- The paper introduces a novel trajectory-aware reward mechanism, ETR, that incentivizes early entropy reduction during chain-of-thought reasoning to enhance efficiency.
- The paper demonstrates that models incorporating ETR achieve significant reductions in reasoning trace length and up to +9.9% accuracy improvement across various benchmarks.
- The paper validates that a momentum-based, temporally aggregated entropy reduction approach outperforms traditional length-penalty and global entropy control methods in LLM reasoning.
Entropy Trend Reward (ETR) for Efficient Chain-of-Thought Reasoning
Introduction
The paper "ETR: Entropy Trend Reward for Efficient Chain-of-Thought Reasoning" (2604.05355) addresses the challenge of excessive, inefficient chain-of-thought (CoT) reasoning in contemporary LLMs. While CoT has demonstrably advanced model accuracy and interpretability in complex tasks, inference latency and redundancies stemming from prolonged, repetitive reasoning traces remain pervasive. The authors identify the inadequacy of existing length-penalty and global entropy reduction approaches, which are generally content-blind or fail to align with the inherent semantics of exploratory human reasoning trajectories.
Motivation and Empirical Observation
The central insight motivating this work is the empirical link between reasoning efficiency and the monotonicity of predictive uncertainty during CoT generation. Rather than minimizing entropy at every step, the authors observe that efficient chains exhibit entropy trajectories with coherent, global downward trends. Long, redundant CoTs are strongly associated with persistent or oscillatory entropy, particularly during self-reflection steps, as detailed in analyses using Spearman’s rank correlation between reasoning step indices and entropy values (Figure 1).

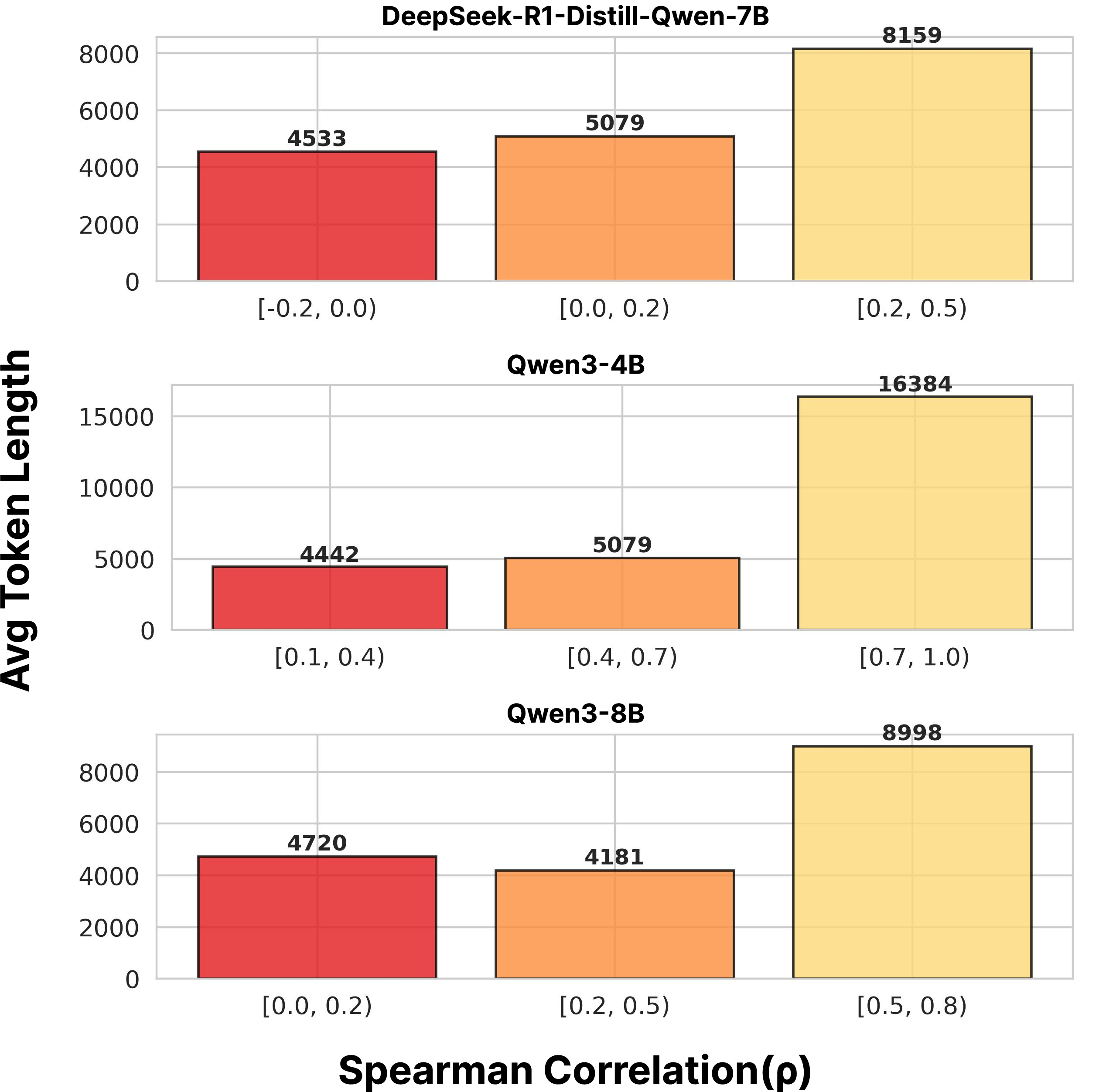
Figure 1: Step-wise entropy dynamics in generated CoTs on the MATH500 dataset. Left: Example with high entropy in self-reflective steps. Right: Positive correlation (persistent entropy growth) consistently relates to longer, more redundant outputs.
This observation falsifies the static “always-minimize-entropy” criterion: effective reasoning must allow early-stage exploratory uncertainty before a decisive convergence. The authors’ empirical analyses confirm that stricter global entropy descent correlates with shorter, more efficient chains.
ETR formalizes a trajectory-aware reward: it incentivizes progressive, momentum-aggregated reduction of step-wise entropy, granting richer feedback than coarse, endpoint-driven objectives. For a chain with steps {Ct}, the entropy at each step Ht is calculated from the model’s next-token predictive distribution. Step-wise changes Δt=Ht−1−Ht are accumulated via a momentum term:
St=γSt−1+Δt,S1=0,
Rentropy(o)=∑t=2TSt,
where γ is the temporal smoothing coefficient. This recursive accumulation ensures that entropy drops earlier in the chain yield greater reward—driving rapid uncertainty collapse and discouraging the deferred or repeated self-reflection characteristic of inefficient CoT traces.
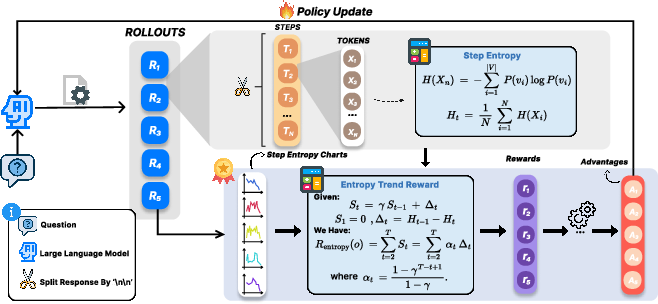
Figure 2: Overview of ETR in RL training—momentum-based aggregation of entropy changes, yielding a dense, trajectory-sensitive reward signal.
The weight coefficients αt decrease with t, as shown in Figure 3, rigorously prioritizing early convergence.
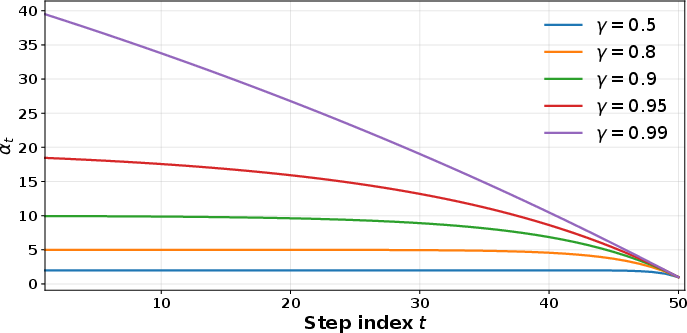
Figure 3: Cumulative momentum weights αt for different γ values, demonstrating emphasis on earlier uncertainty reductions.
ETR is integrated into Group Relative Policy Optimization (GRPO), employing a two-stage reward wherein correctness is a hard constraint and the entropy trend only shapes valid reasoning paths:
Ht0
Experimental Results
Experiments are conducted on both mathematical (AIME24, AMC23, MATH500) and general reasoning benchmarks (GPQA Diamond), with models including DeepSeek-R1-Distill-Qwen-7B, Qwen3-4B, and Qwen3-8B. The primary metrics are accuracy (Acc), response length (Len), compression rate (CR), and AES (accuracy-efficiency trade-off score).
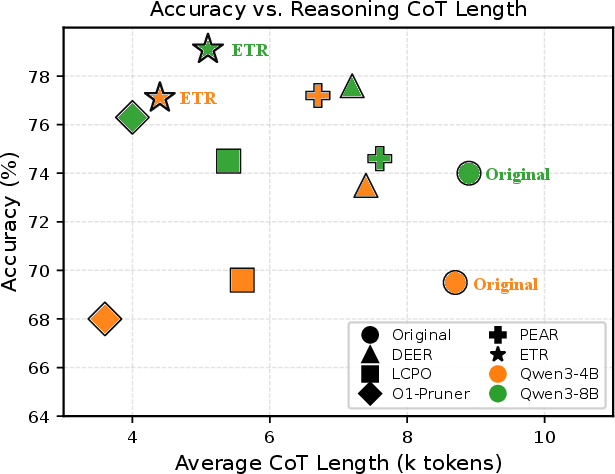
Figure 4: Accuracy vs. average CoT length across model sizes. ETR consistently achieves high accuracy at substantially reduced reasoning lengths compared to baseline and competing approaches.
Numerical results:
- ETR on DeepSeek-R1-Distill-7B achieves +9.9% accuracy and a 67% reduction in CoT length over four benchmarks relative to the original model baseline.
- On Qwen3-8B, ETR attains highest AES and reduces reasoning length by over 3x with no significant loss of accuracy.
NoThink and DEER exemplify the deficiencies of training-free truncation: either accuracy is sacrificed for brevity or compressibility is limited. Explicit length reward approaches (LCPO, O1-Pruner) and global entropy controls (PEAR) also exhibit diminished joint performance on accuracy and compression compared to ETR.
Empirical and Behavioral Analysis
Ablation studies demonstrate the superiority of momentum-based aggregation; naïve endpoint-difference rewards or removal of correctness constraints degrade performance and stability. Furthermore, ETR promotes globally convergent reasoning (Figure 5), suppressing entropy oscillations and ensuring logical trajectory alignment.
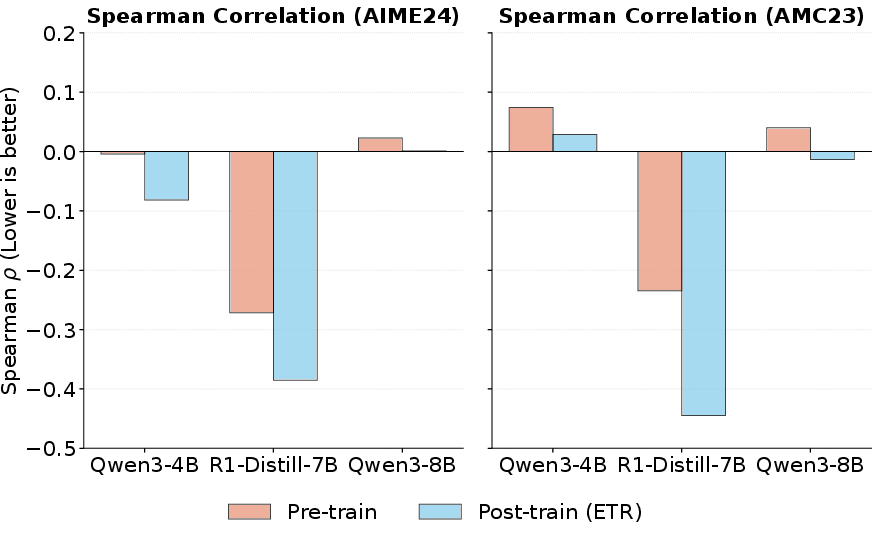
Figure 5: Spearman’s rank correlation between steps and entropy. ETR shifts values negative, denoting strong monotonic entropy descent.
ETR reduces verbosity by compacting per-step information rather than merely eliminating steps or reflection—retaining essential exploratory dynamics while suppressing repetitive, non-informative self-doubt (Figure 6).
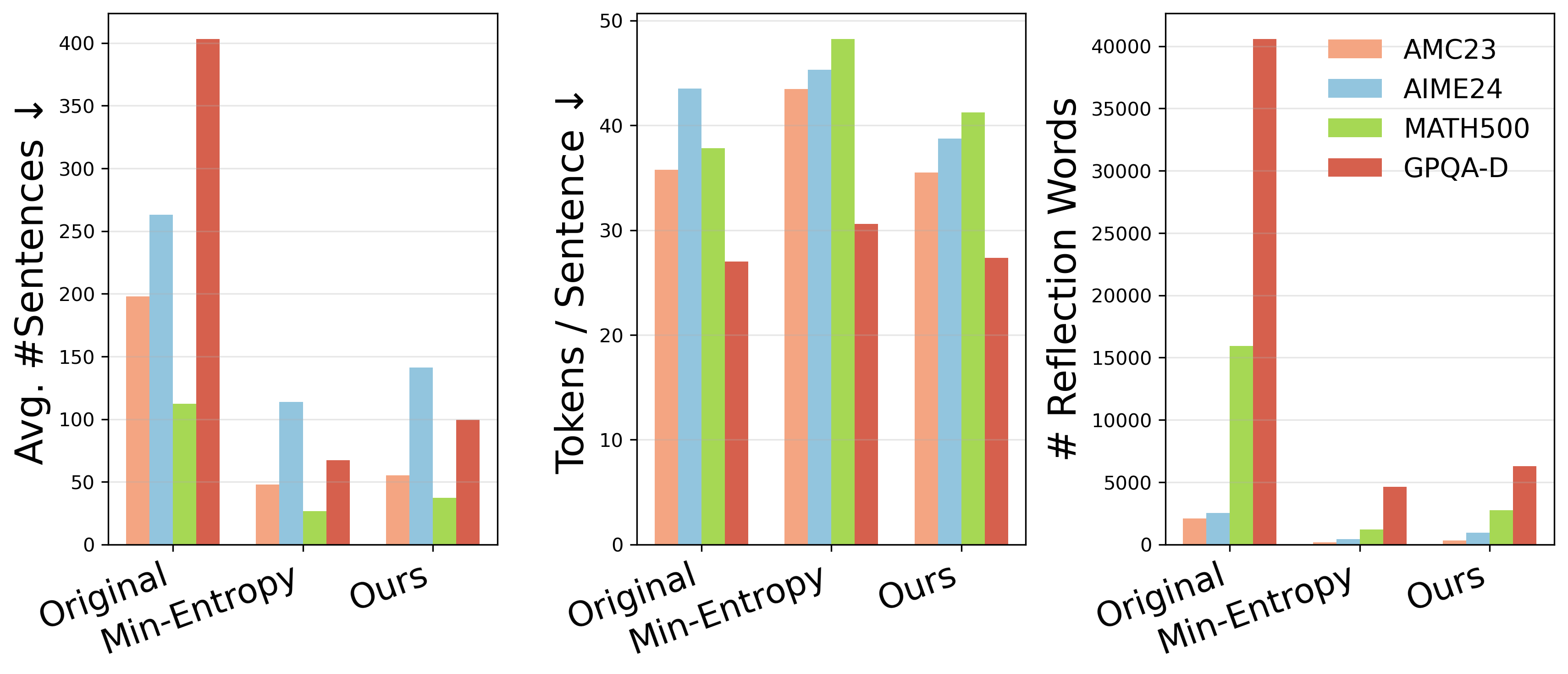
Figure 6: Behavioral decomposition shows ETR achieves compression via lower per-step verbosity, preserving self-verification capacity without excessive truncation.
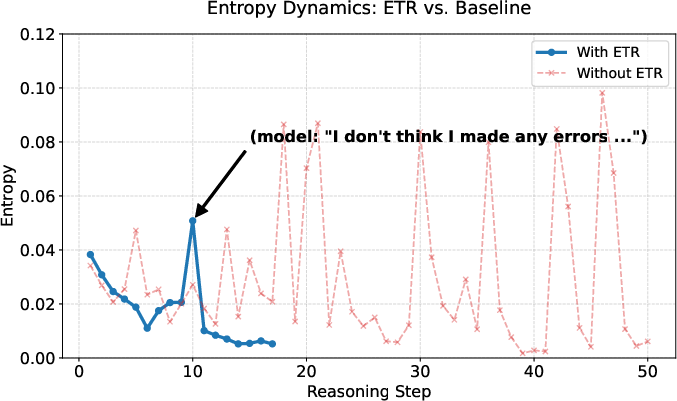
Figure 7: Entropy trajectories—ETR-trained models display monotonic, efficient convergence, while baselines show oscillations and redundancy.
Implications and Future Directions
On the theoretical level, this work extends the paradigm of reward design in RL for LLMs, demonstrating that trajectory sensitivity and temporally-structured signals produce markedly superior control over both logical efficiency and correctness. The method is agnostic to specific LLM architectures and demonstrates transfer to out-of-domain tasks (e.g., code generation) without further RL retraining.
In practical deployments, ETR enables scalable, efficient inference for advanced reasoning applications, substantially reducing computation cost and latency in production pipelines. By instantiating instance-adaptive early termination without hand-crafted length constraints, ETR supports more intelligent, user-responsive LLM behaviors.
Future research directions include scaling to larger models, tuning temporal aggregation schedules, and extending the entropy trend framework to multi-modal and open-ended reasoning scenarios. More refined aggregation strategies, hierarchical trend shaping, and integration with other alignment objectives are also promising avenues.
Conclusion
ETR introduces a principled, trajectory-aware reward for efficient chain-of-thought reasoning in LLMs, rectifying the limitations of static or content-blind compressibility constraints. It demonstrates robust empirical gains in accuracy-efficiency balance, scalable performance across model families, and transferability to non-mathematical domains. The framework represents a significant advancement in the formal control of LLM reasoning dynamics, with immediate applicability and broad implications for future AI system design.