ShadowPEFT: Shadow Network for Parameter-Efficient Fine-Tuning
Abstract: Parameter-efficient fine-tuning (PEFT) reduces the training cost of full-parameter fine-tuning for LLMs by training only a small set of task-specific parameters while freezing the pretrained backbone. However, existing approaches, such as Low-Rank Adaptation (LoRA), achieve adaptation by inserting independent low-rank perturbations directly to individual weights, resulting in a local parameterization of adaptation. We propose ShadowPEFT, a centralized PEFT framework that instead performs layer-level refinement through a depth-shared shadow module. At each transformer layer, ShadowPEFT maintains a parallel shadow state and evolves it repeatedly for progressively richer hidden states. This design shifts adaptation from distributed weight-space perturbations to a shared layer-space refinement process. Since the shadow module is decoupled from the backbone, it can be reused across depth, independently pretrained, and optionally deployed in a detached mode, benefiting edge computing scenarios. Experiments on generation and understanding benchmarks show that ShadowPEFT matches or outperforms LoRA and DoRA under comparable trainable-parameter budgets. Additional analyses on shadow pretraining, cross-dataset transfer, parameter scaling, inference latency, and system-level evaluation suggest that centralized layer-space adaptation is a competitive and flexible alternative to conventional low-rank PEFT.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
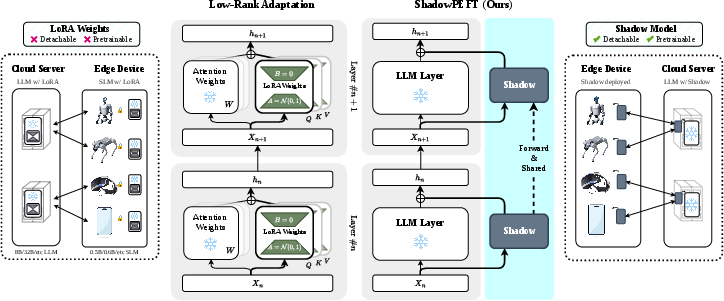
This paper introduces a new way to “fine-tune” big LLMs so they learn new tasks without needing to retrain all their many weights. The new method is called ShadowPEFT. Instead of adding many tiny fixes scattered throughout the model (like older methods do), ShadowPEFT adds one small “shadow” helper network that travels alongside the main model and gently guides it at every step. This makes training cheaper, keeps the main model unchanged, and can even let the helper run by itself on small devices.
What questions the researchers asked
The paper focuses on a few simple questions:
- Can we adapt (fine-tune) LLMs using fewer new parameters and less cost?
- Can we replace many scattered fixes (used by methods like LoRA) with one shared, smarter helper that works across the whole model?
- Can this helper be reused, detached, or even run alone on small devices?
- Will this approach match or beat popular methods (like LoRA and DoRA) on real tasks?
How the method works, in everyday terms
First, some quick definitions in simple language:
- Fine-tuning: Teaching a pre-trained model a new skill (like answering medical questions or solving math problems) using a smaller amount of training, without changing everything inside it.
- Parameter-efficient fine-tuning (PEFT): Fine-tuning that adds only a small number of new “knobs” or “notes” to the model so it learns the new task cheaply.
Older PEFT method (LoRA), in an analogy:
- Think of a long book (the model) with many chapters (layers). LoRA adds tiny sticky notes to many pages, each with small instructions. These notes are separate and don’t talk to each other. It works, but you end up managing lots of scattered notes.
What’s new with ShadowPEFT:
- Instead of sticky notes everywhere, ShadowPEFT adds a single small “study guide” (the shadow network) that walks through each chapter with the book. At each chapter (layer), the guide checks how the book’s current understanding compares to its own and suggests a small, focused correction.
- This shadow guide carries a “notebook” (its state) from chapter to chapter, updating it along the way. That means the advice stays consistent and improves as the reading goes deeper.
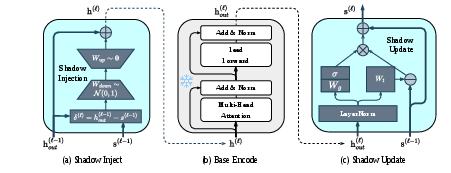
The three steps at every layer (chapter):
- Shadow injection: Compare what the main model thinks now with what the shadow thinks. Turn that difference into a small, useful nudge and add it to the main model’s current activations. Think: “Here’s a small course correction based on our shared plan.”
- Base encoding: The main (frozen) model reads the next part using that slightly improved input.
- Shadow update: The shadow updates its own notebook using the new information it just saw, deciding (with a “gate” that’s like a volume knob) how much to keep from before vs. how much to change now.
Why this is efficient and flexible:
- The main big model’s original weights remain frozen (unchanged). You only train the small, shared shadow pieces.
- The shadow is shared across all layers, so you don’t have to add separate modules all over the place.
- The shadow can be “detached” and run by itself for simple tasks on a phone or robot, which is great for edge computing (running on small devices without relying on the cloud).
- You can even initialize the shadow from a smaller pre-trained model, then plug it into a larger model—so the helper’s skills transfer across sizes.
What the experiments found (results that matter)
Across several well-known tests—reasoning (GSM8K), question answering (SQuAD v2), general knowledge (MMLU), and text classification (Amazon reviews, 20 Newsgroups)—ShadowPEFT:
- Matched or outperformed popular methods (LoRA and DoRA) while using a similar or slightly smaller number of trainable parameters.
- Kept inference speed close to LoRA (about 4–6% extra time), and much faster than DoRA.
- Generalized well: When trained on one dataset, it transferred better to others, often scoring highest out-of-distribution.
- Scaled nicely: Increasing the shadow’s size usually helped, without the “too-big hurts” problem seen in some low-rank methods.
- Benefited from pretraining: A shadow that’s pre-trained (even a small one) did better than a randomly initialized one. In fact, a pre-trained shadow could run by itself (detached mode) and still do fairly well for lightweight tasks.
- Showed real-world promise: In a robot dog intent-understanding demo, the detached shadow handled routine commands locally (fast) and flagged harder ones for the full cloud model—achieving both high accuracy and lower latency.
Why this is important
- More efficient learning: It gives a new, centralized way to adapt large models without touching their core, which saves time and memory.
- Better coordination: Instead of many disconnected tweaks, the shadow provides one consistent “coach” guiding each layer, which can improve stability, generalization, and reasoning.
- Practical deployment: Because the shadow can be detached, small devices can handle simple tasks on their own, reducing costs and delays from sending everything to the cloud.
- Reuse across scales: A smaller pre-trained helper can be plugged into a bigger model, sharing its learned skills—a step toward modular, mix-and-match AI systems.
Quick takeaway
ShadowPEFT replaces lots of scattered, layer-by-layer tweaks with one small, smart helper that walks through the whole model, providing consistent guidance. It’s efficient, flexible (can attach or detach), and often performs as well as or better than popular alternatives—all while keeping the main model frozen. This makes it a promising approach for both research and real-world applications, from better reasoning to fast, edge-friendly AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each item suggests concrete directions for future work.
- Theoretical foundations: No formal analysis of why a depth-shared shadow state should improve expressivity or stability versus per-layer low-rank updates; convergence properties, identifiability, and failure modes of the gated shadow update remain unstudied.
- Degree of parameter sharing: The shadow is “shared across depth,” yet the injection projections are layer-dependent; the trade-off between full sharing vs. per-layer parameters is not analyzed or ablated.
- Placement within transformer blocks: The paper does not examine where to inject/update (e.g., pre/post-attention, MLP, residual paths) or layer subsets to target; lack of ablations on placement and sparsity patterns.
- Hyperparameter sensitivity: No study of injection rank r, residual scaling α, dropout rate, gate function choices, normalization strategies, or the auxiliary shadow-loss weight λ; unclear robustness to these settings.
- Initialization strategies: Pretraining and a Moore–Penrose pseudo-inverse initialization are mentioned but not systematically compared to other inits (e.g., Xavier, Kaiming, distillation-based); mechanisms behind the gains remain unclear.
- Training efficiency and resource use: Only inference latency is reported; training-time throughput, GPU memory/activation footprint, and optimization stability vs. LoRA/DoRA are not measured.
- KV-cache and memory overhead at inference: The impact of maintaining and evolving a parallel shadow state on KV cache size, activation reuse, and memory-bound scenarios is unreported.
- Parallelization claim: The method claims the shadow forward “runs in parallel,” but the injection and update depend on prior layer activations; concrete scheduling, pipeline parallelism, and kernel fusion strategies are unspecified and unbenchmarked.
- Quantization compatibility: Interplay with 4-bit/8-bit base models (e.g., QLoRA) and mixed-precision regimes is unexplored for both training and inference.
- Baseline coverage: Comparisons are limited to LoRA/DoRA; adapters (Houlsby, Compacter), IA3, prefix/prompt tuning, shared adapters, and recent PEFT variants are not included under matched budgets.
- Fairness of comparisons: LoRA/DoRA ranks/placements and hyperparameters are fixed and may not be tuned optimally for each backbone/task; the “comparable” budget differs slightly across methods and is not stress-tested for sensitivity.
- Benchmark breadth: Evaluation covers five NLP tasks; missing long-context tasks, code generation, multi-turn instruction following, multilingual evaluation (despite Chinese data in shadow pretraining), and multi-modal tasks.
- Scale limits: Experiments stop at 8B backbones and 0.5B shadows; effects on larger (13B–70B+) models, deeper networks, and larger shadows (or smaller/mobile shadows) remain unknown.
- Cross-backbone portability: The claim that shadows are decoupled is not tested across model families (e.g., Qwen shadow on LLaMA/Mistral) or architectures (encoder–decoder models like T5).
- Shadow-only routing policy: The [REMOTE] decision mechanism for detached mode is ad hoc; no training/thresholding strategy, false-positive/false-negative analysis, or impact on user experience is reported.
- Composition of multiple shadows: How to combine or switch among task-specific shadows (conflict resolution, routing, or mixture-of-shadows) is not addressed.
- Catastrophic forgetting and retention: Whether centralized adaptation preserves general capabilities and safety behaviors better/worse than LoRA over long fine-tuning or multi-task settings is not measured.
- Robustness and safety: No systematic evaluation of adversarial robustness, calibration, hallucination rates, or safety alignment; robot case study is anecdotal with limited, curated prompts.
- OOD generalization scope: OOD results are restricted to three generation tasks with 2-shot demos; broader domain shifts and cross-lingual transfer remain untested.
- Statistical reporting: Main results average over five runs but omit variance/CI; other analyses (generalization, scaling, latency) lack uncertainty estimates and significance testing.
- Detachable shadow as a standalone model: Detached performance is reported, but model size vs. quality trade-offs, latency/memory on real edge devices, and energy consumption are not provided.
- Shadow–backbone mismatch: How architectural/dimensional mismatches (e.g., different hidden sizes, attention heads) affect effectiveness and stability is not explored beyond the Qwen examples.
- Alternative objectives: Beyond cross-entropy, other training objectives (e.g., KD from the backbone, consistency, contrastive or alignment losses) for the shadow are not investigated.
- Failure analyses: No qualitative or quantitative breakdown of where ShadowPEFT underperforms (by category, reasoning type, or input length) to guide targeted improvements.
- Long-context behavior: The effect of evolving a shadow state across many layers/tokens on very long sequences (state drift, vanishing/exploding signals) is unexamined.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases enabled by ShadowPEFT’s centralized, detachable “shadow” module, minimal latency overhead (≈4–6% vs. LoRA), and competitive accuracy. Each item lists sectors, potential tools/products/workflows, and feasibility notes.
- Edge–cloud split inference for robotics and IoT
- Sectors: robotics, smart home/IoT, manufacturing
- What: Run the detached shadow locally for routine skills/intents; auto-escalate complex/open-domain queries to the cloud-attached backbone (e.g., using a tag like [REMOTE] as in the paper’s robot-dog demo).
- Tools/workflows: “Shadow Router” for on-device gating; local skill library + cloud fallback; telemetry for escalation rates and latency.
- Assumptions/dependencies: Shadow must be (pre)trained for sufficient standalone quality; reliable on-device resource budget; robust escalation logic.
- On-device assistants with privacy-first defaults
- Sectors: mobile/edge computing, consumer electronics, automotive
- What: Ship a shadow-only assistant for offline commands (alarms, notes, summaries) with cloud fallback for harder tasks; reduced cloud calls cut cost and data exposure.
- Tools/workflows: Mobile SDK with “shadow sidecar”; escalation policies; privacy dashboards.
- Assumptions/dependencies: Memory/compute fit on target hardware; evaluation to enforce no sensitive data leaves device unless escalated.
- Modular enterprise fine-tuning and rapid rollback
- Sectors: software/SaaS, finance, healthcare, e-commerce
- What: Treat the shadow as a versioned, attachable adapter that can be hot-swapped, A/B tested, and rolled back without touching backbone weights.
- Tools/workflows: “Shadow Registry” for versioning; feature flags; canary deployments; per-tenant shadow loading on a shared frozen backbone.
- Assumptions/dependencies: MLOps integration; policy/contract clarity on mixing model weights (IP/licensing).
- Multi-tenant serving with one backbone, many shadows
- Sectors: LLM platform providers, internal ML platforms
- What: Serve a single frozen model with tenant- or task-specific shadows to reduce memory duplication and simplify updates.
- Tools/workflows: Session-scoped shadow loading/unloading; caching; cost accounting per shadow.
- Assumptions/dependencies: Scheduler support for dynamic per-request modules; memory isolation; throughput validation under load.
- Cross-scale adaptation (small-model shadow for big-model backbone)
- Sectors: model vendors, research labs, integrators
- What: Initialize the shadow from a smaller pretrained model (e.g., 0.5B) and attach it to a larger backbone (e.g., 8B) for reusable, cross-scale adaptation.
- Tools/workflows: “Shadow Pretrainer” to prepare compact shadows; shared catalogs of domain-specific shadows.
- Assumptions/dependencies: Gains depend on shadow pretraining quality; inter-family compatibility may require tuning.
- Latency-aware task routing in agents
- Sectors: customer support, RPA, developer tooling
- What: Use the shadow to quickly classify/route requests (e.g., triage, tool selection), invoking the full backbone only when needed.
- Tools/workflows: Shadow-based router; latency/accuracy SLAs; tool-use policies.
- Assumptions/dependencies: Shadow must be reliable as a router; careful evaluation to avoid misrouting critical tasks.
- Education personalization on shared devices
- Sectors: education, edtech platforms
- What: Load curriculum- or institution-specific shadows on school hardware; run offline practice or Q&A; escalate open-ended tasks to the backbone.
- Tools/workflows: Per-class/course shadows; assignment-aligned evaluation; parental/teacher controls.
- Assumptions/dependencies: Content alignment data; device fleet management; safeguarding policies.
- Safety and guardrails as a detachable pre-filter
- Sectors: online platforms, regulated industries
- What: Run a detached shadow as a lightweight safety/maturity gate (policy compliance, PII screens) before cloud escalation or high-capacity reasoning.
- Tools/workflows: Policy-tuned shadows (e.g., AI Act/sectoral compliance); incident logging; continuous red-teaming.
- Assumptions/dependencies: High-quality policy-tuned pretraining; periodic audits; clear escalation paths.
- Reproducible PEFT research and benchmarking
- Sectors: academia, open-source communities, model hubs
- What: Share task- or dataset-specific shadows as portable artifacts; reproduce results by attaching the same shadow to a known backbone.
- Tools/workflows: “ShadowBench” leaderboards; standardized metadata (backbone version, training data, parameter budget).
- Assumptions/dependencies: Agreement on packaging formats; licensing for redistributing shadows.
- Cost-optimized inference in contact centers and analytics
- Sectors: BPO/contact centers, BI/analytics
- What: Shadow-only mode handles repetitive requests (FAQs, routing); complex cases escalate to full model, lowering cloud costs.
- Tools/workflows: Routing dashboards; per-skill shadows; ROI monitoring on escalate rates.
- Assumptions/dependencies: Call-level evaluation; workforce integration (handoff rules).
Long-Term Applications
These opportunities likely require additional research, scaling, or ecosystem development (e.g., broader model-family support, standardization, or new hardware).
- Federated or continual shadow pretraining across sites
- Sectors: healthcare, finance, public sector
- What: Train shadows on local/private data and aggregate updates without exposing raw data; share only compact shadow deltas.
- Tools/workflows: Federated learning pipelines tailored to shadows; privacy accounting; model provenance tracking.
- Assumptions/dependencies: Robust privacy tech (e.g., DP, secure aggregation); harmonized evaluation across sites.
- Standardized “shadow module” formats and marketplaces
- Sectors: model hubs, enterprise marketplaces, open-source
- What: Create interoperable packaging for shadows (versions, provenance, safety grades) for exchange across platforms.
- Tools/workflows: Hugging Face-style collections for shadows; certification badges; dependency resolvers.
- Assumptions/dependencies: Community consensus; legal clarity on redistribution and cross-backbone compatibility.
- Hardware–software co-design for parallel shadow/backbone execution
- Sectors: silicon vendors, device OEMs
- What: Fuse shadow injection/update into transformer kernels; exploit NPUs for parallel streams; dynamic gating accelerators.
- Tools/workflows: Compiler passes for fused ops; runtime schedulers for dual-path inference; power/thermal tuning.
- Assumptions/dependencies: Vendor support; kernel standardization; stable APIs across model families.
- Composable multi-shadow orchestration
- Sectors: large enterprises, LLM platforms
- What: Attach multiple specialized shadows (e.g., safety + domain + locale), with learned policies to sequence/merge their effects.
- Tools/workflows: “Shadow Orchestrator” for conflict resolution and weighting; evaluation harness for interactions.
- Assumptions/dependencies: Research on interference mitigation; unified scoring for composition; memory budgets.
- Robust detached-mode small-model assistants
- Sectors: consumer electronics, automotive, wearables
- What: Evolve detached shadows into strong, self-sufficient small models for most daily tasks, with rare cloud escalations.
- Tools/workflows: Large-scale shadow pretraining (e.g., FineWeb-Edu, domain corpora); continual learning on-device.
- Assumptions/dependencies: Strong pretraining is essential (paper shows random-init shadows collapse in detached mode); guard against drift.
- Regulatory-grade adaptation and auditability
- Sectors: policy/regulatory, compliance-heavy industries
- What: Certify shadows as auditable, non-invasive adapters; enable model updates via shadow swaps without altering backbone weights.
- Tools/workflows: Model cards for shadows; audit logs of attached/detached states; lifecycle controls for regulated deployments.
- Assumptions/dependencies: Standards for adapter-level certification; clearer AI Act/sectoral guidance on modular updates.
- Cross-backbone portability and inter-family shadows
- Sectors: model vendors, integrators
- What: Develop methods to reuse a shadow across different backbone families (e.g., mapping layers/interfaces), multiplying reuse benefits.
- Tools/workflows: Interface adapters; alignment/pre-alignment steps; automated compatibility tests.
- Assumptions/dependencies: Research to normalize layer spaces; risk of performance cliffs without careful adaptation.
- Energy-efficient edge AI for buildings and grids
- Sectors: energy, smart buildings, industrial IoT
- What: Use shadows for local policy/command interpretation (setpoints, diagnostics) and escalate complex analysis to cloud models.
- Tools/workflows: Edge gateways with shadows; escalation policies tied to latency/availability constraints.
- Assumptions/dependencies: Domain-tuned shadow pretraining; secure deployment; resilience requirements.
- Task-optimized parameter scaling policies
- Sectors: research, platforms
- What: Automate selection of shadow size given task latency/accuracy targets (paper shows gains up to ~0.4B shadow with mild saturation).
- Tools/workflows: Auto-tuning of shadow size/architecture; dynamic scaling per user/session.
- Assumptions/dependencies: Monitoring and feedback loops; guardrails to avoid overfitting/generalization loss.
- Knowledge transfer and distillation workflows
- Sectors: academia, model vendors
- What: Use the shadow as a conduit for distillation (e.g., from backbone or external teacher), then deploy the detached shadow for low-cost inference.
- Tools/workflows: Distillation pipelines targeting shadow states/outputs; hybrid training with auxiliary shadow losses (as in the paper).
- Assumptions/dependencies: Task-aligned teachers; evaluation to prevent catastrophic forgetting.
Notes on Feasibility and Assumptions (cross-cutting)
- Model scope and generality: Results are shown on Qwen3 backbones and specific benchmarks; replication on other LLM families may require engineering and tuning.
- Shadow pretraining matters: Detached mode quality depends strongly on shadow pretraining; randomly initialized shadows underperform substantially when detached.
- Architectural assumptions: ShadowPEFT is designed for transformer decoder stacks with layer-wise injection and gated updates; adaptation for other architectures (e.g., encoders, multimodal) needs further work.
- Resource envelopes: Even with low overhead, deployment must meet device memory/compute budgets; large shadows (e.g., 0.5B) may not fit on very constrained devices.
- Governance and IP: Combining a third-party shadow with a proprietary backbone requires licensing clarity and security reviews (supply-chain risk).
- Safety and evaluation: While the paper indicates improvements and a robot-dog demo, domain-specific safety, robustness, and bias evaluations are essential prior to high-stakes use.
Glossary
- AdaLoRA: A LoRA variant that allocates rank adaptively across layers to improve efficiency and performance. "rank adaptivity (AdaLoRA \citep{zhangadaptive}, DyLoRA \cite{valipour2023dylora}, LoRA-GA \citep{wang2024lora})"
- Adapter modules: Small trainable blocks inserted into Transformer layers to adapt models while keeping most parameters frozen. "adapter modules inserted into Transformer blocks \citep{houlsby2019parameter}"
- AdapterSoup: A method for composing or fine-tuning multiple adapters to improve modularity and transfer. "Subsequent extensions improve modularity and transferability, including AdapterSoup \citep{chronopoulou2023adaptersoup}, Tiny-attention adapter \citep{zhao2022tiny}, and Compacter \citep{karimi2021compacter}."
- Amazon review sentiment: A benchmark dataset for sentiment classification on Amazon product reviews. "Understanding tasks: Amazon review sentiment \citep{keung2020amazonreview} (Amazon) and 20 Newsgroup \citep{twenty_newsgroups} (20News) classification."
- base-shadow discrepancy: The difference between base model and shadow states used to compute corrective signals. "In the injection step, the model uses base-shadow discrepancy to compute a correction."
- causal language modeling: A training objective where the model predicts the next token given past tokens in a sequence. "Causal language modeling objective."
- Chain-of-Thought reasoning: A prompting technique that elicits step-by-step reasoning to improve problem-solving. "Chain-of-Thought reasoning \citep{Wei2022COT}"
- Compacter: An adapter method that compresses adapters for parameter efficiency. "Subsequent extensions improve modularity and transferability, including AdapterSoup \citep{chronopoulou2023adaptersoup}, Tiny-attention adapter \citep{zhao2022tiny}, and Compacter \citep{karimi2021compacter}."
- cross-entropy loss: A standard loss function for classification and language modeling that measures prediction uncertainty. "is the standard next-token cross-entropy loss"
- cross-layer parameter sharing: Reusing the same adaptation parameters across multiple layers to enable centralized refinement. "ShadowPEFT performs transformer layer-level refinement with cross-layer parameter sharing."
- detached shadow-only inference: An inference mode where only the shadow model runs, bypassing the large backbone for lightweight deployment. "2) Detached shadow-only inference. Only the shadow backbone and its prediction head are used."
- DoRA: A LoRA variant that decomposes weight updates to potentially improve robustness and performance. "We compare against two widely used low-rank PEFT baselines: LoRA~\citep{hu2022lora} and DoRA~\citep{liu2024dora}."
- DyLoRA: A dynamic LoRA variant that adjusts rank or structure during training. "rank adaptivity (AdaLoRA \citep{zhangadaptive}, DyLoRA \cite{valipour2023dylora}, LoRA-GA \citep{wang2024lora})"
- edge computing: Performing computation on local or near-device hardware to reduce latency and cloud dependency. "benefiting edge computing scenarios."
- few-shot prompting: Supplying a few exemplars in the prompt to guide model behavior without parameter updates. "few-shot prompting \citep{liu2022few}"
- FineWeb-Edu: A curated web dataset for educational or general pretraining use. "on a small portion of FineWeb-Edu \citep{lozhkov2024fineweb-edu} (English) and Wudao \citep{wudao} corpus (Chinese)."
- gated residual: An update mechanism that interpolates between old and new states using a learned gate. "their product updates the shadow state via a gated residual."
- GRU-style: Referring to mechanisms inspired by Gated Recurrent Units, using gating for stable updates. "This GRU-style \citep{Cho2014GRU} design is helpful to prevent shadow collapse and improve optimization stability."
- GSM8K: A math word problem benchmark for arithmetic and reasoning evaluation. "GSM8K \citep{cobbe2021gsm8k}"
- LayerNorm: A normalization technique applied across feature dimensions within a layer to stabilize training. "The base output $\mathbf{h}^{(\ell)}_{\mathrm{out}$ is LayerNorm-normalised, then split into a transform and a sigmoid gate ;"
- layer-space refinement: Adapting model behavior by refining representations at the layer level rather than perturbing individual weights. "a shared layer-space refinement process."
- LoRA: Low-Rank Adaptation; a PEFT method that injects low-rank trainable updates into linear layers while freezing the base model. "LoRA injects trainable low-rank updates into selected linear projections while keeping the pretrained weights frozen."
- LoRA-GA: A LoRA variant incorporating genetic or gradient allocation strategies (as per citation) to manage rank/updates. "rank adaptivity (AdaLoRA \citep{zhangadaptive}, DyLoRA \cite{valipour2023dylora}, LoRA-GA \citep{wang2024lora})"
- low-rank adaptation: Constraining parameter updates to low-dimensional subspaces to reduce trainable parameters. "Low-rank adaptation has emerged as one of the most influential PEFT paradigms."
- low-rank bottleneck: A projection through a low-dimensional subspace used to limit parameter count and capacity. "The discrepancy is projected through a low-rank bottleneck"
- MMLU: A multi-task language understanding benchmark spanning diverse subjects. "including MMLU \citep{hendryckstest2021}, GSM8K \citep{cobbe2021gsm8k}, and SQuAD~v2 \citep{rajpurkar2018squadv2}."
- MoELoRA: A mixture-of-experts LoRA variant for multi-task or modular adaptation. "MoELoRA \citep{li2024mixlora}, Mtl-LoRA \citep{yang2025mtl}, and LLM safety \citep{hsu2024safe}"
- Moore--Penrose pseudo-inverse: A generalized matrix inverse used for initialization or analytical solutions in linear systems. "with Moore--Penrose pseudo-inverse \citep{barata2012moore} initialization"
- out-of-distribution (OOD) generalization: The ability of a model to perform well on data that differ from the training distribution. "To assess whether ShadowPEFT improves out-of-distribution (OOD) generalization, we fine-tune Qwen3 4B on a single dataset and evaluate on the remaining two held-out generation benchmarks"
- Parameter-efficient fine-tuning (PEFT): Techniques that adapt large models by training only a small number of parameters while keeping most weights frozen. "Parameter-efficient fine-tuning (PEFT) reduces the training cost of full-parameter fine-tuning for LLMs by training only a small set of task-specific parameters while freezing the pretrained backbone."
- P-Tuning: A prompt-based PEFT method that learns continuous prompt embeddings. "P-Tuning \citep{liu2022p}"
- Prefix Tuning: A method that prepends trainable vectors to Transformer inputs as soft prompts. "Prefix Tuning \citep{li2021prefix}"
- QLoRA: A LoRA variant that uses quantization to enable memory- and compute-efficient fine-tuning. "QLoRA \citep{dettmers2023qlora}"
- quantization: Representing weights/activations with lower precision to reduce memory and computation. "quantization (QLoRA \citep{dettmers2023qlora}, QA-LoRA \citep{xu2023qa})"
- rank adaptivity: Adjusting the rank of low-rank updates during training to better allocate capacity. "rank adaptivity (AdaLoRA \citep{zhangadaptive}, DyLoRA \cite{valipour2023dylora}, LoRA-GA \citep{wang2024lora})"
- residual connection: A skip connection that adds inputs to outputs to ease optimization and stabilize deep networks. "corrected representation is obtained via a residual connection"
- ShadowPEFT: The proposed centralized PEFT framework that uses a depth-shared shadow module for layer-level refinement. "We propose ShadowPEFT, a centralized PEFT framework that instead performs layer-level refinement through a depth-shared shadow module."
- shadow module: The shared, portable component in ShadowPEFT that maintains and updates a parallel state to refine the base model. "Since the shadow module is decoupled from the backbone, it can be reused across depth, independently pretrained, and optionally deployed in a detached mode"
- shadow pretraining: Pretraining the shadow model before fine-tuning to improve both attached and detached performance. "Additional analyses on shadow pretraining, cross-dataset transfer, parameter scaling, inference latency, and system-level evaluation"
- SQuAD V2: A question-answering benchmark that includes unanswerable questions. "SQuAD V2 \citep{rajpurkar2018squadv2}"
- state-space adaptation: Viewing adaptation as the evolution of a state across layers rather than local weight tweaks. "a depth-wise state-space adaptation process"
- Tiny-attention adapter: A lightweight adapter variant focusing on small attention modules. "Subsequent extensions improve modularity and transferability, including AdapterSoup \citep{chronopoulou2023adaptersoup}, Tiny-attention adapter \citep{zhao2022tiny}, and Compacter \citep{karimi2021compacter}."
- Unitree Go2: A quadruped robot platform used for system-level evaluation of intent understanding. "we further conduct a system-level experiment on the Unitree Go2 robot dog intent understanding."
- weight-magnitude decomposition: A technique (used in DoRA) separating weight direction and magnitude, which can impact generalization. "its additional weight-magnitude decomposition may hurt generalization performance."
- weight-space perturbations: Direct modifications to model weights to induce adaptation. "shifts adaptation from distributed weight-space perturbations to a shared layer-space refinement process."
- Wudao: A large-scale Chinese corpus used for pretraining. "and Wudao \citep{wudao} corpus (Chinese)."
Collections
Sign up for free to add this paper to one or more collections.

