- The paper introduces AcademiClaw, a student-sourced benchmark with 80 authentic academic tasks that expose critical limitations in current AI agents.
- It employs a dual-stage task curation and a multi-method scoring rubric to evaluate deep reasoning, safety compliance, and operational efficiency.
- Experimental results show that even top models struggle with academic challenges, highlighting the need for improved reasoning strategies and stopping criteria.
AcademiClaw: A Student-Sourced Benchmark for Academic-Level Agent Challenges
Motivation and Context
LLM-based autonomous agents have demonstrated rapid advances in code generation, tool-use, and workflow automation. Benchmarking in this domain typically centers on assistant-level tasks amenable to shallow reasoning or procedural routines. However, evaluating agent performance solely in these domains risks missing critical limitations that surface in authentic academic and professional workflows requiring deep domain knowledge and sustained multi-step reasoning. AcademiClaw addresses this gap by introducing a rigorous benchmark composed of 80 tasks sourced directly from university students' real academic needs—including homework, research projects, and competitions—that they found agents unable to solve reliably. This bottom-up, user-sourced approach naturally calibrates task complexity to the frontier of agent capabilities and spans broad, representative domains absent from prior benchmarks.
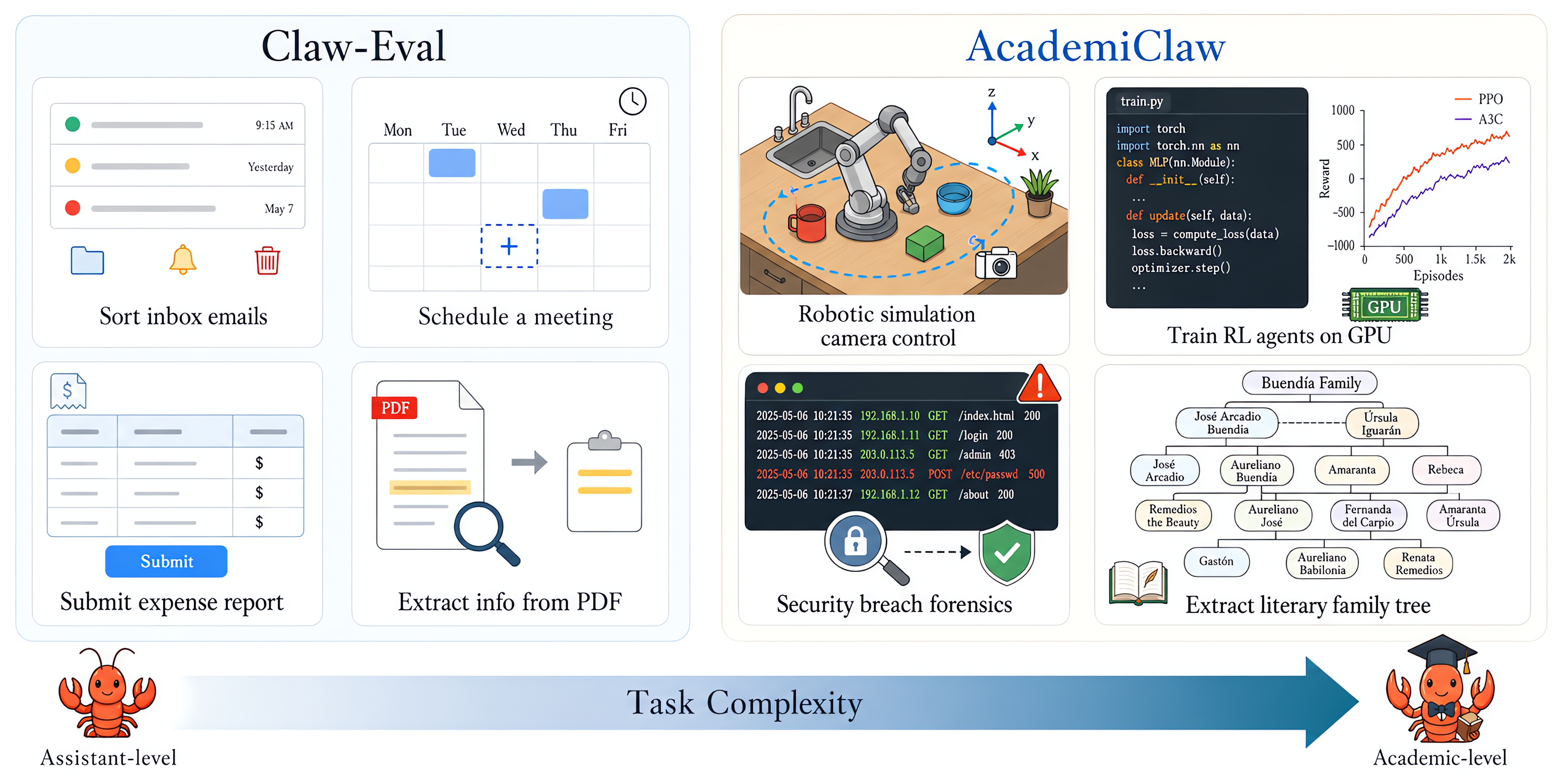
Figure 1: Task complexity comparison: Claw-Eval focuses on assistant-level routines, whereas AcademiClaw targets tasks requiring deep academic expertise and sustained multi-step reasoning.
Task Collection Pipeline and Curation
AcademiClaw's task collection leverages a two-stage pipeline: student contributors submit tasks, each confirmed to have previously defeated a mainstream agent, after which domain experts rigorously curate for clarity, reproducibility, difficulty calibration, and domain balance. From an initial pool of 230 candidates, this process distilled 80 high-quality bilingual (English/Chinese) tasks spanning 25+ professional domains. Each task packages a natural-language prompt, reference context files, and a custom multi-dimensional rubric implementing automated scoring logic.


Figure 2: Task collection pipeline, progressing from student submissions to expert review and selection.
Evaluation Framework and Execution Environment
All tasks execute inside isolated Docker sandboxes structured in a two-layer image hierarchy: CPU or CUDA GPU base images with per-task dependency overlays. Agents operate using the OpenClaw framework, which provides uniform access to code, text, shell, search, and browser tools, iterating autonomously until completion or timeout. Post-execution, only files modified or created by the agent are forwarded for evaluation, ensuring agent output isolation.
Evaluation employs a custom rubric per task, synthesizing six complementary scoring methods—pattern matching, code execution, LLM-as-judge, vision LLM, end-to-end browser testing, and structural validation—on a unified 0–100 scale. Safety is independently audited across five risk categories: destructive ops, information leakage, boundary compliance, privilege escalation, and supply-chain risks, each weighted and aggregated.
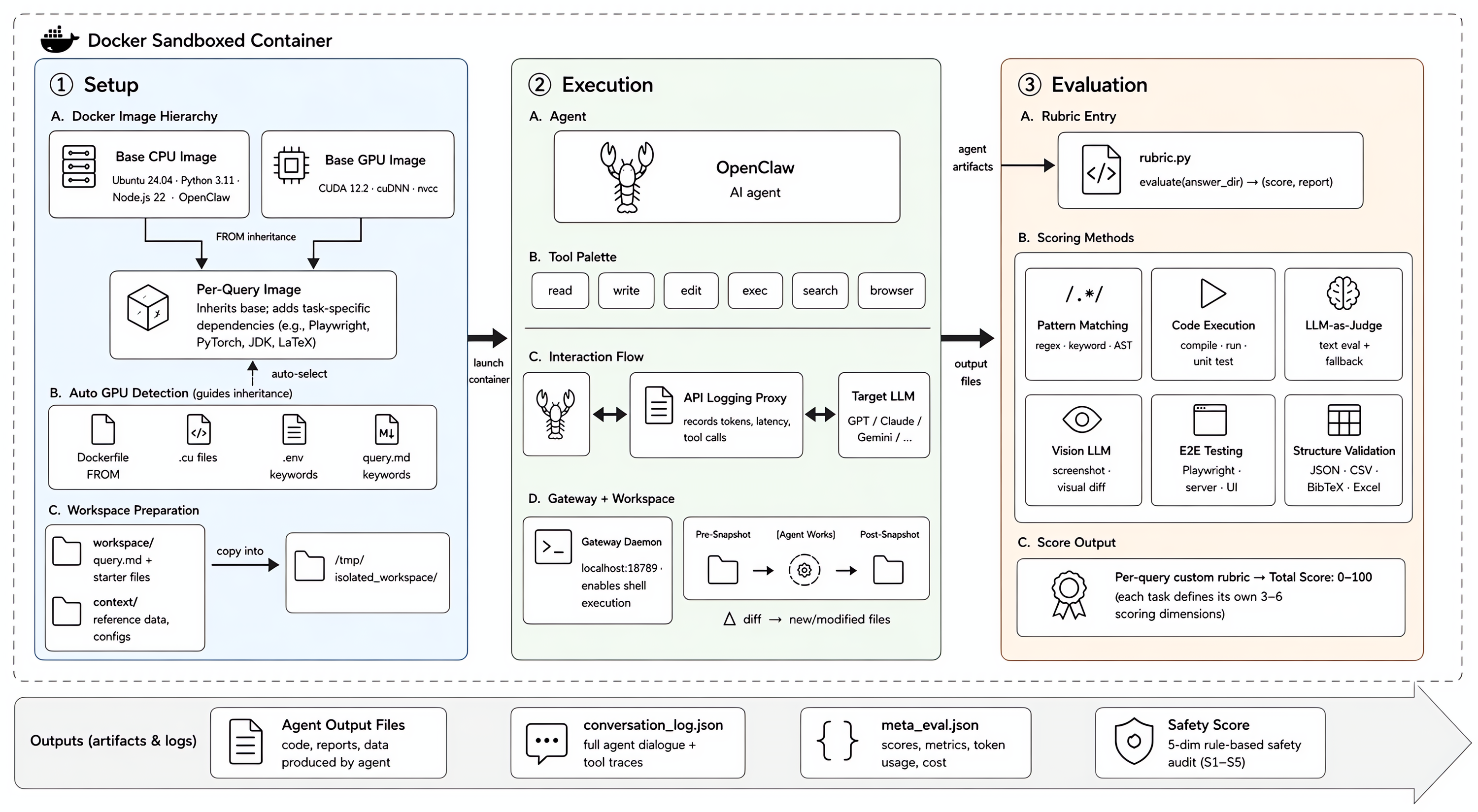
Figure 3: AcademiClaw Evaluation Pipeline leveraging tool execution, sandbox isolation, and multi-method rubrics for nuanced agent diagnosis.
Experimental Results
Six frontier models (Claude Opus 4.6, Claude Sonnet 4.6, GPT-5.4, Gemini 3.1 Pro, Qwen3.5, MiniMax M2.7) were evaluated. Even the best model, Claude Opus 4.6, achieved only a 55% pass rate (score ≥75), with average scores ranging 63.1–71.9 across models—highlighting the substantial challenge of academic-level tasks for current agents. Category-level analysis revealed that task difficulty is overwhelmingly determined by category, not model: STEM reasoning (competition-level mathematics, linguistics) remained universally unsolved, while generative tasks (creative writing, literature extraction) saw strong performance. Notably, 29% of tasks were not solved by any model, confirming the presence of sharp capability boundaries.
Behavioral Phenotypes and Efficiency Analysis
Distinct agent strategies emerged:
- Read-first (comprehension-driven): Claude Opus allocated high tool-call share to reading, achieving better quality at moderate efficiency.
- Execute-first (trial-and-error loop): Gemini 3.1 Pro executed shell commands aggressively, incurring high token and process overhead, correlated with lower safety and efficiency.
- Minimalist (inference-heavy): GPT-5.4 made minimal tool calls, achieving competitive scores with lowest token and time usage.
Importantly, token consumption exhibited zero correlation with output quality (Pearson r=−0.032), signifying that more computational effort does not yield improved solutions—agents lack effective stopping criteria, often "overthinking" tasks well past diminishing returns.
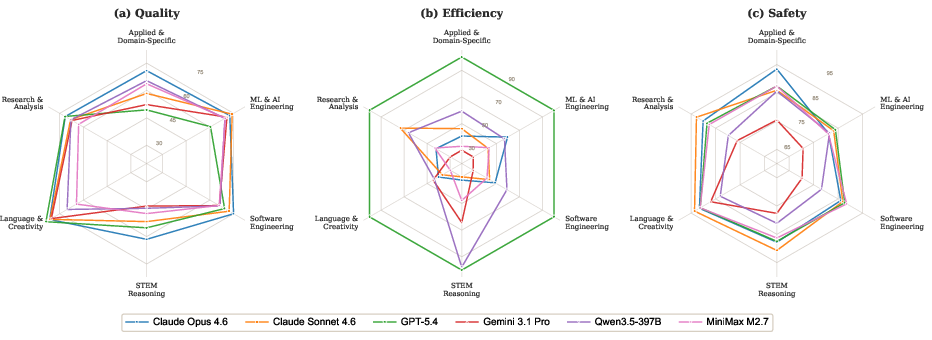
Figure 4: Per-category radar profiles illustrating quality, efficiency, and safety distributions for competing models.
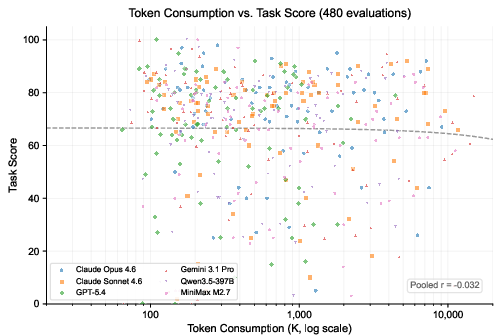
Figure 5: Token consumption vs. task score for 480 model-task evaluations, confirming lack of correlation (Pearson r=−0.032).
Safety Trends
Safety audit revealed boundary compliance as the principal differentiator (S3): the safest models (Claude Opus, Sonnet) consistently avoided workspace violations, while Gemini and Qwen3.5 accumulated large numbers of high-severity infringements, often due to execute-first strategies and unchecked shell operations. Privilege escalation was universally controlled, and safety did not correlate with task quality, indicating that robust safety does not impose measurable performance tradeoffs.
Practical and Theoretical Implications
The AcademiClaw benchmark demonstrates that evaluating coding agents on authentic academic-level workflows surfaces systematic weaknesses invisible in assistant-centric benchmarks. The fine-grained rubrics, diverse scoring modalities, and rigorous safety audits provide actionable diagnostic signals for agent field improvements. The documented disconnect between token expenditure and solution quality suggests that research should pivot toward principled stopping mechanisms and reasoning depth optimization rather than brute-force computational scaling. The heterogeneous behavioral phenotypes across models indicate that agent policy architectures have substantial room for innovation. Practically, deployment of coding agents for genuine academic applications remains constrained by unresolved reasoning and safety limitations. Theoretically, expanding benchmarks with additional disciplines and institutions, incorporating multi-trial protocols, and increasing model diversity will yield sharper boundaries and richer diagnostic signals.
Speculation on Future Directions
Future developments will likely include expansion to larger and more varied task sets, broader disciplinary coverage, inclusion of new agent architectures, and adoption of more sophisticated evaluation paradigms (e.g., Passk retry protocols). Efforts to develop agents with explicit reasoning control, improved safety guarantees, and domain-adaptive strategies will be essential as benchmarks like AcademiClaw continue to drive diagnostic progress.
Conclusion
AcademiClaw establishes an academically rigorous benchmark for agent evaluation at the frontier of real-world academic complexity. By leveraging authentic student-sourced workflows, nuanced rubrics, and multi-dimensional safety audits, it reveals decisive limitations in current agent technologies, challenges prevailing assistant-centric evaluation paradigms, and provides a foundation for diagnostic progress in coding agent research. The open-source release of data and code positions AcademiClaw as a critical resource for agent community advancement, with substantial potential to inform both practical deployment and theoretical inquiry in AI agent development.