- The paper reveals that supervised fine-tuning in LLMs causes non-uniform, depth-dependent adaptation, with shallow layers remaining stable, mid-blocks restructuring semantics, and top layers undergoing drastic changes.
- It utilizes quantitative metrics such as CKA, cosine similarity, and L2 norm of weight updates to demonstrate localized representational shifts and validate the architectural locality hypothesis.
- The proposed mid-block efficient tuning (MBET) method selectively updates parameters in intermediate layers to enhance task performance while mitigating catastrophic forgetting.
Layer-wise Mechanisms and Architectural Locality in Supervised Fine-Tuning
Introduction
Supervised Fine-Tuning (SFT) constitutes the primary methodology for aligning pretrained LLMs with human instructions. Despite its widespread adoption, the underpinnings of how SFT structurally modifies model representations across depth remain ambiguous. "A Layer-wise Analysis of Supervised Fine-Tuning" (2604.11838) presents an information-theoretic, geometric, and optimization-based analysis to localize and characterize SFT-induced changes in transformer encoder layers across scales (1B–32B parameters). The study provides mechanistic insight into the architectural locality of SFT, refuting the assumption that all layers are equally involved in alignment, and introduces an efficiency-improving layer selection method for parameter-efficient alignment.
Depth-dependent Dynamics of SFT
The core finding is that SFT drives non-uniform, depth-dependent adaptation. Layers are partitioned into three functional regimes. First, the shallow (early) layers act as frozen feature extractors largely unaffected by alignment; second, the intermediate “mid-block” layers accommodate most of the alignment-induced semantic restructuring; third, the top layers (final 20%) exhibit maximal sensitivity, aggressive parameter rewrites, and serve as the locus of catastrophic forgetting.
These claims are substantiated by a comprehensive suite of quantitative representational divergence metrics, including Centered Kernel Alignment (CKA), cosine similarity, and mean shift, computed on model representations before and after SFT. The shallow layers exhibit near-perfect geometric alignment post-SFT, whereas the deepest layers show an abrupt decline in representational similarity and sharp displacement in the feature space.
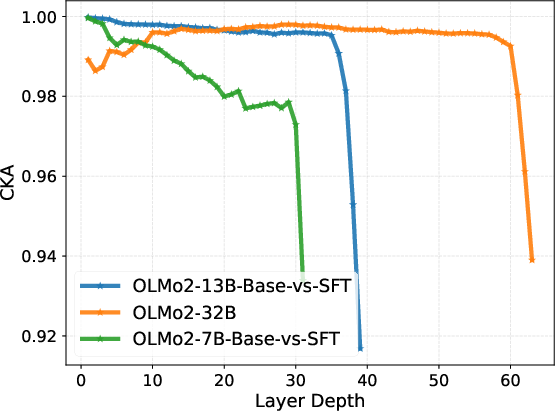
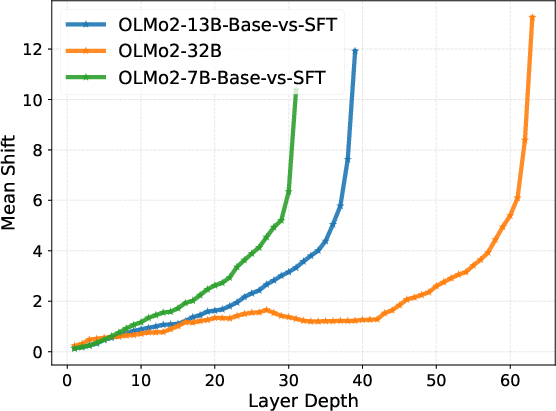
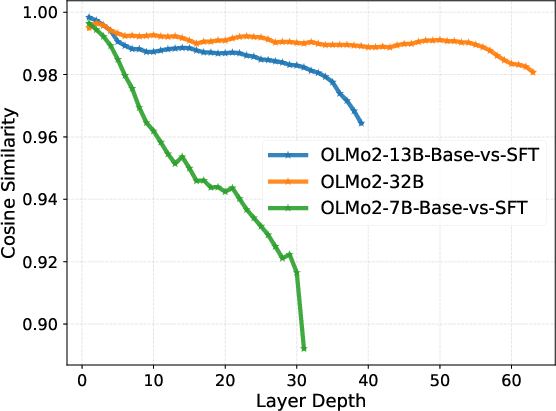
Figure 1: Layer-wise representational divergence (CKA, Cosine Similarity, Mean Shift) demonstrates stability in early layers and sharp transition in late layers.
Intrinsic representation metrics (entropy, effective rank, condition number, rank deficiency) calculated for both Base and SFT models further reveal a three-phase pattern. After an initial expansion to high effective rank and low condition number in the middle layers—indicative of robust, high-dimensional reasoning—the last layers execute strong compression into a low-rank, high-magnitude output manifold.
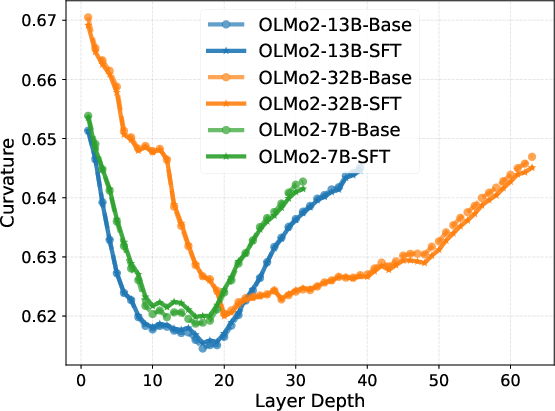
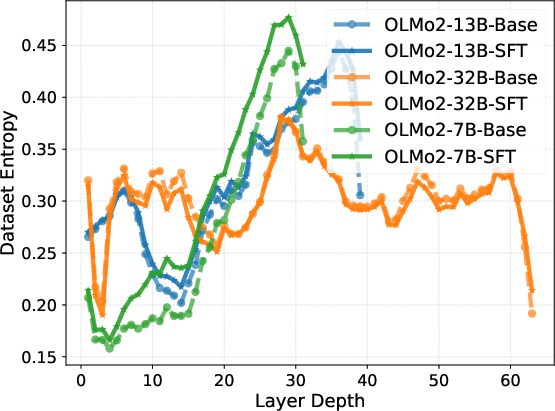
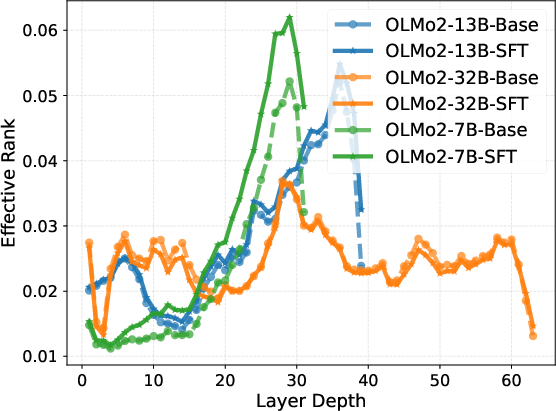
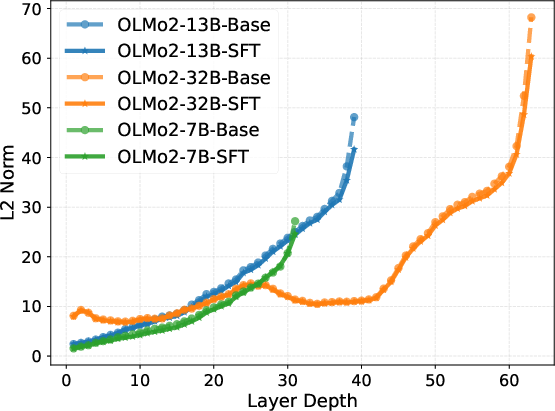
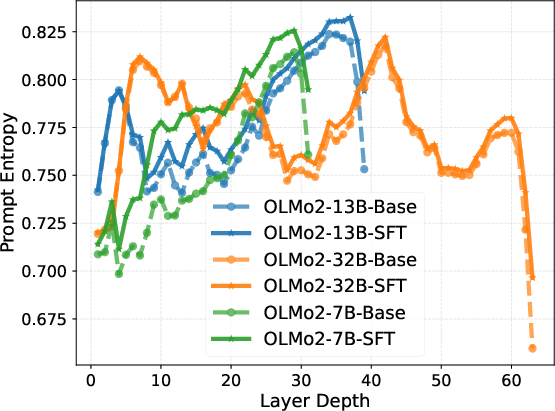
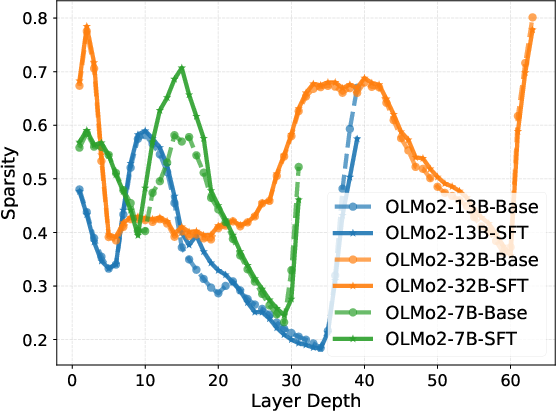
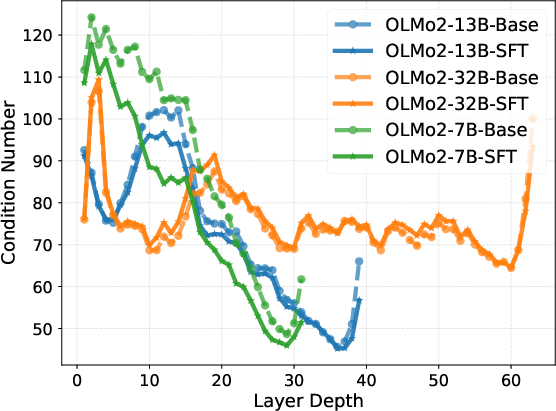
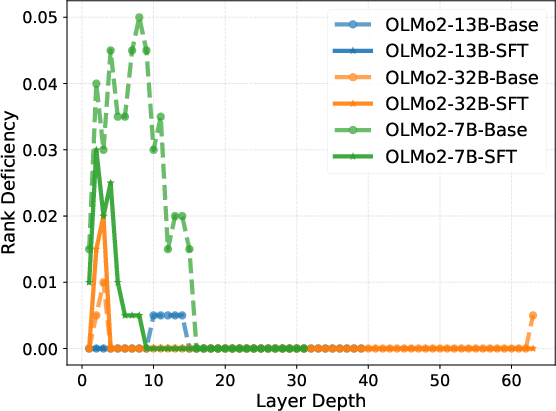
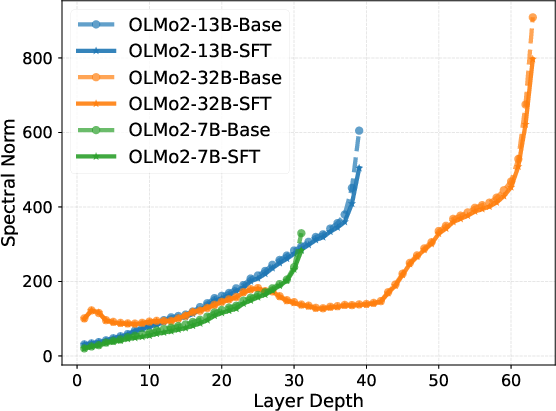
Figure 2: Layer-wise trends in intrinsic information metrics, highlighting mid-block stability and late-layer compression.
Probing, Weight Dynamics, and Alignment Localization
Layer-wise probing, in which the output of each layer is directly tasked with next-token prediction, demonstrates that instruction-following capabilities only emerge sharply in the final block. For models like OLMo2-32B, probe accuracy remains negligible in the first 50 layers, then rapidly ascends in the final 14, evidencing a delayed phase transition in task adaptation.
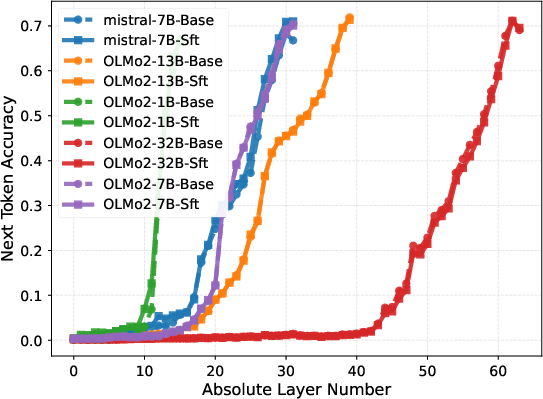
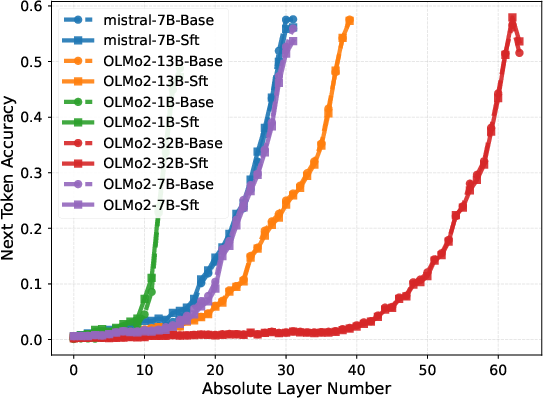
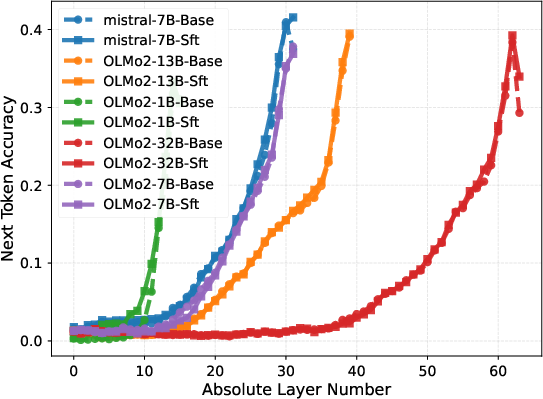
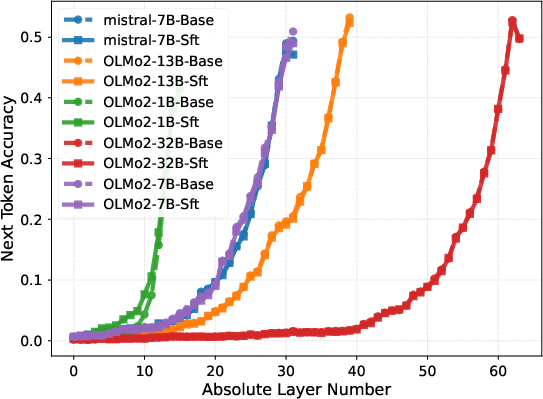
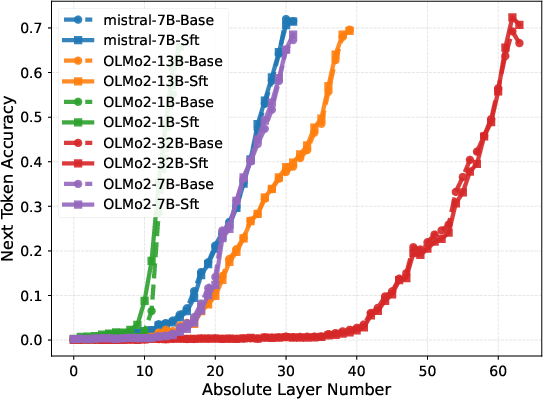
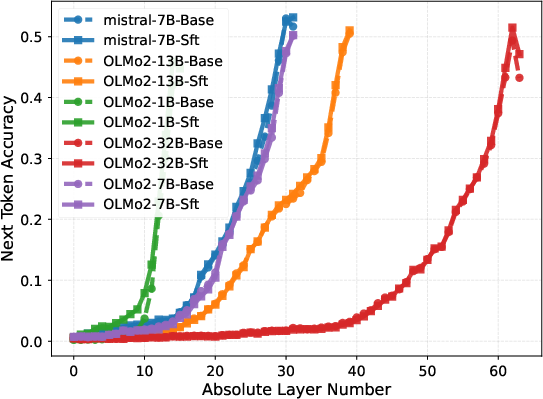
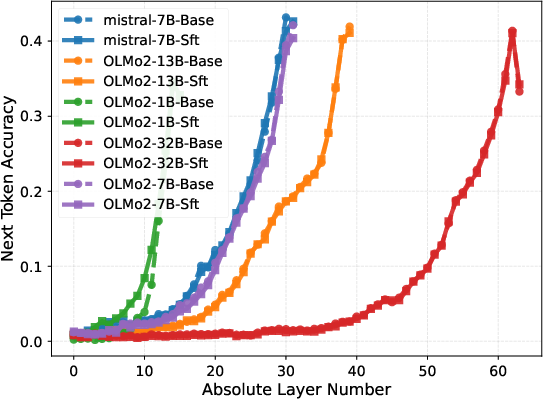
Figure 3: Layer-wise next-token prediction accuracy for various benchmarks shows performance surge only in upper layers.
Optimization analysis quantifies the magnitude of weight change (L2 norm) at each layer during SFT. Results show that the latter 20% of layers undergo an order of magnitude higher update intensity, unequivocally linking representational shifts to increased trainable parameter plasticity in these layers.
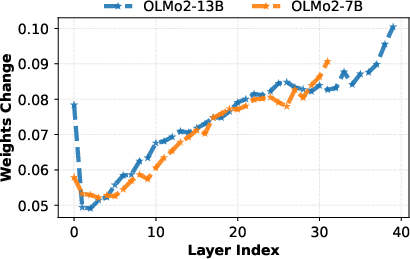
Figure 4: Magnitudes of weight updates are minimal in early/mid layers and peak in the top layers during SFT.
Correlation analysis confirms that layers with the greatest representational divergence (low cosine similarity, high spectral norm) are precisely those with the largest parameter rewrites.
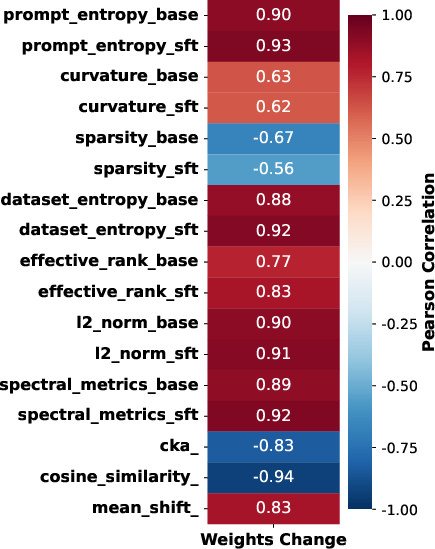
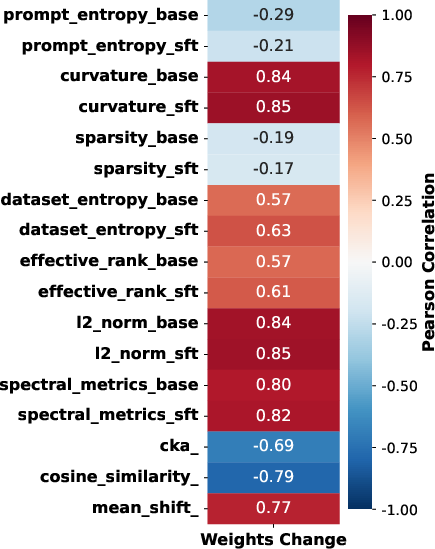
Figure 5: Strong statistical correlation between weight updates and representational change metrics across layers.
Layer block swapping between Base and SFT checkpoints causally validates the locality of task adaptation. Swapping only the top or bottom 20% of layers reduces downstream performance, while swapping the mid-block recovers or slightly improves it, ruling out the hypothesis of uniformly distributed adaptation.
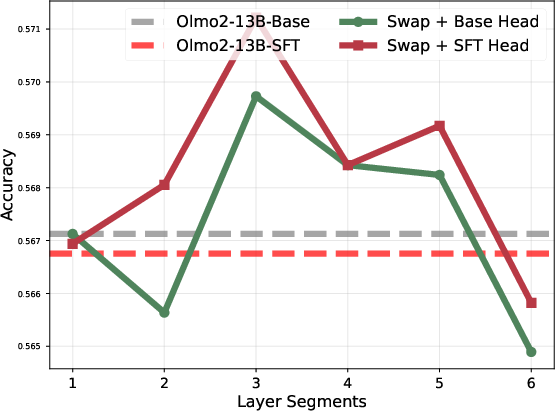
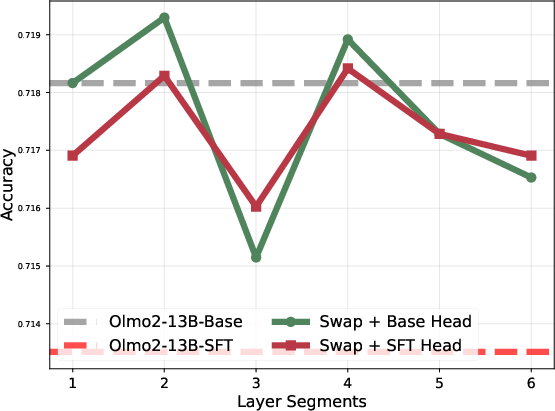
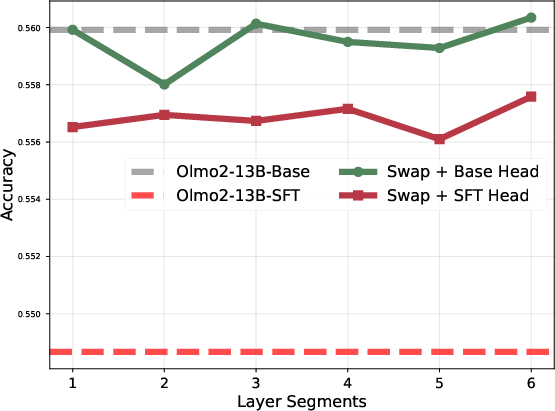
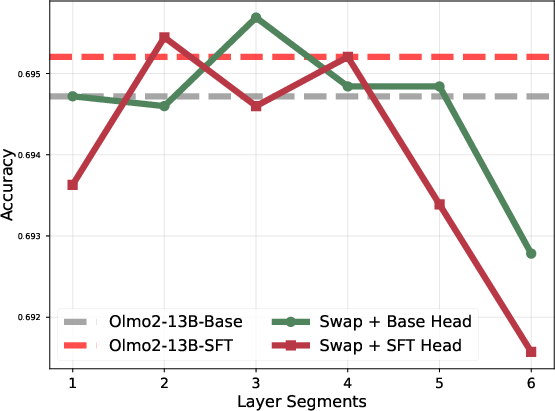
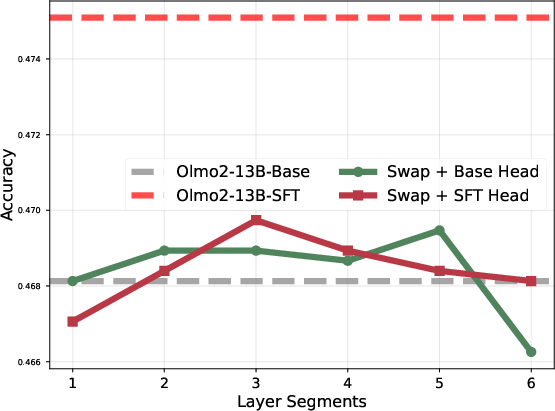
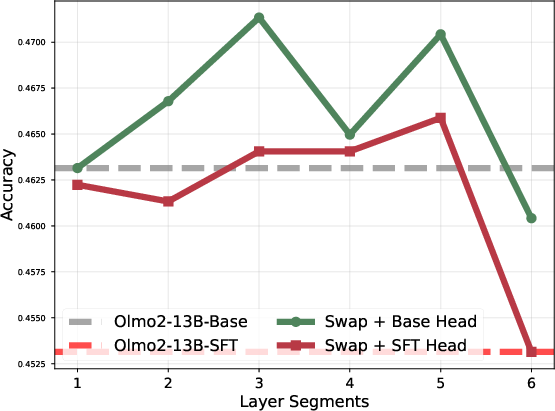
Figure 6: Model accuracy when selectively swapping parameter blocks between Base and SFT; only mid-block swaps avoid degradation.
Mid-Block Efficient Tuning
Motivated by the identified mid-block alignment plateau, the study proposes "Mid-Block Efficient Tuning (MBET)", an SFT technique that restricts LoRA-style parameter updates exclusively to the middle 20–80% of layers. Benchmarking on GSM8K, OLMo2-7B achieves 37.5% accuracy with MBET, a robust improvement of 10.2% over conventional all-layer LoRA, despite utilizing a smaller parameter subset. Notably, performance sharply degrades when LoRA is limited to the bottom or top layer segments, achieving less than 22–25% accuracy. This performance consistently generalizes across OLMo2-1B, 13B, 32B, and Mistral-7B.
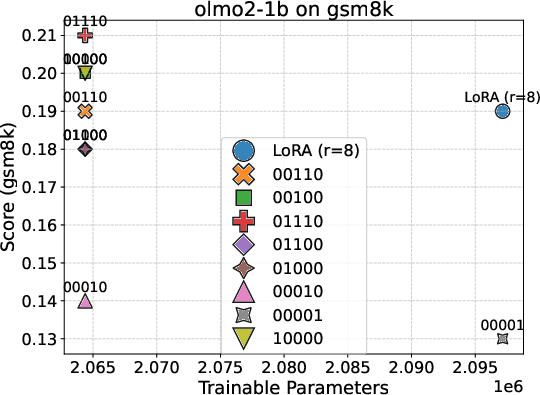
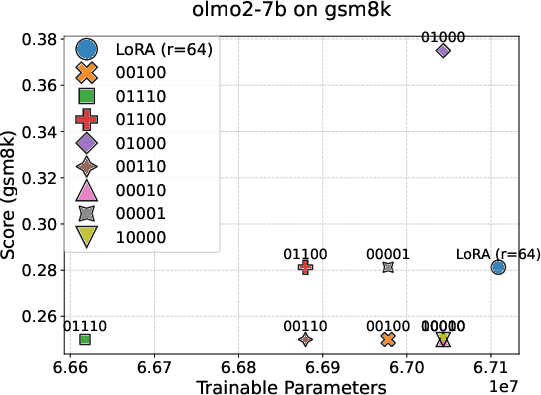
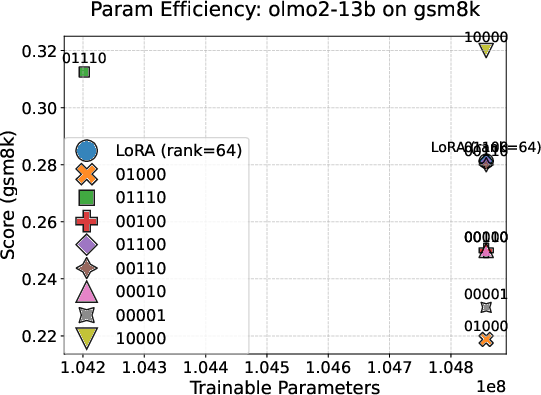
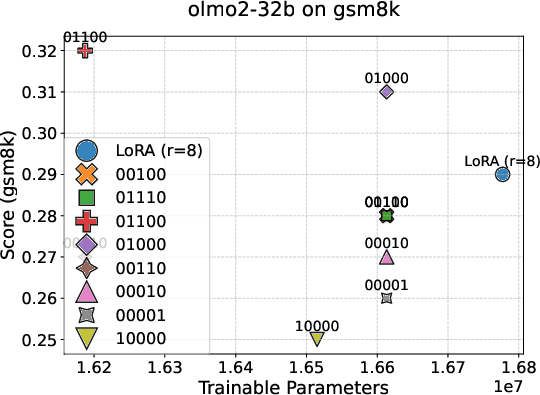
Figure 7: Comparison of LoRA-based efficient tuning strategies across OLMo2 model scales; only mid-block tuning yields substantial gains.
These findings constitute definitive empirical evidence that alignment is not uniformly distributed across depth, and that mid-block layers provide a robust and broad representational plateau optimal for instruction-tuning.
Implications
This work has significant theoretical and practical implications for SFT and parameter-efficient fine-tuning (PEFT):
- Architectural Locality: SFT-induced adaptation is highly localized, invalidating the uniform-update assumption of canonical PEFT methods.
- Mitigating Catastrophic Forgetting: By avoiding aggressive updates to high-plasticity top layers, MBET preserves base model knowledge, maintaining low perplexity on held-out tasks and reducing alignment-preference tradeoff.
- Efficient Computation: MBET leverages the mid-block's functional role, enabling parameter and memory savings while improving or preserving downstream task performance.
- Toward Adaptive Layer Selection: The robustness of the mid-block plateau invites future research into adaptive, model-agnostic methods for selecting the optimal layer set for SFT.
Further work is required to generalize these conclusions to other architectures (e.g., Mixture-of-Experts, encoder-decoder models) and to SFT variants incorporating preference optimization (e.g., RLHF, DPO).
Conclusion
This study demonstrates, through rigorous multi-metric analysis, that supervised fine-tuning in transformer LLMs is characterized by architectural locality. Task alignment is maximally effective when targeted to the mid-section of model depth, as confirmed by representational, optimization, and behavioral metrics. The proposed Mid-Block Efficient Tuning method is an analysis-driven refinement of PEFT, delivering large performance gains with reduced parameter footprint. These insights provide a concrete mechanistic rationale for the design of future SFT, PEFT, and alignment strategies and establish a foundation for subsequent work in scalable, robust model instruction alignment.