- The paper introduces an empirical Q-function that certifies safe task execution by monitoring robustness in robot imitation learning.
- It employs dynamic, task-agnostic criteria—visibility, recognizability, and graspability—fused via WeightNet for adaptive reward modeling.
- Gradient-based recovery guided by energy shaping and Lipschitz constraints improves success rates from 20% to 100% in real robotic tasks.
TAIL-Safe: Task-Agnostic Safety Monitoring for Imitation Learning Policies
The TAIL-Safe framework directly addresses the persistent challenge of runtime safety in robot manipulation policies trained via imitation learning (IL), particularly visually guided methods such as flow-matching and diffusion-based policies. Despite high policy success rates in controlled training distributions, practical deployment faces policy failures due to sensitivity to initial conditions and compounded approximation errors. Traditional control-theoretic safety verification (e.g., barrier functions, reachability) is non-trivial in visuomotor IL due to high-dimensional observation spaces and unknown dynamics.
TAIL-Safe formalizes the guarantee of empirical task success assurance as a binary indicator based on training data. The policy is enabled not only to flag imminent failure but also to recover from unsafe or unknown state-action pairs. This is achieved by constructing a task-agnostic, empirically derived control invariant set—the safe set—governed by a learned Q-value function over state-action pairs.
Task-Agnostic Safety Criteria and Reward Modelling
TAIL-Safe operationalizes safety through three modular task-agnostic criteria for manipulation tasks: visibility (object within sensor FOV), recognizability (observation statistically close to training distribution), and graspability (high-quality geometric contact opportunities). Each criterion is quantified, and their fusion is learned contextually via WeightNet—a neural network that assigns dynamic importance to each criterion based on task phase. This approach avoids manual weighting and ensures the reward function R(s,a)=h(s,a) is appropriately sensitive for diverse manipulation scenarios.

Figure 1: WeightNet dynamically reweights visibility, recognizability, and graspability criteria along the manipulation task, leading to superior empirical accuracy.
Empirical Safe Set via Lipschitz-Continuous Q-Function
The Q-function Q(s,a) models the minimum safety margin along a trajectory, using a reach-avoid Bellman operator. Rather than maximizing cumulative reward, the Q-function propagates the minimum encountered safety score, making Q(s,a)≥0 an empirical certificate of safe task execution from that point onward.
To overcome the requirement for failure data and enable systematic exploration, TAIL-Safe uses high-fidelity Gaussian Splatting to build a digital twin of the real robot and workspace. This simulator produces both successful and failed trajectories by perturbing object positions, orientations, and injecting noise, without risk to hardware.
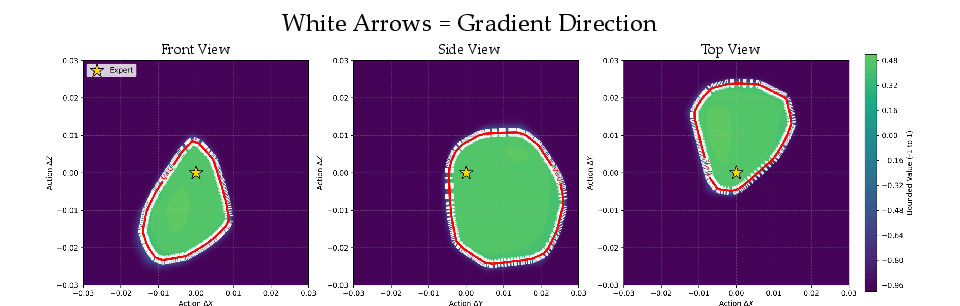
Figure 2: Multi-view projections illustrate the Q-function landscape and bounded safe set, with gradients pointing inward, facilitating recovery.
A significant technical consideration is shaping the Q-function so that its gradient is informative for recovery actions. Energy hill shaping ensures Q peaks at expert actions and decays smoothly, enforced via hinge loss and supervised sampling around successful actions. Spectral normalization maintains a bounded global Lipschitz constant, ensuring gradient stability and reliable convergence during recovery.
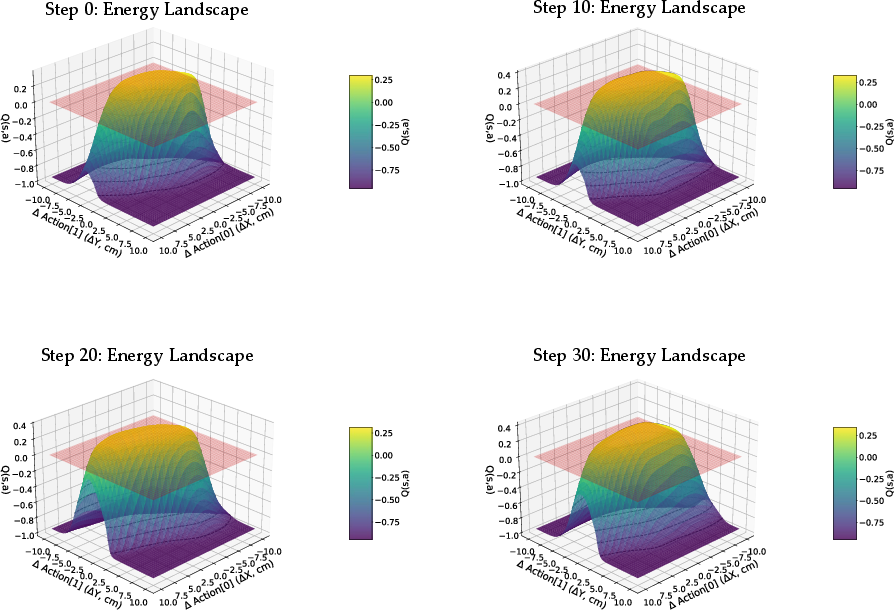
Figure 3: The Q-function landscape forms bounded hills around demonstrated actions, shaping recovery gradients toward safe regions.
Gradient-Based Recovery Controller
TAIL-Safe continuously monitors the proposed actions under the deployed policy. If an action is outside the empirical safe set (Q<0), a gradient-based projected ascent, inspired by Nagumo's tangentiality condition, steers the robot toward safe actions. The gradient ∇aQ is computed and applied iteratively until the action is certified as safe, or a maximum number of recovery steps is reached. Proposition 1, rooted in the Lipschitz constraint, guarantees predictable recovery progression.
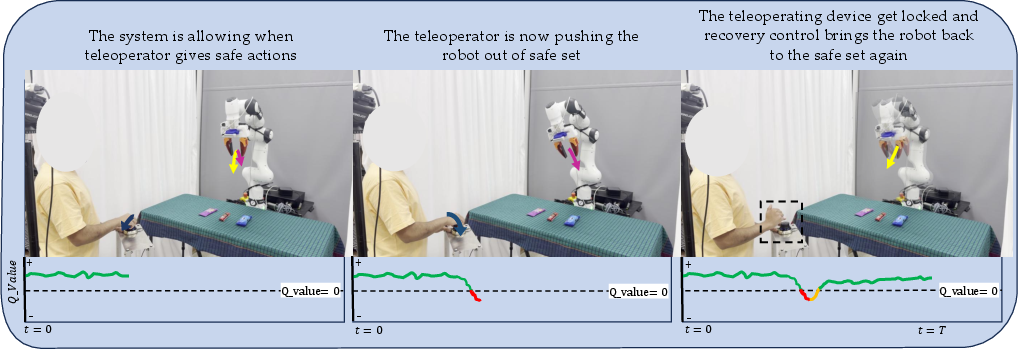
Figure 4: During teleoperation, TAIL-Safe locks the device and activates recovery when unsafe actions are detected, steering back to the empirical safe set.
Recovery efficiency is ensured by the energy-shaped Q-function's non-vanishing gradients at the boundary and by the context-aware reward fusions. Ablation studies show that Lipschitz and energy shaping jointly deliver strong gradient magnitudes and recovery stability, improving recovery success from 20% to 100% and reducing steps from 170 to 2.
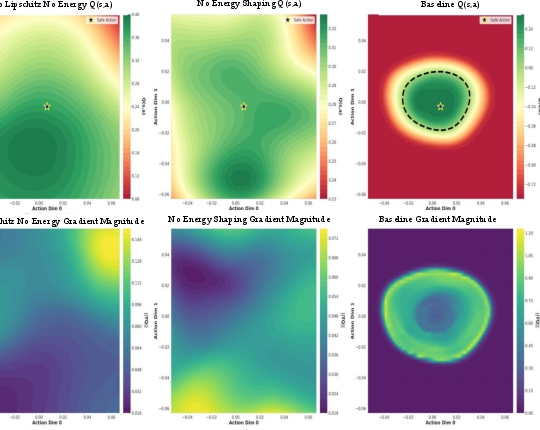
Figure 5: Q-landscape evolution with constraints: flat landscape (none), improved gradients (+Lipschitz), strong gradients at boundary (+Energy shaping).
Experimental Evaluation and Results
TAIL-Safe was evaluated on two real-world robot tasks: Candy Picking and Pick-and-Place. In both simulation and deployment on a Franka Emika robot, vanilla flow-matching policies achieved only 20–25% success under runtime perturbations, mostly failing due to drift, orientation errors, grasp failures, or selecting incorrect objects.
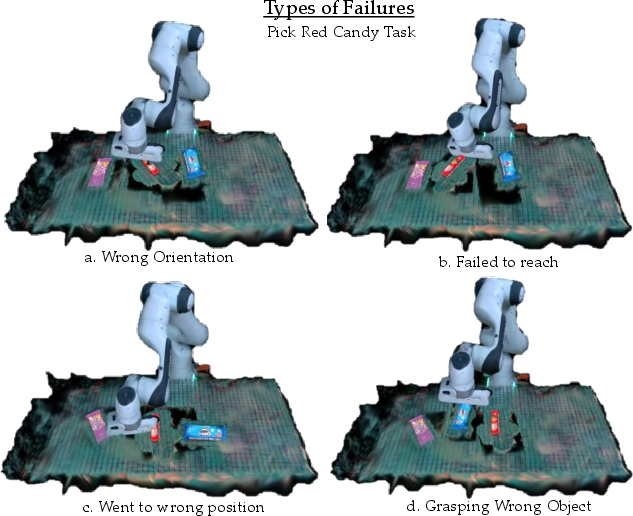
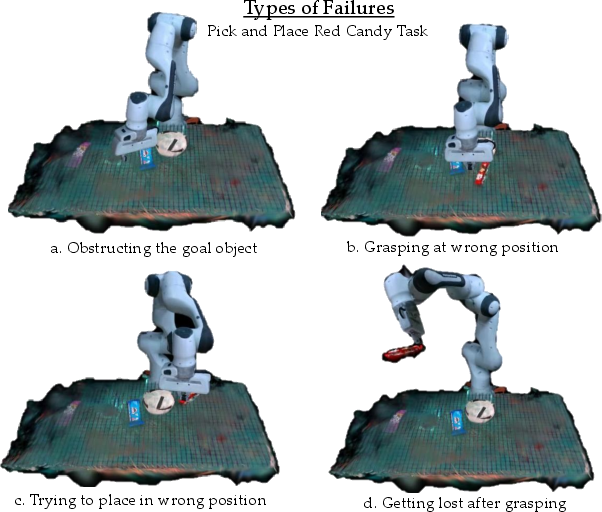
Figure 6: The vanilla policy's failure modes: incorrect grasp orientation, goal miss, translation error, and wrong selection.
When guided by TAIL-Safe, policies achieved consistent 100% success across all evaluation episodes, with reduced task length and fewer recoveries required. Empirical calibration demonstrates high discriminative power (AUROC 99.3%, AUPRC 99.7%, ECE 0.37).

Figure 7: Contrast between no recovery (persistent Q < 0 and task failure) and TAIL-Safe's gradient-based controller restoring safety.
Perturbation resilience is characterized through systematic experiments. TAIL-Safe reliably handles within-distribution object displacements, rotations, and proprioceptive perturbations, but encounters limitations under extreme out-of-distribution scenarios (e.g., excessive deviation, unseen object configurations), where the empirical safe set cannot be established.
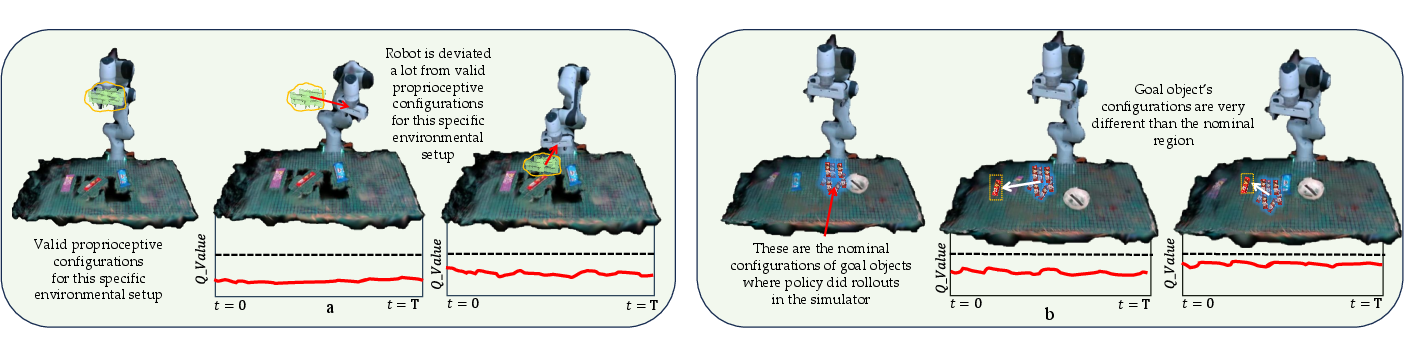
Figure 8: Illustration of extreme deviations (proprioceptive and object position) beyond TAIL-Safe's empirical reach.
Theoretical and Practical Implications
TAIL-Safe demonstrates that the empirical control invariant set, defined by a Lipschitz-continuous, energy-shaped Q-function, provides practical task success assurance for deterministic IL policies in high-dimensional visuomotor domains. While formal guarantees are inapplicable due to unknown dynamics and reliance on data-driven landscapes, the empirical certificate robustly covers the perturbation envelope seen during training and simulation.
The underlying modularity of criteria and context-adaptive reward fusion enables extensibility to diverse manipulation tasks, including those requiring task-specific safety measures. Energy shaping and Lipschitz enforcement are generalizable strategies for constructing recovery landscapes across latent and sensor-rich policy spaces. Practical deployment in field robotics benefits from the risk-avoiding data collection enabled by digital twins.
Limitations and Future Directions
Key limitations include the restriction to deterministic policies, fixed safe set boundaries, and reliance on digital twin fidelity for failure prediction. Extensions to stochastic policies will necessitate expectation over action distributions and possibly higher computational overhead. Broader real-world validation is warranted, especially in unstructured environments and under larger distributional shifts. Comparative benchmarking against latent barrier methods, uncertainty ensembles, and formal shield synthesis approaches will further contextualize TAIL-Safe's benefits.
Conclusion
TAIL-Safe delivers a principled empirical safety watchdog for robot IL policies, balancing task-agnostic modular criteria, context-aware fusion, Lipschitz-continuous Q-function landscapes, and gradient-based recovery. The substantial improvement in task success rate under challenging perturbations, without hardware risk or manual intervention, delineates a new standard for empirical deployment guarantees and recovery strategies in high-dimensional robotic manipulation. The framework's modularity and reliance on empirical data suggest substantial opportunities for adaptation to broader classes of policies and tasks.