- The paper presents LifelongAgentBench, a unified benchmark that measures LLM agents' lifelong learning abilities across Database, OS, and Knowledge Graph environments.
- It introduces methodologies like explicit skill taxonomy, probabilistic sampling, and a group self-consistency protocol to tackle challenges such as catastrophic forgetting and context overflow.
- Experimental results reveal that conventional experience replay is limited, emphasizing the need for adaptive memory strategies to enhance continual learning in large language models.
Evaluating LLM Agents as Lifelong Learners with LifelongAgentBench
Motivation and Problem Scope
The development of LLM-based agents has enabled complex autonomous interaction with dynamic environments. However, contemporary LLM agents are inherently stateless and lack the mechanisms for incremental learning, cross-task knowledge retention, or robust transfer—a critical distinction from human intelligence and a key bottleneck for building generally capable AI. Existing LLM benchmarks evaluate isolated, single-shot tasks and do not address catastrophic forgetting, sequential skill transfer, or the effects of accumulating diverse experiences.
LifelongAgentBench addresses this gap by providing the first unified benchmark to rigorously assess lifelong learning in LLM agents. This framework systematically measures agents’ abilities across knowledge-intensive, interactive settings, focusing on their capacity to acquire, retain, and reuse atomic skills over long sequences of dependent tasks rather than treating each task in isolation.
Benchmark Composition and Properties
LifelongAgentBench consists of modular, skill-grounded tasks embedded within three diverse environments: Database (DB), Operating System (OS), and Knowledge Graph (KG). Each task is constructed to target explicit atomic skills, enforce inter-task dependencies, and exhibit realistic complexity.
The design principles enforce:
- Explicit skill taxonomy and concurrency modeling,
- Probabilistic sampling and noise management to ensure balanced skill coverage,
- Automatic task validation for label verifiability,
- Reproducibility via containerized environments and strict seed control,
- Modularity for seamless environment and agent extension.
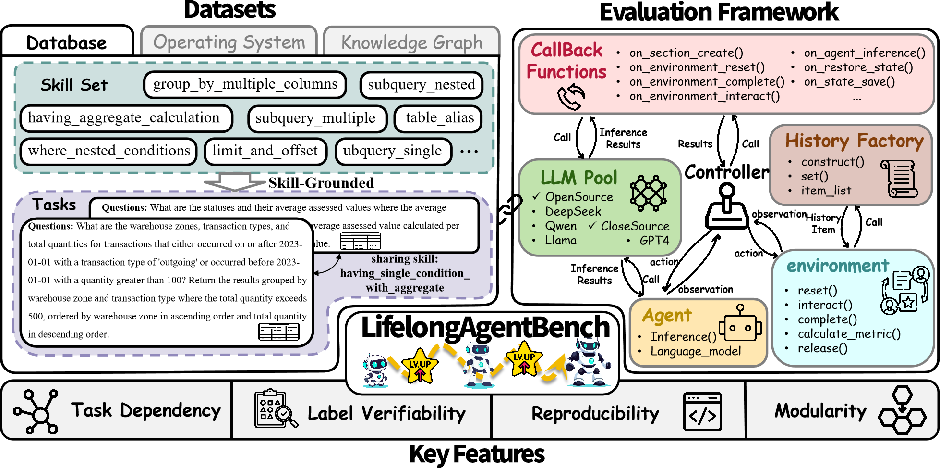
Figure 1: A unified dataset and evaluation framework, highlighting skill-grounded tasks, modular components, and four essential properties: task dependency, verifiability, reproducibility, and modularity.
Statistical analysis of the skill distributions illustrates the breadth and balance of the dataset, with coverage across both frequent and rare skills, and varying levels of concurrency in task composition.
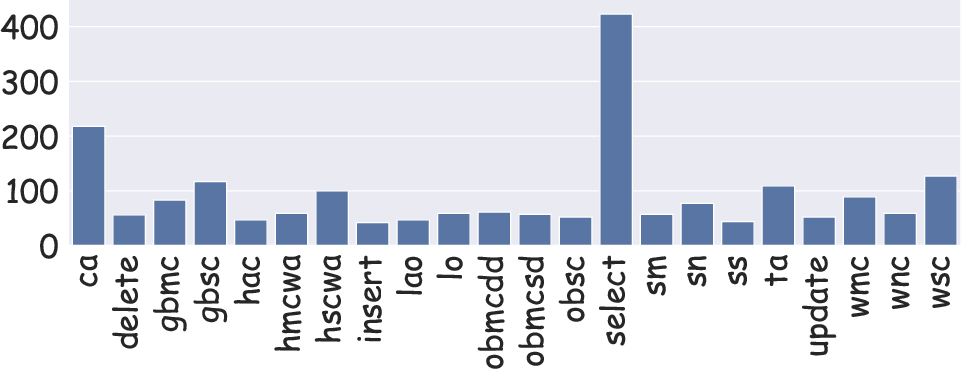
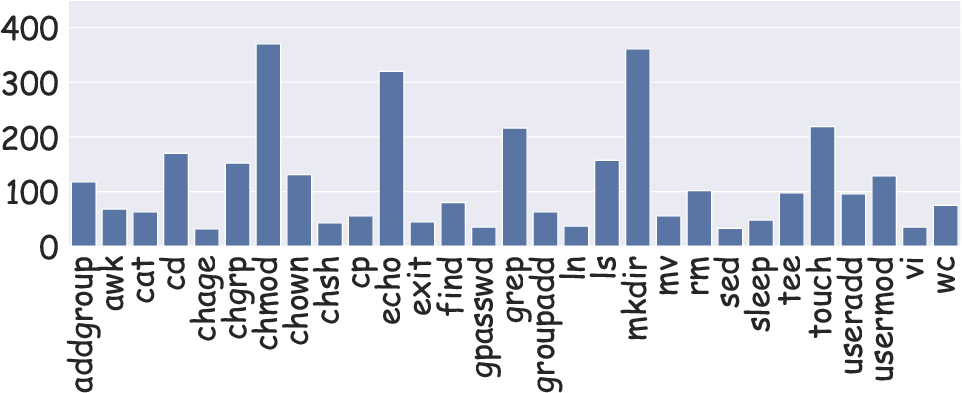
Figure 2: The dataset maintains diverse, balanced coverage of skills, enhancing validity for lifelong learning evaluation.
Data Construction Across Environments
Database Environment
Tasks are deployed in isolated MySQL containers, with each task tied to a subset of 22 SQL skills. The construction pipeline ensures the sampling of low-frequency skills, avoidance of isolated tasks, and rigorous output verification via both automatic and manual methods.
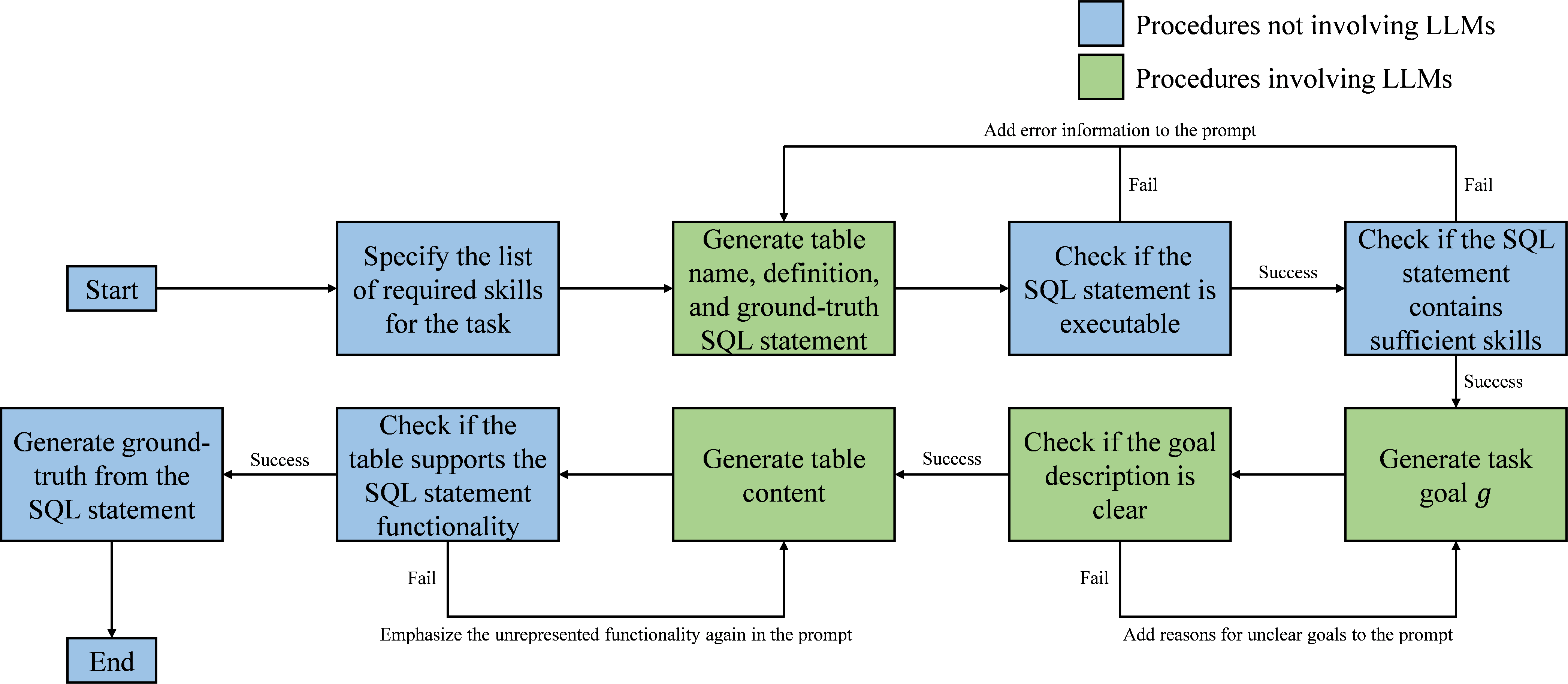
Figure 3: Construction pipeline for the Database environment, emphasizing sampling, validation, and isolation.
Operating System Environment
Disposable Ubuntu containers are used to generate OS tasks, each comprising multi-step Bash command sequences. The skill set includes 29 commands, with tasks sampled for complexity to ensure significant inter-skill dependency. Outputs are matched with expected results using automated scripts and checksums.
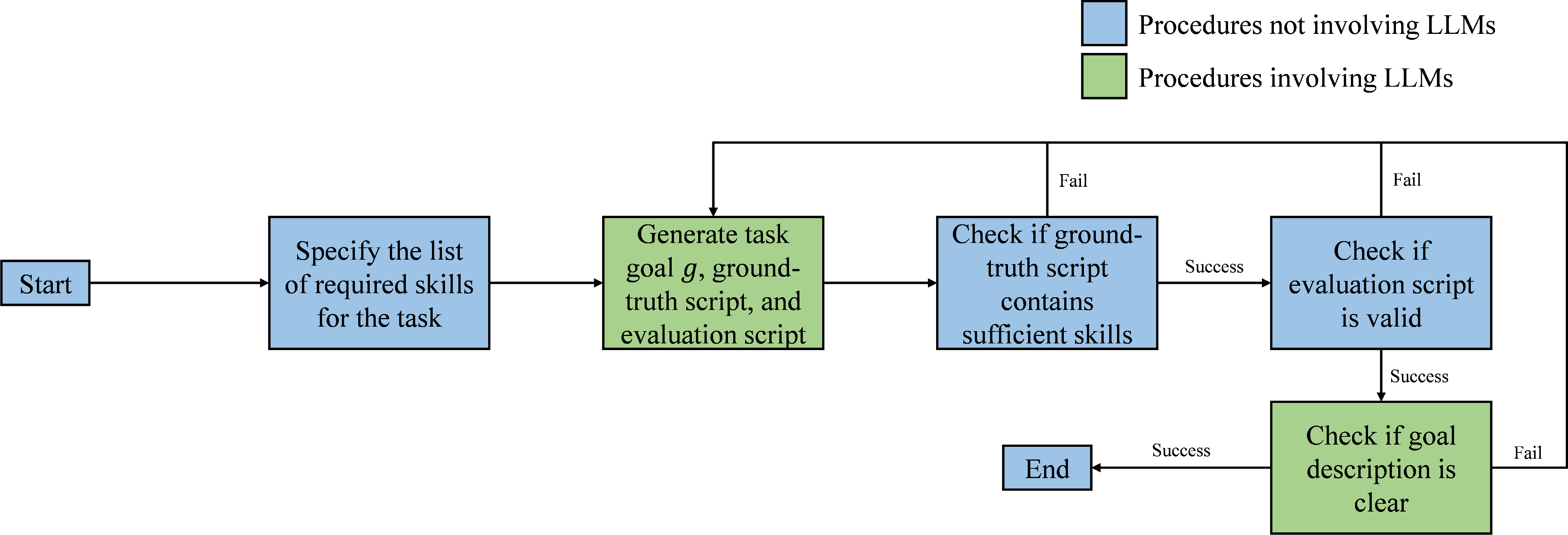
Figure 4: Task generation and validation procedure for the Operating System environment.
Knowledge Graph Environment
Knowledge Graph tasks are mapped from real QA datasets to multi-step action plans employing a constrained set of logical operations. Task validation involves both automatic and human-in-the-loop checks.
Evaluation Framework Architecture
The evaluation framework integrates datasets, API infrastructure, and modular agent–environment–controller–callback pipelines. It enforces strict sequential task execution, supporting both single-machine development and distributed deployment, enabled by a custom RPC toolkit.
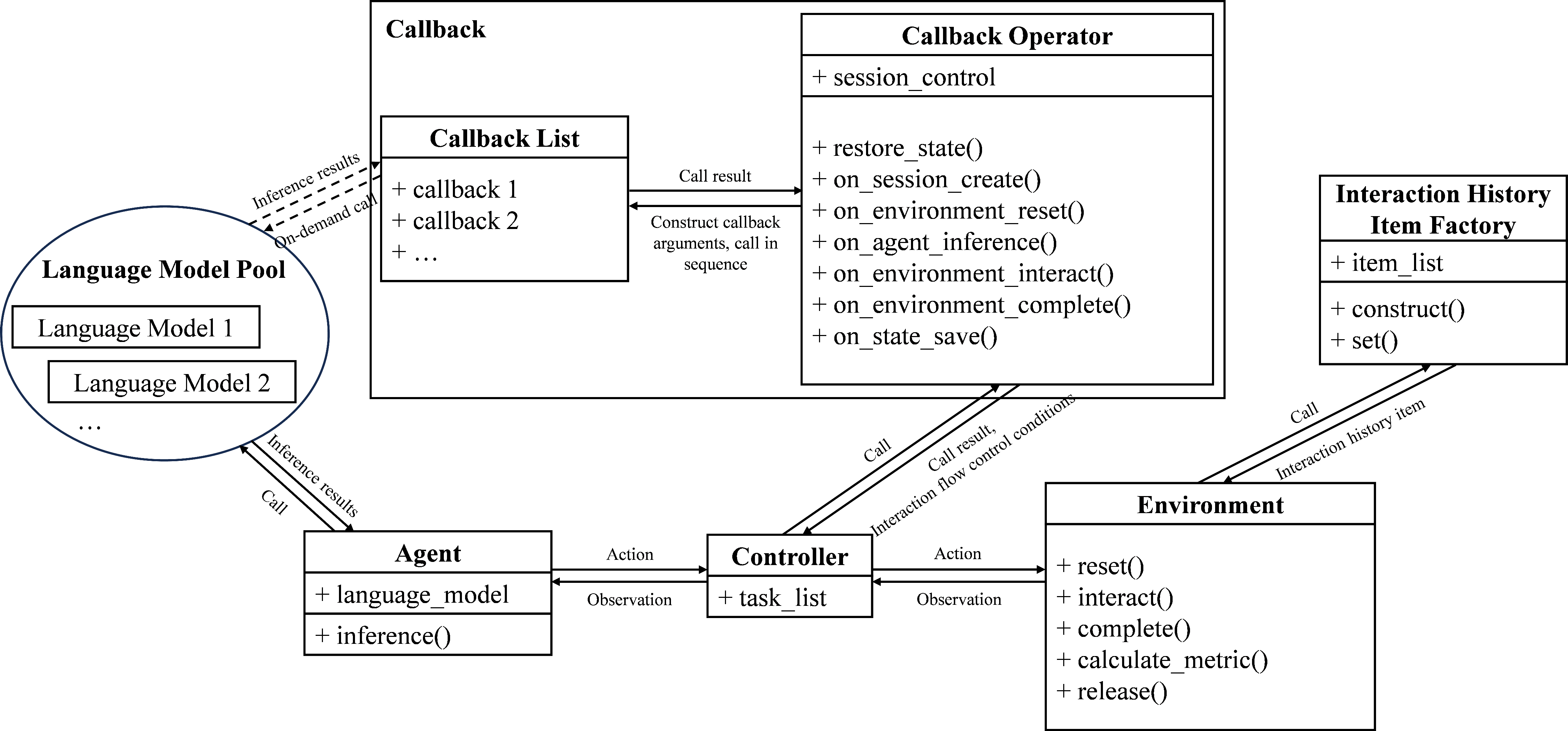
Figure 5: The evaluation architecture, showing the flow and modularity of core components.
Distributed deployment is facilitated by a plug-and-play RPC toolkit, allowing seamless transitions between development and large-scale evaluation runs.
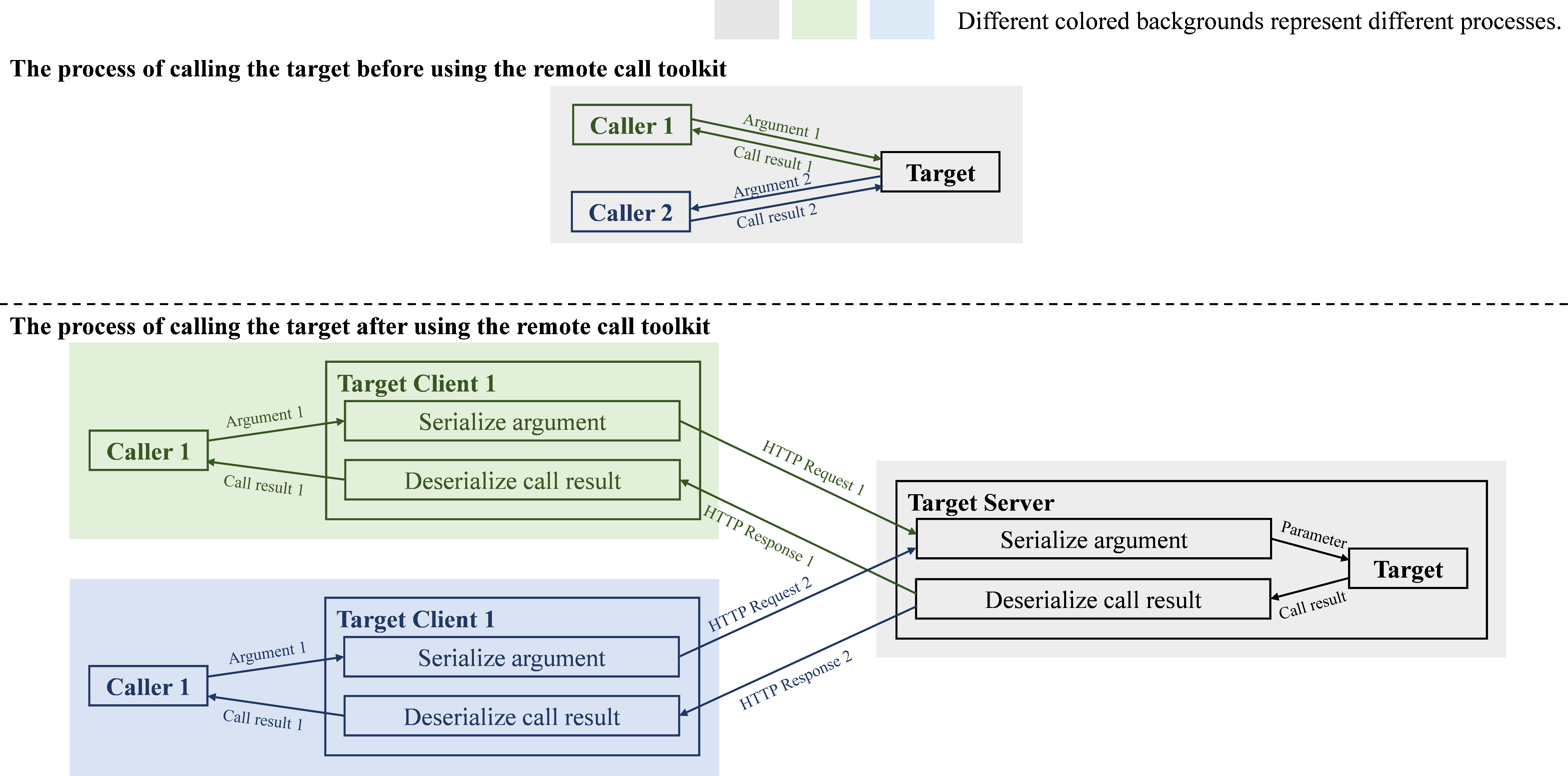
Figure 6: Schematic of the RPC toolkit implementation, central to supporting distributed and modular experimentation.
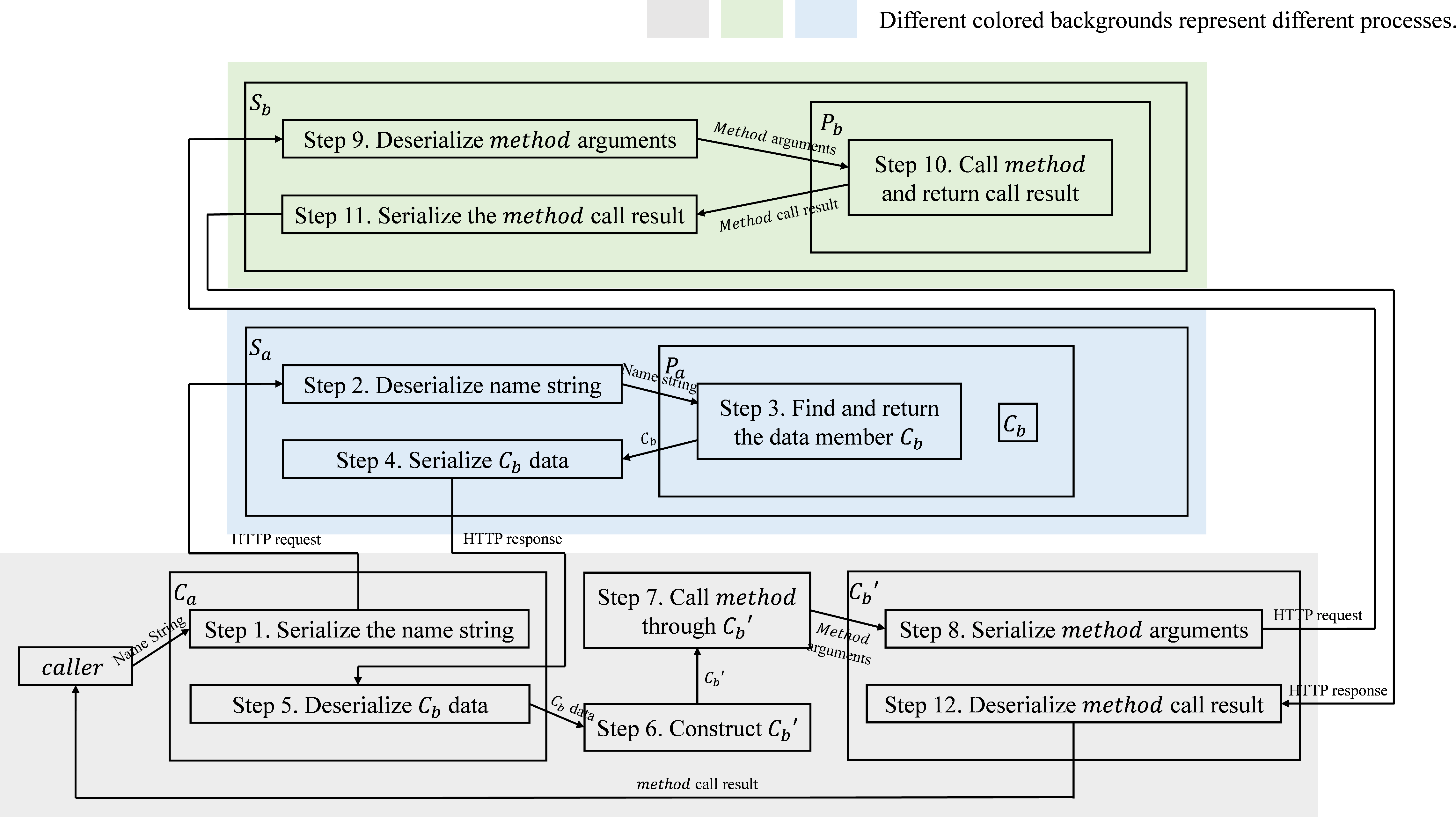
Figure 7: Example demonstrating usage and control flow of the RPC toolkit for modular remote calls.
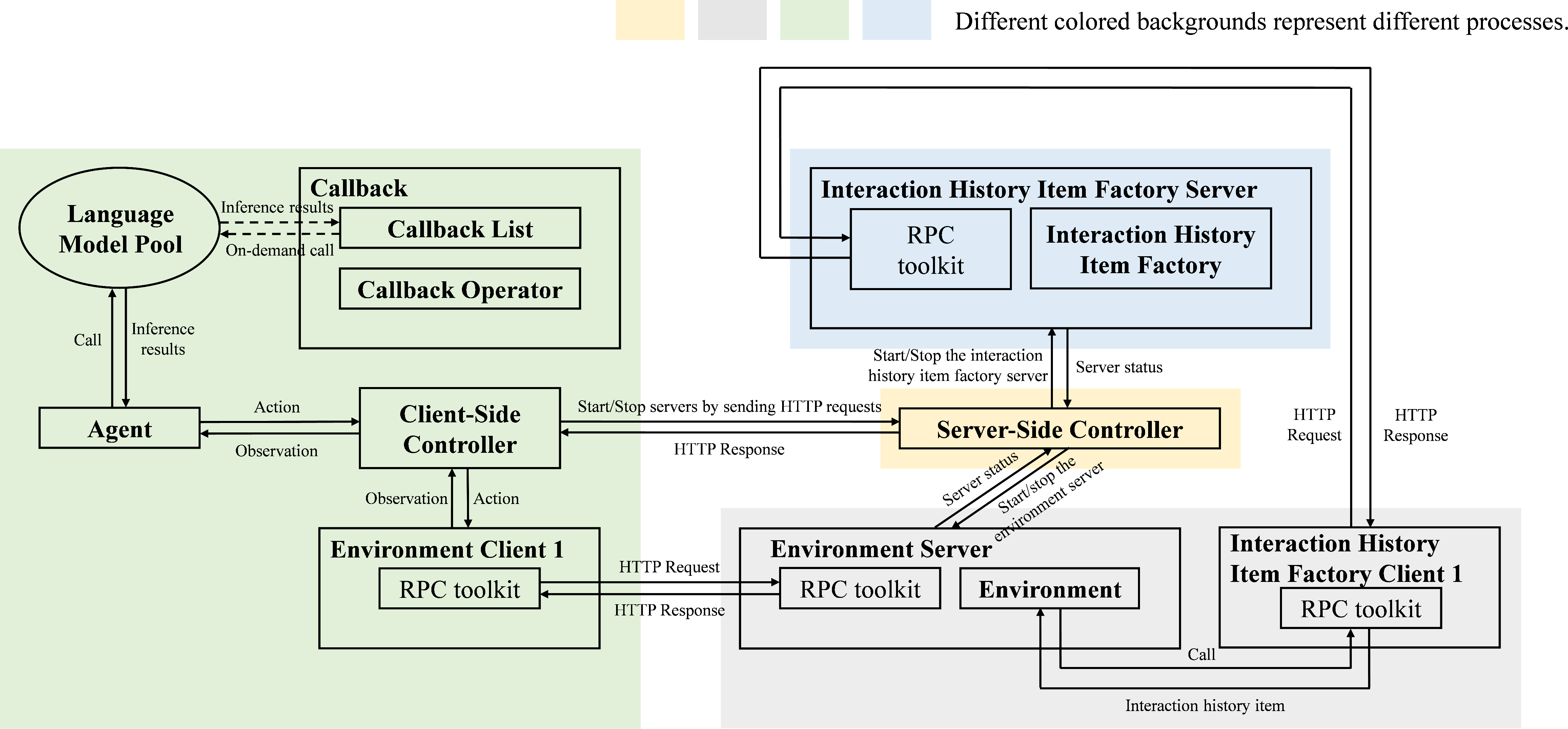
Figure 8: Distributed deployment architecture, with decoupled server and client controller components for scalable and reproducible benchmarking.
Experimental Results
Experience Replay and Memory Constraints
Comprehensive results demonstrate that experience replay generally enhances agent performance, but the impact varies considerably based on model architecture, environment, and task complexity:
- For Database tasks, incorporating up to 64 recent trajectories yields a success-rate increase from 19% to 78% with Llama-3.1-8B-Instruct.
- In OS and KG settings, the benefits plateau or degrade as replay size grows, due to context length limitations and increasing reasoning noise.
- Out-of-memory (OOM) failures frequently occur with large replay buffers—especially in KG, where longer trajectories amplify the memory footprint.
These findings illustrate significant limitations in vanilla experience replay for LLM-based agents, signaling an immediate need for memory-efficient replay and retrieval strategies.
Influence of Model Architecture
Model backbone and parameter scale directly modulate the effectiveness of continual learning mechanisms. Larger models (e.g., Llama-3.1-70B-Instruct) maintain high accuracy without exceeding memory, whereas some reasoning-optimized models (e.g., DeepSeek-R1-Distill variants) experience rapid context overflow and minimal replay benefit. The acquisition of complex, multi-step skills shows more substantial gains from replay compared to simple or near-i.i.d. tasks.
Task Difficulty and Replay Trade-offs
Replay most strongly aids challenging or compositional tasks; for easier instances, improvements are marginal. In KG, tasks with longer required trajectories exhibit diminishing returns from replay, a direct function of context window saturation and input signal-to-noise decline.
Group Self-Consistency
To mitigate replay-induced context and efficiency bottlenecks, LifelongAgentBench introduces a group self-consistency (GSC) protocol. It partitions retrieved trajectories into separate groups, aggregates their predictions via majority voting, and then integrates results to increase decision robustness and minimize context length overhead.
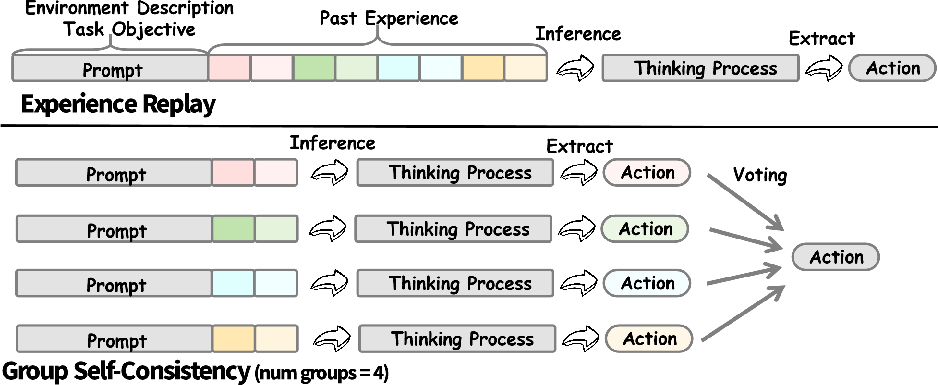
Figure 9: Group self-consistency partitions historical trajectories, reducing memory requirements and stabilizing inference via voting.
Empirically, GSC yields significant accuracy and memory savings, especially at large replay scales. It is especially effective in settings where naïve replay exacerbates context length or OOM failures.
Failure Mode Analysis
The framework provides granular diagnostics, identifying failure classes such as:
- Incorrect final submission despite correct intermediate steps (unstable reasoning/over-correction),
- Exceeding interaction limits due to poor task closure policies,
- Validation failures from instruction non-compliance,
- Context overflow from unbounded output or multi-hop reasoning.
These fine-grained analytics diagnose failure from both agent behavioral and infrastructure perspectives, enabling directed ablation studies and robust method development.
Implications and Future Directions
LifelongAgentBench sets a new standard for benchmarking LLM-based agents on continual, memory-intensive learning. The results underline several critical takeaways:
- Vanilla experience replay is insufficient for scalable memory integration in LLMs due to context explosion and diminishing marginal returns with increasing replay.
- There exists substantial heterogeneity in how model architectures absorb, retain, and transfer replay information.
- Group-based or adaptive memory aggregation (e.g., GSC) is essential for practical, scalable lifelong learning with large LMs.
- Going forward, efficient retrieval, redundant memory compression, curriculum design, and adaptive prompt construction are necessary to overcome catastrophic forgetting and achieve robust lifelong adaptation.
Extending LifelongAgentBench to multimodal and open-world environments, and integrating dynamic environment change or concept drift, are promising directions for future theoretical and practical advances in agent continual learning.
Conclusion
LifelongAgentBench is the first comprehensive, extensible, and diagnostic benchmark for evaluating LLM-based agents under lifelong learning constraints (2505.11942). The results highlight the nuanced interplay among replay strategies, task difficulty, and model capacity, and motivate the development of novel architectures and memory management algorithms to enable robust, scalable, and truly lifelong agent learning.