- The paper proposes a novel Counterfactual Routing (CoR) mechanism to awaken underutilized experts in sparse MoE models, improving factual recall.
- It employs offline causal analysis and dynamic compute redistribution to reallocate resources based on layer sensitivity and expert impact.
- Empirical evaluations show CoR boosts accuracy on benchmarks like TruthfulQA by about 3.1% without increasing overall compute.
Counterfactual Routing for Mitigating Hallucinations in Sparse Mixture-of-Experts LLMs
Introduction
Sparse Mixture-of-Experts (MoE) architectures have become a dominant approach for scaling LLMs, decoupling parameter count from inference cost by activating only a subset of expert networks per token. Despite their scalability and efficiency, MoE models remain prone to hallucinations, especially for rare, long-tail knowledge tokens. This paper identifies the root cause as the static Top-k routing mechanism: routers favor experts associated with frequent syntactic patterns, systematically under-prioritizing specialists storing critical factual information. The proposed Counterfactual Routing (CoR) framework addresses this by awakening dormant expert modules using offline causal analysis and dynamic, compute-preserving resource allocation.
Offline Causal Analysis Pipeline
The core methodology begins with a hierarchical offline analysis to disentangle knowledge-intensive processing from generic syntax, locate knowledge concentration points within the model, and detect causally decisive but underused expert modules.
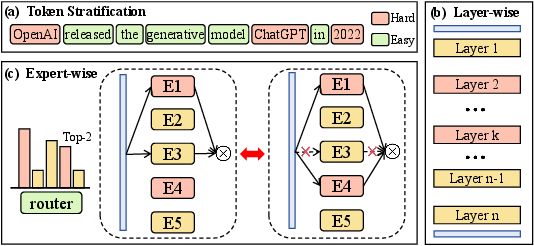
Figure 1: Overview of the Offline Causal Analysis pipeline; a three-stage stratification and analysis process to identify knowledge-bearing layers and dormant experts via token difficulty and contrastive sensitivity.
Tokens are stratified based on uncertainty, segmenting hard (knowledge-intensive) and easy (syntax-dominant) cases. Layer-wise analysis employs Contrastive Sensitivity Normalization to measure each layer’s relative sensitivity (Rl) to hard tokens while negating structural depth bias typical in Transformers. Expert-wise analysis further characterizes experts using the Counterfactual Expert Impact (CEI)—quantifying each expert’s causal value by virtual ablation. Experts with high CEI but low gating confidence comprise the dormant specialists, contextually suppressed by the static router despite their necessity for factual accuracy.
Compute-Preserving Expert Redistribution and Routing Interventions
Online inference adopts a compute-preserving expert redistribution strategy: the overall activation budget remains constant, but resources are dynamically reallocated. More experts are activated in deep, knowledge-intensive layers (identified by high Rl), while shallow, syntax-dominant layers are sparsified.
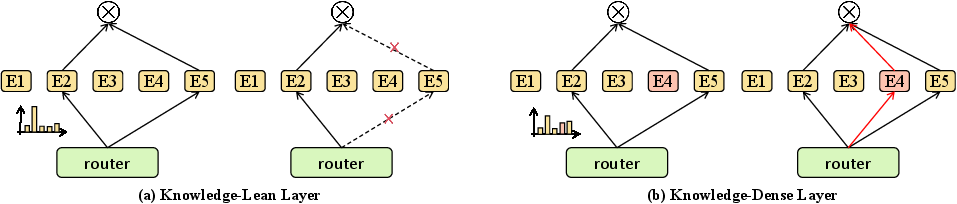
Figure 2: Schematic of Compute-Preserving Expert Redistribution; CoR reallocates budget based on layer sensitivity, saving compute in knowledge-lean layers and expanding it for knowledge-dense layers, maintaining total activation.
Expert selection combines the router’s dynamic context score with the offline-derived, normalized CEI prior. The fusion mechanism rescales scores per layer, tipping the balance in favor of dormant specialists when router uncertainty is high.
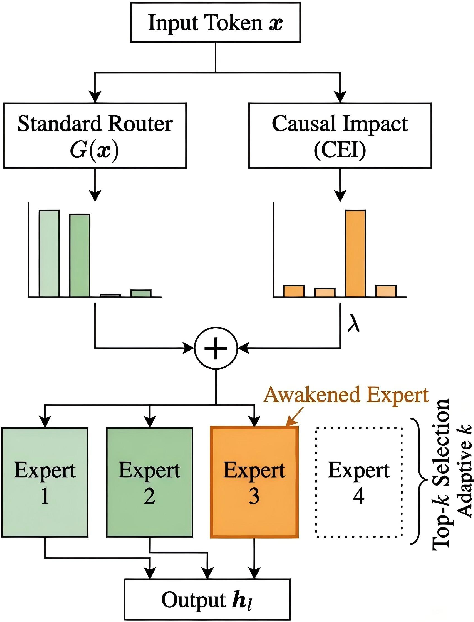
Figure 3: Illustration of Causal-Guided Expert Awakening; CoR’s fusion mechanism elevates dormant experts by combining context-dependent routing with causal priors, overriding frequency bias.
Empirical Results and Ablation Analysis
Extensive zero-shot evaluations on Qwen-3-30B-A3B, DeepSeek-V2-Lite, GPT-OSS-20B, and TeleChat3-105B-A4.7B-Thinking demonstrate CoR’s superiority. CoR consistently increases factual accuracy across TruthfulQA, FACTOR, and TriviaQA benchmarks by a mean of 3.1% without increasing inference cost. This establishes a new Pareto frontier: compute-neutral interventions outperform static scaling (blindly increasing k).
Results also show that post-hoc interventions (DoLa, ITI) are ineffective for MoE hallucinations, confirming that the routing bottleneck is causal rather than superficial. Ablation studies isolate the contributions: layer-wise budget reallocation improves depth-dependent factual recall, while expert-wise awakening retrieves the most critical specialists.
Mechanism Visualization: Dormant Expert Phenomenon
Visualization of router confidence versus CEI score exposes a systematic competence-confidence gap: many experts crucial for factual recall (high CEI) receive minimal gating attention.
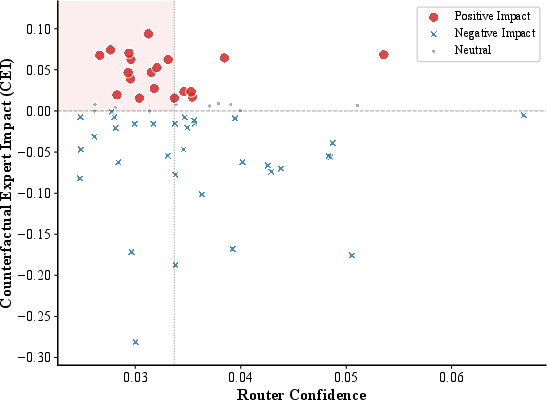
Figure 4: Dormant Expert phenomenon in Layer 22; shaded region represents experts with high CEI but low router confidence, misaligned due to frequency-driven routing.
In deeper layers (e.g., Layer 29), clusters of dormant experts become more prominent, indicating persistent misallocation even near the output.
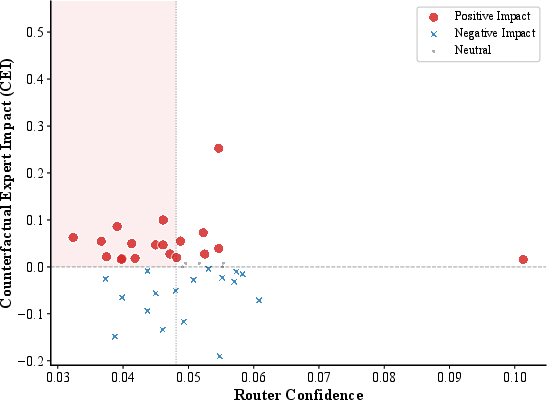
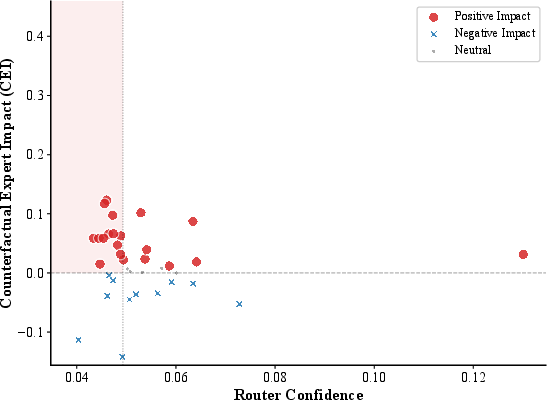
Figure 5: Layer 29 analysis; dense cluster of high-CEI, low-confidence experts, demonstrating robust dormant specialist presence in deep MoE layers.
Pareto Efficiency and Generalization
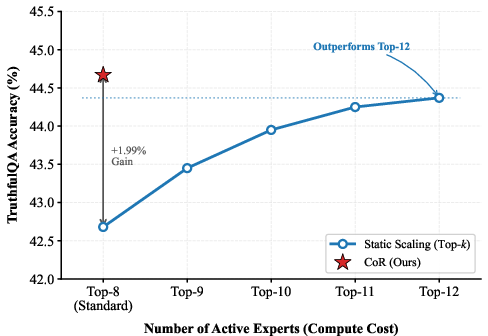
Figure 6: Pareto Efficiency Analysis; CoR curve consistently outperforms static scaling approaches (increasing Top-k), achieving superior accuracy for equivalent compute.
CoR retains or marginally improves performance on general capability benchmarks (ARC, MMLU, GSM8K), confirming that causal interventions do not degrade syntactic or logical reasoning. Synergy experiments indicate that combining CoR with post-hoc decoding methods (DoLa) yields additive gains, establishing orthogonality between routing-level and decoding-level interventions.
Extended Case Studies and Implications
Qualitative comparisons across domains (medicine, law, psychology, history, superstition, trivia) show CoR consistently corrects imitative falsehoods embedded in training corpora, suppressing frequency-driven misinformation and activating accurate specialists. This mechanism is validated in large-scale MoE deployments (TeleChat3), confirming scalability and universality.
Practical and Theoretical Implications
CoR fundamentally challenges the efficacy of uniform or frequency-driven expert activation in MoE architectures, demonstrating that causality-guided selection is critical for robust factual recall. Practical impact includes higher accuracy at fixed computation budgets, enhancing trustworthiness for knowledge-intensive applications (fact verification, QA). Theoretical implications extend to causal interpretability of neural modularity, providing an operational bridge between stored knowledge and active retrieval. CoR's dependence on latent internal knowledge bounds its efficacy; future directions include hybridization with retrieval-augmented generation to expand coverage beyond the pre-training scope.
Conclusion
Counterfactual Routing (CoR) mitigates hallucinations in sparse MoE LLMs by awakening dormant experts based on causal necessity, not statistical popularity. Through hierarchical offline analysis and compute-neutral resource redistribution, CoR aligns model routing with the requirements of factual correctness, achieving substantial accuracy gains without increased compute. This paradigm offers a scalable foundation for trustworthy modular architectures, prioritizing causal recall over frequency-driven optimization.