- The paper presents a novel benchmark that systematically evaluates continual skill generation methods in real-world tasks.
- It compares four paradigms—one-shot, self feedback, teacher feedback, and skill creator—across diverse sub-domains and multiple LLMs.
- Empirical results highlight method-specific trade-offs, stressing the role of external feedback and optimal model scaling for robust skill acquisition.
SkillLearnBench: Benchmarking Continual Learning Methods for Agent Skill Generation on Real-World Tasks
Motivation and Scope
Structured, reusable skills have become central to LLM agent systems, facilitating robust task completion in specialized domains by encoding procedures, domain-specific workflows, and tool invocation patterns. As the skill ecosystem grows, the problem of continual skill acquisition—enabling agents to autonomously generate, store, and reuse skills from ongoing experience—emerges as a primary frontier in agent capability scaling. However, robust evaluation frameworks for skill generation and continual learning remain lacking. "SkillLearnBench: Benchmarking Continual Learning Methods for Agent Skill Generation on Real-World Tasks" (2604.20087) addresses this gap by introducing SkillLearnBench, the first principled benchmark for evaluating continual skill learning techniques through a multi-centric approach grounded in real-world agent skill taxonomies.
Benchmark Design
SkillLearnBench comprises 20 tasks across 15 sub-domains (spanning software engineering, productivity tools, information retrieval, data analytics, creative content, utilities, and more), all selected from actual skill usage patterns in agent communities. Each task is constructed to be skill-dependent, enforced through deterministic verifiers and multi-instance testing: the agent cannot reliably solve the task without skills but achieves high success with human-authored skills that encode the correct approach. Human-authored skills are curated and refined to eliminate redundant, non-essential, or unintuitive patterns, maximizing invocability and actionable guidance.
SkillLearnBench employs a three-level evaluation protocol:
- Level 1 (Skill Quality): Assesses generated skill documents for coverage (oracle key point overlap), executability (completeness, determinism, consistency, usability), and safety (six risk dimensions).
- Level 2 (Execution Trajectory): Evaluates whether the agent's solve trajectory aligns with the oracle path (trajectory keypoint recall, execution order, completeness) and skill usage rate.
- Level 3 (Task Outcome): Measures pass/fail accuracy via deterministic verifiers and solving token cost (resource efficiency).
Continual Learning Methods
Four major skill generation strategies are compared, reflecting diverse paradigms (Figure 1):
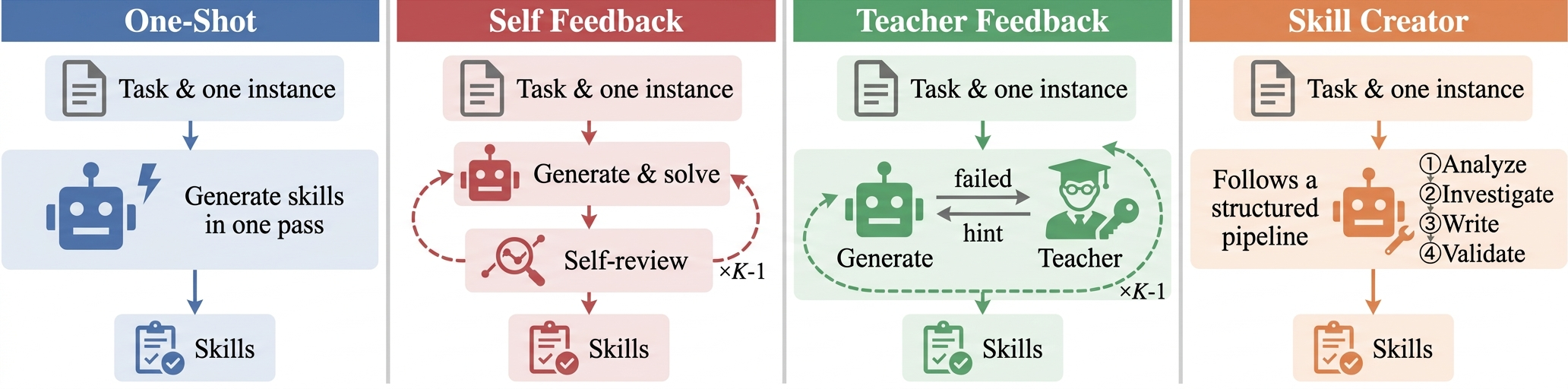
Figure 1: Workflows of four continual learning methods through skill generation.
- One-Shot: Generates skills in a single pass from task description (no iterative refinement).
- Self Feedback: Agent self-revises skills based on its own execution trajectory.
- Teacher Feedback: Iterative skill improvement guided by external teacher feedback, without access to ground-truth skill.
- Skill Creator: Pipeline-based, structured skill generation following a prescriptive format.
These methods are tested across six high-capability LLMs (Claude Haiku/Sonnet/Opus, Gemini Flash Lite/Flash/Pro), allowing analysis of how method effectiveness interacts with backbone model capacity.
Empirical Results
Consistently, all continual learning methods surpass the no-skill baseline in both accuracy and efficiency, but none close the gap to human-authored skill performance. Even the top continual learning method only covers ∼45% of the gap between no-skill and human-authored solutions (Level 3), and scaling to stronger LLMs does not robustly improve skill quality or task accuracy—model capacity interacts strongly with method effectiveness but does not guarantee better results.
Skill learning efficacy is highly task-dependent (Figure 2). Tasks with structured, reusable workflows (e.g., productivity tools, software engineering) show substantial accuracy gains from skill generation; open-ended or instance-specific tasks often exhibit skill-induced regression, as rigid procedural skills constrain agent adaptability.
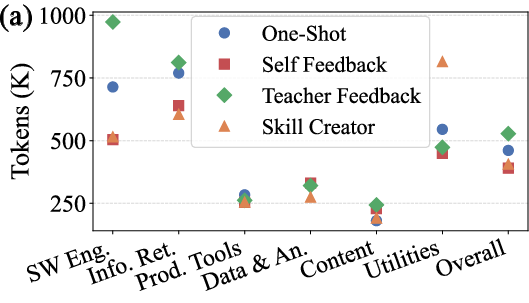
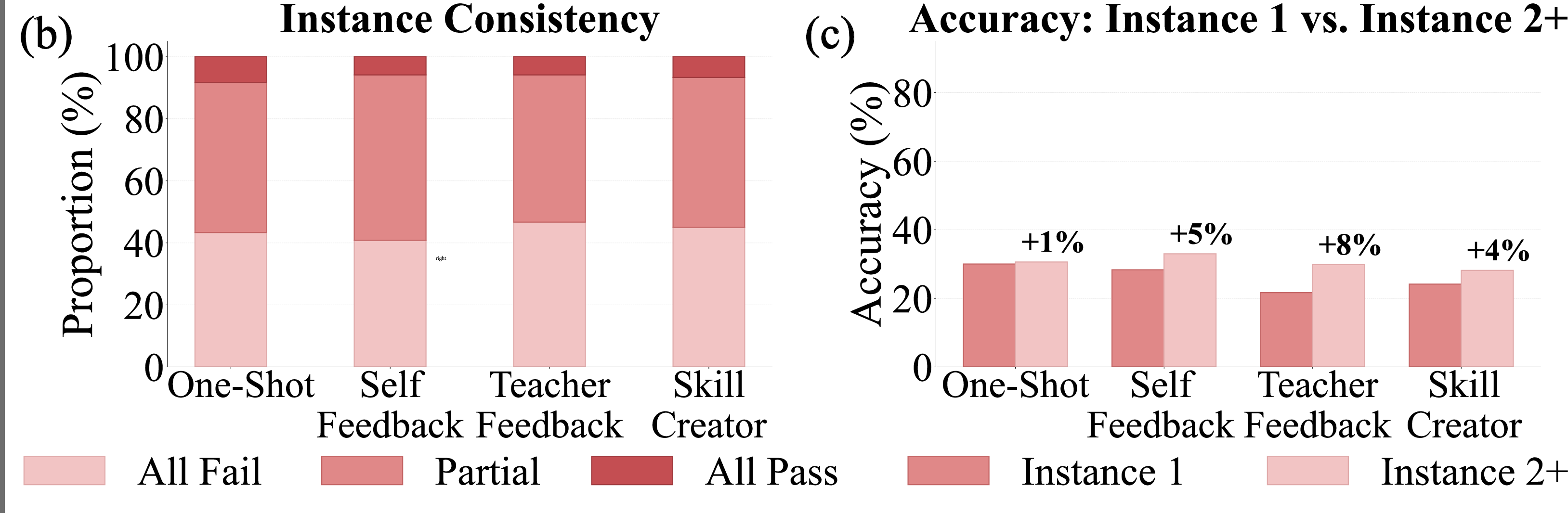
Figure 2: (a) Solving token cost by task category. (b) Proportion of data where skills pass all, partial, or no instances. (c) Accuracy on the seed instance versus held-out instances 2+.
Task outcome metrics (accuracy, token cost) and trajectory metrics (alignment, usage rate) reveal further regime distinctions; most generated skills are only partially effective and capture incomplete task logic. Skill usage rate is a critical bottleneck: generated skills are frequently ignored by agents unless their guidance aligns tightly with actionable task bottlenecks.
Method profiles show distinctive behavioral modulations (Figure 3):
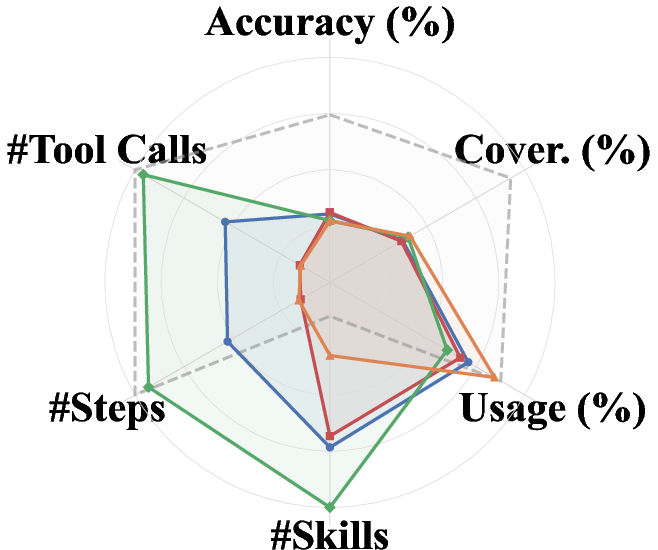
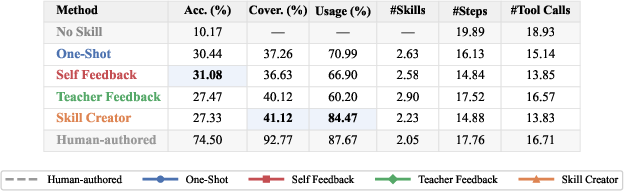
Figure 3: Method profiles across accuracy, coverage, skill usage rate, skills per task, steps per instance, and tool calls per instance.
- Self Feedback yields more focused, compact skill sets and steers agents toward shorter solve paths (better efficiency), but risks recursive drift as revision iterations increase without external input.
- Teacher Feedback increases skill coverage and diversity, but leads to lower adoption and higher context inflation due to verbose skills.
- Skill Creator drives frequent invocation but does not guarantee procedural correctness, indicating that structural formatting alone is insufficient for robust task logic acquisition.
Skill Evolution and Impact of External Feedback
Longitudinal analysis of iterative rounds (Figure 4) shows divergence in skill improvement dynamics:
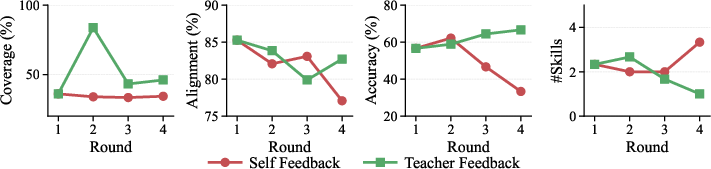
Figure 4: Skill evolution across learning rounds for Self Feedback and Teacher Feedback on Productivity Tools (Claude Sonnet 4.6).
- Self Feedback stagnates or degrades as agent self-revises without new information—coverage stays flat, alignment declines, accuracy drops after initial boost.
- Teacher Feedback, by contrast, leverages external signals to restructure skill content and compound gains across rounds; coverage, alignment, and accuracy improve steadily.
This underscores the necessity of substantive feedback signals for effective skill refinement; self-feedback mechanisms induce recursive drift and cannot reliably address coverage gaps.
Model Scaling
Scaling generation LLMs, rather than uniformly improving skill quality, introduces prescriptiveness and rigidity. Larger models are prone to hardcoding parameters, library selection, and field names, achieving high coverage but often failing when instance variation demands flexible procedural logic (Figure 5).
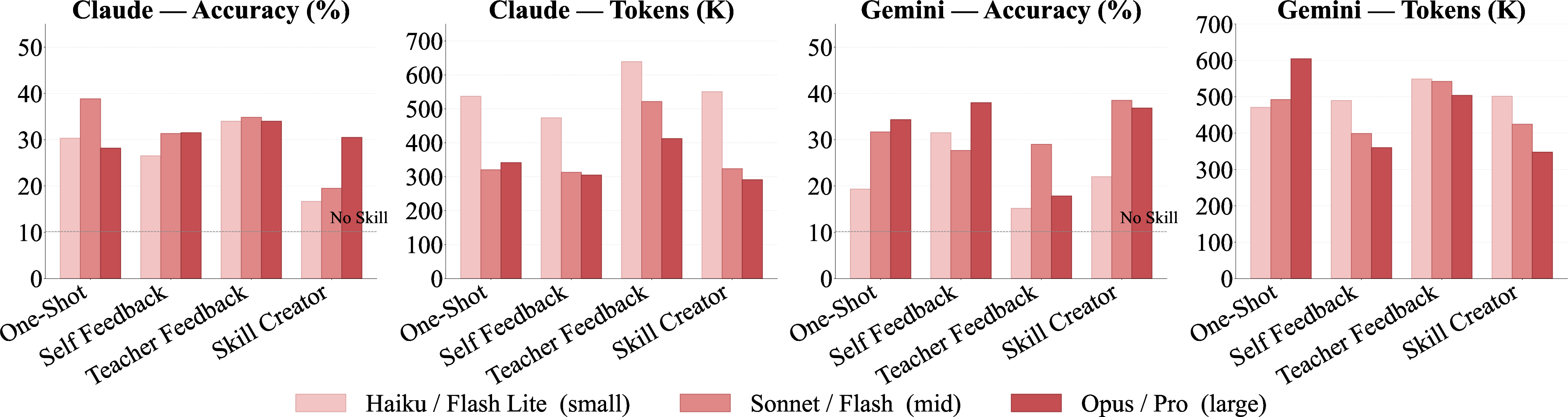
Figure 5: Task accuracy and solving token cost across model scales for each method.
Mid-tier models frequently strike a better balance between specificity and generalizability, producing skills that can be reliably adopted by solvers across varied instances.
Practical and Theoretical Implications
SkillLearnBench reveals substantial challenges for continual skill learning:
- Autonomous skill generation methods must prioritize encoding actionable, reusable task logic that can be adopted by solvers, not merely specification richness or structural diversity.
- Current methods lack robust mechanisms to capture diverse task-specific workflows and to ensure skill invocation aligns with agent solve trajectories.
- External feedback is indispensable for genuine improvement in iterative learning; self-feedback is insufficient to resolve coverage and generalization gaps.
- Scaling LLMs does not provide a panacea, as larger models often overfit to task specifics and induce rigidity.
The benchmark’s three-level evaluation framework enables diagnosis across the skill generation pipeline, highlighting where failures originate (skill specification, agent execution, or final outcome).
Future Directions
Advancing continual skill learning will require methods that:
- Integrate contextual task understanding to ground skill generation in procedural bottlenecks.
- Incorporate reinforcement signals or frequent external critique to guide iterative refinement.
- Emphasize dynamic adaptation and abstraction, avoiding both over-prescriptiveness and excessive generality.
- Foster structurally rich skill artifacts (including code, scripts, and subagents) matching the diversity of human-authored skills.
- Develop principled approaches for skill adoption and invocation, ensuring generated skills are actually leveraged within agent solve trajectories.
These directions will be critical for scalable and robust agent systems, facilitating lifelong adaptability across real-world domains.
Conclusion
SkillLearnBench establishes the first comprehensive benchmark for continual skill learning in LLM agents, systematically evaluating the capability of skill generation methods to bridge the gap between episodic task experience and reusable procedural knowledge. The layered evaluation framework and empirical analysis reveal persistent challenges: task-dependent utility, skill adoption bottlenecks, drift without feedback, and the non-monotonic impact of model scaling. The work sets a rigorous foundation for future research in automatic skill acquisition and agent continual learning, with robust, reproducible protocols and open-source data enabling broad community contributions to advancing agent skill ecosystems.