Flow Sampling: Learning to Sample from Unnormalized Densities via Denoising Conditional Processes
Abstract: Sampling from unnormalized densities is analogous to the generative modeling problem, but the target distribution is defined by a known energy function instead of data samples. Because evaluating the energy function is often costly, a primary challenge is to learn an efficient sampler. We introduce Flow Sampling, a framework built on diffusion models and flow matching for the data-free setting. Our training objective is conditioned on a noise sample and regresses onto a denoising diffusion drift constructed from the energy function. In contrast, diffusion models' objective is conditioned on a data sample and regresses onto a noising diffusion drift. We utilize the interpolant process to minimize the number of energy function evaluations during training, resulting in an efficient and scalable method for sampling unnormalized densities. Furthermore, our formulation naturally extends to Riemannian manifolds, enabling diffusion-based sampling in geometries beyond Euclidean space. We derive a closed-form formula for the conditional drift on constant curvature manifolds, including hyperspheres and hyperbolic spaces. We evaluate Flow Sampling on synthetic energy benchmarks, small peptides, large-scale amortized molecular conformer generation, and distributions supported on the sphere, demonstrating strong empirical performance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper presents a new way to quickly generate random samples from complex probability distributions when you can measure how “good” a point is, but you don’t know the exact probabilities. Think of a landscape where low places are “better” (low energy) and high places are “worse” (high energy). You can measure the height and slope at any spot, but you don’t know how the whole landscape balances out overall. The authors’ method, called Flow Sampling, learns a fast sampler that can draw good, realistic samples from such landscapes—even in curved spaces like the surface of a sphere.
What questions are the authors asking?
- How can we train a fast, reusable sampler when we only have a “score” or “energy” function (which tells us the slope and height at a point), but no example data from the true distribution?
- Can we make this sampler efficient, so it doesn’t need to call the expensive energy function too many times?
- Can the same idea work not just in flat space (like ordinary 3D space) but also on curved spaces (like the surface of a sphere)?
- Does this approach actually work better or faster than existing methods on real problems, such as generating 3D shapes of molecules?
How does their method work?
The basic idea (diffusion and denoising, in plain words)
- Diffusion models imagine a process that starts with pure noise (like a totally blurry picture) and then gradually “denoises” it to form a clear, realistic sample.
- Traditional diffusion for data generation learns from example images or data. But here, we don’t have example data—we only have an energy function that tells us which points are more or less likely.
- Flow Sampling flips the usual setup: instead of conditioning on a real data point and learning how to add noise, it conditions on a noise point and learns how to remove noise in a way that matches the target distribution defined by the energy.
- To guide the denoising, it uses the slope of the energy landscape (the gradient). The slope points “downhill” toward more likely regions.
A time-saving trick: reuse one slope many times
Computing the slope of the energy (the gradient) is expensive. Flow Sampling cleverly reduces how often it needs to do this:
- It connects a starting noise point and a target-like point with a simple “straight” path over time (an interpolant). Along this path, the required guidance can be written in a closed form that reuses a single slope computed at the endpoint.
- In simple terms: you measure the slope once at the destination and reuse that information all along the path back in time, instead of recomputing the slope at many time steps.
A practical training loop (explore and learn)
Flow Sampling trains in two alternating phases:
- Exploration: Use the current model to generate candidate final samples and compute their energy slopes once. Store pairs of (sample, slope) in a replay buffer (like a notebook of useful results).
- Optimization: Repeatedly pick items from the buffer and train the model to match the “correct” denoising direction along the path between noise and those samples. This cuts down the number of expensive slope evaluations by a lot.
Works on curved spaces too
Many problems don’t live in flat space. For example, directions on Earth live on a sphere, not a plane. The authors extend their method to curved spaces (Riemannian manifolds), including:
- Spheres (like the surface of a globe).
- Hyperbolic spaces (another kind of curved space). They derive neat, closed-form formulas that make the same reuse trick work on these curved spaces, where “straight lines” are geodesics (the shortest paths on curved surfaces).
What did they find?
Across several tests, Flow Sampling was accurate and efficient:
- Synthetic physics benchmarks (like Lennard–Jones particle systems): It matched or beat other advanced samplers, especially in concentrating samples in low-energy (more likely) regions.
- Small biomolecules (peptides): It captured the correct range of backbone angles and multimodal structure (multiple valid shapes), with tighter, more realistic samples.
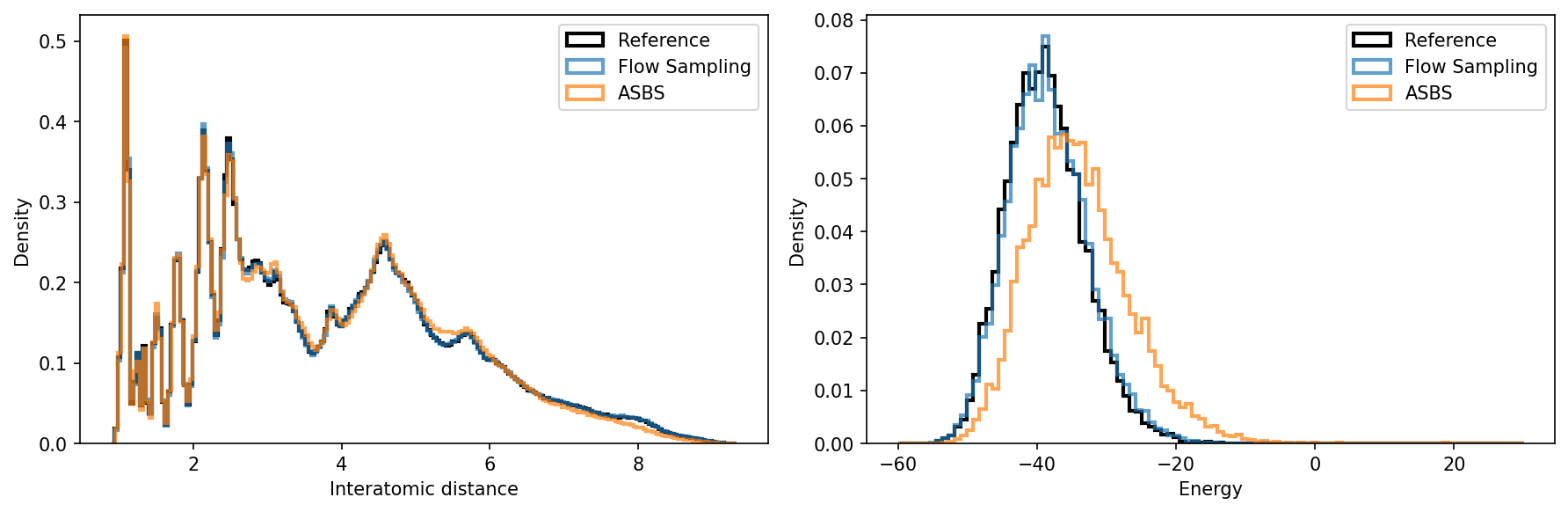
- Large-scale molecular conformer generation: It achieved strong coverage and quality, while reducing training cost. In some cases, it reduced simulation/training cost by 4–8 times compared to previous state-of-the-art methods.
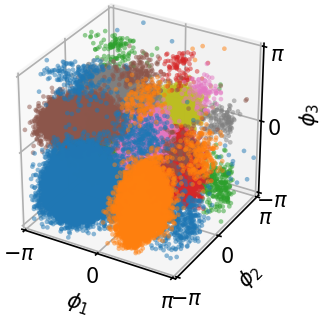
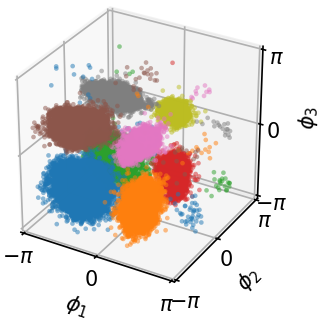
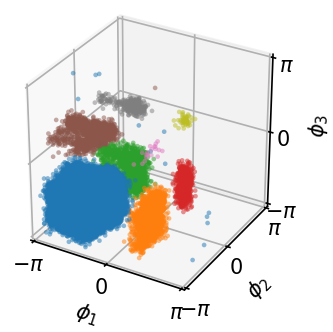
- Curved spaces (like the sphere): It became the first diffusion-based sampler that can learn from an unnormalized density on Riemannian manifolds, demonstrating successful sampling on spherical distributions.
Why this matters in practice:
- It produces high-quality, diverse samples in tough, high-dimensional problems.
- It needs far fewer energy evaluations, which are often the most time-consuming part.
- It generalizes beyond flat geometry, opening doors to problems defined on curved surfaces.
Why is this important?
- Faster design and discovery: Many scientific problems—like exploring possible shapes of molecules or materials—need lots of samples from complex energy landscapes. Flow Sampling can make this faster and more scalable.
- Reusable samplers (amortization): Once trained, the sampler can quickly generate many samples without running long, expensive simulations each time.
- Broader reach: By supporting curved spaces, the method applies to more real-world geometries (e.g., directions, rotations, and other structured domains).
- Strong empirical results: Its accuracy and efficiency suggest it can replace or complement traditional methods like MCMC in several settings, especially when time and compute are limited.
In short, Flow Sampling is a practical, efficient way to turn energy functions into fast, high-quality samplers—both in flat and curved spaces—making it a valuable tool for physics, chemistry, biology, and beyond.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or left unexplored in the paper, organized to guide future work:
- Convergence guarantees for the fixed-point training: establish conditions under which replacing the true target with model-generated in the Flow Sampling (FS) loss leads to convergence to , quantify fixed-point stability, and bound the bias due to off-policy/replay sampling.
- Bias/variance characterization of the FS estimator: analyze the statistical bias introduced by regressing onto computed using rather than , and how replay-buffer staleness affects estimator variance and training stability.
- Energy gradient requirements: explore robustness when is noisy, biased, or unavailable (black-box energies), and whether finite-difference approximations or learned surrogate gradients maintain performance with acceptable energy-evaluation cost.
- Hyperparameter sensitivity: systematically study the impact of the diffusion coefficient schedule (e.g., ), the scalar , and time-sampling strategies for on stability, sample quality, and energy-evaluation efficiency; provide selection guidelines.
- Choice of interpolant: evaluate alternative (nonlinear) schedules beyond the linear process and whether closed-form targets still exist or can be efficiently approximated; assess trade-offs with stability near .
- Source distribution dependence: quantify how the choice of affects convergence rate, mode coverage, and energy-efficiency, and provide practical recommendations (both in Euclidean and manifold settings).
- Exploration solver bias: examine how Euler–Maruyama discretization errors during the exploration phase (to obtain ) bias training; compare higher-order SDE solvers or variance-reduction techniques and their cost–benefit.
- Energy-evaluation accounting and wall-clock: report standardized counts of energy and gradient evaluations and training/inference wall-clock time against baselines (across all tasks), to substantiate the claimed 4–8× training-cost reduction.
- Exactness vs amortization: investigate whether FS can be paired with lightweight MCMC/importance-weighting post-corrections to yield asymptotically exact sampling while retaining amortization benefits, and quantify the residual bias without corrections.
- Scaling to extreme multimodality and dimensionality: stress-test FS on higher-dimensional, highly multimodal targets (beyond LJ-55), and characterize failure modes (e.g., rare-mode under-coverage) and remedies (e.g., curriculum schedules, tempered replay).
- Replay-buffer design: study buffer size, refresh frequency, prioritization (e.g., by energy), and off-policy correction; quantify how replay staleness and sampling policies affect convergence and sample quality.
- Robustness to poor initial models: characterize training dynamics when is initially far from ; assess the risk of collapse or bad fixed points and explore warm-starts, curriculum over , or annealing strategies.
- Theoretical link to optimal control/Schrödinger bridges: beyond the special Brownian-bridge case discussed in the appendix, generalize the relation between FS regression targets and optimal bridges; quantify the optimality gap and its practical implications.
- Observables and diagnostics: go beyond and torsion-angle KL/JSD by reporting expectation errors of physically relevant observables under , enabling more diagnostic assessment of sampler bias.
- General manifold support: the Riemannian extension is limited to constant-curvature manifolds with closed-form exp/log and parallel transport; extend to general manifolds (e.g., learned or triangulated surfaces) using retractions, numerical log/exp maps, or approximate Jacobians, and assess performance.
- Cut-locus and geodesic ambiguities: address numerical and theoretical issues at or near the cut locus (e.g., antipodal points on the sphere) where is multi-valued or ill-conditioned; propose robust implementations and quantify resulting errors.
- Manifold SDE correctness: clarify the correspondence between the projected Stratonovich SDE and the intended Laplace–Beltrami diffusion (Itô vs Stratonovich corrections) on hyperbolic/spherical spaces; provide derivations or experiments validating the Fokker–Planck form used.
- Computational complexity on manifolds: analyze the cost of evaluating the Jacobian determinants and parallel transport in high dimensions; validate that the “rank-1 composition” claim remains efficient at scale, and benchmark against alternatives.
- Empirical validation on manifolds: provide quantitative results (not just visuals) for manifold-supported targets (e.g., von Mises–Fisher mixtures on , hyperbolic distributions), including likelihood-free metrics and comparisons with Riemannian baselines.
- Source distribution on manifolds: specify and evaluate choices for on manifolds (e.g., uniform on , vMF), and their effect on training dynamics and coverage.
- Energy model fidelity in molecular tasks: assess sensitivity to inaccuracies in the learned force field (eSEN) by comparing to ab initio or higher-fidelity references; quantify FS performance when the energy model is misspecified.
- Equivariance and invariance handling: detail how translation/rotation invariances are enforced in the SDE and model beyond zero-COM projection; study whether rotational degrees introduce bias and if SE(3)-equivariant SDE designs improve results.
- Fixed-step vs adaptive-step training: explore adaptive NFE schedules and time-discretization during both exploration and training phases; report how NFE affects bias/variance and energy costs more systematically across tasks.
- Generalization across target families: in amortized settings, evaluate out-of-distribution generalization (e.g., to larger molecules, different chemistries, or new manifolds) and identify failure modes and transfer strategies.
- Discrete or mixed-variable targets: extend FS to settings with discrete or mixed discrete–continuous variables (e.g., combinatorial structures with continuous embeddings) and identify necessary modifications to the conditional drift/Interpolant framework.
- Uncertainty quantification and diagnostics: develop tools to quantify uncertainty in generated samples (e.g., through ensembles or posterior predictive checks) and to detect when the replay-buffer distribution diverges from .
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed using the paper’s methods with existing tooling and minimal additional research. Each item lists sectors, what to build or do, and key feasibility assumptions.
- Amortized molecular conformer generation at scale
- Sectors: healthcare, pharmaceuticals, chemicals, software (cheminformatics)
- What: Use Flow Sampling as a conformer engine to generate Boltzmann-weighted ensembles conditioned on molecular graphs, replacing or complementing ETKDG/RDKit or high-cost MD/MC. Integrate as an OpenMM/RDKit plugin and a callable microservice for virtual screening and docking pipelines.
- Why now: The paper demonstrates state-of-the-art coverage/accuracy on SPICE and GEOM-DRUGS with 4–8× fewer energy evaluations during training.
- Assumptions/dependencies: Differentiable force fields (e.g., eSEN or classical FF) and gradients; reliable graph-conditioned EGNN/PaiNN architectures; careful handling of constraints (e.g., bonds) if needed.
- Rapid exploration of peptide conformational space
- Sectors: healthcare, bioinformatics, academic chemistry
- What: Accelerate exploration of metastable states for small peptides (e.g., Ala2, Ala4) to generate torsion-angle distributions and ensembles for downstream docking, design, and MD seeding.
- Why now: Empirically recovers Ramachandran distributions closely to MD with improved stability at lower NFEs compared to prior baselines.
- Assumptions/dependencies: Access to energy and gradient via OpenMM or other engines; correct treatment of symmetries and restraints; validation against MD for safety-critical tasks.
- Materials design samplers for atomistic potentials
- Sectors: materials, energy, manufacturing
- What: Train amortized samplers for Lennard–Jones-like or learned interatomic potentials to quickly propose low-energy structures (e.g., clusters, adsorbates) across many target instances; embed into high-throughput discovery workflows.
- Why now: Superior performance on DW/LJ benchmarks; amortization reduces per-instance sampling cost.
- Assumptions/dependencies: Differentiable energies (classical or ML interatomic potentials); correct invariance handling (e.g., COM removal); validation against MCMC/MD for target classes.
- Bayesian posterior sampling with known log posteriors
- Sectors: finance, econometrics, ML/AI, social sciences (academia)
- What: Use Flow Sampling as a fast amortized sampler for posteriors defined by unnormalized log densities (likelihood + prior) with tractable gradients; deploy as a probabilistic programming backend to warm-start or replace MCMC in repeated analyses.
- Why now: Directly regresses on conditional drifts, reducing the number of costly model log-prob/gradient evaluations during training; reusable across similar datasets/hyperparameters.
- Assumptions/dependencies: Differentiable log posterior; support for continuous variables (discrete variables require relaxations/auxiliary methods); calibration checks remain necessary.
- Directional data and manifold-aware sampling (sphere)
- Sectors: robotics, computer vision/graphics, geoscience
- What: Sample from von Mises–Fisher mixtures and other spherical densities for surface normals, lighting directions, wind/current directions, and camera/attitude priors; provide a ROS2 package for S2 sampling and a vision library utility.
- Why now: Closed-form conditional drift on constant curvature manifolds enables efficient, principled diffusion on Sd; demonstrated on spherical distributions.
- Assumptions/dependencies: Tasks lie on constant-curvature manifolds (e.g., S2); accurate geodesic/exponential/log maps; integration with filtering/SLAM pipelines requires consistent units and covariances.
- Proposal distribution learning to accelerate MCMC/SMC
- Sectors: physics, climate, computational biology, statistics
- What: Train Flow Sampling models to act as high-quality proposals/warm starts, reducing burn-in and improving mixing in legacy MCMC pipelines; integrate as a preconditioner in Monte Carlo frameworks.
- Why now: The method learns drifts that approximate target conditionals while requiring fewer energy evaluations; proposals can be re-used across related targets.
- Assumptions/dependencies: Post-hoc diagnostics for bias/correctness; compatibility with target samplers (Metropolis-adjusted, tempered SMC, etc.).
- Reward-tilted sampling for offline RL and planning
- Sectors: robotics, operations research, recommender systems
- What: Treat reward as energy to sample high-reward state/action configurations (e.g., trajectory fragments, policy initialization pools) and improve dataset curation in offline RL.
- Why now: The framework regresses onto drifts constructed from reward gradients and supports replay buffers and fixed-point updates similar to off-policy training loops.
- Assumptions/dependencies: Differentiable reward or reward models; state spaces continuous or represented on manifolds; safety checks for real-world deployment.
- Probabilistic rendering and environment-light sampling
- Sectors: AR/VR, VFX, gaming
- What: Sample directional lights and BRDF lobes (vMF/vMF-mixtures) on S2 more robustly than hand-tuned samplers; integrate into path tracers to reduce variance in Monte Carlo integration.
- Why now: Closed-form spherical conditional drifts and efficient Euler–Maruyama on manifolds encourage plug-in samplers with fewer tuning knobs.
- Assumptions/dependencies: Availability of analytic/learned energy models over directions; careful stratification with existing multiple importance sampling.
- Hyperbolic and spherical embedding samplers
- Sectors: software, ads/recommendations, network science
- What: Sample from unnormalized densities over hyperbolic/spherical embeddings (e.g., hierarchical graphs) for uncertainty quantification, calibration, and synthetic data generation.
- Why now: The paper provides closed-form conditionals on constant-curvature manifolds, enabling practical diffusion-based samplers for these spaces.
- Assumptions/dependencies: Energy functions over embeddings are differentiable; scalability to large graphs handled via batching/sharding.
- Education and reproducible research kits
- Sectors: education, academia, open science
- What: Course modules/notebooks demonstrating flow vs diffusion matching, manifold diffusion, and replay-buffer efficiency; benchmark suites for energy-based sampling.
- Why now: Methods are simple to implement (linear schedules, closed-form conditionals) and illustrate modern sampler design beyond MCMC.
- Assumptions/dependencies: GPU access; openly licensed energies/benchmarks.
Long-Term Applications
The following applications are promising but likely require additional theory, engineering, or domain integration before deployment.
- Ab initio quantum chemistry samplers
- Sectors: pharmaceuticals, materials
- What: Train amortized samplers on high-accuracy DFT/CCSD(T) energies to explore PES with far fewer gradient calls, enabling structure enumeration and thermodynamics at higher fidelity.
- Why it’s long-term: Quantum gradients are extremely costly; would need multi-fidelity curricula, active learning, and robust error controls.
- Dependencies: Tight integration with quantum chemistry stacks (Psi4, Q-Chem); batching/HPC scheduling; error bounds and validation against reference thermochemistry.
- SO(3)/SE(3) manifold diffusion for rigid-body pose
- Sectors: robotics, autonomous systems, 3D vision
- What: Extend Flow Sampling’s manifold theory from constant-curvature spaces to Lie groups (SO(3), SE(3)) for pose estimation, motion planning, and uncertainty propagation.
- Why it’s long-term: Requires new closed-form conditionals or numerically stable approximations and careful discretization on groups.
- Dependencies: Efficient exponential/log maps, parallel transport, and Jacobians on Lie groups; integration into SLAM/filtering stacks.
- End-to-end, property-driven generative design
- Sectors: drug/materials discovery
- What: Close the loop between amortized sampling and ML surrogates for properties (ADMET, bandgap, conductivity), to sample from composite energies combining physics and property targets.
- Why it’s long-term: Composite energies may be non-convex/multimodal; requires robust multi-objective formulations and uncertainty-aware sampling.
- Dependencies: Reliable property predictors with gradients; safety and robustness validation; lab-in-the-loop optimization.
- Nationwide/HPC-scale “sampler services” for scientific computing
- Sectors: public research infrastructure, policy
- What: Provide shared services where users submit energy functions and receive trained amortized samplers, reducing redundant compute and democratizing access.
- Why it’s long-term: Requires security/multi-tenancy, standardized energy interfaces, and governance for compute and data.
- Dependencies: APIs/ABIs for energy/gradient provision; accounting and reproducibility frameworks; policy for energy budgets and environmental reporting.
- Probabilistic programming backends with amortized targets
- Sectors: ML/AI, finance, epidemiology
- What: Integrate Flow Sampling as a backend in Pyro/NumPyro/TFP to amortize repeated posterior queries (e.g., rolling forecasts, stress testing).
- Why it’s long-term: Needs model-aware controls for bias/coverage and automated diagnostics to satisfy scientific/regulated use.
- Dependencies: Differentiable log posteriors; calibration/coverage tests; fallbacks to exact MCMC for certification.
- Multi-scale and constraint-aware samplers
- Sectors: structural biology, soft matter, engineering
- What: Compose Flow Sampling with constraints (bonds, angles, volumes) and multi-resolution energies (coarse-grained ↔ all-atom) for efficient cross-scale exploration.
- Why it’s long-term: Requires principled handling of constraints on manifolds and stable refinement across scales.
- Dependencies: Constraint projection operators with gradients; hierarchical training curricula; consistency checks across resolutions.
- Safety-critical deployment in autonomy and healthcare
- Sectors: autonomous vehicles/robots, clinical decision support
- What: Use amortized samplers for uncertainty quantification in perception and decision-making with tight computational budgets.
- Why it’s long-term: Demands formal guarantees, robustness to distribution shift, and rigorous validation/audit trails.
- Dependencies: Runtime monitors, certified bounds, and fallback mechanisms; compliance with standards (e.g., ISO 26262, FDA guidance).
- Green AI policy and procurement standards
- Sectors: public policy, enterprise IT
- What: Codify “energy-evaluation budgets” and amortized-sampler reuse in grant/compute allocations to reduce emissions from scientific simulations.
- Why it’s long-term: Requires consensus on metrics, auditing, and incentives; cross-agency coordination.
- Dependencies: Tooling to track energy-evaluation counts; standardized reporting; buy-in from research agencies and cloud/HPC providers.
- Hyperbolic hierarchical modeling at web scale
- Sectors: recommendations, knowledge graphs, search
- What: Sample uncertainty over hierarchical embeddings in hyperbolic spaces for calibrated ranking and counterfactual testing.
- Why it’s long-term: Scaling manifold diffusion to billions of entities with tight latency constraints is nontrivial.
- Dependencies: Sharded training/inference; approximate neighbors/negative sampling; memory-efficient manifold ops.
Cross-cutting assumptions and dependencies
- Availability of energy functions and their gradients (exact or via autodiff); if gradients are unavailable, finite differences greatly increase cost and may negate efficiency gains.
- Continuous state spaces (or smooth manifold structure). Discrete or combinatorial domains require relaxations or hybrid methods.
- Numerical stability of Euler–Maruyama integration and schedule choices (e.g., diffusion coefficient γ); requires tuning and diagnostics.
- For manifold extensions, closed-form geodesic maps and Jacobians are currently provided for constant-curvature cases; broader manifolds need additional derivations or approximations.
- Validation against reference samplers (MCMC/MD) remains necessary in scientific and regulated domains to quantify bias and coverage.
Glossary
- Adjoint Sampling: A training framework for diffusion samplers that alternates exploration and optimization phases using adjoint-based objectives. "We use the same alternating scheme as Adjoint Sampling~\cite{AS}, which consists of two phases:"
- Amortized sampling: Learning reusable samplers that generalize across target instances, replacing long sequential simulations with learned dynamics. "This motivates the development of amortized sampling methods that replace long sequential simulations with learned sampling dynamics."
- Brownian motion: A fundamental stochastic process used as the noise term in stochastic differential equations. "where is the Brownian motion."
- Conditional Boltzmann distribution: A Boltzmann distribution conditioned on auxiliary variables (e.g., a molecular graph), typically scaled by temperature. "the target is a conditional Boltzmann distribution ,"
- Conditional drift: The drift field of a diffusion process defined under a conditioning (e.g., on an endpoint) to generate a specific conditional probability path. "The second, is defined by the conditional drift"
- Continuity equation: A partial differential equation expressing conservation of probability mass under a deterministic flow. "and it is given by the continuity equation,"
- Diffusion Matching (DM) objective: A regression objective that trains the drift by matching a conditional denoising diffusion drift. "This yields a diffusion matching (DM) objective"
- Diffusion process: A stochastic process governed by a drift and diffusion coefficient, typically formulated as a stochastic differential equation. "A diffusion process is defined by a drift $u:R^d\times[0,1]\tooR^d$, a diffusion coefficient $g_t:[0,1]\rightarrowR_{\ge0}$, and a boundary condition,"
- Euler–Maruyama algorithm: A numerical method for simulating stochastic differential equations. "using the Euler--Maruyama algorithm,"
- Fokker–Planck equation: A partial differential equation describing the time evolution of the probability density of a diffusion process. "The probability path of a diffusion process is given by the FokkerâPlanck equation,"
- Flow Matching (FM): A method for learning a velocity field so that a deterministic flow transports a source distribution to a target distribution. "the goal of flow matching (FM)~\citep{lipman2023flow,liu2023flow, albergo2023si} is to learn a velocity field "
- Geodesic interpolant: An interpolation along geodesics on a manifold, used to replace affine interpolants in non-Euclidean geometries. "we replace the affine interpolant with a geodesic interpolant,"
- Householder reflection: An orthogonal transformation that reflects vectors across a hyperplane; used here to express parallel transport on the sphere. "The parallel transport from to on the hyper-sphere is the Householder reflection about the midpoint ,"
- Hyperbolic spaces: Riemannian manifolds with constant negative curvature. "including hyperspheres and hyperbolic spaces."
- Hyper-sphere: A sphere in arbitrary dimension, a constant positive curvature manifold. "As an example, we consider the case of a hyper-sphere "
- Jacobi fields: Vector fields along geodesics that describe how nearby geodesics deviate; used to derive Jacobians of geodesic maps. "Its proof is based on results in Jacobi fields~\citep{lee2018introduction},"
- Jensen–Shannon divergence (JSD): A symmetric measure of similarity between probability distributions. "and the Jensen-Shannon divergence (JSD) of the 2D joint"
- Langevin dynamics: Stochastic dynamics combining gradient information with noise to sample from a target distribution. "including Langevin dynamics~\citep{roberts1996exponential, roberts1998optimal},"
- Markov chain Monte Carlo (MCMC): A class of algorithms that generate samples from a distribution via a Markov chain, typically with asymptotic guarantees. "Markov chain Monte Carlo (MCMC) methods~\citep{hastings1970monte, neal2001annealed},"
- Parallel transport: The operation that moves tangent vectors along a curve on a manifold while preserving inner products. "where $T_{X_1 X_t}:T_{X_1} T_{X_t} is the parallel transport,"</li> <li><strong>Push-forward formula</strong>: The transformation rule for probability densities under a mapping via the Jacobian determinant. "is the conditional probability path that is given by the push forward formula"</li> <li><strong>Ramachandran plots</strong>: 2D histograms of protein backbone dihedral angles used to assess conformational distributions. "Ala2 Ramachandran plots over $10^6$ samples."</li> <li><strong>Replay buffer</strong>: A memory storing past samples and associated statistics (e.g., scores) for reuse in training. "Off-policy variants~\citep{malkin2023trajectory, richterimproved} use trajectory-level objectives over a replay buffer"</li> <li><strong>Riemannian manifolds</strong>: Smooth manifolds equipped with a metric tensor, enabling geometric notions like distances, geodesics, and curvature. "extends to Riemannian manifolds,"</li> <li><strong>Schrödinger bridge</strong>: A stochastic optimal control formulation that interpolates between distributions via minimum entropy paths. "stochastic optimal control or Schr\"odinger bridge problems haved emerged."</li> <li><strong>Score function</strong>: The gradient of the log-density, providing directional information for sampling or training. "Given a score function of the target $\nabla\log q(x_1) = \nabla r(x_1)$,"</li> <li><strong>SLERP</strong>: Spherical linear interpolation; a standard way to interpolate between points on a sphere along a geodesic. "is the SLERP function,"</li> <li><strong>Stochastic optimal control</strong>: Optimization of control policies for stochastic dynamics to achieve objectives like matching target distributions. "stochastic optimal control or Schr\"odinger bridge problems haved emerged."</li> <li><strong>von Mises–Fisher distributions</strong>: Directional probability distributions on the sphere characterized by a mean direction and concentration parameter. "mixture of spherical von Mises--Fisher distributions."</li> <li><strong>Wasserstein-2 metric</strong>: A geometric optimal transport distance between probability distributions capturing displacement cost. "We report a geometric $\mathcal{W}_2$ metric~\citet{klein2024equivariant}"
Collections
Sign up for free to add this paper to one or more collections.

