- The paper demonstrates that a closed-loop collective evolution system enables LLM agents to continuously improve their skills, achieving up to 88.41% relative gains in creative synthesis tasks.
- It introduces an agentic evolver that aggregates structured session trajectories to autonomously refine or create skills, validated across a diverse 60-task benchmark.
- The framework minimizes manual intervention by synchronizing evidence-backed skill updates, ensuring robust performance improvements and cross-user knowledge transfer.
SkillClaw: Framework for Collective Skill Evolution in Multi-User LLM Agent Ecosystems
The proliferation of LLM-powered agents (e.g., OpenClaw) has enabled practical AI assistants that coordinate multi-step workflows by leveraging skills—reusable, structured procedures encoding environment and tool interaction protocols. However, current skill ecosystems are essentially static: skills are manually curated, installed, and persist as immutable entities after deployment. This results in recurring inefficiencies: similar failures and discoveries are repeatedly encountered and solved in isolation by individual users, with no mechanism to aggregate these experiences into global improvements. Consequently, knowledge remains siloed, constraining systematic advancement and cross-user transfer.
SkillClaw Framework: Architecture and Methods
SkillClaw introduces a closed-loop architecture to enable collective, evidence-driven evolution of skills across a multi-user agent ecosystem.
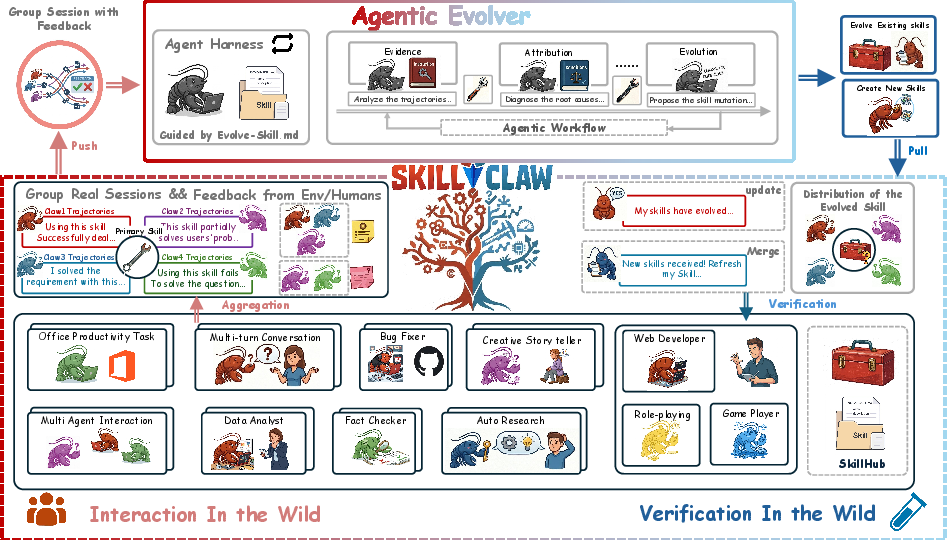
Figure 1: System overview: skill trajectories from all agents are causally structured, aggregated, and analyzed by an agentic evolver that proposes skill refinements or new skills, which are validated and synchronized to all agents.
At runtime, agents deployed independently by different users interact with diverse environments, generating structured session trajectories that preserve complete action–feedback chains. These trajectories are synchronized to a centralized repository and grouped by referenced skills, yielding a shared evidence pool capturing both effective behaviors and recurring failures across heterogeneous deployments.
The core mechanism is an "agentic evolver": an LLM-powered agent receives the accumulated structured evidence (grouped by skill) and, via open-ended reasoning, determines targeted evolution actions:
- Refine: Edit a skill to directly address observed failure modes, preserving validated procedures from successful episodes.
- Create: Synthesize a new skill when recurring behaviors are identified in sessions not explained by any existing skill.
- Skip: Leave the skill definition unchanged if evidence is ambiguous or insufficient.
Crucially, updates are validated in situ: candidate skill modifications are executed in user-like environments under real conditions, and only accepted if they yield superior or at least non-regressive performance. Only validated evolutions are synchronized back to all agent instances, guaranteeing monotonic improvement and deployment robustness.
Empirical Evaluation: Benchmarks and Outcomes
SkillClaw is evaluated on WildClawBench, a complex, real-world benchmark comprising 60 tasks across six functional categories, including productivity, code intelligence, social interaction, retrieval, creative synthesis, and safety alignment. The scenarios feature strict procedural constraints, multimodal tool interfacing, and long-horizon agents. All experiments are conducted in a continuous 6-day, 8-user simulation, with Qwen3-Max as the backbone model.
Numerical results on challenge categories demonstrate strong cumulative gains due to collective evolution:
| Category |
Day 1 |
Day 6 |
Absolute Gain |
Relative Gain |
| Social Interaction |
54.01% |
60.34% |
+6.33% |
+11.72% |
| Search Retrieval |
22.73% |
34.55% |
+11.82% |
+52.00% |
| Creative Synthesis |
11.57% |
21.80% |
+10.23% |
+88.41% |
| Safety Alignment |
24.00% |
32.00% |
+8.00% |
+33.33% |
These improvements are realized with minimal user intervention and moderate rounds of interaction, indicating high sample efficiency and rapid consolidation of local improvements. The validation pipeline ensures that only performance-backed evolutions propagate, eliminating regressions and stabilizing deployment.
Qualitative Case Studies
SkillClaw's closed-loop evolution pipeline was examined in diverse application scenarios:

Figure 2: Slack message analysis—evolved skills introduce task decomposition, error correction, and targeted retrieval, rectifying naïve trial-and-error workflows with structured pipelines.
In a Slack message summarization task, the primitive agent used a brute-force, error-prone retrieval strategy. SkillClaw evolved a workflow with pre-filtering, selective retrieval, and explicit correction of environment-specific tool configurations, resulting in higher robustness and reliability.

Figure 3: ICCV 2025 oral paper analysis—evolved skills implement stricter field definitions and cross-reference OpenAccess databases, improving accuracy under noisy conditions.
For document analysis, the evolved skill replaces naive, heuristic matching with constraints based on structural cues (e.g., parsing official PDFs) and ensembling over multiple authoritative sources, substantially boosting the fidelity of extraction.

Figure 4: SAM3 inference in incomplete environments—skills evolved to systematically inspect, patch, and adapt execution given missing dependencies or hardware.
Robustness under partial observability is achieved by evolving the workflow to incorporate pre-execution inspection, fallback strategies, and adaptive dispatch under resource constraints.

Figure 5: Multi-criteria product selection—evolved skills perform joint constraint satisfaction and provide calibrated outcomes rather than over-committing to partial matches.
For complex decision processes, SkillClaw evolved multi-condition verification and explicit reporting of infeasibility, yielding calibrated outputs aligned with ground-truth constraints.
Comparative Analysis and Domain Impact
SkillClaw's architecture achieves several distinct properties compared to prior approaches:
- Collective Evolution: Aggregation across user populations enables generalizable, non-idiosyncratic improvements.
- Full Automation: Evolution loop operates without manual curation or user burden, operationalizing agent self-improvement at deployment scale.
- Agentic Reasoning: The evolver leverages LLM inference over structured evidence, handling unseen behavior and context-sensitive deficiencies beyond reach of rule-based or template-driven updates.
Theoretical implications include the operationalization of collective intelligence in agentic systems, bridging the persistent gap between single-agent online adaptation and population-level knowledge consolidation. Practically, SkillClaw enables AI teams to deploy evolving agents that continuously adapt to real-world, changing environments and requirements with minimal retraining or engineering intervention.
Limitations and Future Directions
Empirical analysis reveals that the gains from skill evolution are most pronounced when errors are procedural and environment-specific, whereas improvements are less dramatic in tasks demanding nuanced semantic reasoning. This suggests synergy with agent-level enhancements such as improved subagent orchestration, context management, and intrinsic motivation for exploration. There is clear potential for extension:
- Integration with meta-reinforcement learning and episodic memory for lifelong continual adaptation.
- Cross-system skill libraries with multi-agent federated synchronization.
- Multi-modal and cross-domain evolution with richer, structured feedback and reward signals.
Expanding the scale (over longer horizons and broader user/task distributions) and refining validation strategies to reduce token and compute overhead are salient next steps.
Conclusion
SkillClaw proposes and validates a system for collective, automated, agentic skill evolution in large-scale, multi-user LLM agent deployments (2604.08377). By transforming decentralized experience into reusable, evidence-driven skill updates, the framework enables robust, monotonic improvement and seamless cross-user knowledge transfer. Experimental results confirm significant, category-specific performance gains in diverse real-world tasks. This paradigm establishes a foundation for the development of scalable, continuously improving agentic ecosystems—unlocking new avenues for adaptive AI aligned with dynamic and heterogeneous user requirements.