- The paper introduces a novel four-stage data synthesis pipeline that integrates knowledge graph seeds, online QA, entity obfuscation, and multi-model verification for complex multi-hop medical search tasks.
- It employs a two-phase supervised fine-tuning combined with GRPO-based reinforcement learning with verifiable rewards to enhance reasoning accuracy and mitigate reward hacking.
- Empirical results demonstrate that QuarkMedSearch outperforms baseline models on diverse benchmarks, validating its practical application in clinical report generation and deep medical research.
QuarkMedSearch: A Long-Horizon Deep Search Agent for Medical Intelligence
Motivation and Problem Definition
QuarkMedSearch addresses the critical challenge of transferring agentic foundation model capabilities to the Chinese medical domain, where the complexity of multi-hop reasoning, evidence integration, and high-stakes decision-making imposes stringent demands on data, training, and evaluation. Existing systems, primarily pretrained on general-domain corpora or English-centric medical literature, suffer from limited multi-step interaction, weak retrieval depth, and insufficient coverage of rare medical entities. The scarcity of high-quality, long-horizon medical deep-search data further restricts supervised training and reinforcement learning protocols. Traditional RAG frameworks fail to meet the iterative, reasoning-intensive requirements of real-world medical information-seeking, especially given the prevalence of parametric memory shortcuts in frontier LLMs.
Four-Stage Data Synthesis Pipeline
A major contribution is the construction of a rigorous pipeline for synthesizing long-horizon medical deep search tasks, detailed as follows:
- Knowledge Graph-Based Seed Construction: Leveraging a large-scale, professionally curated medical knowledge graph, QuarkMedSearch samples long-tail entities (rare diseases, niche drugs, non-standard protocols) and constructs subgraphs with extended semantic relations. QA pairs are generated by transforming these structures into natural language, ensuring multi-hop reasoning and factual coherence via cross-model answer alignment.
- Online Environment-Based QA Expansion: A WebExplorer-style multi-tool agentic framework introduces online evidence at each reasoning hop, enforcing retrieval necessity through dynamic tool invocation (including specialized medical search engines) and LLM-based parametric memory checks. The pipeline iteratively deepens task complexity until retrieval-based solution exceeds 10 hops.
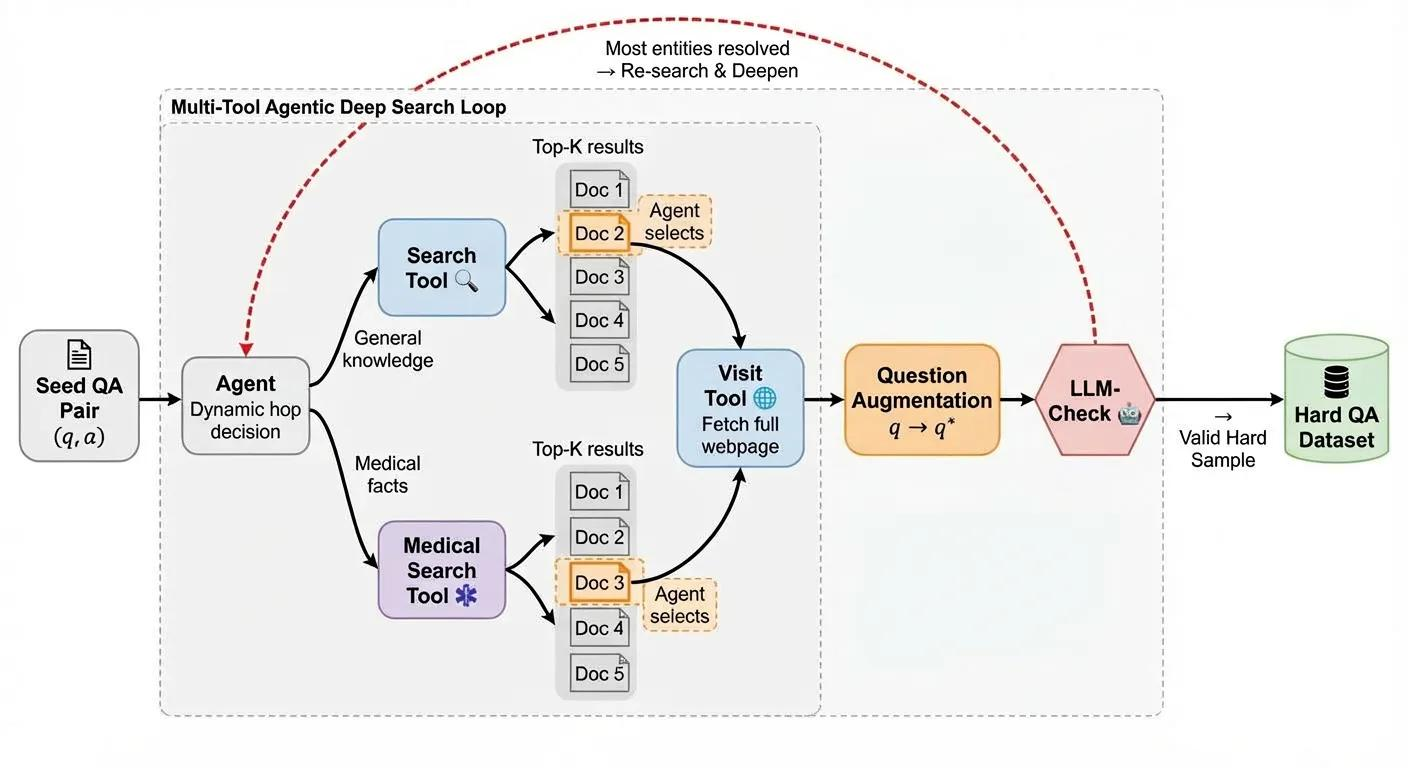
Figure 1: Long-horizon QA augmentation via progressive online evidence integration at each reasoning step.
- Entity Obfuscation: Critical entities are systematically rewritten using differentiated strategies (temporal, locational, occupational, pathological, numerical), combined with iterative checklist optimization to conceal direct cues and ensure naturalness, coverage, difficulty, and answer uniqueness.
- Multi-Model Verification: To guarantee answer correctness and uniqueness after semantic paraphrasing and online augmentation, the pipeline employs single-model multi-rollout, cross-model validation, and recovery checks, filtering ambiguous or inconsistent samples.
Difficulty analysis using tool-call distributions shows the synthesized dataset matches the complexity of BrowseComp, with an average tool-call count (27.2 vs. 32.3), confirming its suitability for SFT and RL-style training.
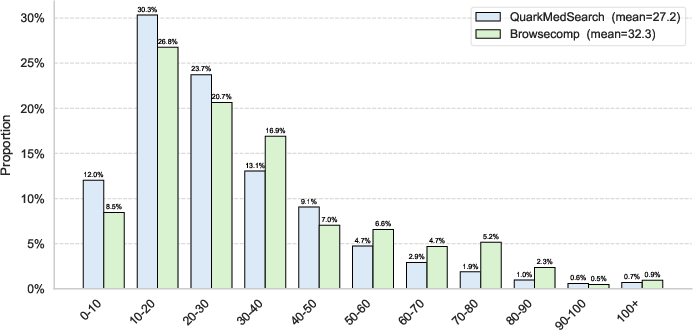
Figure 2: Comparative tool-call count distributions for QuarkMedSearch vs. BrowseComp benchmarking task difficulty.
Training Protocol: Progressive SFT and RLVR
QuarkMedSearch is instantiated atop the 30B-A3B Tongyi DeepResearch backbone. The training pipeline combines:
- Two-Phase SFT: Initial SFT covers short trajectories (≤32K tokens) to instill basic search-reasoning conventions. Subsequent SFT on filtered long trajectories (32–128K tokens) enables complex multi-step planning, evidence synthesis, and format fidelity. Both phases mix general and medical-domain tasks, with rubrics and rule-based filters enforcing intent planning, tool invocation quality, information integration, and factual rigor.
- GRPO-Based RL with Verifiable Rewards (RLVR): RL is performed on boundary samples using a strict reward function: format rewards are gated by correctness, eliminating reward hacking (models forcing answers without proper retrieval). RL uses group-based advantage normalization, truncated importance sampling, and route replay for policy stability.
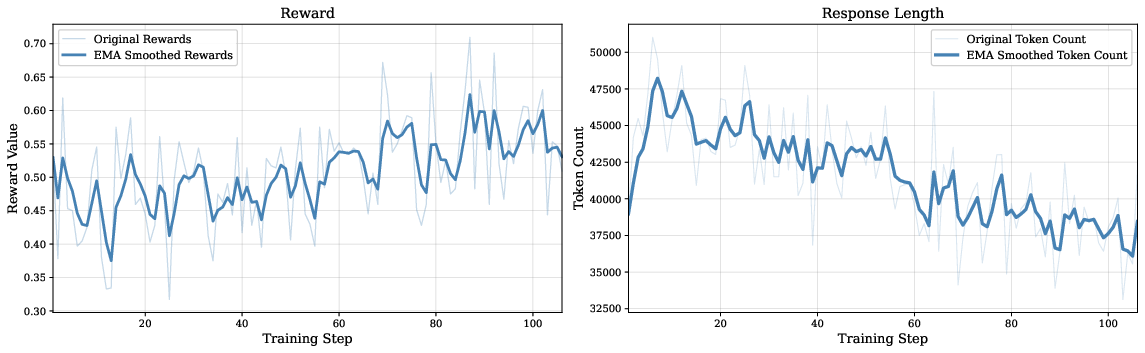
Figure 3: RL training dynamics illustrate concurrent increase in reward and decrease in response length, evidencing more efficient search.
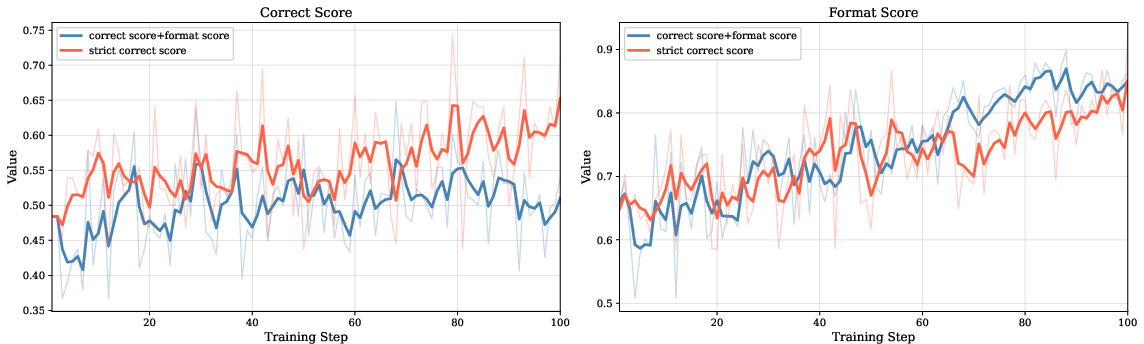
Figure 4: Correct-score and format-score curves under two reward strategies, highlighting elimination of reward hacking via strict reward gating.
Benchmark Construction: Human Expert-Annotated Medical Deep Search
The QuarkMedSearch Benchmark is built through two channels: filtering difficult questions from established benchmarks (BrowseComp, HLE) and pipeline-synthesized samples. Entity-level exclusion ensures zero overlap with training sets. Medical experts rigorously verify clarity, reasoning depth, and answer uniqueness, yielding a 140-question testbed spanning six categories (biomedical fundamentals, drugs/products, research/knowledge, disease/clinical manifestations, clinical procedures, medical institutions).
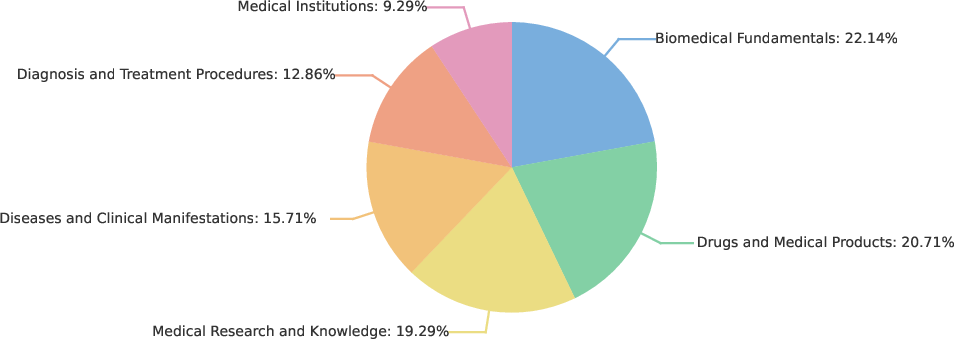
Figure 5: Sample category distribution in the QuarkMedSearch Benchmark, demonstrating coverage breadth and balance.
Empirical Results
QuarkMedSearch achieves strong numerical results on both medical and general deep search benchmarks. On the QuarkMedSearch Benchmark, it attains 55.71 (comparable scale), outperforming its Tongyi DeepResearch backbone by +15 points and matching large-scale models’ performance. Similar gains are seen on BrowseComp-EN, BrowseComp-ZH, and Xbench DeepSearch, with RLVR further improving termination rate and reducing tool calls.
Context-management strategies for handling overflow (Discard-all) yield +10.58 and +9.58 point increases on BrowseComp benchmarks, demonstrating robustness in extended horizon settings.
Application to Real-World Medical Deep Research
Fusion of long-answer samples with deep search capability data shows transferable benefits: in expert evaluations of Deep Research report generation, the fused QuarkMedSearch model achieves preference/tie in 72.3% of cases (G:S:B = 48.9% : 23.4% : 27.7%), validating that intent understanding, tool-call planning, and reflective verification generalize to open-ended clinical documentation.
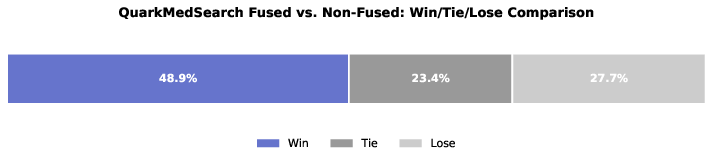
Figure 6: Human expert evaluation outcomes for fused vs. non-fused models on medical Deep Research report generation, evidencing domain adaptation.
Theoretical and Practical Implications
QuarkMedSearch demonstrates that agentic deep search capabilities can be systematically transferred to specialized verticals via principled data synthesis, progressive training, and strict evaluation. The data pipeline enforces retrieval necessity, obfuscates parametric shortcuts, and guarantees answer clarity, while RLVR pushes behavioral efficiency and format adherence, mitigating reward exploitation. Empirical evidence supports the claim that moderate-scale open-source models, through targeted post-training, match or surpass commercial systems on domain tasks. Benchmark construction protocols advance reproducible, category-stratified evaluation.
Practically, QuarkMedSearch enables deployment of strong medical agents for evidence-based information synthesis, complex diagnostic reasoning, and clinical report generation. Theoretically, the work underscores the value of multi-stage data pipeline design, rubrics-based filtering, and strict reward gating in RL for high-stakes domains.
Future Directions
Key areas for future research include: deeper integration of real-time clinical databases, dynamic benchmarking for evolving medical knowledge, adaptive RL reward shaping to handle open-ended report evaluation, and transfer learning architectures for cross-lingual and cross-specialty generalization.
Conclusion
QuarkMedSearch advances the state of medical deep search by integrating a comprehensive pipeline for multi-hop, retrieval-centric data synthesis, combined SFT and RLVR training, and rigorous expert-verified benchmarking. It sets a reproducible reference for transferring agentic foundation model capabilities to demanding vertical domains and demonstrates strong, scalable performance in real-world and synthetic medical scenarios.