- The paper presents a novel closed-loop RL framework that co-evolves LLM agents and their data using feedback signals like forgetting, boundary, and rare signals.
- It employs GRPO for agent optimization and uses signal-conditioned LLM re-exploration to generate complex, validated tasks addressing agent weaknesses.
- Empirical results on multiple benchmarks show consistent performance gains, underlining the effectiveness of adaptive curriculum learning without human annotation.
CoEvolve: Agent-Data Mutual Evolution for LLM Agents
Motivation and Background
Existing reinforcement learning paradigms for LLM-based agents largely depend on static and non-adaptive data distributions, typically sourced through human-annotated expert trajectories or offline synthetic data generated via LLMs in an open-loop setting. These approaches are limited by prohibitive data collection costs, poor generalization to interactive complexities, and the inability to adapt the training distribution as the agent policy evolves. The "CoEvolve: Training LLM Agents via Agent-Data Mutual Evolution" (2604.15840) paper presents a framework that introduces closed-loop, interaction-guided mutual evolution of both agent and data distribution to address these core limitations.
The paradigm shift is depicted in (Figure 1), which contrasts traditional expert-supervised and static synthetic generation with the agent-data co-evolution approach.
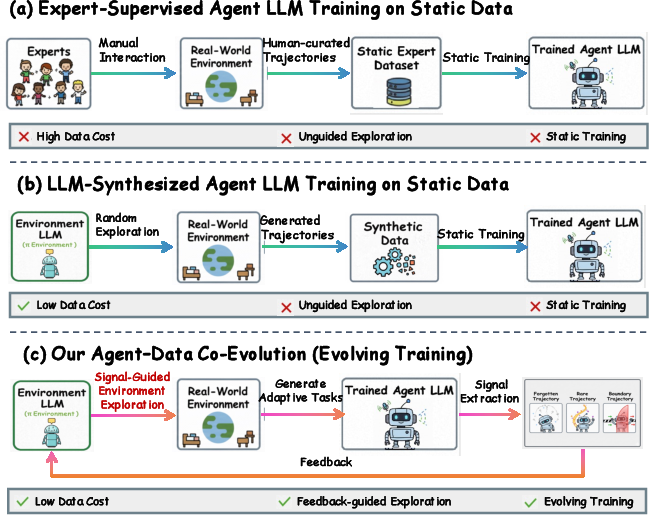
Figure 1: Supervised, static synthetic, and agent-data co-evolution data generation regimes.
CoEvolve Framework
CoEvolve operationalizes a closed-loop RL paradigm where agent weaknesses are detected via training-time feedback signals, which in turn condition environment re-exploration and targeted task synthesis. The feedback types include:
- Forgetting signals: Triggered by regression on previously solved tasks.
- Boundary signals: Performance instability near the decision threshold under a fixed policy.
- Rare signals: Under-explored or long-tail behavior patterns.
The overall framework is illustrated in (Figure 2): RL optimization alternates with signal-driven data evolution—feedback extraction, signal-conditioned LLM re-exploration, and task validation—allowing the agent and its training set to adapt in lock-step, absent any human supervision.
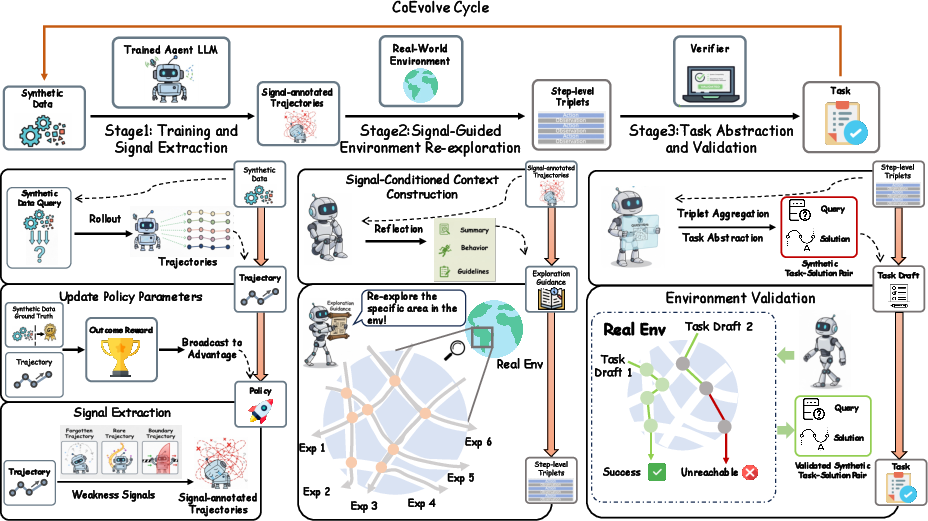
Figure 2: CoEvolve employs GRPO for agent optimization and guides signal-conditioned data generation through LLM exploration and validation in a closed loop.
Training and Feedback Signal Extraction
At each policy update, a group of sampled trajectories is analyzed for feedback signal extraction. The group-relative policy optimization (GRPO) objective is used to maximize expected reward regularized by KL divergence to a reference policy. Empirical criteria for forgetting, boundary, and rare signals are applied to identify failure-prone modes. The explicit encoding of signal extraction criteria ensures focused, precise identification of vulnerability regions in the learning curriculum.
Signal-Guided Re-Exploration and Task Synthesis
For each annotated behavior trace, the LLM is prompted with structured, signal-conditioned contexts to conduct targeted, multi-step explorations. This process recovers diverse behavioral variants that are aligned with the agent’s current deficiencies, unlike open-loop synthetic data pipelines. New tasks are abstracted from collected step-level episodes and validated for executability before incorporation into the evolving training set.
Task Validation and Data Evolution
Synthesized tasks, after abstraction, are validated: only tasks solvable by the agent or yielding non-trivial reward are accepted. This constrains the data evolution process, preventing the proliferation of useless or unexecutable tasks that would degrade optimization.
Empirical Evaluation and Results
CoEvolve is evaluated on AppWorld and BFCL benchmarks using Qwen2.5-7B, Qwen3-4B, and Qwen3-30B-A3B backbones. Consistent, significant gains are observed: CoEvolve achieves absolute average improvements of 19.43%, 15.58%, and 18.14% on Qwen2.5-7B, Qwen3-4B, and Qwen3-30B-A3B, respectively, all without human supervision or annotation.
Performance trajectories, feedback extraction statistics, and data evolution dynamics are shown in (Figure 3):
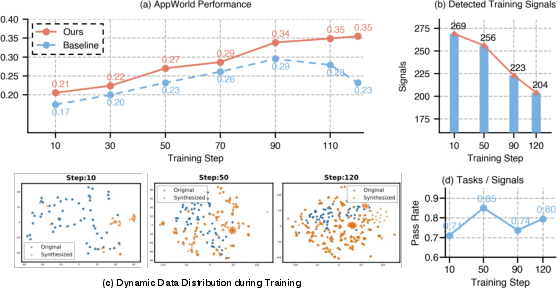
Figure 3: Training dynamics of CoEvolve: superior performance improvement, evolving data complexity, and feedback-driven adaptation to agent weaknesses.
Further analysis reveals that boundary signals make up the majority of extracted weaknesses, with rare and forgetting signals being less frequent but still impactful. Their relative distribution is illustrated in (Figure 4):
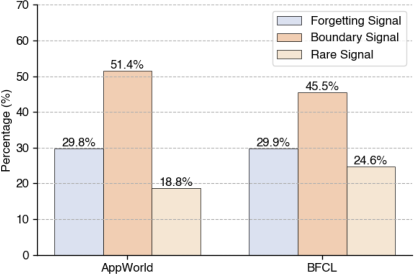
Figure 4: Proportion of behavioral feedback signals extracted during closed-loop agent training.
Synthesis diversity is quantitatively evidenced by moderate-to-low cosine similarity between synthesized tasks and their validation partners, precluding simple mode collapse or duplication (Figure 5).
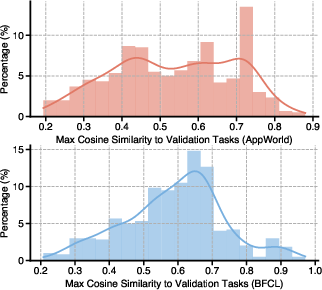
Figure 5: Cosine similarity distribution between synthesized tasks and their respective validation tasks, reflecting non-trivial diversity in generated data.
Ablations and Efficiency
Ablation studies confirm the necessity of all three feedback signal types for optimal performance. The exclusion of any single signal leads to measurable degradation. The validation process for synthesized tasks emerges as critical: removing validation yields a sharp performance drop, highlighting the risk of training collapse under unconstrained data synthesis. The closed-loop regime is shown to outperform open-loop baselines, static synthetic data, and unguided random exploration in all metrics.
Task Complexity and Data Enrichment
Behavioral analyses indicate that synthesized tasks exhibit greater compositional and operational complexity versus original data, promoting longer horizons and richer, multi-turn dependencies (see Figures 6 and 7 for BFCL case studies and interaction turn distributions). AppWorld tasks generated by CoEvolve feature more intricate control-flow and state alignment challenges compared to baseline tasks (Figure 6).
Implications and Future Directions
The practical implication is clear: closed-loop, signal-driven data evolution supports both enhanced final policy performance and efficient, scalable training for LLM agents, closing much of the gap between open and closed-source models. Theoretically, CoEvolve exemplifies a curriculum learning instantiation tailored via endogenous agent performance signals and establishes a blueprint for self-adaptive RL pipelines at scale.
Potential future directions include:
- Expansion and diversification of feedback signals, e.g., by leveraging uncertainty quantification and richer behavioral metrics.
- Robustification of the early-stage feedback loop to mitigate noise when agent competence is low.
- Safety-critical extensions involving human oversight, adversarial filtering, or automated risk-sensitive validation.
Conclusion
CoEvolve substantiates that agent-data mutual evolution, operationalized as a structured, closed-loop RL process, enables consistent and robust improvements in LLM agent learning across domains. The framework provides a scalable, annotation-free pathway for curriculum adaptation, with both efficiency and generalization advantages over static or open-loop synthetic RL training approaches. The proposed paradigm is poised to inform subsequent developments in continual agent learning, self-improving systems, and deployment-safe RL for complex, interactive environments.