- The paper introduces an execution guarantee by defining control-invariant safesets from demonstration data to ensure safe visuomotor policy performance.
- It employs a scalar safety function based on goal visibility and recognizability, using a QP-based recovery controller to maintain safe trajectories.
- Empirical evaluations in simulation and hardware demonstrate that the recovery mechanism sustains high success rates even under out-of-distribution conditions.
A Set-Theoretic Safety Framework for Visuomotor Imitation Learning Policies
Motivation: Safety in Field-Deployed Imitation Learning
While imitation learning (IL) enables flexible, user-driven skill acquisition in robotics, deployment in uncontrolled real-world settings has highlighted the necessity for safety guarantees beyond mere task success rates. Most existing IL approaches optimize for success on demonstration-like states, with little consideration for distributional shifts, partial observability, or unforeseen edge cases. The main challenge lies in providing rigorous, policy-agnostic definitions of safety for IL policies—particularly visuomotor policies that operate from raw sensor input—without access to privileged simulator information, expert handcrafting of constraints, or accurate dynamics models.
This work addresses these challenges by introducing a deployment-ready safety framework based on the concept of an execution guarantee: for a given IL policy, define and certify the largest region in the system’s state space (the control-invariant safeset) from which the policy is guaranteed to achieve its maximum attainable task success rate, even under minor runtime changes and perceptual noise. The core contributions are a task-agnostic definition of IL policy safety, a method for constructing and certifying this guarantee directly from demonstrations and policy-specific perception, and a recovery mechanism for runtime enforcement.
Execution Guarantee: Task-Agnostic Safety via Control-Invariant Safesets
The execution guarantee is formalized as follows. Given demonstration data D and a trained policy π, the safeset S is the largest region such that, for all initializations x(0)∈S, trajectories under π reach the goal set with the same high success rate observed during evaluation on in-distribution demonstrations. Critically, this region should be determined without reliance on explicit dynamics models or handcrafted state constraints, and instead grounded in the perceptual competence of the policy.
The central technical tool is the synthesis of a control-invariant set (CI set) using only the demonstration data and the perception module of the policy. The construction leverages Nagumo’s sub-tangentiality condition from set invariance theory, enabling provable enclosure of closed-loop trajectories within S by means of a minimal recovery controller. The CI set, by design, extends beyond the demonstration points to include all states from which the goal remains visible and recognizable by the policy, ensuring the policy remains in-distribution perceptually.
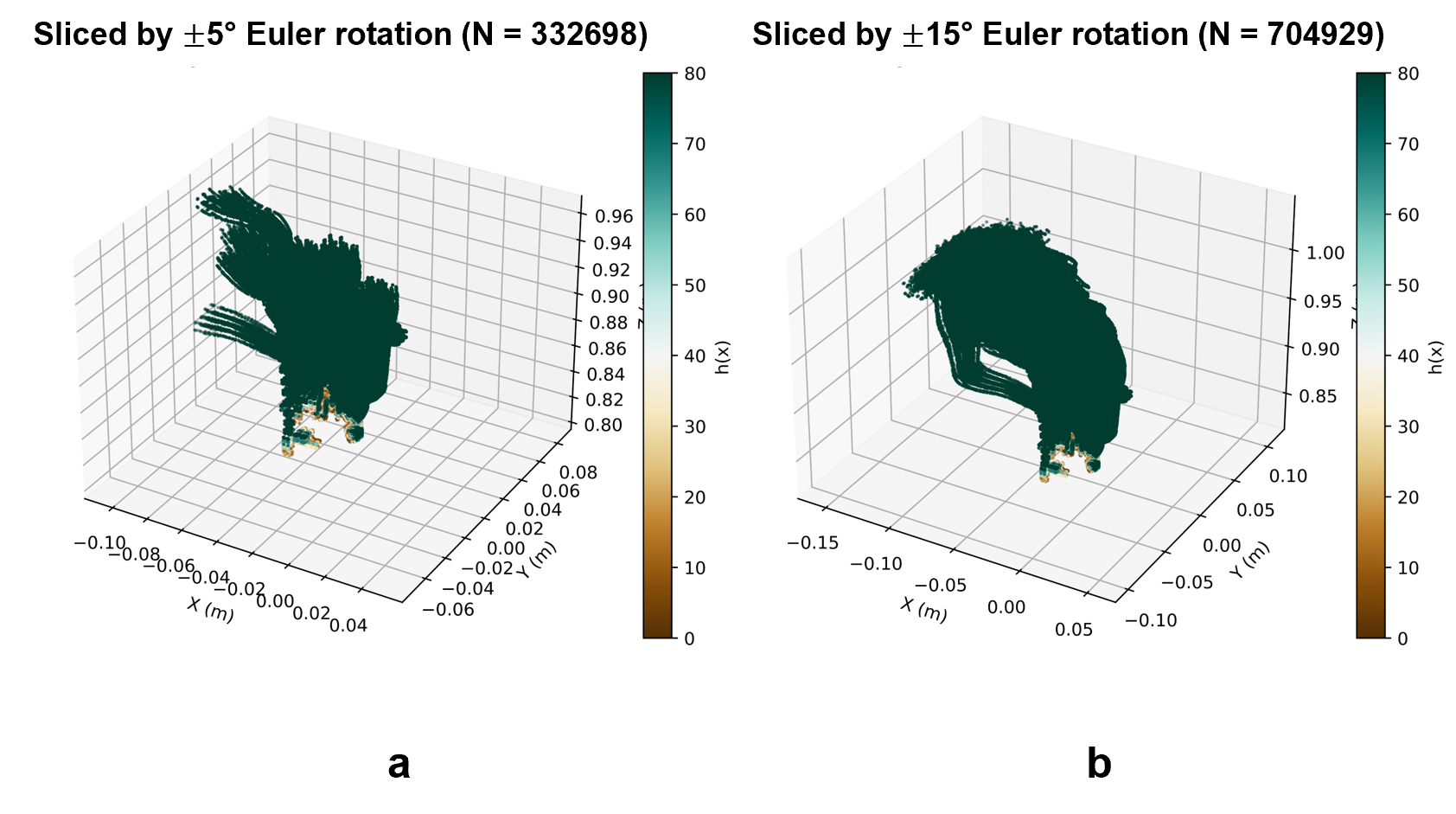
Figure 1: Construction of the control-invariant set S: zero super-level sets of h(x) at different rotational margins visualize progressively expanded safesets based on visual familiarity and goal visibility.
Methodology: Perceptual Safeset Construction and Recovery Control
Definition of the Safety Function
The safeset is specified as the zero-superlevel set of a scalar function h(x):
S={x∈Rnx∣h(x)≥0},
where π0 is positive if and only if:
- The task goal lies in the field of view (π1),
- The current observation from π2 is recognizable by the frozen visual encoder (π3).
The function π4 is shown to be Lipschitz continuous, enabling the application of set-theoretic control techniques.
Safeset Construction
Candidate states are generated by systematically perturbing demonstration trajectories in SE(3), locally exploring both translation and orientation, with denser samples near the goal. For each candidate state:
- The visibility score π5 is derived from camera geometry, providing a smooth estimate of goal visibility within the robot’s perceptual frustum.
- The recognizability score π6 is computed as the exponential of the (negative) Mahalanobis distance between the candidate’s view embedding and the demonstration distribution in the policy’s visual encoder space, using novel view synthesis for unseen poses (see Appendix for technical details).
The safeset boundary is then recovered as the union of states with π7, ensuring both perceptual confidence and task relevance.
Recovery Controller for Set Invariance
At runtime, if the nominal action π8 would drive the system outside π9, a recovery controller solves a quadratic program minimizing the action deviation subject to the Nagumo constraint at the safeset boundary:
S0
where S1. This intervention ensures the controlled trajectory remains within S2, preserving the execution guarantee with minimal disturbance to task objectives.
Simulation and Franka Emika Panda hardware experiments validated the framework across diffusion-based visuomotor policies (DP, CDP) and two manipulation tasks in both clean and cluttered environments. Three key findings are highlighted:
- Robust Success Rates with Recovery: In both simulation and real-world scenarios, enforcing the CI safeset via recovery controller maintained or increased task success rates, outperforming raw policies in cluttered and out-of-distribution (OOD) settings.
- High Out-of-Distribution Robustness: Under significant OOD perturbations (novel start states, distractor objects, or both), baseline policies exhibited sharp degradation, while recovery-enhanced variants consistently exhibited robust high performance.
- Practical Real-World Applicability: No retraining, system model, or manual constraint design was required—even in real-world deployment.
Qualitative results confirm that trajectories are safely contained within S3, with explicit avoidance of poorly defined or perceptually ambiguous states.
Theoretical and Practical Implications
The proposed framework demonstrates that robust, certifiable safety in IL is attainable by coupling perceptual safeset construction with set-invariance principles. The approach unifies elements from control theory (Nagumo’s condition, set invariance), modern deep visuomotor policy learning, and differentiable perception to produce a practically enforceable runtime safety filter.
Notable claims include:
- Demonstration-only, policy-agnostic construction of safesets is possible, with no dynamics or simulation access.
- Recovery projection yields performance exceeding nominal demonstration-aligned policy success rates, particularly under OOD disturbances.
- Policy safety and task efficiency are no longer strictly at odds—recovery extends the operational envelope without requiring conservative retraining.
By leveraging task-agnostic, perceptually defined safesets, the method generalizes across visual tasks and policy classes, provided the policy’s perception module remains accessible.
Limitations and Prospects for Future Research
The framework requires sufficient demonstration diversity to cover perceptually valid regions for each goal and assumes a static goal configuration. Extension to arbitrary, dynamic, or multi-goal tasks will demand generalized safeset definitions and adaptive perception models. The conservative nature of the QP-based recovery controller leaves room for learning-based or predictive control enhancements to avoid unnecessary interventions in tightly constrained scenes.
Potential extensions include:
- Integration with grasp feasibility and semantic constraints for more fine-grained task definitions.
- Automated demonstration collection strategies maximizing safeset coverage.
- Generalization to closed-loop, multi-agent, or high-DoF settings where the perceptual envelope is challenging to parameterize.
Conclusion
This work formally operationalizes policy safety in imitation learning by linking task success guarantees to the control-theoretic notion of set invariance in the perception space induced by the policy. By constructing control-invariant safesets using only demonstration data and frozen perception modules, and enforcing containment through an efficient recovery controller, strong safety and robustness properties are achieved for a range of visuomotor policies. The method’s practical, task-agnostic nature positions it as a promising foundation for verifiable IL policy deployment in the field, and motivates new research at the intersection of safety-critical control and representation-driven learning systems.

