- The paper introduces a novel framework that retrieves query-conditioned, validated cognitive abstractions to improve memory in agentic systems.
- It employs a multi-stage pipeline combining retrieval, synthesis, and redundancy filtering, achieving notable improvements in F1 scores and recall.
- The framework scales effectively by self-evolving through recursive abstraction, enabling robust long-term reasoning beyond fixed context limits.
Thought-Retriever: A Model-Agnostic Framework for Memory-Augmented Agentic Systems
Motivation and Context
The proliferation of LLMs has generated transformative advances in NLP and agentic systems, yet their ability to integrate arbitrarily vast external knowledge remains fundamentally bounded by context length and retrieval granularity. Prevailing paradigms—long-context LLMs and retrieval-augmented LLMs (RALMs)—are hindered by quadratic complexity and top-K chunk limitations, respectively. Hierarchical RALMs and agent frameworks (e.g., MemGPT, Generative Agents) store raw observations or rigid summaries, introducing noise and inefficiency in information retrieval. The Thought-Retriever framework (2604.12231) addresses these inefficiencies by organizing intermediate LLM responses (“thoughts”) as query-conditioned, validated cognitive abstractions, thereby enabling dynamic, reasoning-aware long-term memory for agentic architectures.
Framework Architecture
Thought-Retriever formulates a memory module agnostic to LLM backbone and retrieval model. The process pipeline consists of the following steps:
- Thought Retrieval: Top-K retrieval from the union of external knowledge and thought memory using embedding similarity (Contriever by default), ensuring context relevance across both low- and high-abstraction content.
- Answer Generation: The LLM synthesizes an answer based on retrieved content.
- Thought and Confidence Generation: A custom prompt (Figure 1) guides the model to generate thought candidates and confidence scores. Meaningless or hallucinated thoughts are filtered via this confidence mechanism.
- Thought Merge (Redundancy Filtering): Embedding similarity checks prune redundant inferred thoughts, maintaining a diverse, information-dense memory bank.
- Memory Update: Only high-confidence, non-redundant thoughts update the memory store, resulting in a self-evolving, scalable knowledge structure.
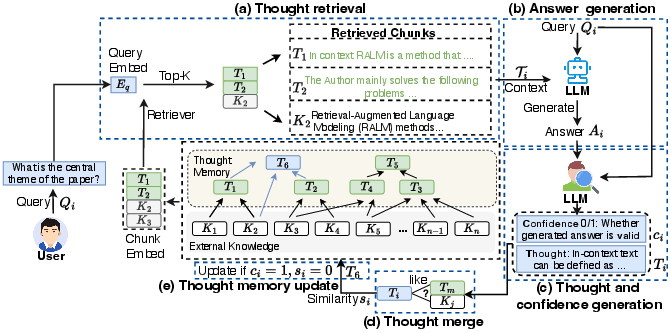
Figure 2: Thought-Retriever framework architecture, showing query-driven retrieval, answer generation, thought synthesis, redundancy filtering, and memory update.
Each thought Ti is query-conditioned, abstractive, and validated. Root source mapping O^(Ti) recursively traces all information provenance from base raw chunks through layers of thought synthesis, establishing strict grounding for factual recall and precision analysis.
Benchmark and Datasets
To rigorously evaluate long-context comprehension and memory utilization, “AcademicEval” is introduced. This benchmark features:
- Abstract-single: Summarization of a single paper (abstract/conclusion omitted).
- Abstract-multi: Synthesis of multiple papers’ abstracts (expert-generated ground truth).
- Related-multi: Generation of related work using abstracts from both cited and random papers.
Real-world complexity is ensured via multi-modal information (e.g., tables, sectioned content) and stratification by abstraction level.
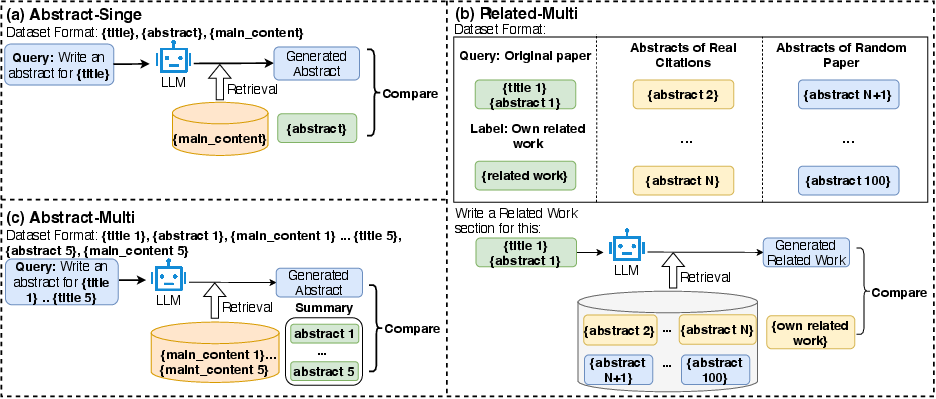
Figure 3: AcademicEval usage instructions for abstract and related work tasks with data flow and prompt structure.
Experimental Results
Quantitative Evaluation
Thought-Retriever achieves at least a 7.6% absolute improvement in F1 score and 16% win rate increase across AcademicEval and public datasets (GovReport, WCEP), consistently outperforming BM25, TF-IDF, DPR, DRAGON, IRCoT, RECOMP, full context window truncation, and long-context LLMs (OpenOrca-8k, Nous Hermes-32k). Its performance is robust even when compared against Oracle retrieval (ground-truth chunk upper bound), indicating superior information density due to compressive thought abstraction.

Figure 4: Qualitative example showing original abstract and Thought-Retriever’s synthesized abstract, evaluated for alignment and content density by expert LLM.
Ablation Study
Replacing Contriever with alternative retrievers and removing thought filtering drops performance, validating both the retrieval and validation modules as critical for efficient memory abstraction and recall.
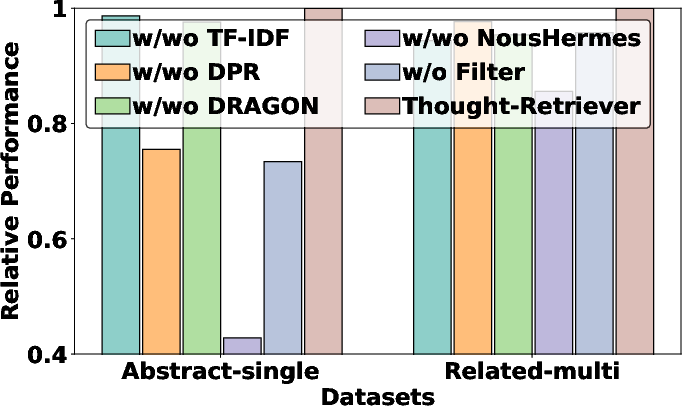
Figure 5: Comparative ablation study showing retrieval and filtering effectiveness across methods and datasets.
Recall/Precision Trade-off
Thought-Retriever attains high recall by synthesizing multi-paper thoughts, surpassing traditional retrieval limits. Its precision remains competitive due to confidence and redundancy filtering.
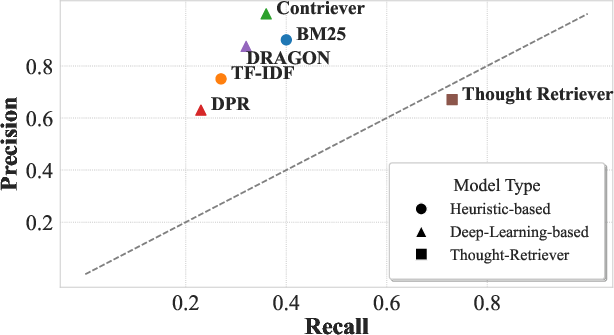
Figure 6: Thought-Retriever’s recall–precision balance compared to baselines, demonstrating superior chunk coverage.
Self-Evolution and Scaling Laws
Performance scales positively with memory size: as user queries accumulate, the system self-evolves, generating deeper abstraction levels (quantified recursively) and improving reasoning breadth.

Figure 7: Empirical correlation between query abstraction level and retrieved thought abstraction, confirming hierarchical cognitive scaling.
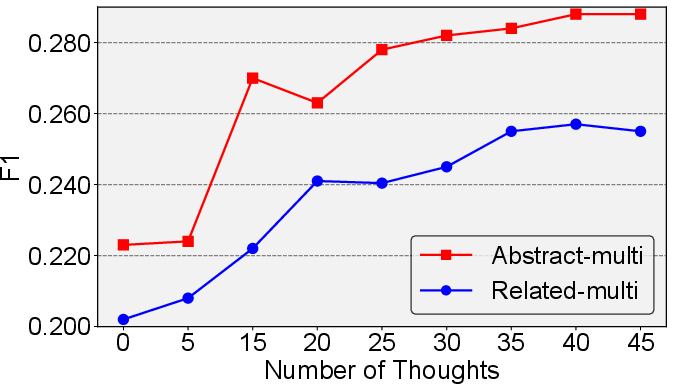
Figure 8: F1 score scaling with thought count, visualizing self-evolution as the thought memory expands through interaction.
Integration and Efficiency
Thought-Retriever operates as a lightweight, training-free module adaptable to both open-source and closed-source LLMs. Memory stores and retrieval indexes require minimal compute/storage, enabling prompt real-world deployment, exemplified by the Arxiv Copilot demo on Hugging Face.
Figure 9: Arxiv Copilot demo interface, built upon Thought-Retriever for personalized academic service and dynamic memory testing.
Theoretical and Practical Implications
Thought-Retriever introduces a paradigm wherein agentic systems can distill and retrieve reasoning-aware cognitive units instead of static raw data or rigid summary hierarchies. The framework is inherently suited for settings demanding persistent, information-dense intelligence—spanning LLM-powered experts, multi-agent collaboration, continual learning, and high-abstraction reasoning tasks. Its recursive abstraction and provenance tracking enable robust causal inference and transferable memory across unseen queries. The approach further aligns with human memory models, offering future directions for scaling, multilingual extension, and human-comparable reasoning fidelity.
Conclusion
The Thought-Retriever framework advances the state of retrieval-augmented LLMs by introducing dynamic, validated, query-driven cognitive abstractions as persistent memory. This enables scalable, self-evolving agentic reasoning well beyond existing context window constraints. Extensive validation on AcademicEval and public benchmarks confirms its efficacy, stability, and adaptability. The architecture is poised for integration in advanced agentic systems, continual learning, and interactive, real-world AI services.

