Continuous Latent Diffusion Language Model
Abstract: LLMs have achieved remarkable success under the autoregressive paradigm, yet high-quality text generation need not be tied to a fixed left-to-right order. Existing alternatives still struggle to jointly achieve generation efficiency, scalable representation learning, and effective global semantic modeling. We propose Cola DLM, a hierarchical latent diffusion LLM that frames text generation through hierarchical information decomposition. Cola DLM first learns a stable text-to-latent mapping with a Text VAE, then models a global semantic prior in continuous latent space with a block-causal DiT, and finally generates text through conditional decoding. From a unified Markov-path perspective, its diffusion process performs latent prior transport rather than token-level observation recovery, thereby separating global semantic organization from local textual realization. This design yields a more flexible non-autoregressive inductive bias, supports semantic compression and prior fitting in continuous space, and naturally extends to other continuous modalities. Through experiments spanning 4 research questions, 8 benchmarks, strictly matched ~2B-parameter autoregressive and LLaDA baselines, and scaling curves up to about 2000 EFLOPs, we identify an effective overall configuration of Cola DLM and verify its strong scaling behavior for text generation. Taken together, the results establish hierarchical continuous latent prior modeling as a principled alternative to strictly token-level language modeling, where generation quality and scaling behavior may better reflect model capability than likelihood, while also suggesting a concrete path toward unified modeling across discrete text and continuous modalities.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Imagine writing a story. You can either write it word by word from left to right, or first sketch a clear outline and then fill in the sentences. Most LLMs today write one token at a time, strictly left to right. This paper introduces a different approach, called CoLa (Continuous Latent Diffusion LLM). CoLa first plans the overall idea in a smooth “idea space,” and only then turns that plan into words. The goal is to make text generation more flexible, faster in parts, and better at capturing big-picture meaning.
What questions the authors wanted to answer
- Can we separate “global meaning” (the gist of what to say) from “local wording” (the exact tokens)?
- Is it better to plan in a continuous space (like a sketch) before writing text?
- Can a diffusion process (which gradually shapes randomness into structure) model those global ideas effectively?
- Will this new setup scale well with more compute and compete with strong, similarly sized baselines?
How their method works (in simple terms)
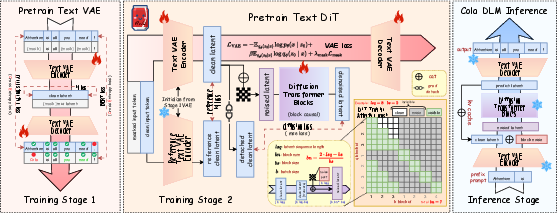
Think of CoLa as a three-step writing process that splits “what to say” from “how to say it.”
Step 1: Learn a secret code for text (Text VAE)
- The model learns to convert text into a compact, continuous “idea vector” (a hidden code) and back again.
- Encoder: turns words into an “idea vector.”
- Decoder: turns the “idea vector” back into words.
- Why do this? It creates a stable bridge between messy text and a smoother space where meaning can be stored more compactly.
Step 2: Learn how ideas usually look (Latent diffusion “prior” with block-causal DiT)
- CoLa learns a “prior,” which is a model of what good “idea vectors” tend to look like across many texts.
- It uses a diffusion-like process: start from noise and gradually shape it into a coherent idea.
- “Block-causal” means it divides the idea into chunks (blocks). It respects order across blocks (so future depends on past), but can think in parallel within each block. That helps with speed and flexibility.
Step 3: Turn ideas back into words (Conditional decoding)
- At generation time, if you give a prompt, CoLa encodes the prompt into the idea space.
- It then grows new idea blocks based on the prompt, transforming noise into a planned idea.
- Finally, it decodes that plan into fluent text.
How this differs from the usual left-to-right approach
- Typical models predict the next word, then the next, and so on, which ties them to a single strict order.
- CoLa first models the big-picture meaning in a continuous space, then writes. This can ease long-range planning, reduce the “one-order-only” bias, and make parts of generation more parallel.
What they found and why it matters
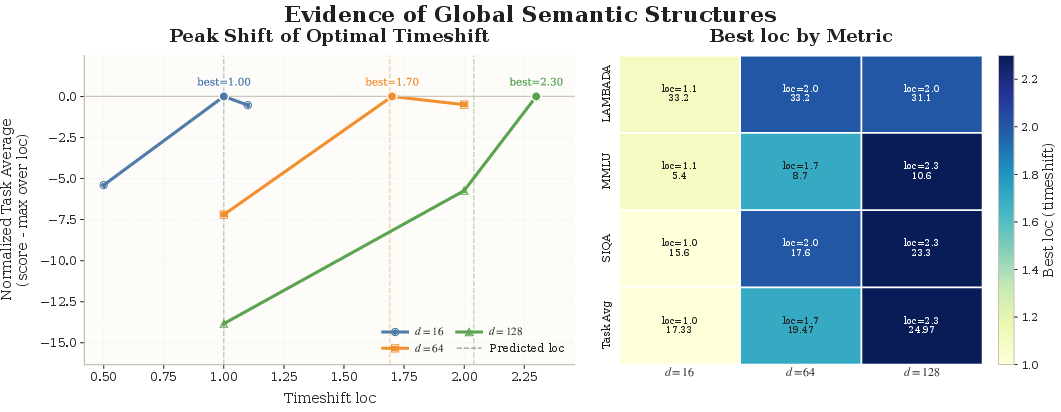
- Evidence of real “global meaning” in the idea space:
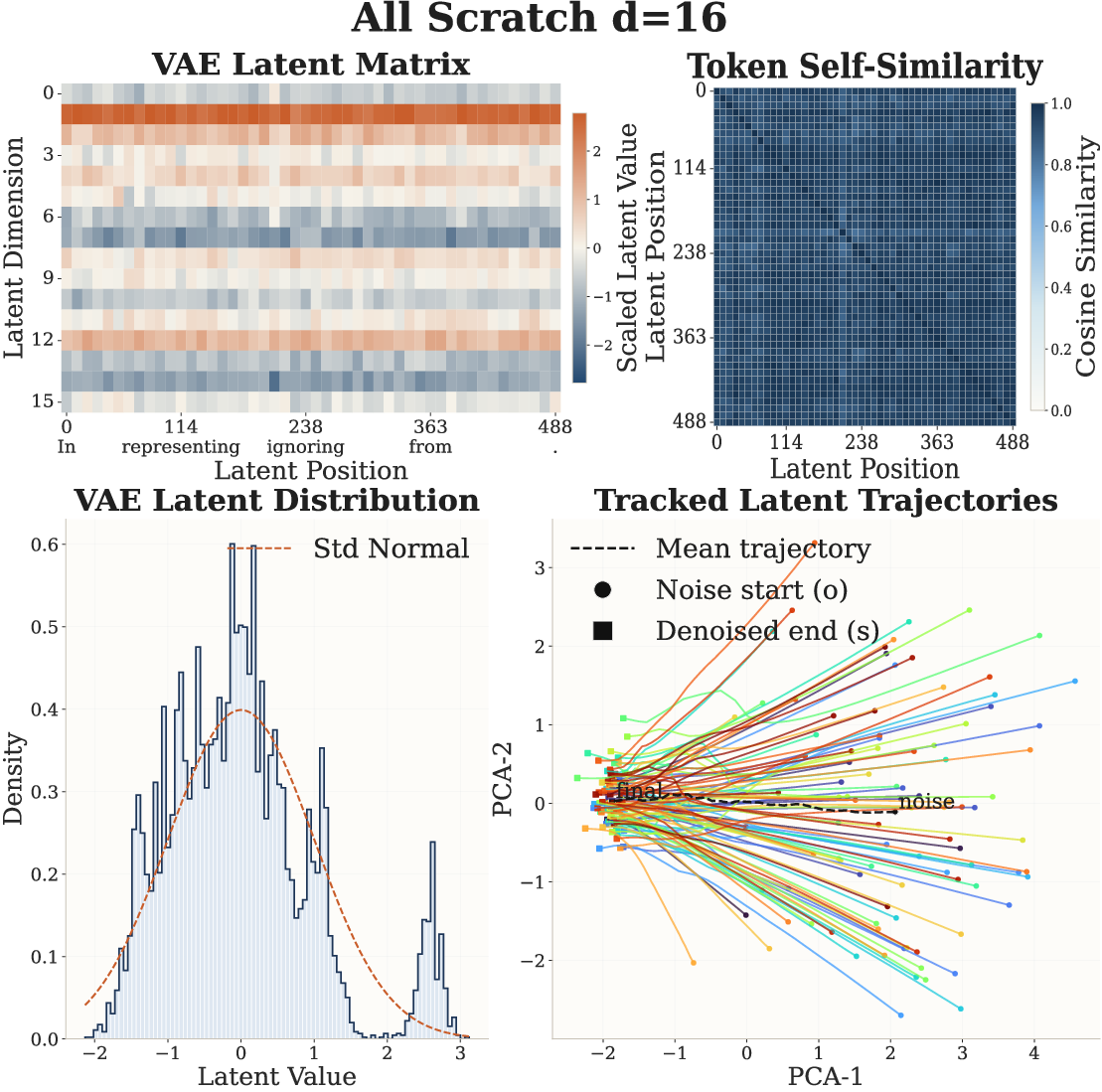
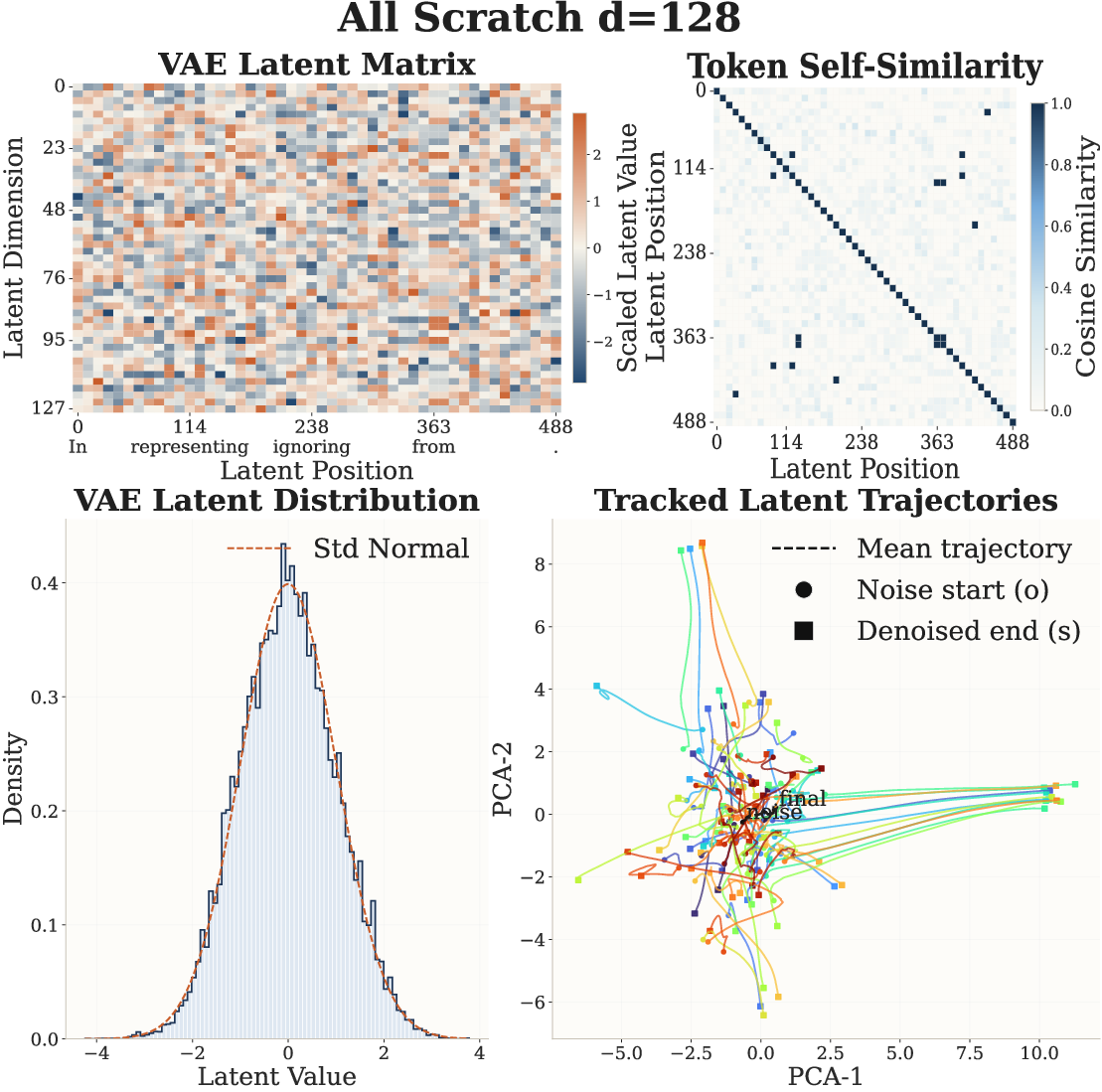
- When they changed the size of the idea vector, the best settings for the diffusion process shifted in a predictable way across several tasks. This suggests the model’s hidden space truly captures high-level meaning shared across tasks, not just surface wording.
- The latent (idea) space works best when it’s trained in two stages and allowed to evolve:
- First, pretrain a stable text-to-idea mapping (so the code is meaningful).
- Then, jointly train the idea prior (diffusion) and keep adjusting the mapping gently. Fixing the code forever hurts; learning everything from scratch can be unstable. A balanced, guided co-training works best.
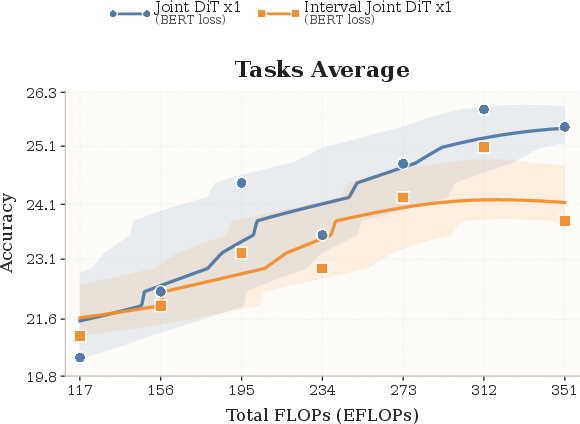
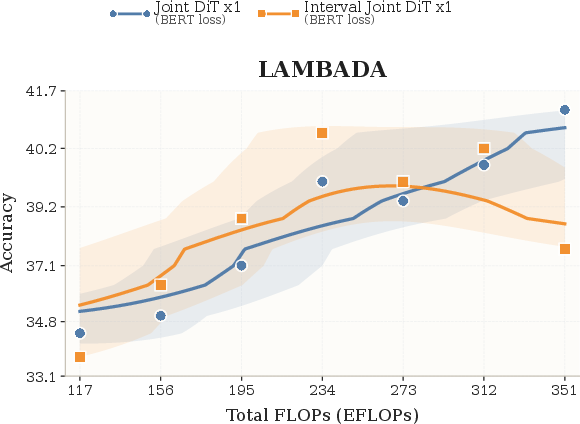
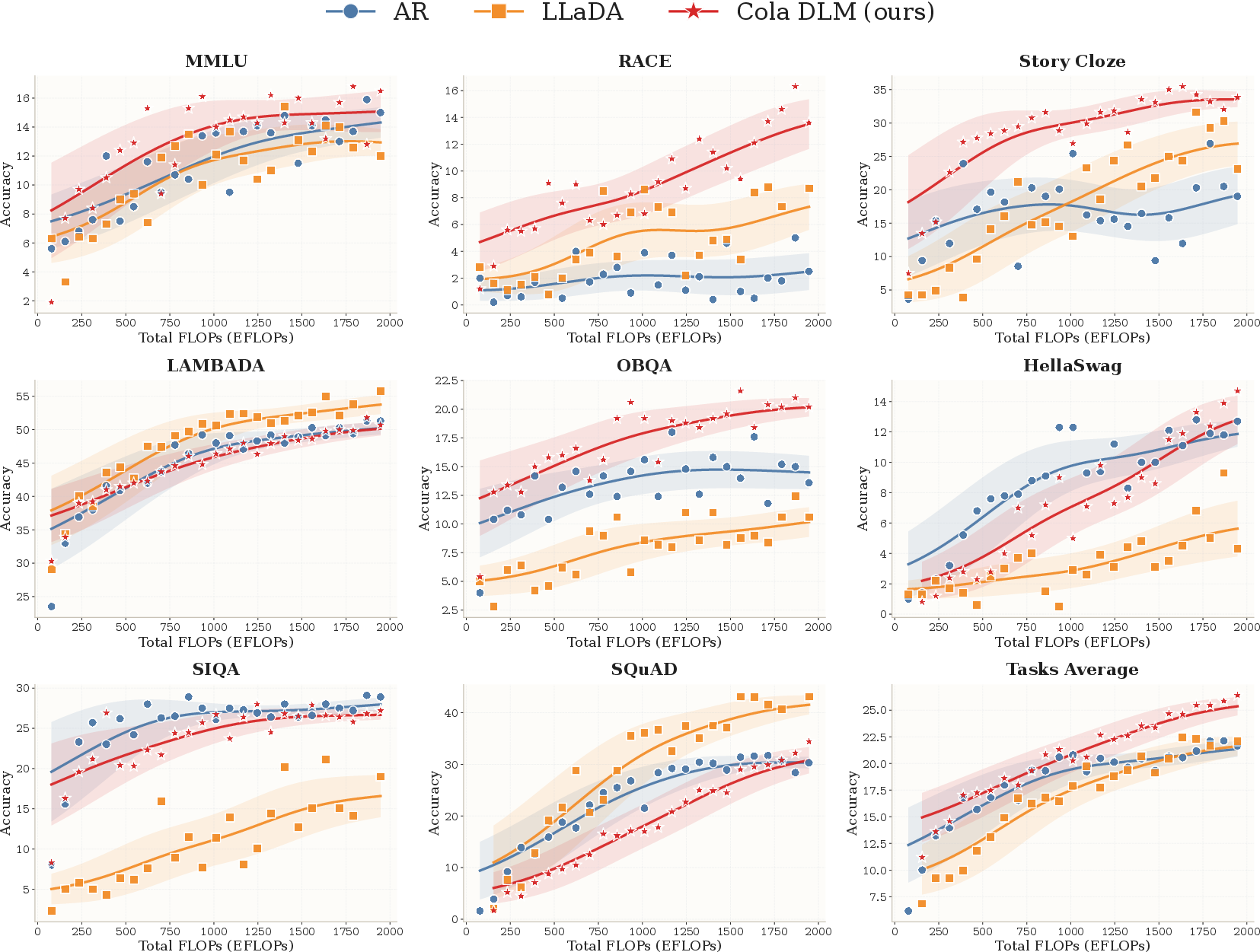
- Strong scaling behavior:
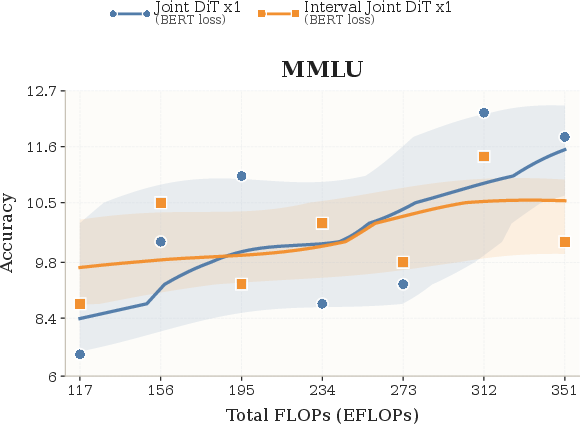
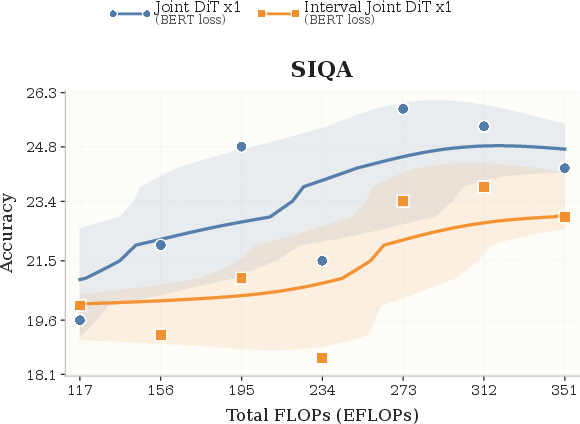
- With compute and size comparable to ~2B-parameter baselines, CoLa scales well on 8 benchmarks (like LAMBADA, MMLU, SIQA, SQuAD, and more).
- As training compute increases, performance improves in a healthy way, showing the approach isn’t just a neat trick—it grows with resources.
- Quality doesn’t always match likelihood scores:
- Traditional scores like “perplexity” (how well the model predicts tokens) did not always line up with how good the generated text was.
- CoLa’s results suggest generation quality (what people actually care about) can be a better indicator of capability than certain likelihood-based metrics.
Why this research matters (implications)
- More flexible text generation: By planning in an idea space before writing, models can better handle tasks like infilling, reordering, and global editing, which are awkward for strict left-to-right writers.
- Better long-range thinking: Splitting “meaning” from “wording” helps the model organize big-picture content before committing to exact tokens.
- Efficiency opportunities: The block-causal design allows parallel thinking within chunks, potentially speeding up parts of generation compared to purely sequential methods.
- A path to multimodal models: Because the core planning happens in a continuous space, the same ideas could extend beyond text, making it easier to connect with other continuous data like images or audio.
- Rethinking evaluation: If generation quality and human-like output don’t always match traditional likelihood measures, we may need to prioritize evaluations that reflect what users experience.
In short, CoLa shows that first planning in a smooth idea space and then writing can be a powerful alternative to word-by-word generation. It brings promising improvements in coherence, flexibility, and scaling—and hints at a unified way to build models that handle both discrete text and continuous modalities.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized by theme.
Modeling and theory
- Lack of empirical quantification of the variational inference gap : no measurements over training or ablations on encoder/decoder architectures to understand how large the gap is and how to reduce it.
- No empirical estimate of the rate–distortion curve for text: the paper argues benefits depend on low-rate global semantics but does not measure vs. reconstruction quality or establish a practical operating point.
- Unclear conditions for when the latent bottleneck helps or hurts: the “structured-generation” assumption is not validated across tasks; a systematic study relating task types to representational rate requirements is missing.
- Posterior collapse and mutual information monitoring are not reported: the paper introduces masking and a reference-encoder regularizer, but does not track or show that latents remain informative across training regimes.
- Bias/variance of conditional likelihood estimator is uncharacterized: subtracting two ELBO/IWAE estimates for can introduce bias/variance; no analysis or confidence intervals are provided.
- Flow-matching prior is treated as a black box: no analysis of identifiability, path dependence, or whether different parameterizations of the vector field induce materially different priors given the same aggregated posterior.
- Theoretical guarantees for block-causal priors are absent: how block size and bidirectional attention within blocks affect causality, information leakage, or calibration remain unproven.
Architecture and training
- No length compression in the Text VAE: the model currently does not compress sequence length; it is unknown how different compression ratios (temporal pooling, learned segmentation) affect quality and efficiency.
- Decoder is strictly causal (autoregressive), so end-to-end generation remains sequential at the token level: the actual speed/effectiveness advantage of latent prior transport vs. standard AR decoding is unquantified.
- Block size and segmentation are fixed and hand-designed: there is no exploration of learned/dynamic block boundaries, variable block sizes, or the trade-off between intra-block bidirectionality and cross-block causality.
- Stability and sensitivity of joint training are underexplored: the paper introduces a reference-encoder KL and gradient control but lacks ablations on hyperparameters (, , ), optimizer choices, and training schedules.
- First-block conditioning is mentioned but not systematically studied: no ablation on how different initialization or conditioning strategies for the first block influence downstream quality and stability.
- ODE solver and divergence estimator choices are not justified: no comparison of solvers (tolerances, step sizes), divergence estimators (number of Hutchinson probe vectors), or their effects on accuracy and compute/memory.
- No study of alternative prior learners: rectified flows, probability flows, discrete-time diffusion, normalizing flows without ODEs, or score-based SDEs might change compute–quality trade-offs but are not evaluated.
- EMA weights are not used or analyzed: diffusion literature often benefits from EMA; the impact on stability and generation quality remains unknown.
Inference and efficiency
- Wall-clock inference costs are not reported: the net runtime/latency of (i) prefix encoding, (ii) block-wise CNF transport, and (iii) AR decoding vs. AR/LLaDA baselines is not measured.
- KV-cache and memory footprint implications are not quantified: the added latent pathway may increase memory; the trade-off with block-parallelism is unclear.
- Prior sampling quality is not assessed: decoding from prior-sampled latents (vs. posteriors) is not evaluated for fluency and semantic coherence; risk of overfitting to the aggregated posterior is unexamined.
- Streaming generation claims are not validated: while components are causal, there is no latency-throughput analysis for streaming or long-running generation scenarios.
Evaluation scope and fairness
- Limited task coverage: evaluation focuses on a small set of benchmarks; instruction following, dialogue, code generation, long-form reasoning, and complex open-ended generation are not tested.
- Non-autoregressive advantages are not validated on appropriate tasks: no experiments on infilling, local editing, global reordering, or fill-in-the-middle to substantiate claims of weaker left-to-right bias.
- No human evaluation or preference studies: the reported metrics are automatic; human judgments on fluency, coherence, and factuality are missing, as is any correlation analysis with proposed likelihood surrogates.
- Perplexity mismatch is acknowledged but unresolved: no alternative intrinsic metrics or calibrated scoring procedures are proposed or validated to replace perplexity for this model class.
- Statistical robustness is not reported: all runs share a single seed; no variance across seeds or confidence intervals are given for any benchmark.
- Baseline breadth is limited: comparisons exclude strong continuous methods (e.g., TESS, SSD-style continuous token models, rectified flows) and larger AR baselines; conclusions may be sensitive to baseline choice.
- Fairness of parameter allocation remains debatable: the VAE (500M) vs. embedding (≈400M) alignment may still yield representational advantages; ablations on equalized representation capacity are missing.
- Data and contamination controls are unspecified: “external open-source pretraining data” is not detailed; dataset provenance, deduplication, and potential test leakage are not discussed.
Scaling and generalization
- Scaling beyond ≈2B parameters and ≈2000 EFLOPs is untested: the paper hints at favorable scaling but provides no experiments at larger model sizes or longer training regimes to establish scaling laws.
- Long-context generalization is not examined: training and evaluation use max length 512; how the model scales to long inputs (e.g., 8k–32k tokens) and maintains latent prior quality is unknown.
- Multilingual and domain adaptation capabilities are unstudied: generalization to non-English, domain shifts, or specialized corpora (law, medicine) is unexplored.
- Robustness and safety are not addressed: no analysis of toxicity, bias, hallucination rates, or adversarial robustness; how latent priors impact safety is uncertain.
- Calibration and uncertainty estimates are unmeasured: whether the hierarchical prior improves predictive calibration or enables better confidence estimates is unknown.
Controllability, interpretability, and modalities
- Latent controllability is not demonstrated: there is no evidence that manipulating can reliably control attributes (style, length, sentiment, topic) or enable semantic editing.
- Interpretability of latent dimensions is unexamined: no probing or causal interventions to map latent directions to linguistic phenomena or task-relevant features.
- Cross-modal claims are preliminary: the paper suggests extensibility to continuous modalities (e.g., vision) but provides no concrete experiments on text–image joint modeling, alignment, or transfer.
- Conditioning mechanisms beyond prefixes are not studied: how to incorporate structured controls (schema, plans), tool outputs, or retrieval signals into the latent prior is unspecified.
Methodological details needing clarification
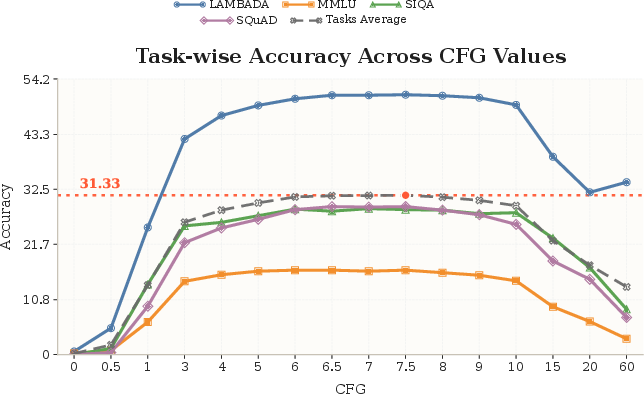
- Exact compute–quality trade-offs for timeshift and diffusion hyperparameters are unclear: while timeshift trends are reported, guidelines for selecting schedules and their interactions with latent dimensionality are missing.
- Sensitivity to tokenizer and vocabulary choices is unknown: the model uses OLMo 2’s tokenizer; no ablation on how subword choices affect latent geometry or prior learning.
- Training from scratch vs. stable initialization needs deeper analysis: initial evidence favors evolving from a pretrained VAE, but the failure modes when training all components from scratch remain undocumented.
These gaps suggest concrete next steps: quantify , , and runtime; benchmark non-AR tasks (infilling/editing); add human evaluations; test length compression and block designs; extend to longer contexts and larger models; and explore controllability and cross-modal extensions.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now by leveraging the paper’s hierarchical latent diffusion LLM (Cola DLM) and its training/inference workflow (Text VAE + block-causal DiT prior + conditional decoder). Each item names sectors, potential tools/workflows, and notes key assumptions or dependencies.
- Low-latency, higher-throughput text generation for assistants and chatbots (software, customer support, education)
- Tools/workflows: Replace or augment autoregressive (AR) decoding with block-wise latent prior transport and conditional decoding; exploit within-block bidirectional attention and across-block causal structure for more parallel generation; cache prefix latents and decoder KV states to reduce end-to-end latency.
- Assumptions/dependencies: A well-trained Text VAE and DiT prior; GPU/TPU support for efficient parallel block computation; careful calibration of latent dimension/timeshift (as in the paper’s RQ1/RQ2 findings).
- Streaming assistants with prefix encoding and block-wise latent generation (productivity, mobile, enterprise)
- Tools/workflows: Encode prefix causally into clean latents, then generate response latents block-by-block while rendering tokens via the conditional decoder; use the paper’s inference stage design (prefix encoding → latent transport → decoding).
- Assumptions/dependencies: Causal encoder/decoder stability; robust first-block conditioning; production-ready ODE/Flow solvers for prior transport.
- Latent-guided local editing, infilling, and document restructuring (productivity suites, IDEs/code, publishing)
- Tools/workflows: Map selected spans to latent blocks, manipulate or regenerate specific latent segments, then decode for localized edits or infill without re-generating the entire document; build “semantic edit” operations in the latent space.
- Assumptions/dependencies: Stable span-to-block mapping; interfaces for latent selection and targeted re-generation; decoder fidelity to preserve unchanged regions.
- Semantic compression and storage as a “text codec” (data engineering, MLOps, edge devices)
- Tools/workflows: Store/transmit z0 latents instead of raw text or token-aligned embeddings; decode on demand; use reference-encoder regularization and masking (Stage 1/2 losses) to maintain semantic fidelity.
- Assumptions/dependencies: Compression ratio and reconstruction quality are task-dependent; privacy and governance policies for storing latent representations; decoder availability wherever reconstruction is needed.
- Diverse and style-consistent content generation via prior seeding and block controls (marketing, media)
- Tools/workflows: Sample multiple noise seeds per block to generate diverse outputs while preserving global coherence; constrain the block-causal prior with attributes or style tags to enforce brand voice.
- Assumptions/dependencies: Attribute conditioning and block-level controls need fine-tuning; decoding must faithfully realize style from latent constraints.
- Better evaluation practices beyond perplexity (ML evaluation, research)
- Tools/workflows: Use the paper’s unconditional/conditional probability estimators (ELBO/IWAE plug-ins) for analysis, but prioritize task accuracy and human judgments for model selection; integrate few-shot evaluation pipelines that reflect actual generation quality.
- Assumptions/dependencies: Accurate prior log-density estimation via CNF with Hutchinson trace; alignment between evaluation tasks and deployment goals.
- Modular training pipelines that reuse a stable VAE-decoder across priors (ML platforms)
- Tools/workflows: Two-stage training: pretrain a stable causal Text VAE (with KL, masking), then learn/fine-tune the block-causal DiT prior; adopt reference-encoder regularization to prevent latent drift.
- Assumptions/dependencies: Sufficient compute (paper uses ~2B scale and up to ~2000 EFLOPs); careful learning-rate schedules and gradient control.
- Cross-lingual drafting and translation with global semantic planning (localization, content operations)
- Tools/workflows: Encode source language into semantically compressed z0, decode into target language with a language-specific conditional decoder; use latent-level global planning for better long-range consistency.
- Assumptions/dependencies: Multilingual decoders or adapters; aligned training data across languages; evaluation for factuality and style consistency.
- On-device prefix encoding with server-side prior transport (mobile, privacy-preserving apps)
- Tools/workflows: Perform causal prefix encoding locally; offload block-wise prior transport and decoding to a server or vice versa, depending on privacy and latency constraints.
- Assumptions/dependencies: Secure split-compute infrastructure; robust latency budgets; consistent encoder–decoder versions across device and server.
Long-Term Applications
These opportunities are enabled by the paper’s core innovations but require further research, scaling, or engineering. They draw on hierarchical decomposition, block-causal priors, and continuous latent transport, and extend to multi-modal and safety-critical settings.
- Unified multi-modal generative modeling via shared continuous latent priors (media, robotics, education)
- Tools/products: Train modality-specific encoders/decoders (vision/audio/embodied state) around a shared DiT latent prior; enable text–image–audio co-generation and cross-modal editing.
- Assumptions/dependencies: Large multi-modal datasets; scalable latent alignment across modalities; robust decoders per modality; training stability for joint co-adaptation.
- Latent-level safety, moderation, and controllability (platform safety, policy, enterprise governance)
- Tools/products: Classifiers and rule-based filters operating on z0 to steer or block unsafe semantics before token realization; constraint-aware priors for brand/legal compliance.
- Assumptions/dependencies: Interpretability of z0; reliable mapping between latent semantics and surface behavior; thorough red-teaming; policy alignment frameworks.
- Constraint-satisfying generation via optimization/guidance in latent space (enterprise content, scientific and legal drafting)
- Tools/products: Gradient-based or RL-guided search over z0 to satisfy factuality, tone, length, citation, or structural constraints; latent-level beam search or MCTS for global planning.
- Assumptions/dependencies: Differentiable guidance signals and reward models; stable trade-offs between constraint satisfaction and fluency; robust decoding under guided latents.
- Personalized and federated priors for on-device assistants (mobile, privacy-first AI)
- Tools/products: Lightweight fine-tuning of the prior to a user’s domain/style while reusing a shared decoder; on-device or federated updates to z0 distributions.
- Assumptions/dependencies: Efficient adaptation methods (LoRA/adapters) for DiT priors; privacy-preserving training; storage and compute constraints on edge devices.
- Latent-space planning for code and multi-step reasoning (software engineering, research, operations)
- Tools/products: Treat z0 as a high-level plan; perform latent search over solution structures before decoding into code or step-by-step rationales; use block-wise priors to coordinate long-range dependencies.
- Assumptions/dependencies: Benchmarks demonstrating improvements over AR on reasoning; integration with unit tests or static analyzers as latent guidance signals.
- Domain-specific priors for regulated sectors (healthcare, legal, finance)
- Tools/products: Fine-tune DiT priors on curated, compliant corpora to encode sector-specific global semantics; decode with domain-conditioned decoders for reports, summaries, or recommendations.
- Assumptions/dependencies: High-quality, de-identified datasets; rigorous validation for bias, safety, and compliance; clear human-in-the-loop oversight.
- AI infrastructure optimized for continuous-flow priors (inference platforms, hardware)
- Tools/products: Runtimes and accelerators that optimize CNF/Flow Matching, ODE integration, and Hutchinson trace; kernels for block-causal attention within DiT.
- Assumptions/dependencies: Standardized APIs for flow-based priors; compiler/runtime support for mixed ODE/transformer workloads; community adoption.
- Robust watermarking and provenance in latent transport (policy, platform trust)
- Tools/products: Embed persistent, hard-to-remove watermarks during latent prior transport; verify provenance from latent statistics rather than surface tokens alone.
- Assumptions/dependencies: Watermarks resilient to editing/paraphrasing; low false-positive rates; policy frameworks for disclosure and enforcement.
- Interoperable “semantic codec” standards (telecom, storage, content pipelines)
- Tools/products: Open standards for compressing, storing, and transmitting z0 latents with versioned decoders; shared tooling for validation and audit.
- Assumptions/dependencies: Community standardization; governance for upgrades and backward compatibility; robust security practices.
- Interactive story/game engines with global plot control (gaming, creative tools)
- Tools/products: Editors that expose and manipulate plot-level latent blocks, then realize scenes and dialogue via decoding; support branching narratives through latent sampling.
- Assumptions/dependencies: UX for latent editing; predictable mapping from latent manipulations to narrative changes; safeguards against incoherence.
- Metrics and policy frameworks beyond perplexity (policy, standards bodies, evaluation labs)
- Tools/products: Standardized generation-quality and safety metrics aligned with end-use tasks; conditional-likelihood estimators only as analysis aids; public leaderboards reflecting real-world utility.
- Assumptions/dependencies: Cross-organization consensus on task suites and scoring; reproducible evaluation harnesses; periodic audits for gaming or overfitting.
Cross-cutting assumptions and dependencies
- Data structure: Gains rely on the presence of low-rate, high-information global semantics (as formalized by the rate–distortion and “three curves” discussion in the paper).
- Training stability: Joint VAE–prior co-adaptation must be carefully controlled (reference-encoder regularization, masking, learning-rate tuning).
- Compute and engineering: Training/fine-tuning DiT priors and solving CNF/ODEs at scale require substantial compute and mature infra; inference stacks need efficient divergence estimation (Hutchinson) and numerical stability.
- Safety and reliability: Hierarchical decomposition does not eliminate hallucinations or bias; deployment in sensitive domains requires domain data, oversight, and monitoring.
- Tooling maturity: Production-ready libraries for block-causal DiT, flow-matching priors, and latent-span editing will accelerate adoption across sectors.
Glossary
- Aggregated posterior: The marginal distribution over latents induced by the data and encoder. Example: "Let the aggregated posterior be ."
- Autoregressive paradigm: A modeling approach that generates tokens sequentially left-to-right via chain-rule factorization. Example: "LLMs have achieved remarkable success under the autoregressive paradigm"
- Augmented ODE: An ordinary differential equation extended with an auxiliary log-density accumulator to compute exact likelihoods under flows. Example: "we solve the augmented ODE"
- Base distribution: The simple reference distribution transformed by a flow to produce a complex prior. Example: "Let the base distribution be "
- BERT-style masking loss: An auxiliary objective that masks tokens and predicts them to encourage robust representations. Example: "Here, $\mathcal L_{\mathrm{mask}$ is the BERT-style masking loss shown in the figure."
- Block-causal DiT: A diffusion transformer with causal dependencies across blocks but parallelism within blocks. Example: "then models a global semantic prior in continuous latent space with a block-causal DiT"
- Block-wise generation: Generating outputs in contiguous blocks rather than token-by-token to improve parallelism. Example: "Inference: Prefix Encoding, Block-wise Generation, and Conditional Decoding"
- CNF change-of-variables formula: The likelihood computation rule for continuous normalizing flows via ODE integration and divergence terms. Example: "The prior term is evaluated by the CNF change-of-variables formula."
- Conditional decoder: A decoder that generates text conditioned on a latent representation. Example: "and finally generates text through a conditional decoder."
- Conditional Flow Matching: A training objective that learns conditional vector fields for flow-based models. Example: "prior learning uses a joint objective that combines conditional Flow Matching with a reference-encoder regularizer"
- Continuous-flow prior: A prior distribution over latents defined by transporting a base distribution through a continuous flow. Example: "We model with a continuous-flow prior."
- Continuous Normalizing Flow (CNF): A flow-based generative model defined via continuous-time dynamics (neural ODEs). Example: "CNF change-of-variables formula."
- DiT (Diffusion Transformer): A transformer architecture adapted to parameterize diffusion or flow processes. Example: "Training Stage 2 shows joint pretraining of the Text VAE and Text DiT with gradient control"
- EFLOPs: Exa–floating point operations; a large-scale compute budget measure. Example: "scaling curves up to about 2000 EFLOPs"
- ELBO (Evidence Lower Bound): A variational lower bound on log-likelihood used to train latent-variable models. Example: "Training therefore maximizes $\mathcal L_{\mathrm{ELBO}(x)$, or equivalently minimizes $-\mathcal L_{\mathrm{ELBO}(x)$."
- Flow Matching: A method to learn vector fields that transport a base distribution to a target distribution. Example: "we learn the corresponding vector field with Flow Matching."
- Hutchinson's trace estimator: A stochastic estimator of the divergence (trace of Jacobian) used in CNF likelihoods. Example: "In high dimensions, the divergence term is estimated with Hutchinson's trace estimator:"
- Importance weight: The reweighting factor used in importance sampling estimators of likelihood. Example: "define the importance weight"
- IWAE (Importance Weighted Autoencoder): A tighter importance-sampling-based estimator of log-likelihood than the ELBO. Example: "This gives two standard estimators, namely the ELBO-style and IWAE-style estimators:"
- KV cache: Key–value memory used to speed transformer decoding by caching past attention states. Example: "Inference Stage illustrates the decoding process with KV cache."
- Latent prior transport: Using diffusion/flow to move a base noise distribution into a learned latent prior, rather than denoising tokens. Example: "its diffusion process performs latent prior transport rather than token-level observation recovery"
- Markov-path perspective: A unified view that treats generation as sampling along a stochastic path with transitions and emissions. Example: "From a unified Markov-path perspective,"
- Non-autoregressive inductive bias: A modeling bias favoring generation that is not constrained to strict left-to-right token order. Example: "This design yields a more flexible non-autoregressive inductive bias"
- Plug-in estimator: An estimator that computes a target quantity by substituting consistent estimates of its components. Example: "We therefore obtain a plug-in estimator by scoring the joint sequence and the prefix with the same unconditional estimator:"
- Prefix--response decomposition: Splitting a sequence into a given prefix and a response to compute conditional probabilities. Example: "For a prefix--response decomposition $x=(x_{\mathrm{pre},x_{\mathrm{res})$, the exact identity is"
- Rate-distortion function: The best achievable reconstruction loss as a function of representation information rate. Example: "Define the representation rate-distortion function as"
- Reference-encoder regularizer: A KL penalty that anchors the current encoder to a reference encoder to stabilize training. Example: "combines conditional Flow Matching with a reference-encoder regularizer:"
- Stop-gradient: An operation that prevents gradients from flowing through a tensor during backpropagation. Example: "where denotes stop-gradient."
- Structured-generation assumption: The hypothesis that data are generated from low-dimensional global variables plus conditional realizations. Example: "This can be characterized further through a structured-generation assumption."
- Variational inference gap: The discrepancy between the true posterior and the variational approximation. Example: "In contrast, C also incurs a variational inference gap:"
- Vector field: The function defining the velocity of latent states over time in a continuous flow. Example: "let be the vector field."
Collections
Sign up for free to add this paper to one or more collections.

