- The paper demonstrates that integrating bidirectional interaction rewards and token-level self-distillation significantly improves recommendation accuracy and user simulation.
- The paper’s CoARS framework jointly optimizes recommender and user agents, surpassing traditional prompt-level memory and sparse reward methods.
- The paper validates its approach with experiments on datasets like LastFM and MovieLens, highlighting the benefits of dense, trajectory-aware supervision.
Self-Distilled Reinforcement Learning for Co-Evolving Agentic Recommender Systems: An Expert Analysis
Introduction
Agentic recommender systems (ARS) leveraging LLMs represent a shift from static, single-shot prediction to interactive, multi-turn preference elicitation between agents representing the recommender and the user. However, parameter-level adaptation in ARS remains challenging as existing practices rely mainly on Reflexion-style textual memory or outcome-based reinforcement learning (RL) with predefined or judge-based sparse rewards. These approaches fail to adequately capture the endogenous, richly interactive, and bidirectional nature of agent co-evolution inherent in ARS. The paper "Self-Distilled Reinforcement Learning for Co-Evolving Agentic Recommender Systems" (2604.10029) introduces CoARS, a self-distilled RL framework that internalizes multi-turn experience into model parameters by leveraging collaborative interaction rewards and self-distilled token-level credit assignment.
Shortcomings of Prior Agentic Recommendation Evolution
Conventional ARS architectures utilize either prompt-level memory update—storing interaction histories as text and re-injecting them into LLM prompts—or RL optimization using outcome-based sparse rewards. The memory-based approach is incapable of parameter-level adaptation and hence, cannot robustly encode ARS-specific reasoning. RL-based baselines typically use outcome-level, externally assigned or judge-derived rewards. These are inadequate for several reasons:
- Reward Exogeneity: Rewards are often derived from heuristic, hand-crafted, or fixed-judge criteria, lacking fidelity to actual agent–agent interactions.
- One-Sided Optimization: Prevailing approaches frequently optimize just the recommender, fixing the user agent, leading to suboptimal co-adaptation and poor user simulation.
- Sparse Supervision: Only final outcomes (e.g., user click) are used, ignoring the dense, trajectory-level information that encodes evolving preferences and rationale.
This motivates a framework wherein both agents undergo joint, trajectory-aware optimization; rewards and credit are endogenous to the richly annotated, inherently dense feedback embedded in ARS trajectories.
The CoARS Framework
CoARS introduces two complementary learning mechanisms for dual-agent co-evolution: (1) interaction rewards for both agents, and (2) a self-distilled credit assignment mechanism enabling token-level refinement from historical interaction trajectories.
Bidirectional Interaction Rewards
CoARS defines coupled reward signals for both RecAgent and UserAgent at every turn, extracting dense supervision from each interaction:
- RecAgent Reward: Integrates correctness (matching ground-truth), intensity of user acceptance (st), and interaction-stage sensitivity (Dt). Penalizes errors especially at later stages, and scales rewards to reflect user response granularity, not just binary outcomes.
- UserAgent Reward: Considers correctness alignment, user response direction/magnitude, and similarity to peer users (via embedding-based qt). This design encourages the UserAgent's fidelity to user preferences, tuned by both individual and collaborative/group-level signals.
This joint reward assignment ensures both agents’ policies are directly shaped by the same interactive episode, in contrast to unidirectional or exogenous RL setups.
Self-Distilled Credit Assignment
Outcome-level signals provide limited guidance for refining step-by-step agent reasoning. CoARS applies a self-distillation strategy, casting each agent as both a student (with original interaction context) and a teacher (with privileged, diagnosed reference trajectory). The teacher receives augmented input including:
- The original agent outputs (recommendation, rationale, user response, feedback),
- Corrections based on ground-truth or diagnosis,
- An explicit diagnosis on failure modes.
Token-level diagnostic advantage At,n is computed by contrasting teacher and student output probabilities, clipped to ensure stability. This process transforms historical trajectories into granular credit assignment, enabling agents to reinforce or correct reasoning at the token level, propagating learning signals within the trajectory.
Unified Optimization
Both RecAgent and UserAgent objectives are composed as a mixture of interaction reward (shared among all tokens in a turn) and self-distilled advantages (token-level, trajectory-dependent). This enables role-specific, yet coordinated, optimization—subsuming both global (outcome) and local (token/path) learning signals in a single RL objective.
Experimental Results
Extensive experimentation demonstrates that CoARS outperforms Reflexion, AFL, iAgent, and RecoWorld baselines on the LastFM, MovieLens, and Instruments datasets using Qwen3-8B and Qwen3-4B LLM backbones.
- Recommendation Accuracy: CoARS achieves higher Hit@1 across datasets and backbone scales. For example, on LastFM with Qwen3-8B, CoARS achieves 0.2212 compared to RecoWorld’s 0.1985.
- User Simulation: CoARS yields superior user-alignment (F1) metrics. For instance, on LastFM with Qwen3-8B, CoARS reaches 0.3145 versus the best baseline at 0.1572.
Figures from ablation studies show that eliminating either interaction reward, self-distilled learning, or joint training of both agents results in substantial performance degradation for both recommendation accuracy and user alignment.
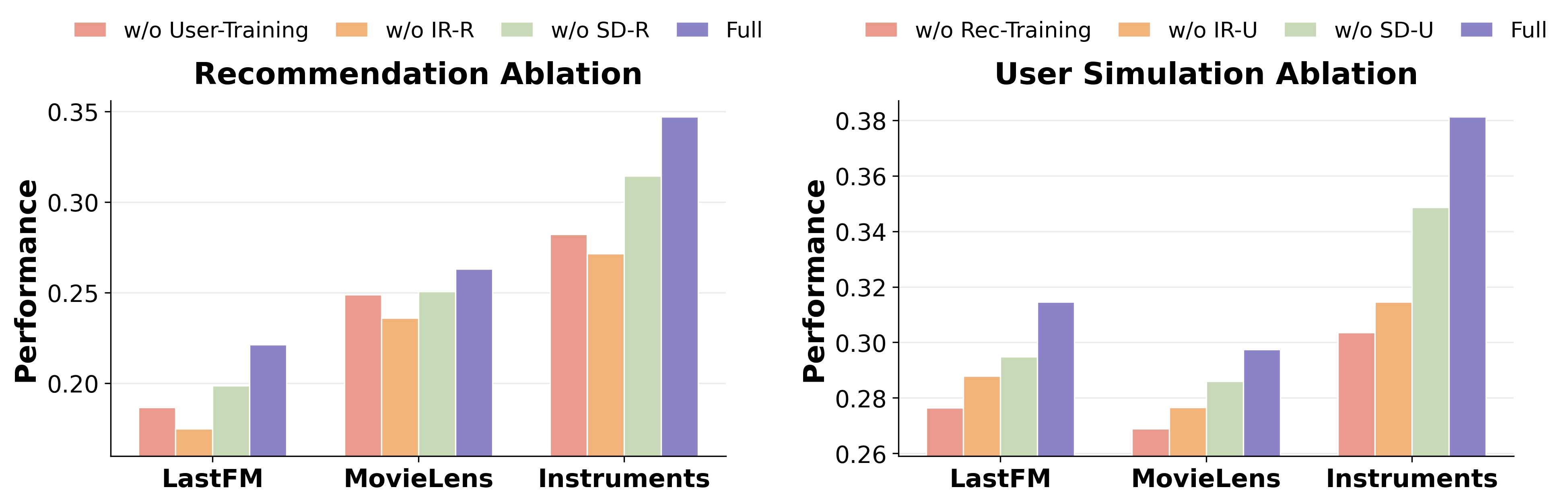
Figure 1: Ablation results illustrate that removing any core CoARS component reduces both recommendation and user simulation performance, underscoring the necessity of each for effective co-evolution.
Analysis and Insights
The CoARS methodology advances ARS research by enabling:
- Interaction-Driven Supervision: Dense, endogenous credit assignment from bidirectional rewards and interleaved self-distillation, surpassing prompt-level or one-sided RL paradigms.
- Agent Co-Evolution: Both recommender and user agents benefit from explicit supervision tied to the same interactive episodes, enhancing model adaptability and aligning agent policies with real user behaviors.
- Token-Level Refinement: Conversion of trajectory records into token-level supervision provides a path for nuanced policy updates, especially beneficial when reasoning paths—not just outcomes—determine recommendation quality.
CoARS’s diagnosis-driven teacher construction and token-level advantage assignment provide clearer attribution of failure modes, leading to coordinated but distinct role-based improvements for each agent.
Implications and Future Directions
From a practical perspective, CoARS demonstrates that ARS can move beyond heuristic reward assignment and memory replay, leveraging bidirectional RL and self-distillation to approach realistic, parameter-level co-adaptation. This leads to improved personalization, better user simulation, and a foundation for adaptive, safe agent design.
Theoretically, self-distilled RL in agentic systems opens paths for:
- More robust preference elicitation and alignment through dense, trajectory-aware credit propagation.
- Scalable, unsupervised refinement of agent reasoning without heavy dependence on external labels or fixed reward functions.
- Advanced personalization by enabling shared yet personalized user policies via historic interaction summarization.
Future developments may include leveraging stronger user instruction modeling, integrating richer environment simulation, and examining convergence and stability properties for self-distilled co-evolving agent ecosystems.
Conclusion
CoARS brings significant methodological innovations to ARS by tightly coupling bidirectional, dense interaction rewards with self-distilled, token-level credit assignment. Empirical results affirm substantial gains in both recommendation quality and user simulation, attributable to the framework’s principled exploitation of interaction histories for coordinated, role-specific agent evolution. CoARS represents a step towards more dynamic, adaptive, and aligned agentic recommendation systems.