- The paper introduces full Transformer-block operator fusion using DSMEM, significantly reducing decoding latency in LLMs.
- It details kernel optimizations, including single-pass LayerNorm and tree reduction, to minimize memory traffic and kernel launch overhead.
- Experimental results on NVIDIA RTX 5090 show up to 1.34× TPOT speedup with negligible loss in output fidelity.
Introduction
LLM deployment is heavily constrained by autoregressive decoding latency, which increases with larger model sizes and longer context lengths. Modern decoding workflows execute the multiple operators within a Transformer block as fragmented GPU kernels, necessitating intermediate tensor storage in off-chip (global) memory. This fragmented operator scheduling introduces significant global memory traffic and kernel launch overhead, ultimately constraining throughput and increasing per-token latency—factors that remain critical even with state-of-the-art hardware.
Recent architectural advances in NVIDIA GPUs, particularly thread-block clusters with distributed shared memory (DSMEM), have opened new avenues for on-chip inter-block collectives, as exemplified by the original ClusterFusion framework, which fused the attention-side operators for LLM inference. The work, "ClusterFusion++: Expanding Cluster-Level Fusion to Full Transformer-Block Decoding" (2604.23553), systematically extends this paradigm to perform operator fusion across the entire Transformer decoder block in GPT-NeoX/Pythia models, unifying LayerNorm, QKV projection, RoPE, multi-head attention, projections, MLP, and residual pathways. This extension is backed with architectural adaptation, CUDA Graph compatibility, and detailed kernel-level optimizations—substantially reducing overall decoding step latency with only negligible effects on output fidelity.
Methodology and System Design
Full-Block Fusion
ClusterFusion++ broadens the scope of prior cluster-centric fusion beyond just the attention pipeline. A single CUDA kernel, orchestrated over thread-block clusters, now processes every operation of the Transformer decoder block sequentially and in-register/on-chip, encompassing:
- Pre-attention LayerNorm
- QKV projection, along with memory-efficient KV cache management
- Rotary Positional Embedding (RoPE), including model-specific partial rotation (as in Pythia-2.8B)
- Scaled dot-product attention, fused with on-chip key-value accumulation
- Output projection and residual update
- Post-attention LayerNorm
- Full MLP, including up-projection, activation (via PTX-accelerated GELU), down-projection, and residual
This comprehensive fusion exploits DSMEM-based collective primitives, circumventing the block-barrier limitation of prior on-chip fusion, and eliminates the need for intermediate tensor materialization in global memory between any stage of the block.
Architecture-Specific Adaptations
The kernel is shaped by GPT-NeoX/Pythia architectural details: weight matrices stored per-head-interleaved, the partial RoPE application unique to Pythia-2.8B (only the first 25% of each head dimension), and addition of bias at multiple layers. Special tiling and warp selection are employed to accommodate non-power-of-two dimensions such as dhead=80.
Kernel and Execution Optimizations
Key kernel-level innovations include:
- Single-pass LayerNorm: Combines mean and variance computation using Var(x)=E[x2]−E[x]2, halving memory traffic compared to two-pass implementations.
- Cluster-Cooperative Attention: Blocks in a cluster partition the sequence length, exchanging partial results via DSMEM for efficient on-chip reduction.
- Tree Reduction: Replaces sequential O(n) ring reductions with tree-structured O(logn) reductions for output accumulation across blocks.
- PTX-Intrinsic GELU: Leverages hand-optimized inline PTX for efficient nonlinearity computation.
To address kernel-launch and buffer-allocation overheads, ClusterFusion++ implements a persistent CUDA Graph mode. All layer-level context descriptors and buffer allocations are constructed once and reused over decode steps, allowing each autoregressive decode iteration to be launched as a graph replay, which further slashes per-step overhead.
Experimental Results
Evaluation on an NVIDIA RTX 5090 demonstrates substantial improvements in both throughput and time-per-output-token (TPOT), across both Pythia-2.8B and Pythia-6.9B models.
ClusterFusion++ delivers consistent speedups over the HuggingFace Transformers baseline with KV caching enabled:
- Pythia-2.8B: TPOT speedups from 1.21× up to 1.34× across sequence lengths of 16 to 2048.
- Pythia-6.9B: Similar speedups from 1.19× to 1.34×.
These speedups are accompanied by equivalently improved throughput, as shown below.
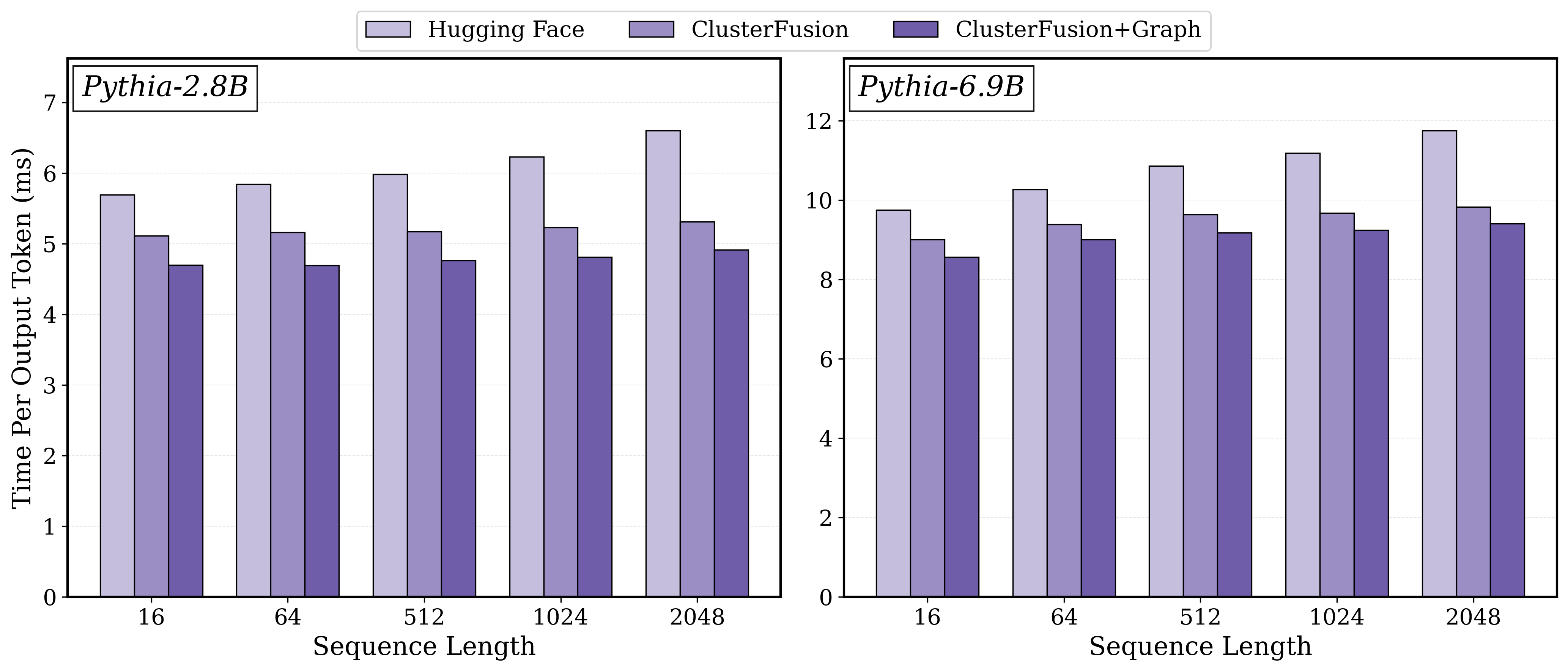
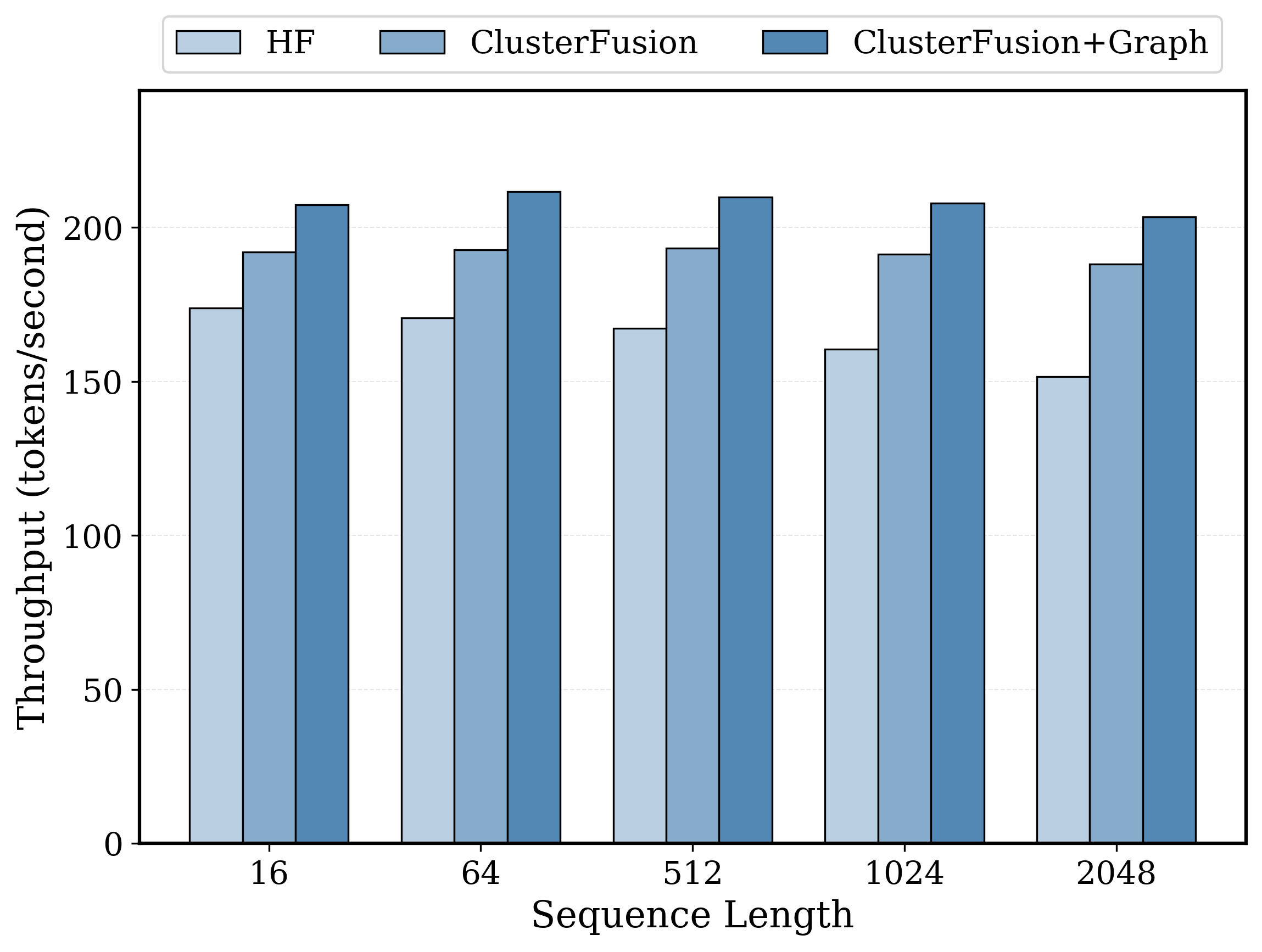
Figure 1: Time per output token (TPOT) for Pythia-2.8B (left) and Pythia-6.9B (right) on the RTX 5090 GPU, demonstrating up to 1.34× speedup with ClusterFusion++ compared to the baseline.
Output fidelity is preserved at a near-token-identical level (≈99.4–99.8% token match rate on WikiText-2), with only negligible non-deterministic differences, primarily attributed to the use of FP16 atomics during intra-cluster reductions. Perplexity evaluations remain unchanged, as the modifications exclusively affect the decode phase.
Ablation studies reveal important synergy: fusing an MLP kernel alone is suboptimal (0.75× PyTorch baseline), yet, when fused with attention and MLP-up, the throughput exceeds the attention-only path due to register reuse and amortized memory traffic/self-synchronization overhead. Hence, cross-operator kernel fusion yields amplified performance benefits compared to the sum of its isolated components.
Discussion and Implications
ClusterFusion++ establishes the technical feasibility and practicality of block-wide CUDA kernel fusion using DSMEM collectives. The demonstrated speedups, especially on top-of-the-line hardware, have immediate relevance in reducing inference latency for deployed LLM-serving systems, which translates to higher token throughput, lower time-to-first-token, and potentially reduced costs at scale.
The persisting near-deterministic output and unchanged perplexity metrics indicate that these system-level optimizations can be introduced into production settings without model retraining or fine-tuning. Furthermore, the architectural adaptability strategies outlined (e.g., non-power-of-two dhead, custom RoPE) are likely to generalize to other open-source and proprietary GPT variants.
Practically, the graph-based execution model developed here is orthogonal and complementary to operator fusion, suggesting that future work might further optimize autoregressive decoding by combining graph-level scheduling with advanced memory and operator fusion primitives. Additionally, the reduction of global memory bandwidth use and kernel dispatches can mitigate scaling bottlenecks seen when serving LLMs in high-concurrency contexts (e.g., via multi-process or multi-stream inference backends).
On a theoretical level, these system-level advances prompt reconsideration of optimal operator granularity for on-device neural network execution in scenarios with rapidly converging hardware/software interfaces.
Looking ahead, future research and engineering efforts may target:
- Extending full-block fusion to Transformer encoder-decoder architectures and vision Transformers.
- Hardware-aware auto-tuning for further performance gains on variable architectures and context lengths.
- Integration with quantization, sparsity, and low-rank adaptation techniques.
- Moving from PyTorch/HuggingFace baselines to further optimized, production-grade LLM inference frameworks with native cluster-centric kernels.
Conclusion
ClusterFusion++ delivers a comprehensive system-level contribution in efficient LLM decoding, demonstrating that full Transformer-block CUDA fusion—enabled by recent hardware features—yields robust throughput gains, reduced per-token latency, and maintains output fidelity for large-scale LLMs on modern NVIDIA GPUs. This approach is poised for further extension and integration into high-performance, low-latency inference deployments in real-world AI applications.