- The paper introduces PhysCodeBench, a comprehensive benchmark that evaluates physics-aware symbolic simulation in 3D scenes.
- It proposes the SMRF framework, a self-corrective multi-agent system that iteratively refines simulation code for enhanced physical accuracy.
- Experimental results show SMRF achieves a 31-point improvement over state-of-the-art models, ensuring robust simulation fidelity.
PhysCodeBench: Benchmarking Physics-Aware Symbolic Simulation of 3D Scenes via Self-Corrective Multi-Agent Refinement
Motivation and Problem Definition
The design and accurate implementation of physics-aware symbolic simulation for 3D scenes are essential to downstream domains such as robotics, embodied AI, and scientific computing, where the correct modeling of physical phenomena is a necessity for both experimentation and real-world deployment. Traditional LLMs, while competent at code synthesis, lack the ability to robustly operationalize natural language descriptions of physical phenomena into reliable, executable simulation code that captures semantic and numerical correctness. The domain-specific failure modes include incorrect representation of physical laws, miscalibrated parameters, and violations of numerical stability or conservation principles, which are not systematically addressed by existing code generation benchmarks or LLM approaches.
PhysCodeBench Benchmark
The authors introduce PhysCodeBench, the first comprehensive benchmark dedicated to physics-aware symbolic simulation in 3D environments. The dataset consists of 700 high-quality examples curated across rigid-body physics, soft-body physics, fluid dynamics, and mechanics, each annotated by human experts with metadata (difficulty, physical laws, human preference ratings).

Figure 1: Examples from PhysCodeBench revealing diverse physical domains and multimodal annotation encompassing prompts, code snippets, and simulated frames.
Dataset curation employs a four-stage pipeline: expert-based prompt construction, diversified code generation via multiple LLMs (with the Genesis physics engine as runtime), human-in-the-loop validation (covering both execution and physical simulation correctness), and comprehensive metadata annotation.
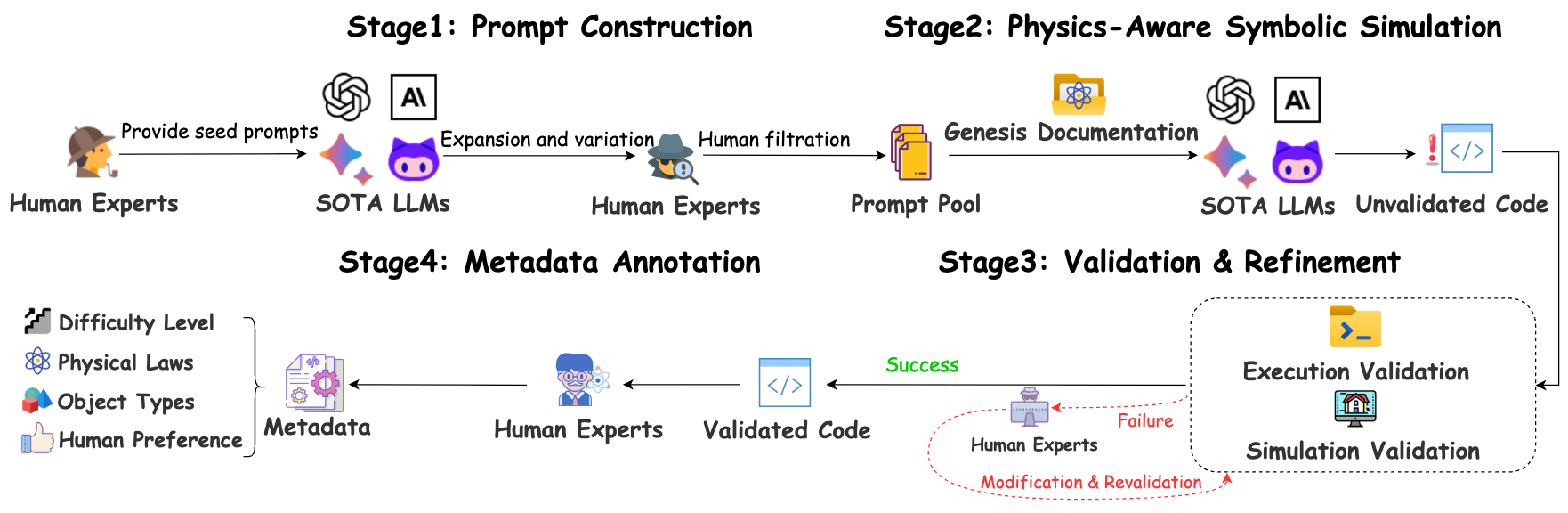
Figure 2: The PhysCodeBench curation pipeline, detailing prompt generation, simulation synthesis, expert validation, and annotation.
This benchmark is characterized by its coverage of physical phenomena requiring fine-grained reasoning about laws (e.g., elasticity, surface tension, collision dynamics) and realistic boundary conditions, going beyond what can be validated by mere code execution. The dataset ensures significant coverage for fundamental and composite physical domains, with pairwise preference labels enabling robust training for models designed for preference alignment.
Self-Corrective Multi-Agent Refinement Framework (SMRF)
To overcome limitations of monolithic LLM-based code generation, the authors propose the Self-Corrective Multi-Agent Refinement Framework (SMRF). This approach instantiates three specialized agents: a Simulation Generator (SG), an Error Corrector (EC), and a Simulation Refiner (SR), each trained via supervised fine-tuning (SFT) and preference alignment (DPO) with dedicated data from PhysCodeBench. The agents communicate through an iterative feedback mechanism, systematically decomposing the task into initial code generation, autonomous error diagnosis and correction, and preference-driven refinement.
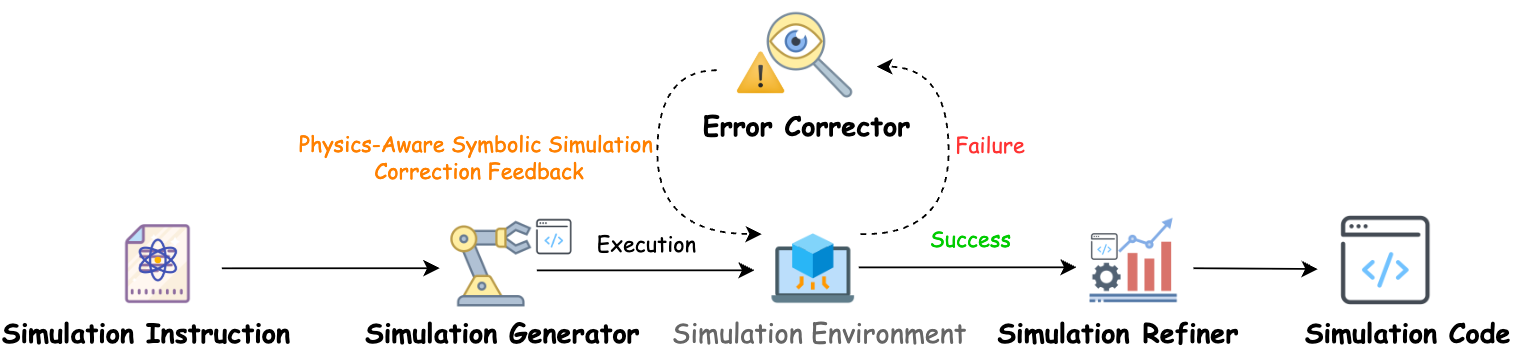
Figure 3: SMRF architecture, elucidating the interactions between specialized agents (SG, EC, SR) in an iterative, role-specific pipeline.
The theoretical grounding is modular cognitive science and multi-agent system protocols. The framework explicitly separates concerns: SG encodes scenario synthesis, EC mitigates both syntax and semantic physical errors, while SR uses expert-labelled preferences for code optimization and alignment.
Evaluation Protocol
The PhysCodeEval protocol assesses both code and physical simulation fidelity, each contributing 50 points to a 100-point scale. Code-based metrics mandate successful execution within Genesis (including file validity), whereas vision-based metrics employ CLIP-based semantic alignment and motion smoothness scoring (a variant from VBench) for fidelity assessment.
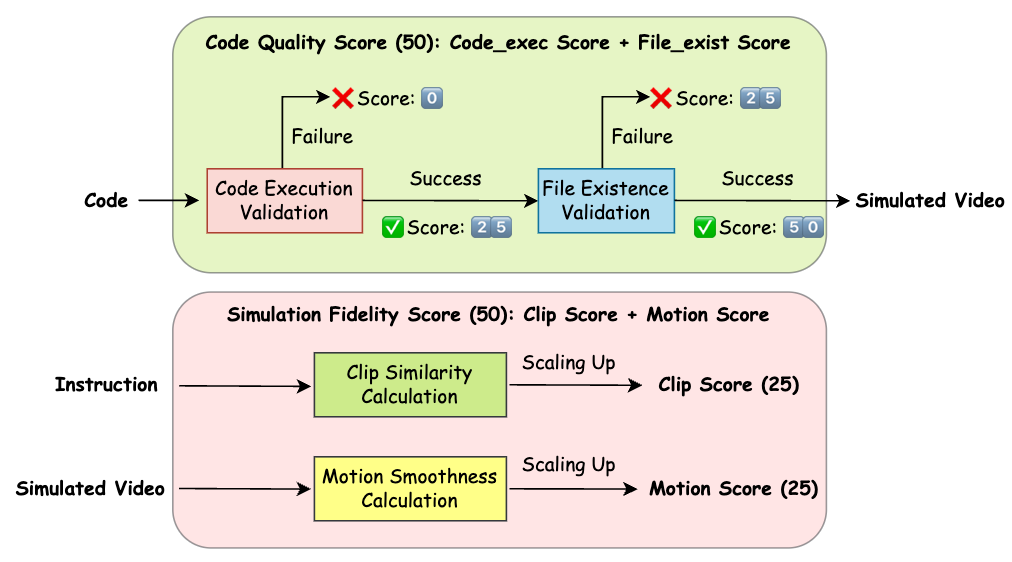
Figure 4: Dual-path evaluation protocol: code execution/file generation and vision-based fidelity via ClipScore and motion smoothness.
This composite metric rigorously penalizes syntactic errors, file misproductions, and physically implausible simulation artifacts—for example, energy non-conservation or instability in object interactions.
Experimental Results
Quantitative analysis demonstrates that SMRF + SFT + DPO achieves an overall PhysCodeBench score of 67.7, outperforming top proprietary (Claude-3.5-Sonnet, 36.3) and fine-tuned open-source baselines by over 31 points—a substantial margin.

Figure 5: SMRF attains 67.7, a 31.4-point increase over SOTA, with substantial improvements in physical accuracy, including conservation laws, surface tension, and collision modeling.
SMRF’s advantage holds across difficulty stratification and persists in fluid, soft-body, and rigid-body subdomains. Ablation studies confirm that both the EC and SR agents are essential; removing either causes significant performance degradation—demonstrating that error correction and preference-aligned refinement are critical for closing the gap between syntactic and physical/semantic correctness.
Qualitative comparisons show that baseline models frequently generate simulations that visually deviate from described phenomena (e.g., poor boundary adherence for raindrop and LEGO collapse scenarios). By contrast, SMRF consistently produces realistic surface tension, energy-conserving rebound, and plausible multi-body collapse.

Figure 6: Qualitative comparison of simulations for fluid and rigid-body tasks; SMRF yields physically consistent ripple and collapse effects, outperforming GPT-4o, Claude-3.5, and DRDQ.
User studies (with physics-expert raters) confirm metric validity: SMRF solutions are rated 4.5/5 for physical accuracy, with strong code readability and overall utility, significantly above all other evaluated systems.
Theoretical and Practical Implications
The empirical superiority of the SMRF multi-agent approach validates the hypothesis that specialized decomposition and iterative self-correction substantially mitigates both execution and physical reasoning errors endemic to single-agent LLMs. Preference alignment via DPO on pairwise expert annotations serves as a robust regularizer for code quality and physical realism.
This work has substantial implications for future AI development in both simulation synthesis and broader scientific programming:
- Domain-specialized multi-agent LLMs: Physics-centric decomposition unlocks new regimes of code+physical fidelity unattainable by monolithic transformers.
- Evaluation in scientific domains: PhysCodeBench establishes a new standard for systematic assessment, incentivizing research on domain fidelity, not just executability.
- Generalization and Adaptability: Preliminary cross-engine experiments demonstrate that SMRF’s physical reasoning generalizes to novel physics engines (e.g., MuJoCo), showing model robustness beyond Genesis-specific APIs.
Limitations and Future Directions
While PhysCodeBench and SMRF focus on symbolic simulation via high-level APIs, algorithmic generation of low-level solvers remains unsolved. The dataset is currently limited to Genesis; inclusion of additional engines and more exotic physical phenomena (e.g., electromagnetism, quantum effects) is left for future iterations. The multi-agent inference pipeline incurs computational overhead, which must be balanced against deployment constraints in real-time or embedded applications.
A natural progression involves expanding the dataset, automating more aspects of physical law measurement (e.g., direct conservation checks), and integrating advanced fine-tuning for low-level algorithmic synthesis.
Conclusion
PhysCodeBench introduces a rigorous, expert-annotated platform for assessment of physics-aware 3D simulation synthesis, and the SMRF self-corrective multi-agent framework defines a new SOTA paradigm in aligning executable code generation with physical correctness. The results decisively show that single-agent LLMs do not suffice for in-domain fidelity, and that agent specialization coupled with expert-informed preference alignment substantially closes the gap between language, code, and physics. This work will serve as a foundation for future development of AI systems in science, engineering, and digital fabrication requiring reliable, physically-accurate simulation synthesis.

