LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
Abstract: We present LLaDA2.0-Uni, a unified discrete diffusion LLM (dLLM) that supports multimodal understanding and generation within a natively integrated framework. Its architecture combines a fully semantic discrete tokenizer, a MoE-based dLLM backbone, and a diffusion decoder. By discretizing continuous visual inputs via SigLIP-VQ, the model enables block-level masked diffusion for both text and vision inputs within the backbone, while the decoder reconstructs visual tokens into high-fidelity images. Inference efficiency is enhanced beyond parallel decoding through prefix-aware optimizations in the backbone and few-step distillation in the decoder. Supported by carefully curated large-scale data and a tailored multi-stage training pipeline, LLaDA2.0-Uni matches specialized VLMs in multimodal understanding while delivering strong performance in image generation and editing. Its native support for interleaved generation and reasoning establishes a promising and scalable paradigm for next-generation unified foundation models. Codes and models are available at https://github.com/inclusionAI/LLaDA2.0-Uni.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LLaDA2.0-Uni, a single AI model that can both understand images (like answering questions about a photo or a chart) and create or edit images (like drawing what you describe or changing parts of a picture). Instead of using two separate systems—one for understanding and one for making images—this model does both in one unified way.
What questions are the researchers asking?
The team set out to answer a few simple but important questions:
- Can one model handle both “understanding” (reading images and answering questions) and “generation” (making and editing images) without needing separate parts or different training rules?
- Can we make this model fast and efficient while keeping high quality?
- Can understanding and generation help each other, so the model can reason while creating, or create while reasoning?
How does the model work?
Think of the system like a factory with three clever stations. Each station uses simple ideas under the hood:
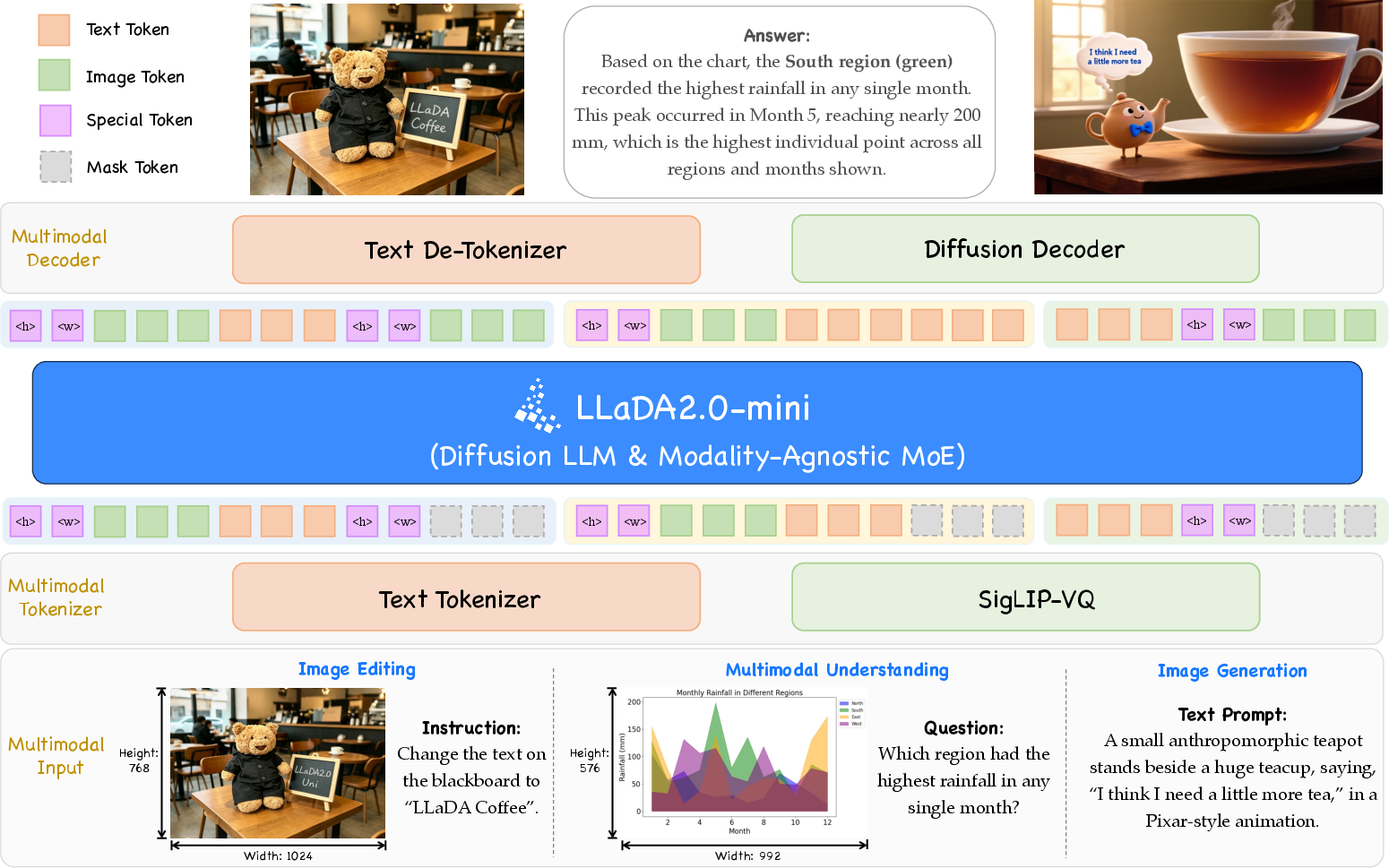
1) Turning pictures into “words” the model understands (the tokenizer)
- Real-world images are continuous (lots of pixel details), but the LLM works best with discrete symbols (like words).
- The model uses a tool called a “semantic tokenizer” (SigLIP‑VQ) to translate an image into a sequence of meaningful tokens—like turning a picture into a string of LEGO-like pieces that carry meaning (e.g., “dog,” “grass,” “two people,” “red ball”) instead of raw pixels.
- Why this matters: Many older image tokenizers focused on recreating pixels, which hurt understanding. This tokenizer focuses on meaning, which helps the model understand better while still allowing high-quality image reconstruction later.
2) The “brain” that thinks across text and image tokens (the Mixture‑of‑Experts dLLM)
- The core is a Diffusion LLM (dLLM) with a Mixture‑of‑Experts (MoE) design. Think of MoE as a team of specialized advisers inside the model—each good at different things—so the model can route problems to the right expert.
- Instead of predicting the next word one-by-one, it uses a “masked diffusion” process: it hides blocks of tokens (like covering parts of a puzzle) and fills them in. This lets it:
- Look at both left and right context (bidirectional reasoning),
- Fill in many pieces in parallel (faster than step-by-step),
- Use the same training rule for both text and image tokens (unified learning).
- It uses “block-wise attention,” which means the model focuses on chunks of the sequence at a time. This makes it more stable and efficient while still being good at understanding and generating.
3) Turning “meaning tokens” back into pictures (the diffusion decoder)
- Once the model decides which image tokens describe the final picture, a specialized “diffusion decoder” turns those tokens into a high-quality image.
- Imagine fog slowly lifting to reveal an image: diffusion starts from noise and refines it step by step into a clear picture.
- The team distilled this process so it only needs about 8 steps (instead of ~50), making it much faster with little loss in quality.
Making it fast: SPRINT and few‑step generation
- SPRINT is a pair of tricks to speed up decoding without retraining:
- Sparse Prefix Retention: keep only the most important past information in memory, and prune the rest. (Text is kept more cautiously; image tokens are pruned more aggressively because images have redundancy.)
- Non‑uniform Token Unmasking: don’t waste steps on tokens the model is already confident about. If it’s confident, accept that token quickly; spend time on the hard parts.
- Combined, these speedups can make generation up to about 1.6× faster with almost no quality loss.
- The image decoder is also distilled to generate in just 8 steps, which is both quick and high quality.
Training and data (in brief)
- The team trained the model in stages: first align vision and language, then pretrain on many tasks, then fine‑tune on high‑quality instruction data.
- They used large amounts of carefully filtered data for:
- Multimodal understanding (questions about images, documents, math diagrams, OCR),
- Image generation (millions of high‑quality images and rich captions),
- Image editing (before/after pairs with precise instructions),
- Interleaved image‑text sequences (like stories mixing pictures and words),
- Reasoning-augmented tasks (thinking step-by-step before creating an image).
What did they find?
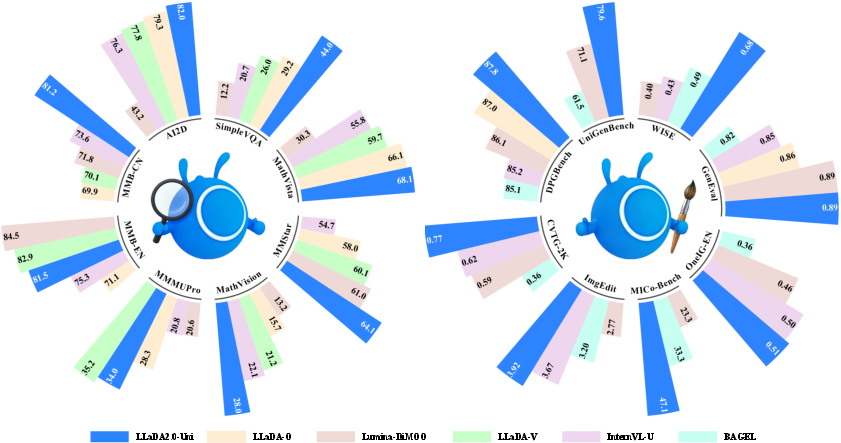
The main results show that one unified model can do a lot—and do it well:
- Strong image understanding: On many tests (like general visual question answering, reasoning, and document/OCR tasks), LLaDA2.0‑Uni performs as well as specialized “understanding-only” models.
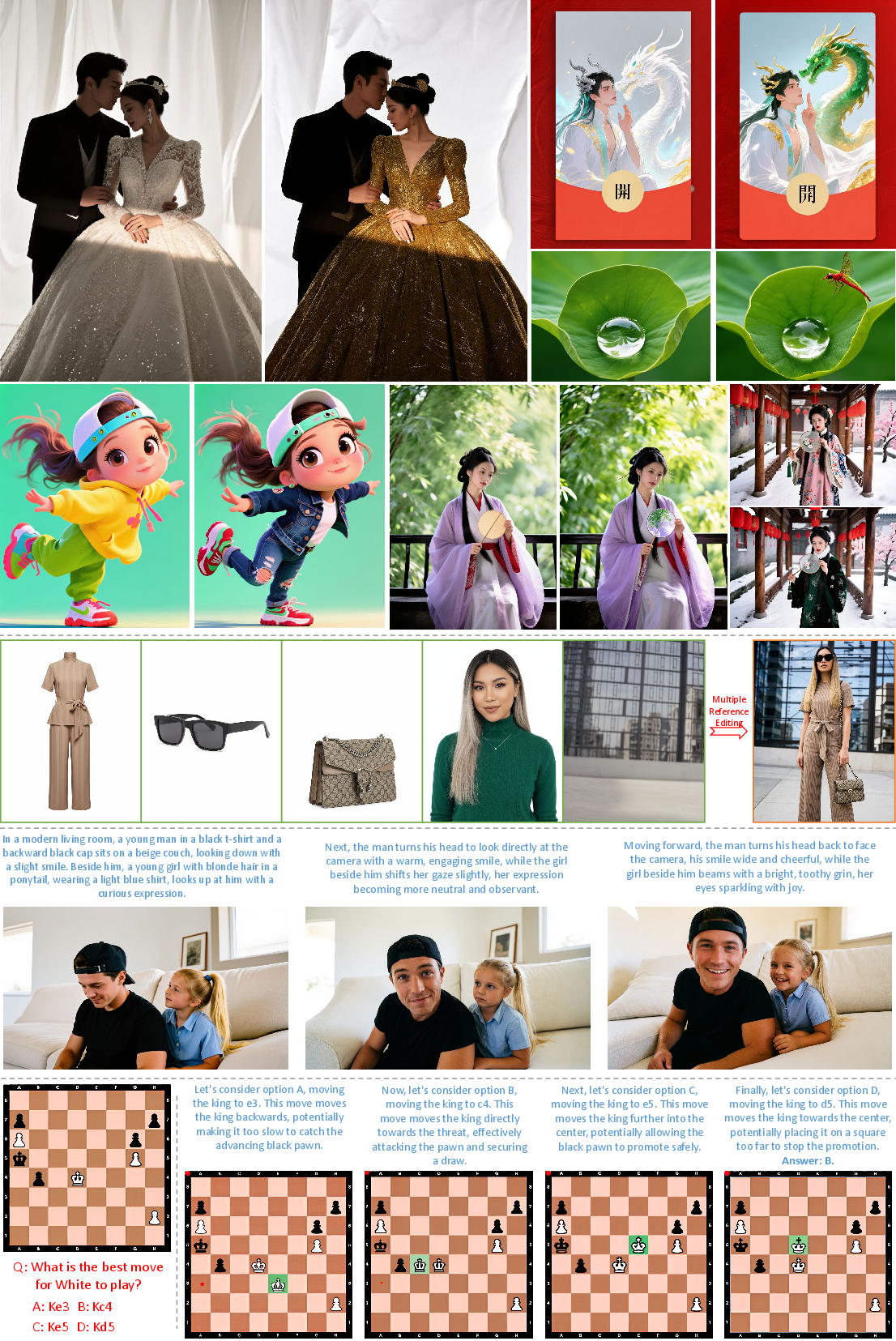
- High‑quality image generation and editing: It makes detailed, faithful images from text prompts and can edit images in flexible ways.
- Interleaved reasoning and creation: The model can mix reading and writing images and text in one go—for example, think step by step about a prompt and then draw exactly what it reasoned about, or generate images while explaining its reasoning.
- Efficient inference: Thanks to parallel masked diffusion, SPRINT, and few‑step decoding, it’s faster than many traditional approaches while keeping quality high.
Why this is important:
- You don’t need one model to understand pictures and a separate one to make them—this unified approach saves memory, deployment time, and engineering effort.
- Understanding and generation can improve each other: better reading helps better drawing, and vice versa.
Why does this matter?
- One foundation, many skills: LLaDA2.0‑Uni shows a practical path toward AI systems that both understand and create across multiple formats—text, images, and even mixed sequences—without juggling many separate models.
- Easier to build future apps: A single model that can answer questions about documents, plan a design, and then create the image (or edit an existing one) is useful for education, content creation, data analysis, and more.
- A step toward more general AI: By unifying understanding and generation under the same learning rules and representations, this work moves toward AI that can reason across different types of information in a more human-like, flexible way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Variable-length text decoding with masked diffusion: the paper does not specify how end-of-sequence (EOS) is predicted, how new blocks are allocated, or how stopping criteria are defined for open-ended understanding tasks.
- Block-wise attention design: critical hyperparameters (block size, cross-block attention pattern) and their effect on long-range consistency, cross-modal dependencies, and bidirectional leakage are not reported or ablated.
- 1D RoPE with size tokens vs 2D positional encodings: the limits of the proposed 1D approach for fine-grained spatial reasoning, grounding, and geometric relations remain unquantified; no comparison to 2D RoPE or alternative spatial encodings.
- Semantic tokenizer trade-offs: how SigLIP-VQ’s semantic compression affects fine texture, small-object fidelity, and text rendering in generation (vs reconstructive VQ or hybrid tokens) is not analyzed.
- Domain gap between extracted and generated tokens: the decoder is trained on tokens from images while it conditions on LM-generated tokens at inference; exposure bias and mitigation strategies (e.g., scheduled sampling, self-conditioning) are not discussed.
- Conditioning strategy in the diffusion decoder: removing text prompts and conditioning only on semantic tokens may reduce controllability or nuance; there are no ablations comparing “tokens-only” vs “tokens+text”.
- CFG-free 8-step distillation: the impact on sample diversity, mode coverage, and controllability is not quantified (e.g., FID/KID, Precision/Recall, diversity metrics), nor are failure modes of few-step sampling explored.
- Resolution scalability: generation is demonstrated up to 1024 via 2× SR; behavior at 2K–4K, tiled generation, and artifact patterns at higher resolutions are not evaluated.
- Video support: although the framework mentions video and uses interleaved frames, there is no temporal diffusion decoder or evaluation of video generation/editing or temporal consistency across frames.
- Interleaved generation and reasoning: there is no standardized evaluation protocol, quantitative metrics, or user studies to validate this capability and characterize failure modes when reasoning contradicts visual outputs.
- Editing evaluation: quantitative metrics for editing quality (locality/faithfulness, identity preservation, structural consistency) and benchmark comparisons are missing; robustness to fine-grained or geometry-preserving edits is unclear.
- MoE specialization and stability: there is no analysis of expert utilization across modalities, risk of expert collapse, or modality interference; scaling behavior to more modalities and larger expert counts is untested.
- Load balancing strategy: the auxiliary-loss-free mechanism is adopted but not ablated; its effect on performance, stability, and expert diversity is not quantified.
- SPRINT robustness and calibration: confidence thresholds and keep ratios are heuristic; there is no study of calibration for diffusion logits, worst-case degradations, or domain-adaptive thresholding.
- Non-uniform unmasking bias: favoring high-confidence positions may disadvantage rare words, small objects, or low-frequency visual patterns; mitigation strategies are not discussed.
- Efficiency reporting: wall-clock latency, throughput, and memory comparisons against AR/hybrid models across tasks, resolutions, and sequence lengths are not provided.
- Multilingual capabilities: beyond limited EN/CN reporting, understanding and generation performance in low-resource languages and script-heavy OCR settings remains unknown.
- Safety, ethics, and bias: data licensing, bias audits, content moderation, and copyright compliance for 200M web images and VLM-filtered annotations are not addressed; potential teacher-model imprinting from Qwen-based filtering is unexplored.
- Robustness and OOD generalization: behavior under distribution shifts, adversarial prompts/images, and compositional generalization stress tests is not studied.
- Training reproducibility and compute: hardware setup, training duration, energy footprint, and key hyperparameters are not disclosed; component-wise ablations (e.g., SigLIP-VQ vs VQ-VAE, MoE vs dense) are missing.
- High-density document/OCR limits: reliance on semantic tokens without reconstructive cues may hinder very small fonts and dense layouts; the need for high-res tiling or zoom-in strategies is not examined.
- Long-context scaling: with 8k→16k contexts, memory/latency trade-offs, retrieval/chunking strategies for multi-image inputs, and degradation beyond 16k tokens are not analyzed.
- Codebook design: sensitivity to codebook size (16,384), code collisions, and adaptability to new domains (e.g., medical, satellite) without retraining are not explored.
- Compositional/spatial control: mechanisms for explicit layout control (e.g., masks, bounding boxes, scene graphs) via semantic tokens are not provided or evaluated.
- Joint training: the pipeline relies on pre-extracted tokens and separate decoder training; the benefits and costs of end-to-end joint finetuning of tokenizer, backbone, and decoder are untested.
- Data packing side effects: potential context leakage between concatenated samples and required segment boundaries/sentinels are not described or evaluated.
- Hallucination handling: strategies to reduce visual or textual hallucination in both understanding and generation are not proposed or measured (e.g., Hallucination/faithfulness diagnostics beyond reported benchmarks).
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage LLaDA2.0-Uni’s unified discrete diffusion LLM (dLLM), SigLIP-VQ semantic tokenizer, diffusion decoder, interleaved generation-and-reasoning, and the SPRINT inference-speedup framework.
Industry
- Marketing and e-commerce creative automation (Sectors: Retail, Advertising, Software)
- What: High-fidelity text-to-image generation; single/multi-reference image editing; brand/scene variations; realistic text rendering in images (e.g., banners, packaging, signage); batch catalog background edits.
- Tools/products/workflows: “Creative Studio” web app/API; DAM-integrations (e.g., Shopify, Adobe/Photoshop/Figma plug-ins); templated brand kits with attribute binding; batch pipelines for seasonal refreshes.
- Assumptions/dependencies: GPU serving for 16B MoE dLLM + 6B diffusion decoder; rights and usage policies for reference assets; safety filters for people/content; prompt libraries and QA for brand compliance.
- Document AI and enterprise digitization (Sectors: Finance, Government, Legal, Insurance)
- What: OCR/DocVQA/chart/table QA; layout-aware extraction; interleaved chain-of-thought (CoT) rationales; conversion to structured JSON for invoices, receipts, KYC forms, scientific PDFs.
- Tools/products/workflows: “Doc-to-Data” pipeline (scan → SigLIP-VQ tokens → dLLM DocVQA → JSON); human-in-the-loop validation UI; retrieval-based verification for field-level confidence.
- Assumptions/dependencies: Domain-tuned SFT for target documents; on-prem or VPC deployment for PII; audit logs and redaction; pixel-perfect needs may require fallback OCR ensembles.
- Visual QA for inventory and operations (Sectors: Manufacturing, Logistics, Retail)
- What: Counting, grounding, and position validation from photos; spot-check pallet counts, shelf compliance, or assembly steps.
- Tools/products/workflows: Mobile photo check-in app; dashboard with visual grounding overlays; exception routing to supervisors.
- Assumptions/dependencies: Task-specific prompts and guardrails; calibration datasets per site; human verify-on-fail; safety policies for workplace images.
- Rapid UI/UX ideation and concept mockups (Sectors: Software, Design)
- What: Prompt-to-mockup images; layout exploration via size tokens; interleaved reasoning to iteratively refine variants.
- Tools/products/workflows: Figma/Sketch plug-ins; “Design brief → multi-variant mockups” generator; design system style-guides as constraints.
- Assumptions/dependencies: Consistency with component libraries; acceptance that outputs are visual concepts (not production code); IP checks on style prompts.
- Synthetic data engine for vision tasks (Sectors: Software, Robotics, Retail)
- What: Generate labeled images with attributes/boxes/counts for OCR, detection, and grounding; data balancing for rare classes.
- Tools/products/workflows: “Data Foundry” service with prompt templates; auto-annotations aligned to generation constraints; bias/coverage dashboards.
- Assumptions/dependencies: Rigorous bias/realism checks; domain shift mitigation; governance for synthetic data provenance.
- Storyboard and visual narrative drafting (Sectors: Media, Games, Advertising)
- What: Interleaved generation-and-reasoning to produce sequences of 2–6 frames from scripts; variant exploration of scenes/angles.
- Tools/products/workflows: “Storyboarder” that turns briefs into frame sequences with rationales; handoff to artists.
- Assumptions/dependencies: Limited temporal consistency (frames, not full video); post-production polish expected.
- Lower-latency multimodal decoding in production (Sectors: Software/Platform)
- What: Adopt SPRINT (Sparse Prefix Retention + Non-uniform Token Unmasking) to reduce compute and latency for masked diffusion backbones.
- Tools/products/workflows: Inference wrappers that prune KV cache by modality, confidence-adaptive unmasking; A/B gating of thresholds.
- Assumptions/dependencies: Threshold tuning per content type; quality guardrails; monitoring for degradation on long/complex prompts.
Academia
- Open research platform for unified multimodality (Sectors: Research, Education)
- What: Reproduce and extend discrete diffusion LLMs; ablate SigLIP-VQ vs. reconstructive VQ; evaluate block-wise attention; study SPRINT speed-quality tradeoffs; build new interleaved reasoning-generation benchmarks.
- Tools/products/workflows: Course labs, tutorials, Colab notebooks; benchmark harnesses; reproducible training configs (pre-extract tokens, data packing).
- Assumptions/dependencies: GPU credits; dataset licensing; careful reporting of evaluation protocols.
Policy and Government
- Public-record digitization and analytics
- What: OCR + DocVQA on forms, archives, and charts; explainable rationales for extracted fields.
- Tools/products/workflows: Secure ingestion pipeline; schema mapping to open data formats; FOIA-ready audit trails.
- Assumptions/dependencies: On-prem deployment; PII protection; governance for error handling and human review.
- Accessible communications
- What: Auto-generate alt-text and detailed image captions for public websites and reports; readable chart explanations.
- Tools/products/workflows: CMS plug-ins; batch jobs for media libraries; accessibility QA dashboards.
- Assumptions/dependencies: Accuracy monitoring; sensitive-content filters; multilingual support as needed.
Daily Life
- Natural-language photo editing and enhancement
- What: Single/multi-reference editing (inpainting, background changes, subject preservation); “make this look professional” workflows.
- Tools/products/workflows: Mobile editing apps; desktop plug-ins; simple share-to-social flows.
- Assumptions/dependencies: Content safety; watermarking as appropriate; default privacy settings.
- Visual tutoring with step-by-step diagrams
- What: Generate/explain math and science problems with interleaved reasoning and illustrative images.
- Tools/products/workflows: Learning apps; worksheet generators; teachers’ assistants for custom visuals.
- Assumptions/dependencies: Hallucination mitigation; curriculum alignment; educator-in-the-loop review.
Long-Term Applications
These concepts are plausible extensions but require further research, scaling, or integration (e.g., domain fine-tuning, safety, latency, or regulatory alignment).
Industry
- Robotics and autonomy co-pilots (Sectors: Robotics, Manufacturing, Logistics)
- What: Use interleaved visual reasoning to produce structured plans with scene illustrations; synthetic environment generation for sim training.
- Tools/products/workflows: “Plan-with-visuals” modules; synthetic data loops for perception; sim2real evaluation suites.
- Assumptions/dependencies: Closed-loop validation; real-time constraints; safety certification; domain-specific sensors and control stacks.
- Healthcare document and imaging assistants (Sectors: Healthcare, Insurance)
- What: Consent/form parsing; visual case summaries; educational medical-image generation (not diagnostic).
- Tools/products/workflows: EHR-integrated extraction; radiology teaching sets; claim document triage.
- Assumptions/dependencies: Medical domain tuning; HIPAA/GDPR compliance; clinical oversight; strict non-diagnostic use unless validated.
- Real-time AR design assistants (Sectors: Software, Retail, Field Service)
- What: On-device, low-latency interleaved reasoning-and-generation to overlay visual suggestions in situ.
- Tools/products/workflows: AR SDKs; edge-distilled models; caching strategies for scene tokens.
- Assumptions/dependencies: Additional distillation and hardware acceleration; battery and thermal budgets; safety/privacy in public spaces.
- Video generation and advanced editing (Sectors: Media, Advertising, Education)
- What: From interleaved frames to full temporally coherent video generation, editing, and inbetweening.
- Tools/products/workflows: Video storyboard-to-clip pipelines; timeline-aware diffusion; consistency validators.
- Assumptions/dependencies: Temporal modeling extensions; substantial compute; IP/licensing for training and outputs.
- Design-to-code multimodal IDE (Sectors: Software, Product Design)
- What: Iterative co-design that reasons with visuals and outputs production-ready components/code.
- Tools/products/workflows: IDE plug-ins that pair visual mockups with code LLMs; constraint solvers for design systems.
- Assumptions/dependencies: Robust integration with code models and test frameworks; accessibility and performance constraints.
- Privacy-preserving and on-prem deployments at scale (Sectors: Finance, Government, Enterprise IT)
- What: Secure MoE/diffusion stacks using TEEs, federated learning, or future cryptographic approaches; tenant-isolated inference.
- Tools/products/workflows: Compliance-ready MLOps; key management; audit-by-design.
- Assumptions/dependencies: Maturity of confidential computing; optimized routing for MoE; predictable latency under isolation.
- Multilingual, multicultural content systems (Sectors: Global Enterprise, Media)
- What: Consistent attribute binding and text rendering across scripts; culturally aware visuals.
- Tools/products/workflows: Language packs; locale-specific prompt libraries; regional compliance checkers.
- Assumptions/dependencies: Multilingual tokenizer alignment; additional training data; cultural bias auditing.
- Retrieval-grounded visual content agents (Sectors: Legal, Pharma, Finance)
- What: Interleaved reasoning + retrieval for provenance-tracked visuals (e.g., annotated figures that cite sources).
- Tools/products/workflows: RAG pipelines; citation injection; fact-checking agents.
- Assumptions/dependencies: High-quality knowledge bases; provenance/signature standards; user trust interfaces.
Academia
- Cross-modal scaling laws and curriculum learning
- What: Systematic studies of data composition, mask schedules, block-wise attention, and expert routing under multimodal diffusion.
- Tools/products/workflows: Public leaderboards for interleaved reasoning-generation; shared training recipes and diagnostics.
- Assumptions/dependencies: Large-scale compute; standardized datasets; community coordination.
Policy and Government
- Automated visual compliance review (ads, packaging, public signage)
- What: Check color/placement/mandatory text, and detect non-compliant patterns with grounded explanations.
- Tools/products/workflows: Pre-submission validation portals; compliance scoring and remediation suggestions.
- Assumptions/dependencies: Encoded regulations; adversarial robustness; appeals and human oversight.
- Scalable assistive services
- What: Live captioning plus illustrative generation for hearings, education, and public broadcasts.
- Tools/products/workflows: Low-latency streaming inference; human moderation.
- Assumptions/dependencies: Further latency reductions; bias/fairness audits; accessibility standards.
Daily Life
- Co-creative personal planners with visual previews
- What: Plan events, interiors, DIY projects with step-wise visuals; generate shopping lists tied to scenes.
- Tools/products/workflows: Home apps; vendor integrations; AR previews.
- Assumptions/dependencies: Personal data privacy; preference learning; safety-aware guidance.
- On-device accessibility companions
- What: Describe surroundings and provide visual guides in real time.
- Tools/products/workflows: Edge-optimized models; offline packs.
- Assumptions/dependencies: Aggressive model compression; reliability standards; private-by-default design.
Glossary
- AGI (Artificial General Intelligence): A goal of creating systems with broad, human-level general cognitive abilities across tasks. "bringing us closer to artificial general intelligence (AGI)."
- AR (Autoregressive): A modeling approach that generates the next token conditioned on previously generated tokens in sequence. "Current unified multimodal models predominantly build upon autoregressive (AR) architectures."
- autoregessive bias: A tendency in models trained with next-token prediction to rely on left-to-right context, which can be disrupted by fully bidirectional attention. "they inherit an autoregressive bias that would be disrupted by pure full-attention."
- auxiliary-loss-free load balancing mechanism: A method to distribute workload evenly across experts in MoE without adding extra auxiliary losses. "We adopt an auxiliary-loss-free load balancing mechanism that promotes differentiated expert specialization while encouraging uniform workload distribution."
- BDLM (Block Diffusion LLM): A discrete diffusion training objective that operates on masked blocks of tokens to enable parallel decoding. "We adopt the Block Diffusion LLM (BDLM) training objective"
- bidirectional context modeling: Using information from both past and future positions in a sequence during inference or training. "masked diffusion models offer an alternative paradigm with inherent advantages in parallel decoding and bidirectional context modeling."
- block-wise attention: An attention pattern that restricts attention within or across blocks to stabilize training and maintain efficiency. "We adopt a block-wise attention scheme to balance quality and efficiency."
- block-wise mask prediction objective: A training objective where the model predicts masked tokens in contiguous blocks rather than individual tokens. "This architecture unifies text and image modeling through a shared block-wise mask prediction objective."
- CFG (Classifier-Free Guidance): A guidance technique used in diffusion models to steer sampling without an explicit classifier, often increasing the number of steps. "To address the computational cost of 50-step sampling with CFG, we employ model distillation to achieve 8-step CFG-free inference"
- Chain-of-Thought (CoT): An approach that encourages models to generate intermediate reasoning steps before final answers or outputs. "Image Generation with CoT"
- codebook: The discrete set of vectors used by a vector quantizer to map continuous embeddings to discrete indices. "featuring a codebook with a vocabulary size of 16,384 and a dimensionality of 2,048."
- complementary masking: A training strategy that creates paired masks so each token is uncorrupted in exactly one of the pair, improving data efficiency. "Complementary masking is a strategy to enhance data efficiency for dLLMs by constructing two antithetical training instances from a single sequence"
- confidence-adaptive unmasking: An inference strategy that unveils tokens based on the model’s confidence rather than a fixed schedule. "Non-uniform Token Unmasking replaces the fixed denoising schedule with confidence-adaptive unmasking to reduce the step count."
- consistency-based distillation: A training technique that enforces consistency across fewer sampling steps to speed up diffusion inference. "we adopt a lightweight consistency-based distillation framework for the diffusion decoder."
- dLLM (discrete diffusion LLM): A LLM trained with discrete diffusion objectives over token sequences. "a unified discrete diffusion LLM (dLLM) that supports multimodal understanding and generation"
- diffusion decoder: A diffusion-based module that reconstructs images from discrete semantic tokens. "a diffusion decoder that reconstructs visual tokens into high-fidelity images."
- discrete diffusion LLMs: LLMs trained to iteratively denoise masked or corrupted discrete token sequences. "Block-wise discrete diffusion LLMs require B × T forward passes to generate B blocks with T denoising steps each."
- dynamic resolution processing: The ability to handle inputs at varying image resolutions without changing architecture. "supports dynamic resolution processing."
- flow matching: A diffusion training objective that learns velocity fields mapping data to noise (or vice versa) across continuous time. "We optimize the diffusion decoder via the standard flow matching objective."
- interleaved generation and reasoning: The capability to alternate between reasoning steps and content generation (e.g., text and images) within one sequence. "native support for interleaved generation and reasoning"
- Jacobian-vector product (JVP): An operation computing the product of a Jacobian matrix with a vector, used here to approximate time derivatives in distillation. "The time derivative is a Jacobian-vector product (JVP) output of the diffusion decoder"
- KV cache (Key-Value cache): Stored key and value tensors from attention layers used to speed up autoregressive or iterative decoding. "Uniform KV cache eviction and fixed-schedule step reduction degrade quality"
- load balancing (MoE): Techniques to distribute tokens/activations across experts to prevent overuse of a subset and underuse of others. "Load Balancing Strategy."
- masked diffusion models: Diffusion models that learn to predict masked or corrupted tokens rather than continuous noise over pixels. "masked diffusion models offer an alternative paradigm"
- mask token reweighting loss: A loss reweighting scheme that balances gradients across samples with different numbers of masked tokens. "introducing complementary masking and a mask token reweighting loss to handle variable-length sequences."
- Mixture-of-Experts (MoE): An architecture with multiple “expert” sub-networks where a gating mechanism routes tokens to subsets of experts for efficiency and capacity. "A modality-agnostic Mixture-of-Experts (MoE) architecture enables language backbones to serve as universal multi-task learners"
- Non-uniform Token Unmasking: An inference strategy that adaptively accepts predictions for masked positions based on confidence thresholds. "Non-uniform Token Unmasking replaces the fixed denoising schedule with confidence-adaptive unmasking"
- parallel decoding: Generating multiple tokens (or blocks) simultaneously rather than strictly one-by-one. "inherent advantages in parallel decoding"
- prefix-aware optimizations: Techniques that accelerate inference by selectively retaining or pruning parts of the prefix during iterative denoising. "Inference efficiency is enhanced beyond parallel decoding through prefix-aware optimizations in the backbone"
- RMSNorm-style normalization: A normalization approach based on root-mean-square statistics, here used to stabilize MoE gate updates. "This RMSNorm-style normalization smooths bias updates, leading to stable load balancing throughout training."
- RoPE (Rotary Position Embedding): A positional encoding method that rotates queries and keys to encode relative positions effectively. "Rotary Position Embedding (RoPE) is a standard choice in LLMs due to its flexibility and scalability."
- Semantic VQ: Vector quantization applied to semantic features (not pixels), producing discrete tokens that capture high-level meaning. "Semantic VQ requires a specialized decoder to map features from the semantic space back to the image space"
- SFT (Supervised Fine-Tuning): A post-training stage where the model is tuned on curated instruction-following or task-specific data with ground-truth supervision. "Stage 2: Supervised Fine-Tuning."
- SigLIP-VQ tokenizer: A semantic discrete tokenizer built on SigLIP features that converts images into discrete tokens aligned with language. "The tokenizer adopts a SigLIP-VQ architecture building upon X-Omni to convert continuous images into discrete tokens."
- SPRINT (Sparse Prefix Retention with Inference-time Non-uniform Token Unmasking): A training-free acceleration framework combining prefix pruning and adaptive unmasking to speed up diffusion decoding. "We propose SPRINT (Sparse Prefix Retention with Inference-time Non-uniform Token Unmasking), a training-free framework that reduces cost along two orthogonal axes."
- super-resolution: The process of increasing image resolution or detail, often by a scaling factor. "our diffusion model performs 2× super-resolution"
- Vector Quantized (VQ) tokenizer: A tokenizer that maps continuous embeddings to discrete indices via a codebook for efficient discrete modeling. "LLaDA2.0-Uni employs a Vector Quantized (VQ) tokenizer to transform images into discrete visual tokens"
- vector quantizer: The module that assigns continuous vectors to their nearest codebook entries, producing discrete token indices. "a vector quantizer aligns the visual representations with a pre-trained LLM"
- ViT (Vision Transformer): A transformer-based architecture for images that processes patches as tokens. "utilizes a pre-trained SigLIP2-g ViT as the visual feature extractor"
- VLM (Vision-LLM): Models that jointly process visual and textual inputs for tasks like VQA, captioning, and reasoning. "specialized VLMs such as Qwen2.5-VL"
- visual grounding: The task of linking text expressions to their corresponding regions or objects in an image. "visual counting/grounding tasks."
Collections
Sign up for free to add this paper to one or more collections.