the most useful physics reasoning skills?
How did they do it?
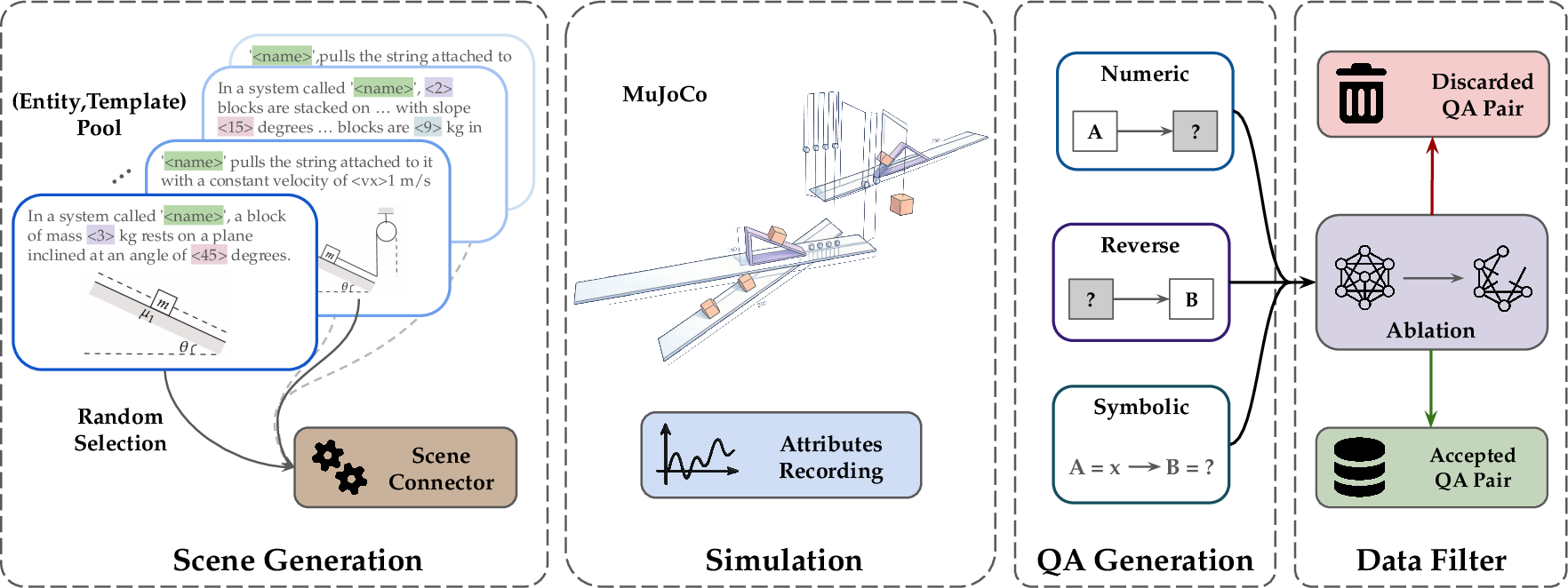
Building lots of physics problems automatically
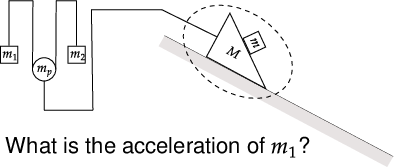
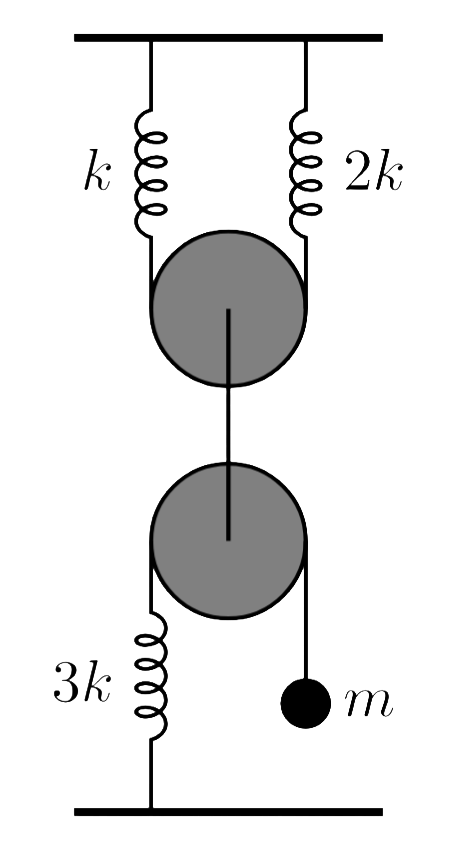
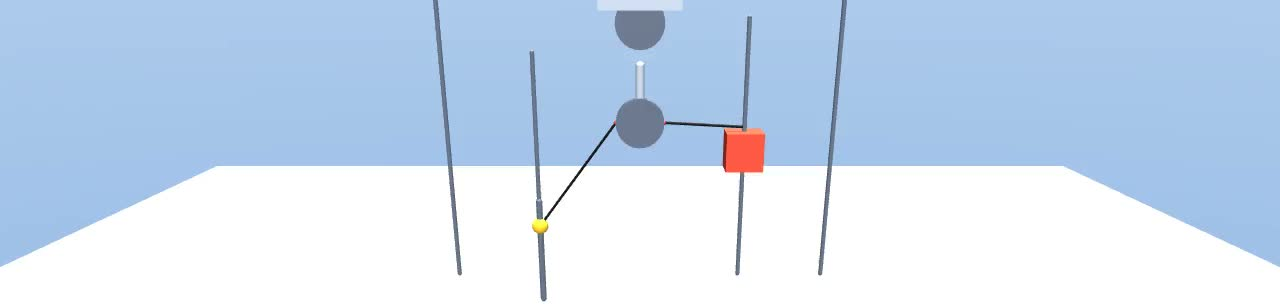
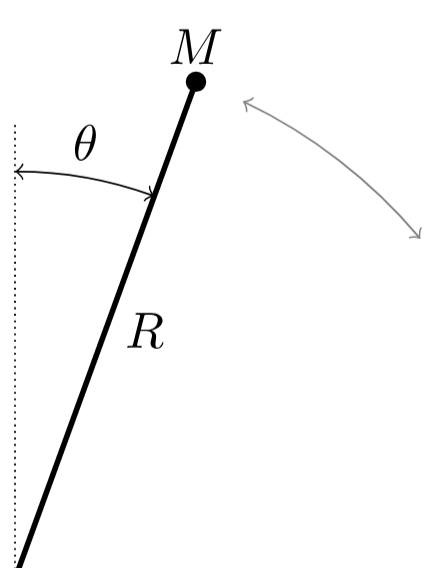
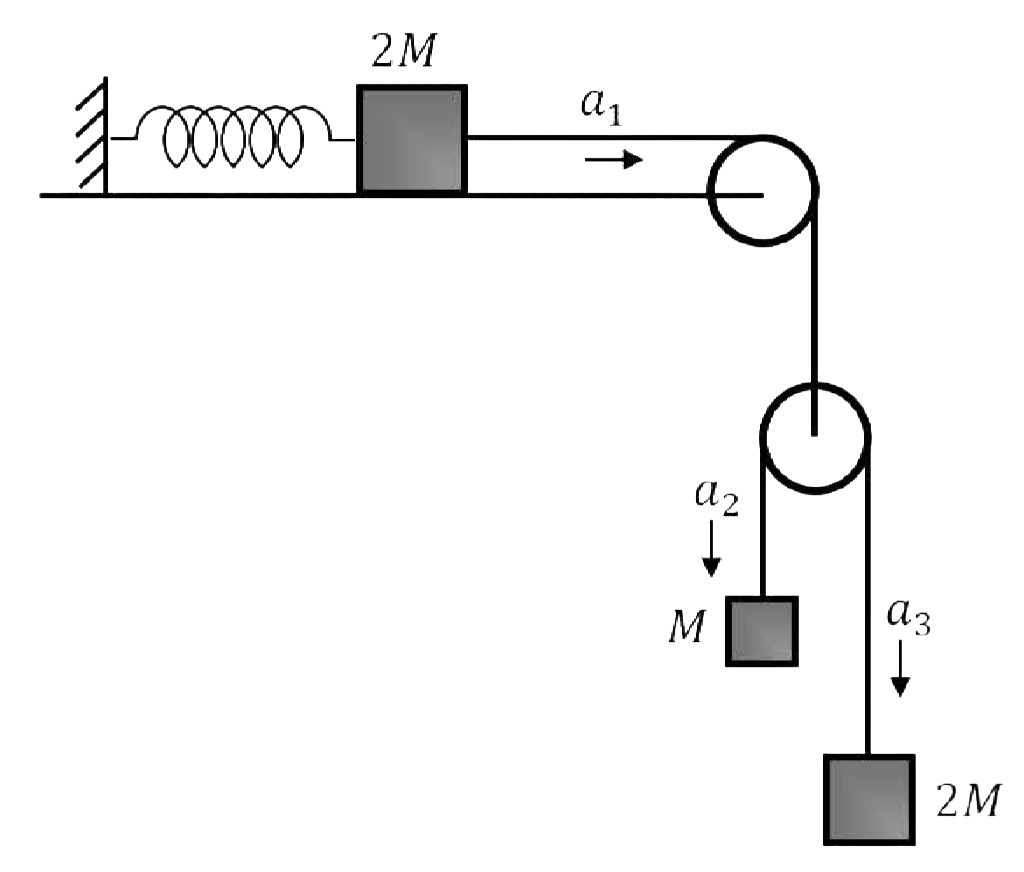
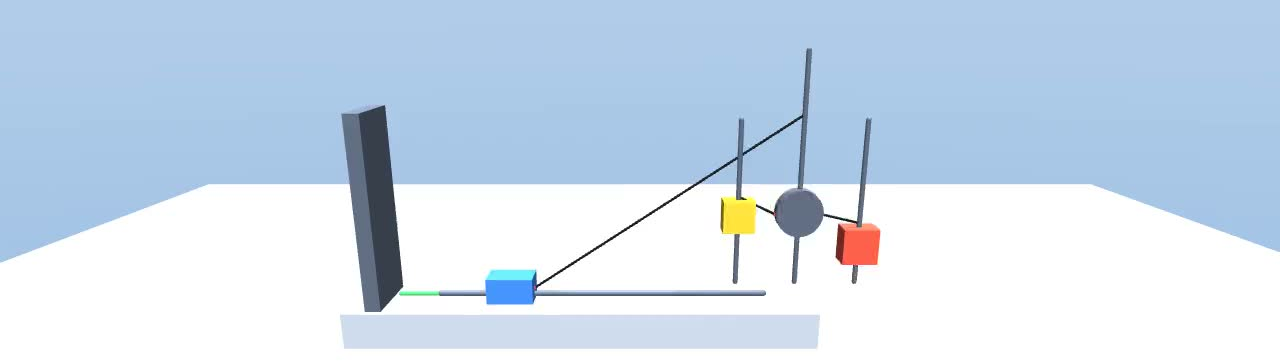
The team created a “recipe language” (called a DSL) that lets them assemble physics scenes from building blocks—like masses, pulleys, springs, ramps, and rotating parts. It’s like having Lego pieces for physics. They connect these pieces in meaningful ways so the scenes are realistic and varied.
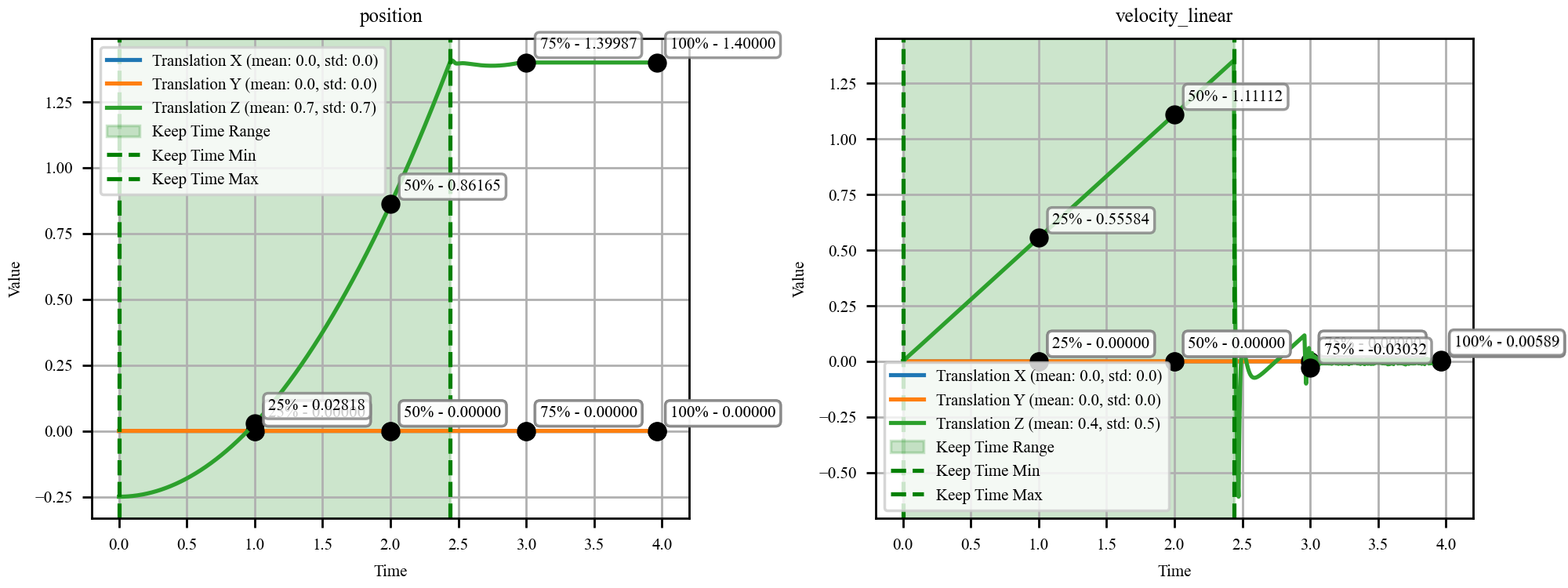
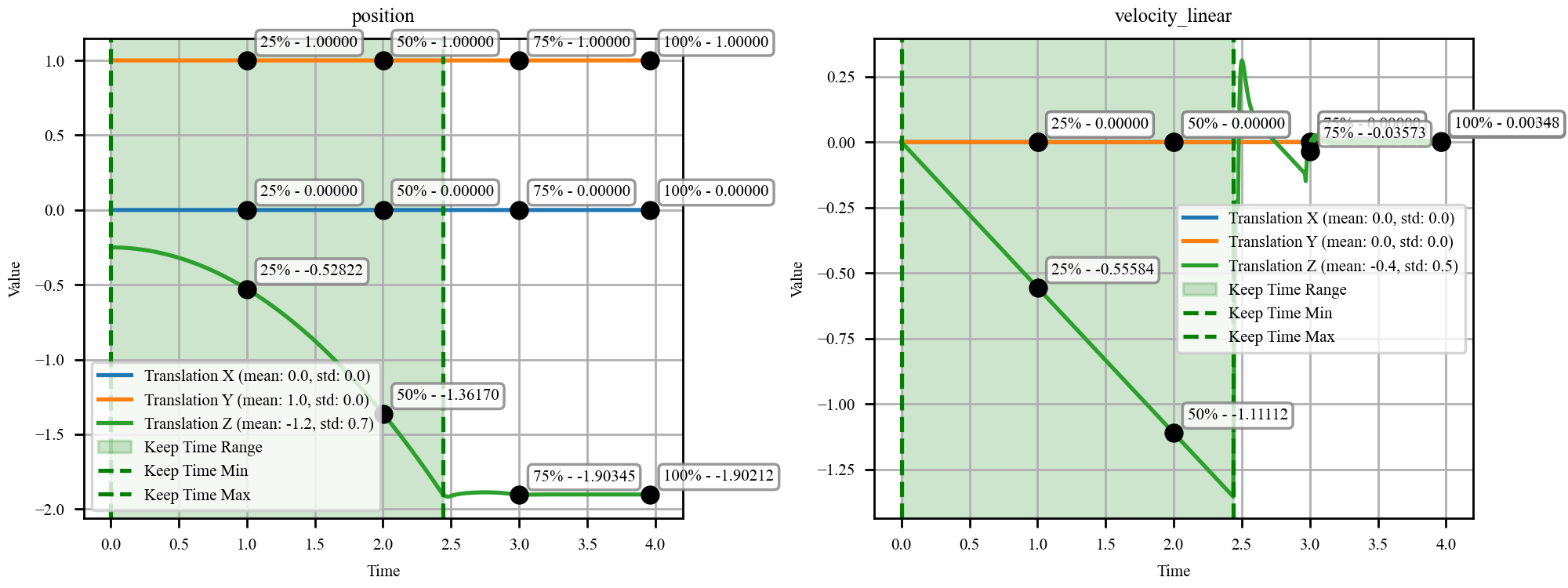
They then compile these scenes into MuJoCo, a physics engine that simulates motion and forces over time.
Turning simulations into questions
As the simulator runs, it records things like positions, speeds, accelerations, forces, and string tensions. From this, the system automatically writes natural-language question–answer pairs in three styles:
- Numeric (forward): “What is the speed of block A at 3 seconds?”
- Reverse (inference): “If the speed at 3 seconds is 5 m/s, what must the mass be?”
- Symbolic (formula): “What is the speed after time t in terms of m, g, and L?”
Because the simulator knows the true values, it can provide the correct answers instantly.
Throwing out bad or “shortcut” questions
Not all generated questions are useful. Some are too easy, too weird, or can be solved by ignoring most of the setup (a “shortcut”). For example, a problem might accidentally allow you to pretend two connected objects are just one big object and still get the right number. To prevent the AI from learning lazy tricks, the authors:
- Remove questions that don’t really depend on the whole scene.
- Remove unstable or glitchy parts of simulations (for example, sudden spikes when something collides unexpectedly).
- Keep questions in a “sweet spot” of difficulty.
Training the AI with rewards
They fine‑tune LLMs using reinforcement learning with verifiable rewards. In plain terms:
- The AI tries to solve a question and gives a final answer.
- The simulator acts like an instant teacher: if the answer is within about 5% of the true value, the AI gets a “reward”; otherwise, no reward.
- Over many tries, the AI learns to reason more carefully to earn more rewards.
This is different from simply copying solutions (supervised learning). Here, the AI explores different solution paths and gets feedback only based on whether the final answer is correct, which encourages genuine problem-solving.
What did they find?
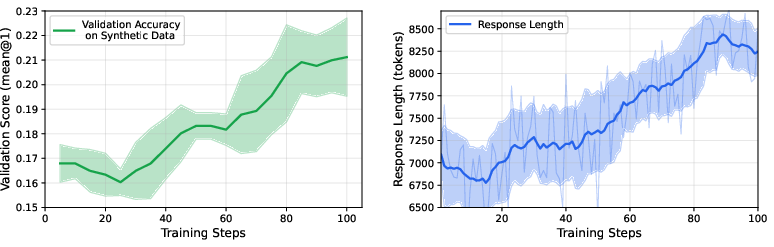
Across several tests, the AI trained with Sim2Reason got better at real physics problems—even though it was trained only on synthetic (simulator-made) questions:
- On International Physics Olympiad (IPhO) mechanics problems, scores improved by about 5–10 percentage points for models of many sizes.
- On JEEBench (a tough exam set), one model improved by +17.9 percentage points.
- There were also gains on other physics sets (like PHYSICS and OlympiadBench) and even small improvements on math benchmarks, suggesting better general step‑by‑step thinking.
They also found:
- Reinforcement learning worked better than standard “copy the teacher” training, which sometimes made the model worse on real problems.
- Training on numeric questions gave the strongest transfer to real exams.
- Filtering out shortcut/degenerate questions was crucial; without that filter, gains were much smaller.
- Performance on simulator-made questions was strongly correlated with performance on real IPhO problems. This means the simulator can double as a fast, scalable way to test and compare models.
Why does this matter?
This work shows a practical path to grow AI’s scientific reasoning without depending on scarce, human-annotated datasets. Key takeaways:
- Scalable practice: Physics engines can generate endless, diverse, and correct practice questions, covering many classic mechanics topics (kinematics, rotation, collisions, orbits, and more).
- Real-world transfer: Skills learned from simulated worlds carry over to human-written exam problems—no special “tricks” needed.
- Better training recipe: Reward‑based training that checks final answers helps AI develop deeper problem‑solving, not just memorization.
- New toolkit: Because simulator results track real performance, researchers can quickly test ideas and diagnose strengths/weaknesses by topic (e.g., springs, pulleys, rotation) without waiting for new curated datasets.
In short, Sim2Reason turns a physics simulator into both a teacher and a grader. It gives AI unlimited hands-on physics practice and helps it become better at the kind of careful, step-by-step reasoning needed for real competitions like the Physics Olympiad.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unanswered questions that the paper leaves open, organized by theme to guide follow‑up research.
Simulator fidelity and coverage
- Unvalidated simulator fidelity: no quantitative calibration of MuJoCo (and custom extensions) against analytic solutions across covered phenomena (e.g., pulleys, collisions, rotation), nor sensitivity to integrator, timestep, and solver settings.
- Electromagnetism support is underspecified: the paper claims “basic electromagnetism” and “time‑varying fields” but provides no technical description, validation, or examples; applicability and numerical accuracy remain unclear.
- Limited physics domains: no coverage or experiments for thermodynamics, fluids, elasticity/deformables, waves/optics, complex circuits/Maxwell equations, non-inertial frames, or continuum mechanics—how to extend the pipeline to these domains?
- Contact and discontinuities are largely avoided by truncation heuristics; it is unknown whether models learn robust reasoning for non-smooth dynamics (impacts, stick–slip friction, rolling transitions) rather than learning on sanitized segments.
- Realism of non-idealities: friction, air drag, rolling resistance, restitution, and damping distributions are not detailed or validated; their realism and effect on transfer to real problems are unknown.
DSL and data generation design
- DSL bias and coverage: no empirical audit of whether the DSL’s “physically meaningful” randomization axes yield sufficient diversity and avoid hidden shortcuts or biases; how to systematically measure and expand DSL coverage?
- Natural language template artifacts: scene and question templates may produce stylistic cues not present in real Olympiad text; no paraphrase/stylistic augmentation study quantifies template-induced distribution shift.
- Degeneracy pruning criteria are under-specified beyond spike detection; formal definitions and thresholds for “trivially easy” or “intractable” problems are not provided, nor their impact on learning.
- Shortcut detection incompleteness: current ablations (entity/joint removal) may miss subtle solvability shortcuts (e.g., implicit symmetries, effective-mass reductions); need broader counterfactuals or dependence tests (e.g., mutual information or differentiable causal ablations).
QA formats and verification
- Reverse QA identifiability: no analysis ensures parameter inference problems are well-posed (uniqueness, observability) or conditioned; how to construct identifiably invertible scenes and certify them?
- Symbolic QA verification is undeveloped: no symbolic reward/checking pipeline (e.g., CAS-based equivalence up to algebraic identities, dimension checks); how to robustly grade and train for closed-form reasoning?
- Units and dimensional correctness are not explicitly graded; adding unit-aware verification and dimensional-analysis rewards may improve robustness—this is not explored.
RL training and optimization
- Reward tolerance choice (±5% relative): no sensitivity analysis on learning dynamics, solution strategies, or reward hacking; how do tighter/looser tolerances affect outcomes, especially under simulator noise?
- RL hyperparameters are underspecified (group size G, sampling temperature, clip ε, KL control, reference blend, advantage normalization details, entropy bonuses); no sensitivity/ablation study to guide practitioners.
- DAPO-style dynamic sampling is mentioned but not detailed (trigger criteria, resampling budget, effect sizes); its contribution remains unquantified.
- Training scale and sample efficiency: results use ~6.4K prompts per run; no scaling curves over prompts, steps, or mixture schedules; how do gains evolve with 10×–100× more synthetic data?
- Long response length vs accuracy: correlation is shown, but causality is untested; do length caps or penalties reduce gains, and can structured intermediate rewards substitute for verbosity?
Evaluation methodology and robustness
- Statistical rigor is limited: no multiple seeds, confidence intervals, or significance tests; improvements of 2–5 percentage points may be within variance—how stable are results across runs?
- Answer extraction and grading details for real datasets are not specified (unit normalization, numeric tolerance, multi-part scoring, exact-match parsing); replicability and fairness are uncertain.
- Use of GPT‑4o-generated figure captions may introduce leakage or paraphrasing bias; impact on evaluation fidelity is untested; how do results change with human or sanitized captions?
- PHYSICS grading uses an LLM verifier (Gemini 2.5 Flash) without inter-verifier agreement or robustness checks; need rule-based/CAS graders or cross-grader validation.
- Correlation between synthetic and real benchmarks (ρ=0.79) lacks sample size, CIs, and cross-family validation; robustness across model families/sizes remains unknown.
- General capability retention is only lightly probed (AIME, MATH); broader regressions (e.g., MMLU, instruction following, safety) are unmeasured.
Generalization, transfer, and analysis
- Diagram grounding is absent: evaluations avoid visual problems; it remains open whether sim-generated rendered diagrams plus multimodal RL improve transfer on diagram-dependent tasks.
- Failure mode taxonomy is qualitative; no quantitative error analysis by phenomenon (e.g., collisions vs rotation), regime (e.g., low/high friction), or step type (kinematics vs force balance) to prioritize DSL expansions.
- Compositional generalization: no stress tests for novel compositions of entities or adversarial paraphrases; do gains hold under deliberately out-of-template problems?
- Hybrid tool-use pathways: the paper dismisses simulator-as-tool due to code-gen difficulty, but does not explore intermediate/hybrid approaches (e.g., DSL-assisted tool use, constrained code generation, execution-feedback loops).
Portability and reproducibility
- Cross-engine consistency is largely anecdotal; no quantitative comparison of trajectories/answers across MuJoCo vs Omniverse for the same DSL scene and parameters.
- Reproducibility gaps: several implementation details (random seeds, data dedup metrics, tokenizer specifics, exact prompts/templates, simulator patches for gravity/variable mass/EM) are not fully specified; end-to-end reproducibility is uncertain.
- Licensing and dataset release scope: it is unclear which synthetic corpora, DSL libraries, and trained checkpoints will be released and under what terms, limiting external validation.
Future training signals
- Beyond final-answer rewards: unexplored stepwise verifiable rewards (e.g., conservation checks, constraint satisfaction, unit consistency) that may teach physically grounded intermediate reasoning with less verbosity.
- Curriculum and ability matching: no adaptive difficulty or phenomenon-targeted curricula; do curricula improve stability and transfer compared to uniform random sampling?
These targeted gaps suggest concrete next steps: broaden physics coverage with validated simulators/solvers, develop CAS- and unit-aware verifiers for symbolic/units training, run rigorous multi-seed ablations with transparent hyperparameters, incorporate multimodal diagram grounding, and expand the DSL while auditing for biases and shortcut leakage.
Practical Applications
Immediate Applications
Below are actionable, deployable uses of the paper’s Sim2Reason framework (DSL-driven scene generation + MuJoCo simulation + QA synthesis + RL with verifiable rewards) and its findings on sim-to-real transfer.
- Physics practice and tutoring at scale (Education)
- What: Auto-generate unlimited, diverse, verifiable physics problems (numeric/reverse/symbolic) with solutions and difficulty control via pruning; create adaptive tutors that improve step-by-step reasoning.
- Tools/Workflows: LMS plugins that call the DSL→MuJoCo→QA pipeline; auto-graders with ±5% numeric tolerance; spaced/competency-based assignment generators.
- Assumptions/Dependencies: Coverage is strongest in classical mechanics; requires simulator backend (e.g., MuJoCo) and compute for on-demand generation; symbolic verification is harder than numeric.
- Reliable, fast STEM benchmarking for LLMs (Software, Academia, AI labs)
- What: Use simulator-generated QA as a continuous integration testbed for physics reasoning; track capability by phenomenon (pulleys, collisions, rotation) with automatic answer verification.
- Tools/Workflows: Benchmark-as-a-service dashboards; per-entity scorecards; A/B evaluation harnesses; correlation to real benchmarks (IPhO) supports model selection.
- Assumptions/Dependencies: Validity depends on DSL coverage and shortcut filtering; correlations reported for mechanics may not generalize to all STEM subfields.
- Synthetic data nodes for RL post-training (AI/Software)
- What: Integrate Sim2Reason data into RLVR (e.g., GSPO) pipelines to strengthen multi-step quantitative reasoning and reduce reliance on scarce internet QA.
- Tools/Workflows: RLVR training with group sampling, dynamic sampling (DAPO-style), correctness-based rewards with numeric tolerance; mixed curricula with existing math datasets.
- Assumptions/Dependencies: Requires base model and RL compute; reward hacking is mitigated by shortcut pruning; out-of-domain generalization depends on scene diversity.
- Internal training and assessment for engineers (Automotive, Aerospace, Energy)
- What: Customized mechanics problem sets for onboarding and continuing education; randomized-but-equivalent variants to reduce content leakage in certifications.
- Tools/Workflows: Corporate LMS integrations; item banks tagged by skill/phenomenon; auto-generated solution keys with visible chains of reasoning.
- Assumptions/Dependencies: Domain specificity—today’s pipeline mostly covers mechanics; SMEs may need to extend DSL/entities for sector-specific phenomena.
- Hiring and credentialing tests with leakage resistance (Industry HR/TA, Academia)
- What: Dynamic, procedurally generated physics assessments that are resistant to memorization and content sharing, with auto-scoring.
- Tools/Workflows: Proctored testing portals; on-the-fly scene generation seeded per candidate; item analysis using simulator metadata.
- Assumptions/Dependencies: Testing policies must accept synthetic items; fairness validation needed across cohorts and languages.
- Red-teaming and plausibility checks for physical reasoning (Safety, Policy, Software QA)
- What: Evaluate whether LLMs propose physically implausible or unsafe solutions under constrained scenarios (e.g., collisions, friction limits).
- Tools/Workflows: Scenario libraries targeting failure modes; pass/fail gates in model release pipelines; thresholds on error bands and constraint violations.
- Assumptions/Dependencies: Focused on mechanics; extending to safety-critical regimes (e.g., structural loads, aero) requires additional simulators/entities.
- Research instrumentation for studying reasoning biases (Academia)
- What: Use entity- and joint-removal ablations to identify shortcut pathways and quantify robustness to spurious cues.
- Tools/Workflows: Experiment suites that auto-generate ablated variants; analysis of answer invariance; reporting by failure type.
- Assumptions/Dependencies: Findings tied to the DSL’s abstraction boundaries; requires careful design to avoid over-pruning.
- Early-stage support for robotics reasoning (Robotics)
- What: Pretrain language planners on physically grounded QA to improve commonsense about forces, friction, and kinematics before policy learning.
- Tools/Workflows: Incorporate Sim2Reason-generated traces in instruction/RL datasets for task planning; evaluate with simulator-based tests.
- Assumptions/Dependencies: Sim-to-real gap remains; not a substitute for low-level control learning; coverage limited to modeled entities.
- Teacher tools for interactive labs (Education, Daily life)
- What: Generate virtual lab scenarios with measured traces and guided questions; exportable as worksheets or interactive notebooks.
- Tools/Workflows: Teacher-facing DSL presets; time-series visualizations; student activities with instant feedback.
- Assumptions/Dependencies: Requires school IT to host or access simulations; alignment to standards/curricula needed.
Long-Term Applications
These use cases require further research or engineering (e.g., new entities, simulators, or verification tools), but are natural extensions of the paper’s innovations.
- Multi-physics and cross-science expansion (Healthcare, Materials, Energy)
- What: Extend DSL and reward design to electromagnetism, fluids, thermodynamics, materials, and molecular dynamics for chemistry/biophysics.
- Tools/Workflows: Multi-simulator backends (e.g., NVIDIA Omniverse, Ansys, OpenFOAM, LAMMPS); domain-specific verification strategies (symbolic solvers, PDE-based validators).
- Assumptions/Dependencies: High-fidelity simulators and vetted entities; expert curation for correctness; more complex rewards than ±5% numeric tolerance.
- Physics-aware design copilots integrated with CAE/CAD (Manufacturing, Aerospace, Automotive)
- What: LLM assistants that reason about dynamics during conceptual design and run quick checks/sensitivity analyses.
- Tools/Workflows: Plugins for CAD/CAE (e.g., Omniverse, SolidWorks, Ansys) coupling natural-language reasoning with in-situ simulations; inverse design using reverse-QA for parameter inference.
- Assumptions/Dependencies: Robust tool-use and API control; traceable reasoning; liability and verification frameworks for engineering sign-off.
- Digital twins with QA-driven operator training (Industrial IoT, Energy, Smart Infrastructure)
- What: Use digital twins to generate scenario-based drills with automatically verifiable outcomes for operators and controllers.
- Tools/Workflows: DSL mappings to plant assets; event libraries (faults, parameter drifts); operator scoreboards and remediation plans.
- Assumptions/Dependencies: Twin fidelity and domain coverage; secure integration with OT; rigorous safety validation.
- Standardized, simulator-backed certification for AI procurement (Policy, Standards)
- What: Regulator- or industry-backed physics reasoning suites for certifying LLMs used in education, engineering, or advisory roles.
- Tools/Workflows: Public leaderboards; stratified test sets with psychometric calibration; conformance profiles by domain.
- Assumptions/Dependencies: Consensus on benchmarks and acceptance criteria; governance for updates; transparency of simulator assumptions.
- Robotics planners with physics-grounded chain-of-thought and tool use (Robotics)
- What: Planners that translate scene descriptions to DSL, run brief simulations, and reason about outcomes before executing in the real world.
- Tools/Workflows: Closed-loop tool-use agents combining perception→DSL→sim→plan; on-robot validation via onboard sensing.
- Assumptions/Dependencies: Robust perception-to-DSL translation; fast, differentiable or approximate simulators; sim-to-real transfer for contact-rich tasks.
- Automated textbook and assessment generation with adaptive psychometrics (Education/EdTech)
- What: End-to-end generation of textbooks, question banks, and adaptive exams with calibrated difficulty and coverage.
- Tools/Workflows: Content authoring pipelines; psychometric models aligned to simulator-derived difficulty estimates; cross-language templating.
- Assumptions/Dependencies: Acceptance by accreditation bodies; extensive bias/fairness audits; teacher oversight.
- Scientific discovery assistants (Academia, R&D)
- What: Use synthetic reverse and symbolic QA modes for hypothesis testing and inverse design (e.g., identify parameters to achieve target trajectories).
- Tools/Workflows: Hybrid symbolic-numeric solvers; automated experiment planning with simulators-in-the-loop; uncertainty quantification.
- Assumptions/Dependencies: High-fidelity multi-physics; trustworthy symbolic derivations; integration with lab automation.
- Safety cases for autonomy with physics reasoning tests (Autonomous Driving, Aerospace)
- What: Demonstrate that language-enabled components pass domain-specific physics plausibility suites before deployment.
- Tools/Workflows: Adversarial scenario generation; parameter sweeps; pass/fail gates tied to requirements (e.g., braking distances, collision dynamics).
- Assumptions/Dependencies: Domain simulators (CARLA, AirSim) and validated entities; alignment with certification (e.g., ISO 26262).
- Consumer apps for interactive physics learning and AR/VR (Daily life, Education)
- What: Immersive, physics-sandbox experiences where users pose questions and receive validated, step-by-step explanations tied to simulated worlds.
- Tools/Workflows: AR/VR engines linked to the DSL; real-time QA and feedback; gamified progression.
- Assumptions/Dependencies: Real-time simulation performance on consumer devices; intuitive UX for scene creation.
- Global access and localization of STEM content (Policy, Social impact)
- What: Language-agnostic, simulator-backed item generation translated into low-resource languages to broaden access to high-quality STEM practice.
- Tools/Workflows: Template-based multilingual generation; local curriculum alignment; community review loops.
- Assumptions/Dependencies: Reliable translation of technical terms; cultural and curriculum fit; infrastructure for delivery.
Notes on feasibility across applications
- Core dependencies: simulator availability (MuJoCo is open-source), compute for RLVR, DSL coverage of phenomena, and robust data filtration to avoid shortcut learning.
- Transfer limits: current gains are strongest in classical mechanics; extending to other domains requires new entities, simulators, and verification.
- Risk controls: monitor for reward hacking, catastrophic forgetting (favor RLVR over large-SFT shifts), and ensure fairness/validity for educational or high-stakes uses.
Glossary
- Ablation: The deliberate removal or modification of components to assess their impact on outcomes in experiments or data generation. "we construct controlled ``ablations'' of each scene:"
- Catastrophic forgetting: The loss of previously learned capabilities when a model is fine-tuned on a narrow or shifted distribution. "can induce catastrophic forgetting during post-training."
- Coefficient of restitution: A parameter (0–1) describing how bouncy a collision is, defined as the ratio of relative speeds after and before impact. "collisions with a specified coefficient of restitution."
- Counterfactual reasoning: Reasoning about hypothetical alternatives to observed events or parameters (e.g., “what if” scenarios). "physics problem solving requires accurate, inverse, symbolic, and counterfactual reasoning."
- DAPO-17K: A curated dataset of 17,000 math problems designed for outcome-reward reinforcement learning. "DAPO-17K contains 17K curated mathematical problems designed for outcome-reward RL training at scale."
- DAPO-style dynamic sampling: An adaptive batch construction strategy that resamples prompts to avoid uninformative (near-zero variance) reward groups. "Finally, we incorporate DAPO-style dynamic sampling to improve training efficiency in sparse-reward settings."
- Domain-specific language (DSL): A specialized language tailored to a particular domain—in this case, to compose physics scenes with meaningful randomized parameters. "we design a domain-specific language (DSL)"
- Entity-removal ablations: A specific ablation technique where individual entities are removed from a scene to test whether questions depend on the full system. "Entity-removal ablations: We treat a scene as a graph of entities and connections, generate sub-scenes by removing one entity at a time while preserving the connectivity of the remaining graph, and re-simulate these sub-scenes."
- Group Sequence Policy Optimization (GSPO): A reinforcement learning algorithm that optimizes sequence-level policies using grouped samples and clipping for stability. "We optimize Group Sequence Policy Optimization (GSPO)"
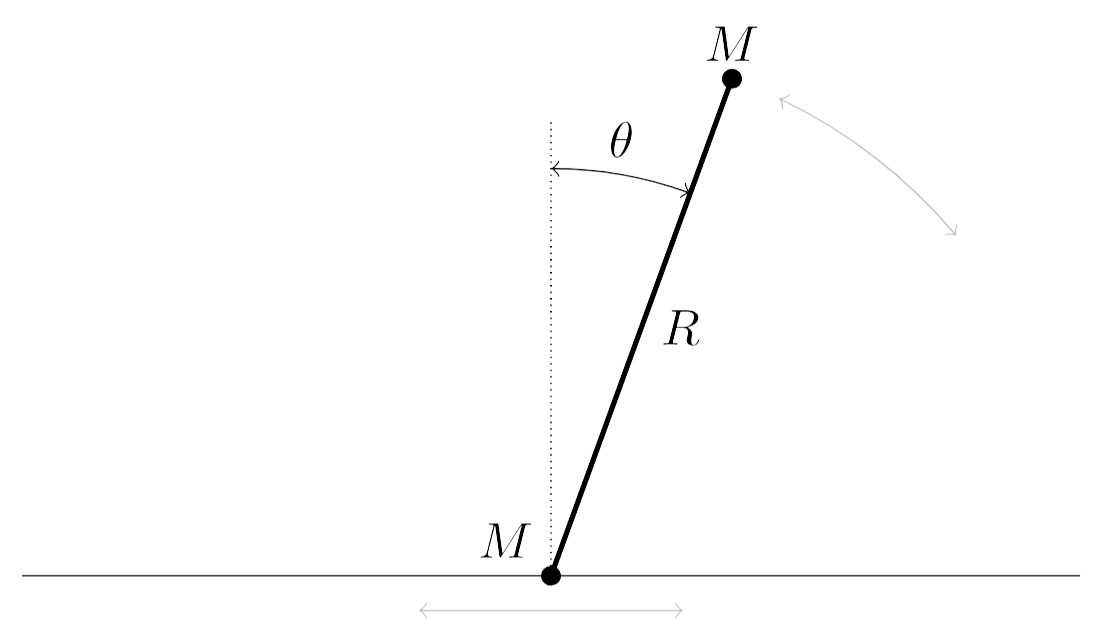
- Homogeneous gravitational field: A gravitational field with constant magnitude and direction across space. "A ball is thrown with a fixed initial speed in a homogeneous gravitational field."
- International Physics Olympiad (IPhO): A prestigious international competition in physics for pre-university students. "IPhO (International Physics Olympiad)"
- Joint-removal ablations: An ablation method that tests dependence on constraints by substituting or removing joints, often replacing them with rigid connections. "Joint-removal ablations: We generate variants in which individual joints/constraints are replaced by rigid ``glued'' components."
- KL shift (Kullback–Leibler shift): A large divergence from the base model’s behavior (distribution) during post-training, which can harm generalization. "a large KL shift from the base Instruct model"
- MuJoCo: A physics engine for model-based control and simulation, used here to generate and record physical interactions. "Using MuJoCo \cite{mujoco} as our simulator"
- Newtonian gravitation: The classical inverse-square law of gravitational attraction as formulated by Newton. "We also extend the simulator to support variable-mass systems, Newtonian gravitation, and collisions with a specified coefficient of restitution."
- Ordinary differential equations (ODEs): Equations involving functions and their derivatives with respect to a single variable; used to model time evolution in physics. "systems of ordinary differential equations"
- Proprioceptive quantities: Internal state variables of bodies (e.g., position, velocity, acceleration) measured from the system’s own perspective. "masses (proprioceptive quantities)"
- Reference policy: A fixed or slowly changing policy used to regularize learning and prevent large deviations during RL fine-tuning. "with a reference policy $\pi_{\mathrm{ref}$ (the base Instruct model)."
- Reinforcement learning with verifiable rewards (RLVR): An RL paradigm where rewards are computed from objectively checkable outcomes (e.g., final-answer correctness). "Reinforcement learning with verifiable rewards (RLVR) has enabled LLMs to cross the threshold from pattern matching to multi-step reasoning."
- Sequence-level policy-gradient objective: An RL objective that assigns credit based on entire generated sequences rather than token-level signals. "The GSPO loss is a clipped, sequence-level policy-gradient objective:"
- Sim-to-real transfer: The transfer of skills learned in simulation to performance on real-world or real-benchmark tasks. "zero-shot sim-to-real transfer"
- Sparse-reward settings: RL scenarios where successful outcomes (non-zero rewards) are rare, making learning more difficult. "improve training efficiency in sparse-reward settings."
- Spearman ρ: A rank correlation coefficient measuring the monotonic relationship between two variables. "Spearman "
- Supervised fine-tuning (SFT): Training a model on labeled examples (e.g., teacher solutions) to improve performance in a supervised manner. "supervised fine-tuning (SFT)"
- Variable-mass systems: Physical systems where mass changes over time (e.g., rockets shedding fuel), affecting dynamics. "support variable-mass systems"
- Verifier: An external tool or model used to check the correctness of a model’s answers. "We use Gemini 2.5 Flash as a verifier."
- Zero-shot transfer: Evaluating or applying a model to new tasks or datasets without additional fine-tuning on those tasks. "We evaluate zero-shot transfer on a curated set of mechanics problems from the International Physics Olympiad."
Collections
Sign up for free to add this paper to one or more collections.

