- The paper introduces a novel intrinsic reward technique by computing weighted centroids of high-entropy phases to select the most robust LLM responses.
- It employs percentile-based segmentation to isolate stable uncertainty units, achieving up to 5–10% absolute accuracy gains across diverse benchmarks.
- The approach eliminates dependency on external reward models, offering robust, hyperparameter-insensitive applicability for coding, reasoning, and agentic tasks.
Entropy Centroids as Intrinsic Rewards for Test-Time Scaling
Introduction
The paper "Entropy Centroids as Intrinsic Rewards for Test-Time Scaling" (2604.26173) introduces a novel methodology for best-of-N test-time prompting in LLMs, eliminating the dependency on external reward models. The central thesis is that temporal aggregation of high-entropy tokens—specifically, clustering these into High Entropy Phases (HEPs)—exposes the model’s inference uncertainty patterns beyond noisy token-level entropy signals. By computing the weighted centroid of HEPs within a generation trajectory, the method provides an intrinsic reward for selecting the highest-quality output among multiple sampled responses.

Figure 1: Overview of the Entropy Centroid framework; HEP segmentation and centroid computation filter noisy token-level entropy, enabling robust inference state representation.
High Entropy Phases (HEP): Stable Uncertainty Units
Token-level entropy is an unreliable proxy for model confidence due to its inherent volatility. The paper establishes HEPs as variable-length segments triggered when token entropy crosses a high threshold and ending upon encountering k consecutive low-entropy tokens. This segmentation is driven by percentile thresholds, ensuring adaptability across tasks, models, and varying entropy distributions. HEPs better capture contiguous uncertainty bursts associated with meaningful inference exploration or confusion, aggregating temporal uncertainty into interpretable structural units.
Entropy Centroid: Temporal Aggregation of Model Uncertainty
The entropy centroid is computed analogously to the center-of-mass in physics, aggregating the position (midpoint) and mass (length) of HEPs over the trajectory and normalizing by sequence length. Formally, for N HEPs with midpoints pn and masses mn, the centroid C is:
C=L⋅∑n=1Nmn∑n=1Nmn⋅pn
where L is the sequence length. Empirically, correct inference trajectories exhibit HEPs concentrated early (low centroid), indicating that initial exploration is followed by confident generation; incorrect trajectories show late HEPs (high centroid), often reflecting unresolved uncertainty or confusion.
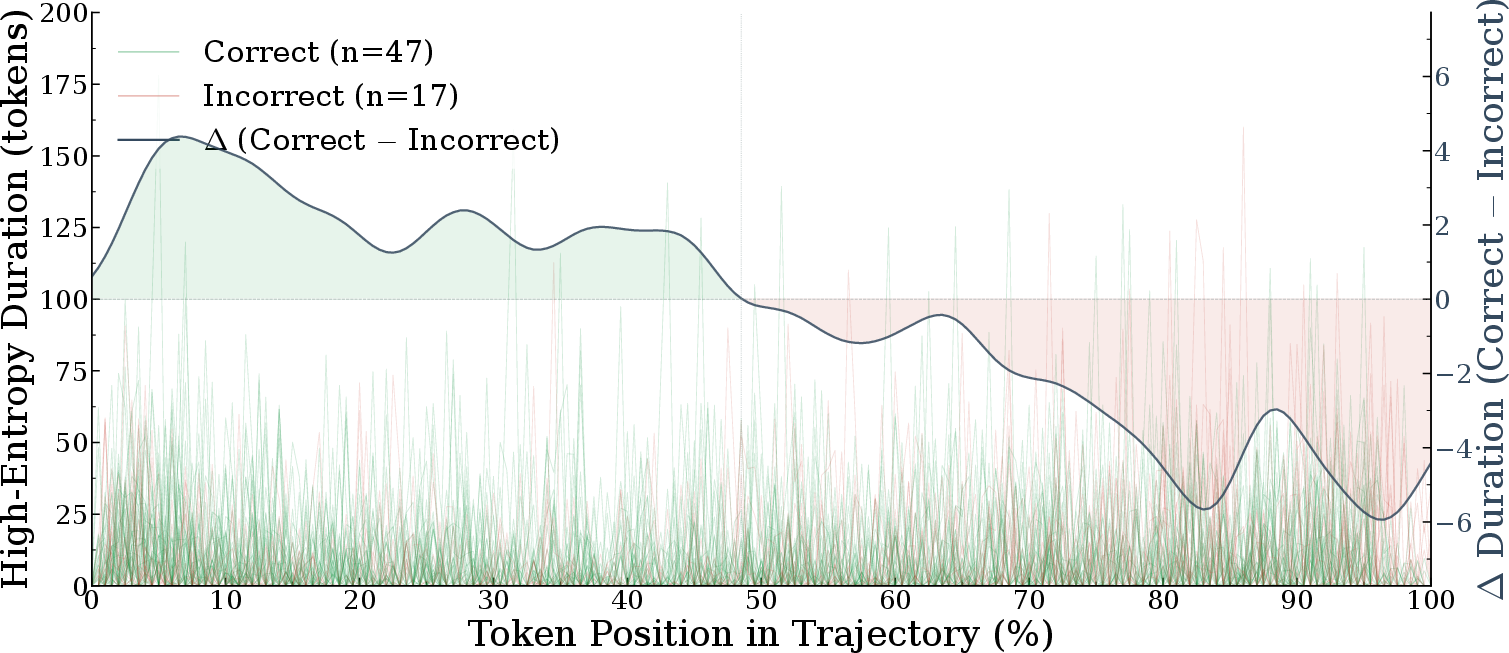
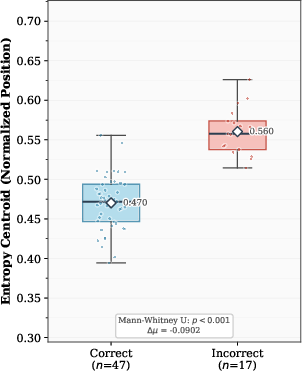
Figure 2: Correct trajectories show concentrated early HEPs (green curves and blue points, low centroid), whereas incorrect ones display late-stage uncertainty (red curves and points, high centroid), confirming centroid separation as a robust selection criterion.
Trajectory Selection via Lowest Entropy Centroid
In the test-time best-of-N scaling paradigm, the method selects the candidate response with the lowest entropy centroid, implicitly preferring early exploration and late certainty. Outlier filtering excludes abnormal or degenerate generations prior to selection. Unlike majority voting and confidence-based approaches, centroid selection functions robustly in settings lacking short, verifiable answers and generalizes to coding, agentic, logic, and math tasks.
Experimental Evaluation Across Diverse Domains
The paper benchmarks the entropy centroid strategy across a spectrum of LLMs from 14B to 480B parameters and datasets spanning mathematics (AIME 2025, Minerva), code generation (BigCodeBench, LiveCodeBench), logic (Synlogic), and agentic environments (τ2-Bench). For each problem instance, multiple trajectories are sampled (k0), and selection strategies are evaluated from a shared response cache to ensure consistency.
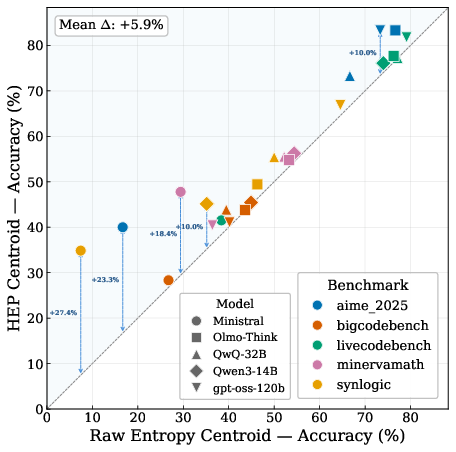
Figure 3: HEP-based centroid consistently outperforms raw entropy centroid across all model-dataset combinations, with average accuracy increase of +5.8%, highlighting effective noise reduction.
Strong numerical results are reported: entropy centroid delivers consistent improvements over intrinsic and external baselines, with mean gains reaching 5–10% absolute over Pass@1 and outperforming other test-time intrinsic reward methods (self-certainty, tail confidence, bottom-window) across all domains and scaling regimes. In agentic and reasoning benchmarks, centroid selection shows pronounced robustness—especially where token-level signals and majority voting fail.
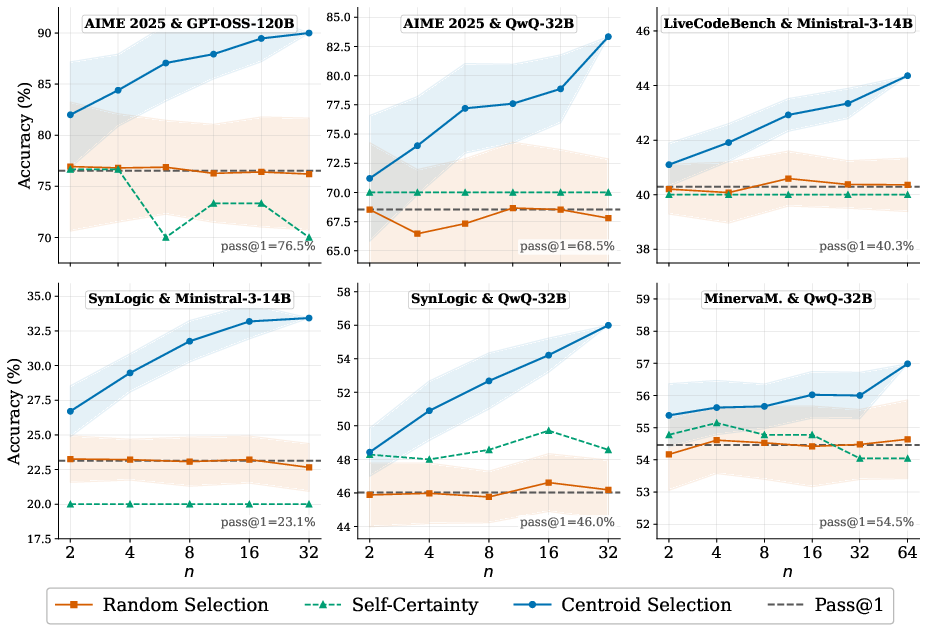
Figure 4: Accuracy scales monotonically with increasing sampled trajectories (k1), confirming stable cost-performance tradeoff and absence of early saturation for centroid selection.
Ablation and Robustness Analysis
Ablation studies demonstrate the superiority of HEP aggregation compared to raw entropy centroid computation, especially in low-accuracy regimes sensitive to local token noise. Hyperparameter robustness is established; the method’s performance remains invariant (<1% difference) under wide variation in entropy percentile thresholds and k2, confirming reliability across model architectures and generation lengths.
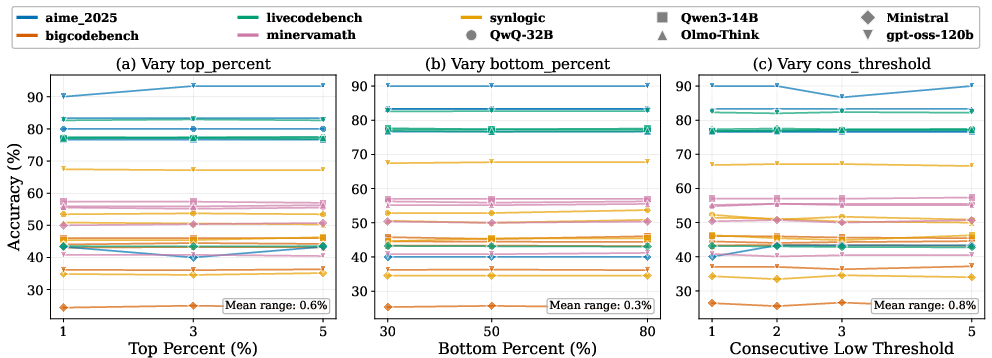
Figure 5: HEP performance maintains robustness across the top entropy threshold k3, bottom threshold k4, and consecutive low-token parameter k5; accuracy varies negligibly.
Case Studies: Trajectory Diagnostics
Case studies from code generation, mathematical reasoning, and logic inference tasks illustrate trajectory-specific centroid analysis. Correct solutions display low centroid values corresponding to early HEPs, whereas errors or degeneracies manifest as delayed HEPs and inflated centroid values. Visualizations underscore the diagnostic value of centroid-based selection beyond answer correctness aggregation.
(Figures 7–25)
Figure 6–13: Code trajectory examples, wrong with high centroid (Figures 7–9) and correct with low centroid (Figures 10–13); centroid separation mirrors actual generation quality.
Practical and Theoretical Implications
The entropy centroid provides a generic intrinsic reward signal applicable to any autoregressive LLM generation, independent of external reward models or post-hoc answer extraction. This method enables efficient test-time scaling—sampling and selecting high-quality responses—without extensive computation overhead. The approach is compatible with agentic, coding, and complex reasoning benchmarks currently unsupported by majority voting or confidence aggregation techniques.
Theoretical implications include reframing uncertainty modeling from token-level to temporally-aggregated structural phases, offering interpretable diagnostics and potential reward designs for RL fine-tuning and on-policy distillation. The method decouples reward signal fidelity from label or model-based evaluation, aligning closely with unsupervised self-improvement and continual learning paradigms.
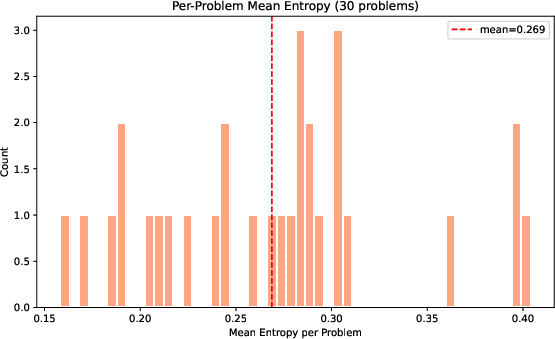
Figure 7: Problem-specific entropy distributions motivate percentile-based rather than absolute thresholds for HEP detection.
Future Directions
Potential future developments include integrating entropy centroid as an auxiliary reward during RL training or on-policy distillation, enabling model self-refinement and more expressive inference diagnostics. Extension to multi-turn dialogue or agentic workflows promises wider applicability, leveraging temporal inference state modeling for deeper interpretability and reward signal design.
Conclusion
The entropy centroid—computed from temporally clustered high-entropy segments in LLM trajectories—constitutes a robust, general-purpose intrinsic reward for trajectory selection at test time. By filtering token-level noise and encoding structural uncertainty, the method delivers consistent accuracy gains, hyperparameter robustness, and practical applicability across complex domains and scaling regimes. Its theoretical framework opens avenues for principled uncertainty modeling, reward design, and inference state analysis in LLMs.