- The paper introduces a novel benchmark using Domain-Agnostic Execution Flow (DAEF) to assess agents' ability to discover, repair, and evolve skills over multi-task curricula.
- The evaluation demonstrates that effective skill repair and consolidation can boost task completion rates (e.g., from 62.65% to 71.08%) while reducing costs and improving efficiency.
- The study highlights key challenges such as skill fragmentation, error propagation, and domain-specific biases, underscoring the need for robust skill evolution strategies in autonomous agents.
SkillFlow: Benchmarking Lifelong Skill Discovery and Evolution for Autonomous Agents
Introduction and Motivation
SkillFlow introduces a comprehensive evaluation paradigm for autonomous agent lifelong procedural learning by focusing on skill discovery, repair, and transfer across realistic, workflow-grounded task sequences. The core motivation is to move beyond prior benchmarks that predominantly evaluate static skill utilization, instead probing the capacity for agents—typically instantiated as LLM-based tool-using command-line agents—to autonomously construct, revise, and organize reusable skill artifacts over continuous multi-task curricula. The design systematically eliminates confounds from domain specifics by employing the Domain-Agnostic Execution Flow (DAEF), ensuring that agents are assessed on their workflow-cognition and skill externalization capabilities, rather than superficial task overlap or rote recall.
Benchmark Structure: DAEF and Task Construction
SkillFlow contains 166 tasks grouped into 20 workflow families spanning five high-level domains: Finance/Economics, Operations/Supply Chain, Healthcare/Life Sciences, Governance/Strategy, and Data/Document Intelligence. Each family is defined by a shared DAEF—an abstract workflow graph specifying operation types and their dependency structure, decoupled from domain-grounded details. DAEF abstraction enables cross-domain transfer and controlled variation in task instances, supporting rigorous evaluation of skill generalization and persistent procedural abstraction.
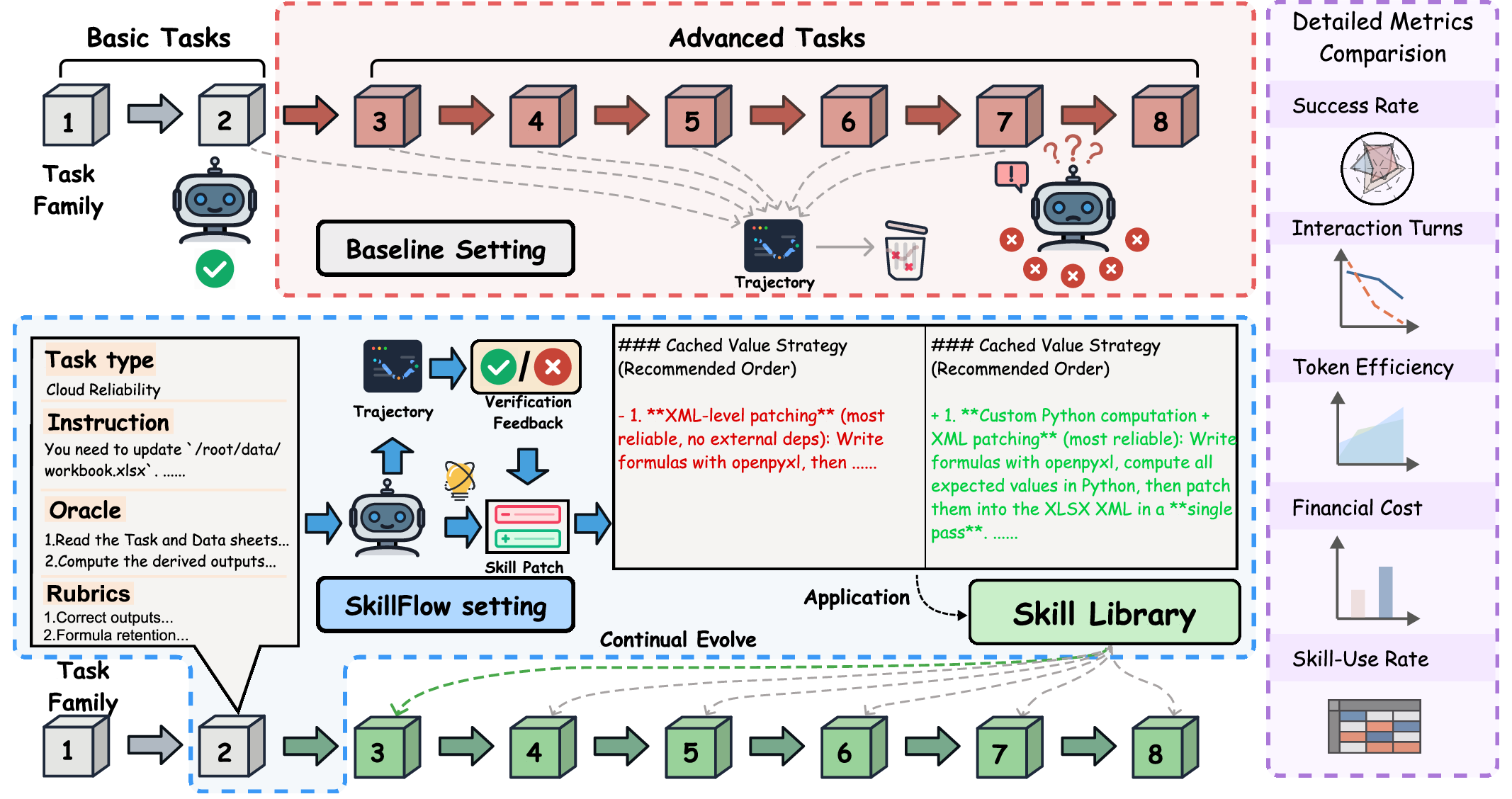
Figure 1: Contrasts static-skill evaluation with the SkillFlow lifelong protocol, where agents externalize, patch, and reuse skills across DAEF-defined task families.
The multi-stage construction pipeline ensures high task quality:
- Seed Collection: Tasks from GDPval and SkillsBench, filtered for authenticity and clarity.
- Skill Matching: Semantic retrieval (using Qwen3-embedding-4B) links seeds to external skills, initializing the explicit skill reference base.
- Domain Expansion: Dual-agent automated construction iteratively generates new task variants under a fixed DAEF, validated by an Architect Agent (generating task assets) and a Critic Agent (verifying structural consistency and robustness).
- Human Review: Ensures correctness, logical consistency, no instruction leakage, and graded task difficulty.
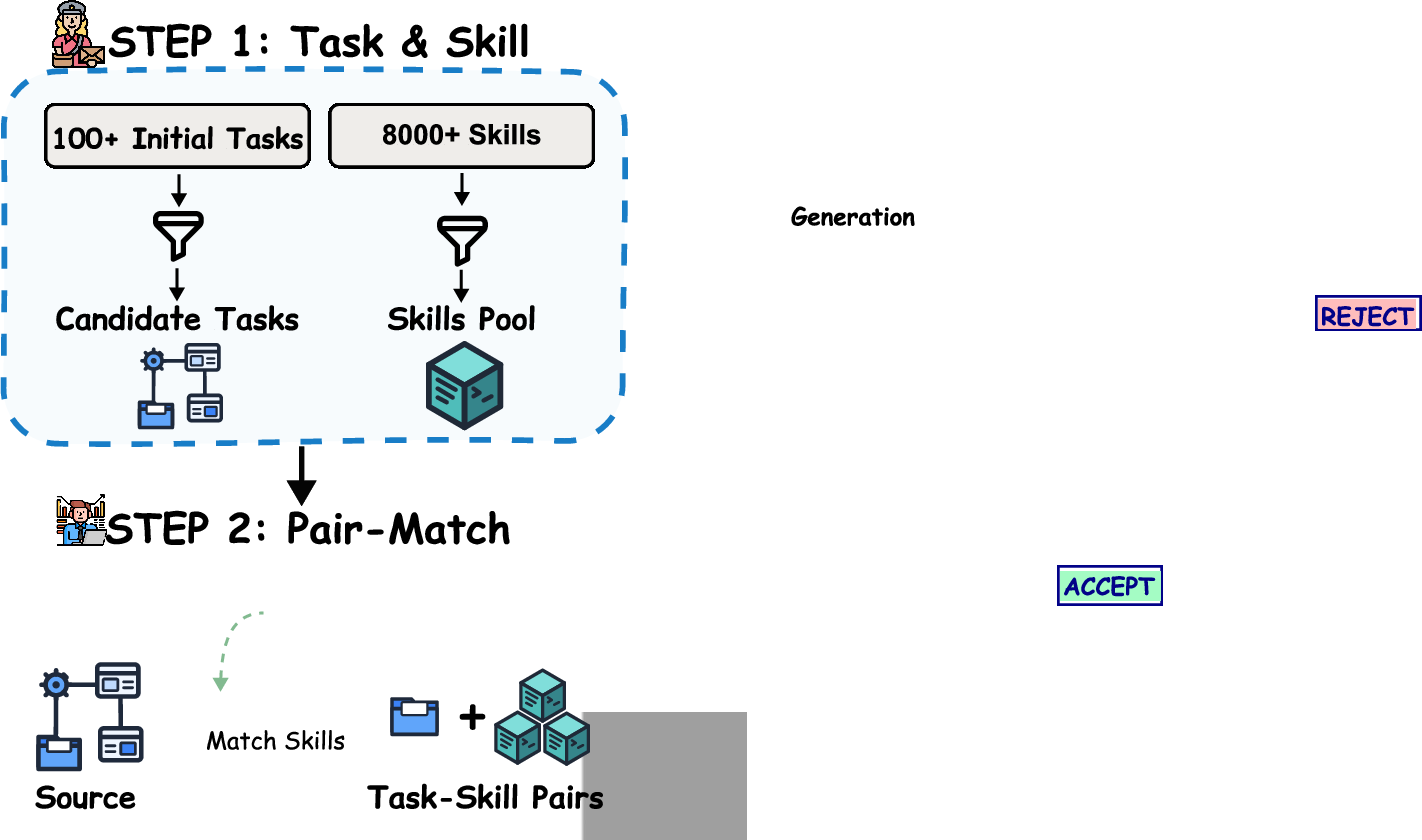
Figure 2: Task construction pipeline involving seed curation, embedding-based skill matching, DAEF-based iterative expansion, and human review.
Lifelong Learning Protocol and Skill Evolution
The benchmark operationalizes lifelong skill evolution as a sequential loop: for a given DAEF family, agents start with an empty skill library, attempt tasks in curriculum order, and generate explicit skill patches conditioned on execution traces and verifier rubric feedback. After each task, models update their external skill repository by adding, modifying, or deleting skills via auditable patches (structured with summary, upsert_files, and delete_paths). Thus, the evaluation is not limited to pass/fail, but also scrutinizes the evolution and practical utility of the skill library—specifically, whether stored skills are actually reused and lead to measurable efficiency and task success improvements.
Metrics and Evaluation
SkillFlow introduces three primary evaluation axes:
- Task completion rate: Proportion of tasks successfully solved under automated verification.
- Efficiency: Per-task cost in monetary terms, interaction turns, and output token count.
- Skill generation/reuse: Number of retained skills and per-task skill utilization rate, exposing gaps between skill creation and effective deployment.
Experimental Results
Empirical analysis over 11 models shows pronounced heterogeneity in lifelong skill evolution efficacy. The key results can be summarized as follows:
- Claude Opus 4.6: Achieves the strongest improvement, with completion rate rising from 62.65% (vanilla) to 71.08% (+8.43 point gain) under skill evolution, with cost reduction and consolidated library maintenance.
- Consolidation vs. Fragmentation: Strong agents tend to develop compact, highly revised skill libraries which enable robust transfer and procedural improvement. In contrast, weaker agents suffer from skill inflation—accumulating fragmented, minimally reused skills—leading to cognitive overload and negative or marginal gains.
- Skill Repair is Critical: The main capability gap lies in editing and correcting incorrect or partial skills, not in producing initial skill artifacts. Agents able to effectively revise erroneous skills demonstrate pronounced positive transfer.
- Negative Transfer: For certain models (e.g., Qwen-Coder-Next, GPT 5.3 Codex), skill evolution is detrimental, reducing completion rates, often due to persistent propagation of workflow errors or overfitting to specific failed abstractions.
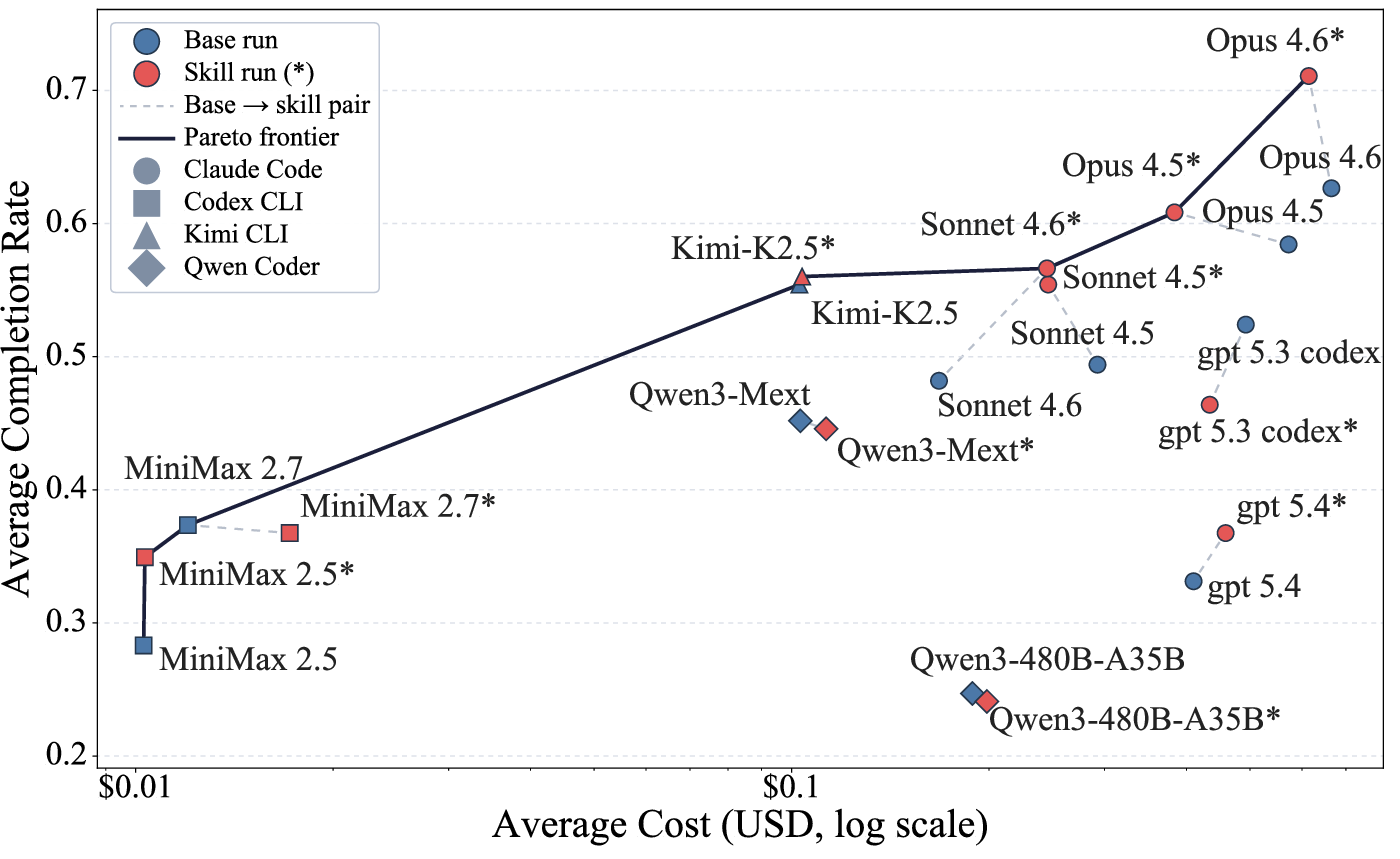
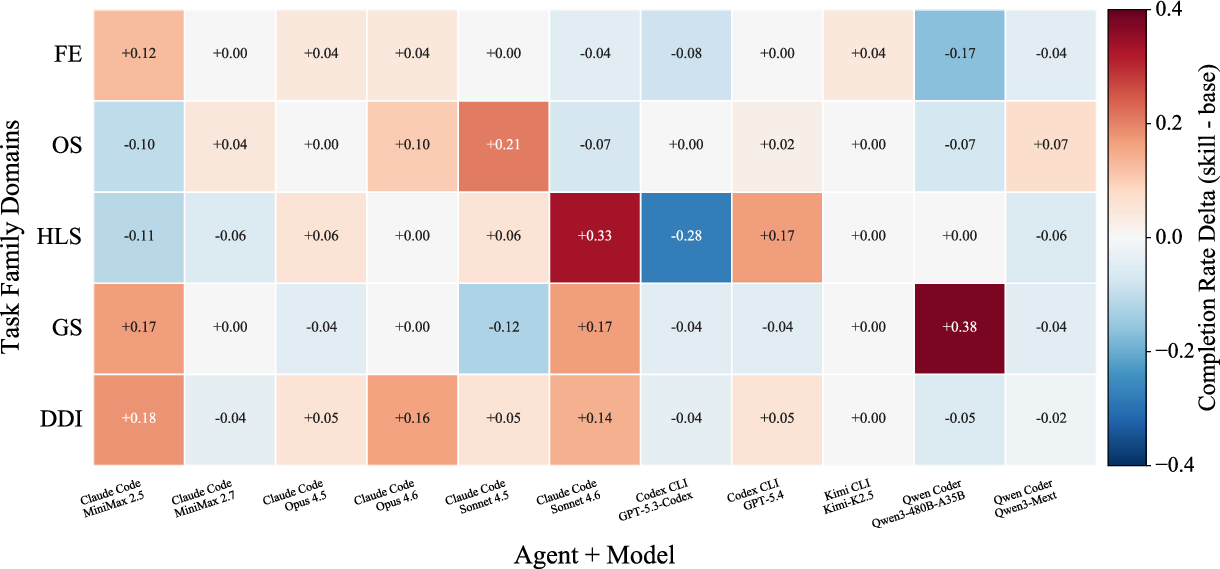
Figure 3: Completion--Cost Pareto frontier highlighting models/settings where skill evolution yields higher task completion at equal/lower cost and regimes where additional skill use is wasteful.
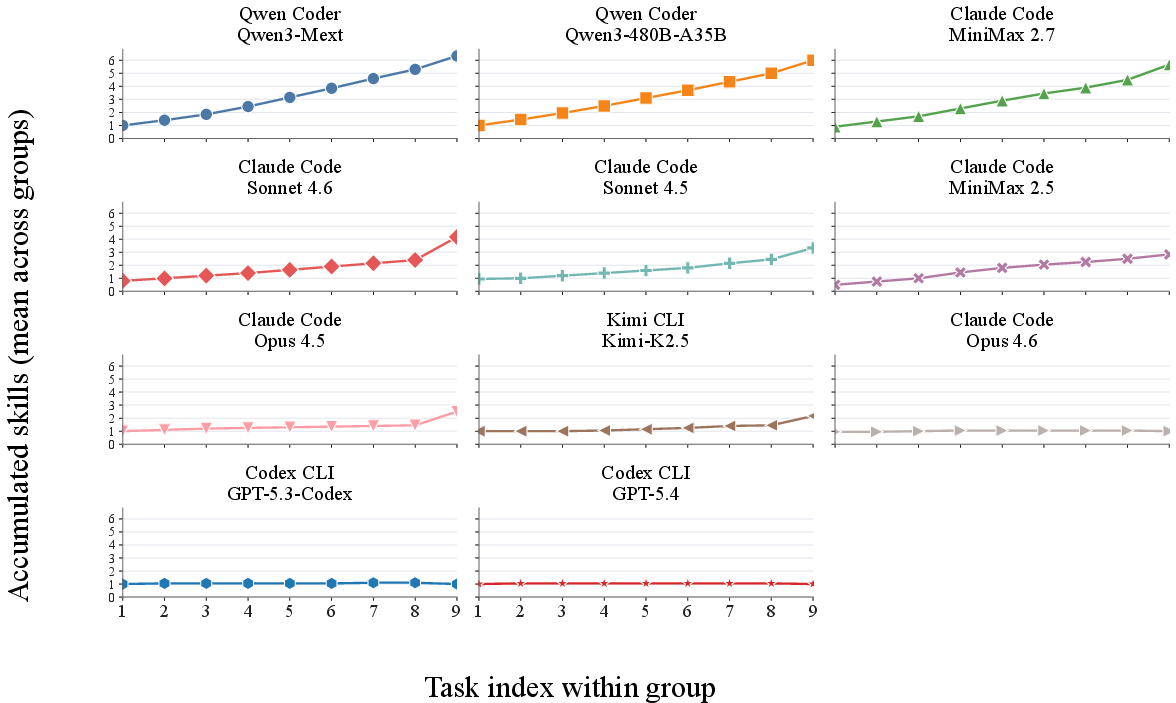
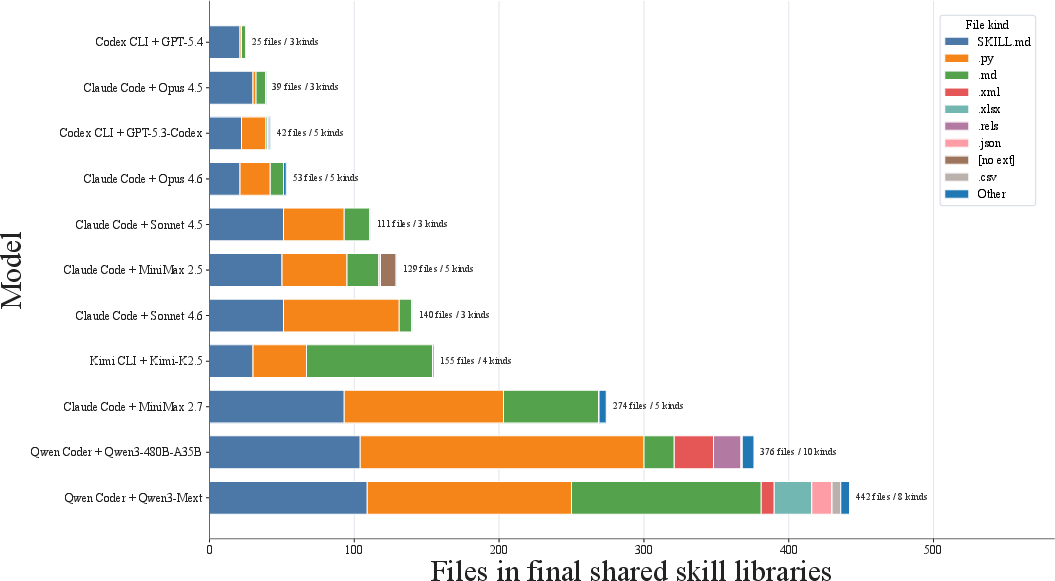
Figure 4: Cumulative skill count by task, demonstrating crisp contrast between models who consolidate libraries as they progress, and those who monotonically accumulate skills.
- Domain Sensitivity: Gains from skill evolution are distributed across major domains, but some (e.g., Data/Document Intelligence) exhibit broader positive transfer, while others show higher incidence of negative transfer, reflecting nuanced interaction between workflow topology, agent architectural biases, and skill abstraction granularity.
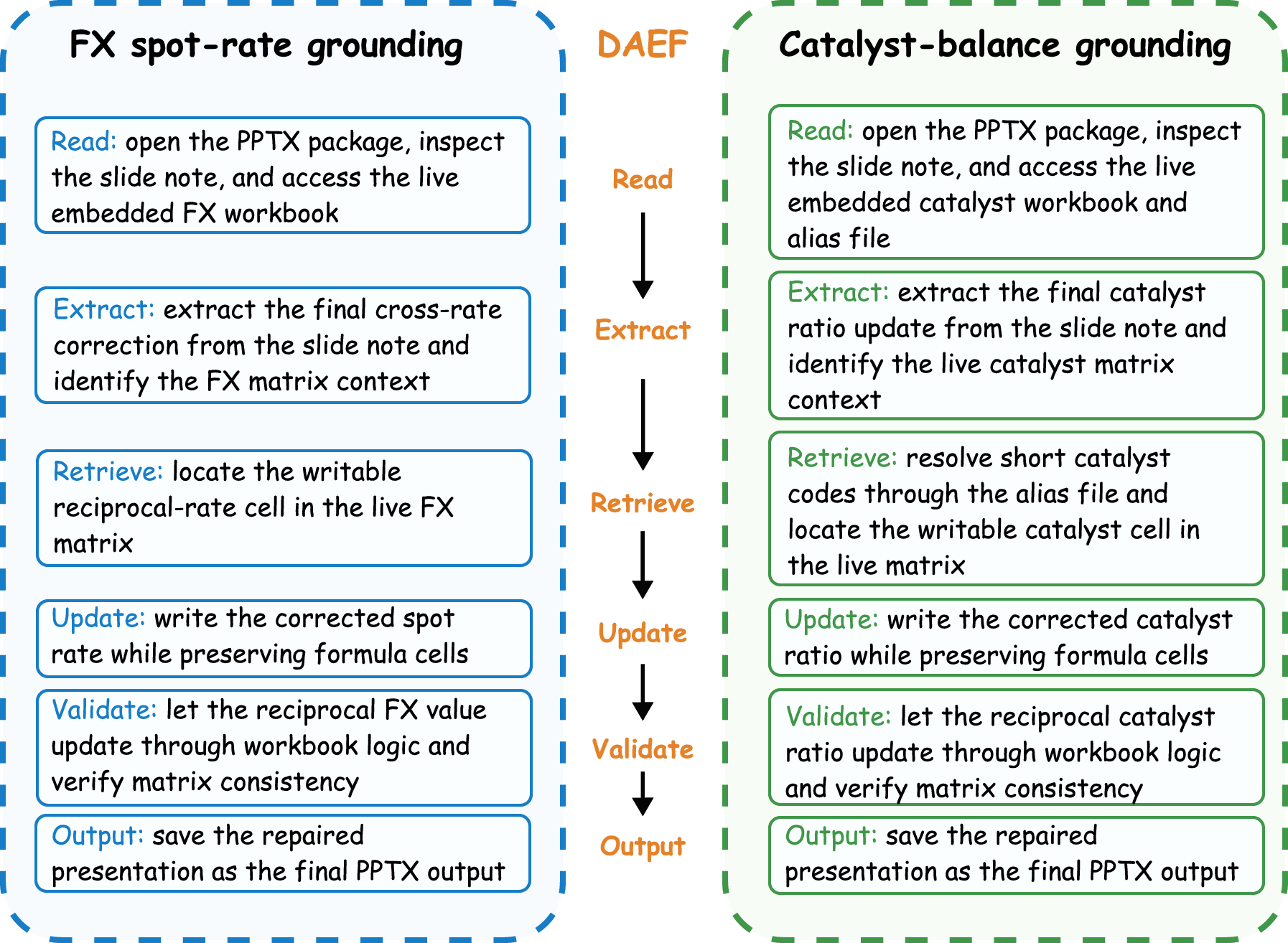
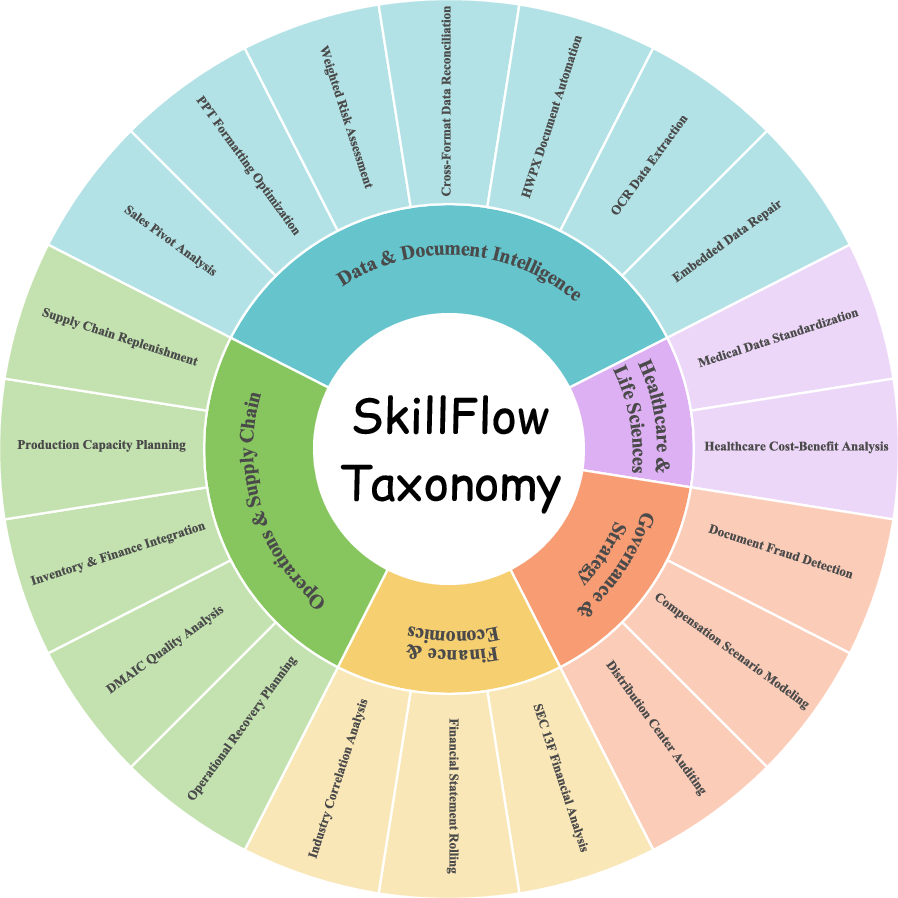
Figure 5: DAEF taxonomy mapping: inner ring denotes benchmark domains, outer shows corresponding DAEFs; distinct tasks instantiate the same abstract workflow, facilitating cross-domain transfer.
Failure Analysis
SkillFlow enables rigorous ablation and trajectory analysis, uncovering common failure types:
- Inability to repair flawed skills (resulting in error propagation across subsequent tasks)
- Skill library bloat, yielding retrieval ambiguity and context-window exhaustion
- Overly domain-specific skills with minimal generalization
- Toolchain-verifier mismatches and incomplete or improper verification practices
Theoretical and Practical Implications
SkillFlow demonstrates that static benchmarks or mere skill usage measurement substantially overstate actual agent reliability and generalizability. Succinct, correct, and repairable procedural abstractions—rather than raw skill volume or naive extraction—are the prime determinants of effective lifelong learning. The benchmark operationalizes a minimal file-level external memory interface, which, in conjunction with DAEF-based curriculum design, exposes fundamental limitations in current LLM-driven agents: difficulty with long-horizon skill repair, tendency for error amplification, and lack of robust consolidation heuristics. This positions SkillFlow as a touchstone for explicit memory and lifelong procedure-centric agent architectures.
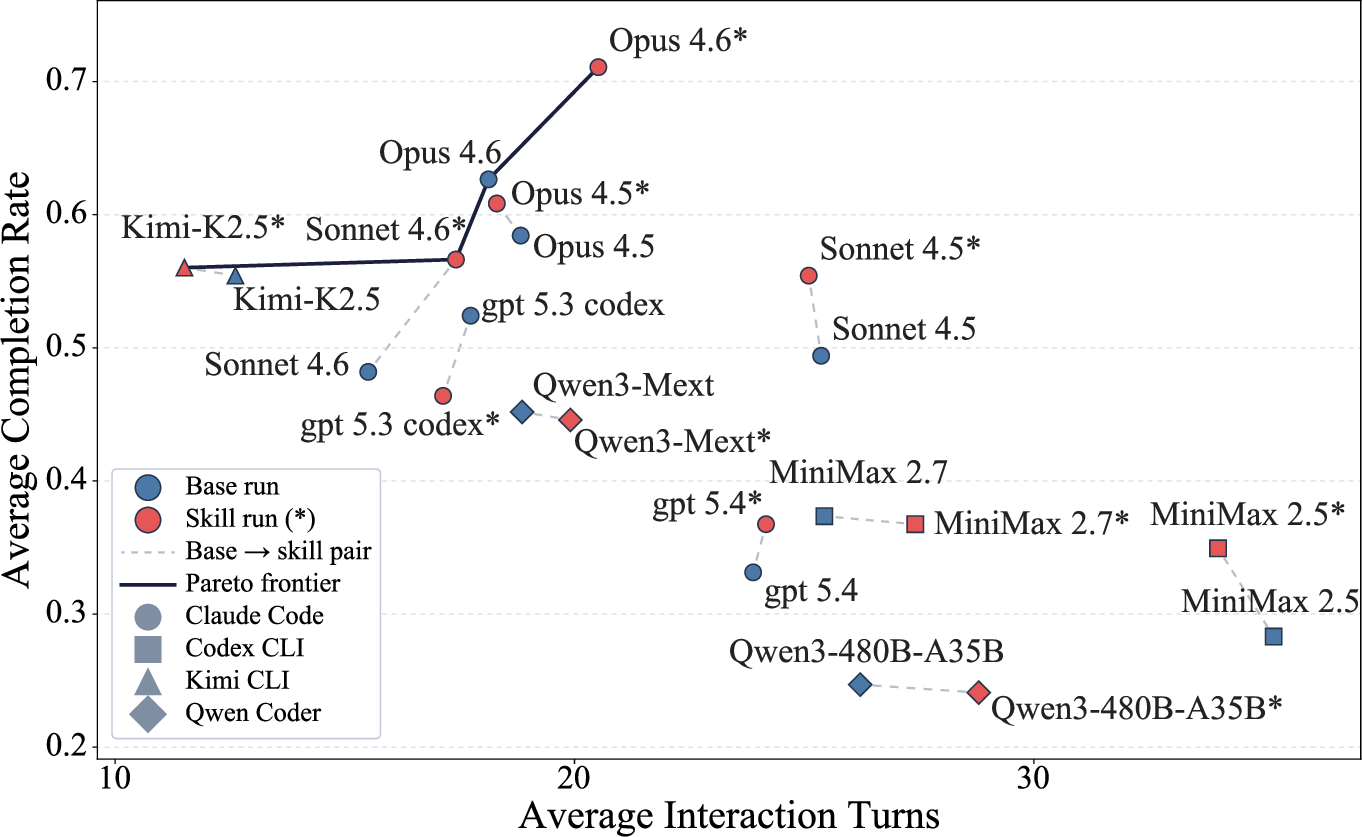
Figure 6: Completion—Interaction Turns Pareto frontier, enabling diagnosis of trade-offs between procedural success and conversational efficiency.
Towards Robust and Adaptive Agents
Practically, SkillFlow's results suggest that external skill repositories and explicit evolution protocols are necessary but not sufficient for robust adaptive behavior: agents must also develop metacognitive strategies for skill abstraction, revision, and selective retrieval. The benchmark's trajectory-level annotations and failure taxonomies set foundational requirements for future work in skill distillation, policy-gradient update mechanisms over external memory, and curriculum-aligned meta-reasoning. Long-term, integrating structured skill evolution into agent operating paradigms is essential for deploying autonomous systems in open-ended, high-stakes application domains.
Conclusion
SkillFlow establishes a rigorous empirical benchmark for lifelong skill discovery and evolution, demonstrating that agentic skill externalization is neither trivially beneficial nor uniformly effective; its utility is sharply conditioned on agent capability, consolidation strategy, and meta-repair proficiency. The DAEF-grounded design and explicit sequential evaluation pipeline make it a critical diagnostic for agent self-improvement paradigms and a data-efficient platform for memory-augmented training regimes. Continued research is needed to close the gap between skill writing and stable, high-utility skill repair, illuminating the next frontier in scalable, general-purpose autonomous agents.