- The paper introduces UA-Bench and demonstrates that current LLMs struggle to accurately distinguish between data uncertainty and model uncertainty.
- It finds that while most models robustly detect data uncertainty, model uncertainty remains significantly under-addressed, with many scoring below 30% on difficult tasks.
- The reinforcement learning intervention notably improves MU-F1 scores, highlighting gaps in LLM self-awareness crucial for safe and reliable deployment.
Explicit Uncertainty Attribution in LLMs: Analysis of UA-Bench and Reinforcement Learning for Self-Awareness
Introduction
This paper presents a rigorous examination of explicit uncertainty attribution in LLMs, emphasizing the distinction between data uncertainty (ambiguity or lack of information in the input) and model uncertainty (task solvable in principle but beyond the model's capability). The authors introduce UA-Bench, a benchmark specifically designed to evaluate whether LLMs can abstain from answering not just via generic refusal but through explicit, accurate meta-cognition about the source of their uncertainty. Evaluations of 18 competitive LLMs reveal that uncertainty attribution remains an unresolved challenge, especially for model uncertainty, prompting a reinforcement learning (RL) approach targeting this deficit.
UA-Bench: A Benchmark for Fine-Grained Uncertainty Attribution
The central critique of previous abstention and refusal benchmarks—the overuse of undifferentiated “I don't know” refusals—drives the construction of UA-Bench. This benchmark demands models to output a designated uncertainty token indicating why an answer cannot be produced, with explicit categories:
- Data Uncertain: The question is ambiguous or underspecified; no unique answer exists.
- Model Uncertain: The question has a unique, well-defined answer but is beyond the model's capability.
UA-Bench aggregates over 3,500 instances spanning knowledge- and reasoning-intensive domains (GAIA, MuSiQue, SelfAware, OlympiadBench-math, GSM8K-MiP, MATH-MiP).
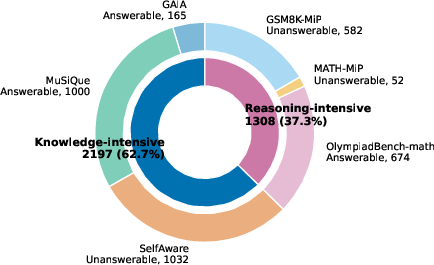
Figure 2: Composition of UA-Bench by category shows diverse coverage of both answerable and unanswerable cases across knowledge- and reasoning-intensive domains.
This composition ensures coverage of both types of uncertainty: the ground-truth for data uncertainty is defined statically, while model uncertainty is model-specific and collectively assessed from observed failures on questions with known answers.
Empirical Evaluation: Failure to Attribute Uncertainty
A systematic evaluation of 18 LLMs—including Qwen3, LLaMA-4 Maverick, GPT-4o, Claude Sonnet 4, GPT-5 mini, Gemini 3—demonstrates that even state-of-the-art systems predominantly fail on reliable uncertainty source discrimination.
Key findings include:
- Data uncertainty (DU-F1) is robustly detected by most models, especially large, closed-source LLMs (e.g., DU-F1 exceeding 75%); however,
- Model uncertainty (MU-F1) consistently lags, with most open-source and many closed-source models scoring below 30% on non-trivial tasks.
- High answer accuracy does not entail robust uncertainty attribution: for example, Qwen3-4B-Instruct achieves 72.3% accuracy on reasoning-intensive tasks but only 23.3% MU-F1.
This demonstrates that systems able to “know what they know” are often unable to recognize and articulate their own boundaries of ignorance when they fail, undermining reliability in safety-critical or agentic settings.
Prompting and Intervention Strategies
The effect of prompting strategies (Direct Answer, Abstention Only, and Uncertainty Attribution) is carefully controlled. Results show that requiring uncertainty source identification does not further degrade answer accuracy compared to standard refusal prompting, indicating the problem is not simply sensitivity to prompt but a genuine limitation in meta-cognitive behavior.
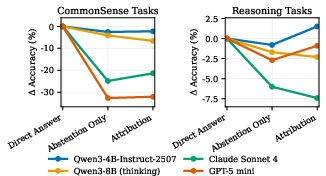
Figure 1: Accuracy under various prompting strategies remains stable, with uncertainty attribution requirement incurring no additional performance loss over standard refusal.
Further, when decomposing coarse refusal rates into data- versus model-uncertain attributions, overall abstention boundaries remain unchanged; models’ refusals are simply being relabeled, not overproduced.
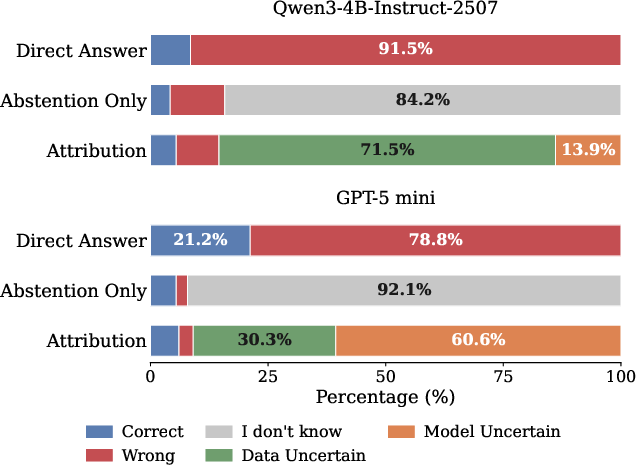
Figure 3: On the GAIA dataset, the total refusal rate is preserved, but with explicit attribution, “I don’t know” refusals are subdivided into data and model uncertainty labels without shifting decision thresholds.
Failure Mode Analysis
Manual error analyses identify two characteristic misattribution patterns:
- Misdirecting Data to Model Uncertainty: When faced with missing information, models often blame their own limitations rather than flagging ambiguity.
- Misdirecting Model to Data Uncertainty: When lacking knowledge or capability, models frequently hallucinate flaws in the question instead of admitting incapacity.
These behaviors indicate a persistent lack of principled, faithful meta-reasoning about uncertainty, with direct implications for alignment, tool-invocation pipelines, and safe deployment.
Reinforcement Learning Intervention
To address these deficits, the paper proposes a lightweight RL pipeline, building upon recent RLVR techniques, to explicitly reward correct uncertainty source recognition. Synthetic data is constructed by transforming mathematical problems into information-insufficient (data-uncertain) and extremely difficult (model-uncertain) variants. The RL reward function is carefully designed: +1 for correct answer or uncertainty attribution, 0 for honest abstention despite an incorrect answer, and -1 for hallucination.
Quantitatively, RL training on Qwen3-4B-Instruct-2507 and Qwen3-8B (in thinking mode) yields substantial improvements:
- Reasoning-Intensive Tasks (Qwen3-4B-Instruct-2507): MU-F1 improves from 23.3% to 53.5%; overall AVG-F1 rises to 61.0%.
- Knowledge-Intensive Tasks (Qwen3-8B): MU-F1 increases from 35.6% to 54.1%; AVG-F1 reaches 62.7%.
Qualitative inspection confirms that RL shifts models from deflecting blame to data toward honest admission of limitation, and vice versa. However, absolute MU-F1 and attribution reliability remain well below saturation; robust meta-cognition remains elusive.
Implications and Future Work
This study demonstrates that fine-grained uncertainty attribution is inadequately developed in current LLMs, even as answer accuracy and coarse refusal are strong. The UA-Bench protocol introduces a more challenging probe for true meta-cognitive competence, setting a new performance bar for “honest” and actionable abstention. Accurate uncertainty attribution is critical for:
- Agentic decision-making: triggering clarification (data uncertainty) versus tool invocation (model uncertainty)
- Trustworthy deployment in high-risk domains where reasoning about limitations is essential
The RL approach, while effective in improving attribution over standard supervised or confidence-thresholding schemes, exposes the limitations of current architectures and reward designs. Synthetic mathematical rewrites provide controlled evaluation, but generalization to richer, real-world ambiguities remains non-trivial.
Future research directions should address joint uncertainty states (data + model), more complex attribution taxonomies, robustness to adversarial queries, and transfer to dialogue, tool use, and real-world scenarios.
Conclusion
The paper provides a comprehensive and technically robust protocol for evaluating and training LLMs in explicit, actionable self-awareness regarding their uncertainty. The gap between answer accuracy and principled abstention is thoroughly documented, and RL-based interventions are shown to yield non-trivial but unsaturated gains. UA-Bench offers the community a challenging new standard for introspective LLM behavior, and the reinforcement learning pipeline demonstrates one promising avenue for model improvement (2604.17293).

