- The paper introduces TMAS, which uses structured multi-agent protocols and hierarchical memory banks to enhance test-time compute scaling for LLM reasoning.
- It details how parallel candidate generation, explicit verification, and iterative refinement enable efficient reuse of validated sub-results and diverse exploration.
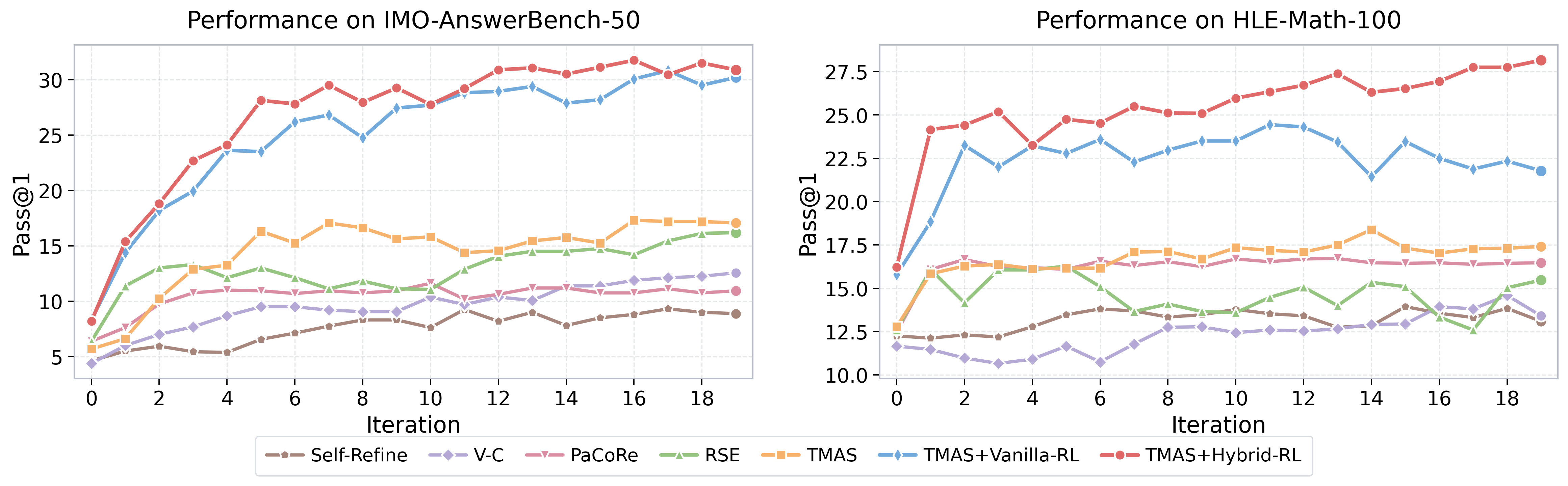
- Empirical results demonstrate that TMAS outperforms legacy TTS approaches with up to 40.50% Pass@1 accuracy and robust iterative scaling on challenging benchmarks.
TMAS: Structured Multi-Agent Test-Time Scaling for LLM Reasoning
Motivation and Limitations of Prior Test-Time Scaling Paradigms
Test-time scaling (TTS) approaches organize additional inference computation to enhance LLM mathematical reasoning and problem-solving. Legacy TTS methods can be broadly categorized into sequential trajectory scaling (e.g., Chain-of-Thought, Self-Refine) and parallel aggregation schemes (e.g., Majority Vote, Self-Consistency). More recent frameworks (e.g., PaCoRe, RSE) aggregate information across multiple solution attempts, while verify-refine systems structure the interaction between generation, verification, and correction. However, these architectures suffer from critical limitations. Parallel and sequential reasoning traversals are often weakly coupled, with no explicit protocol to decide what information should be abstracted, forgotten, or shared. Most approaches rely on undifferentiated, potentially noisy historical trajectories to drive iterative improvement, resulting in inefficient experience utilization, limited exploitation of verified intermediate results, and suboptimal strategy diversity. The exploration–exploitation trade-off is poorly managed, which is detrimental on substantially challenging benchmarks.
TMAS Framework: Multi-Agent Synergy for Hierarchical Reuse and Exploration
TMAS (Test-Time Multi-Agent Synergy) is introduced to resolve these deficiencies with new multi-agent protocols and hierarchical memory mechanisms.
TMAS executes parallel candidate generations, explicit verification, and iterative refinement with five coordinated roles: solution agent, verification agent, summarization agent, experience agent, and guideline agent. Communication is mediated by two persistent, hierarchical memory banks:
- The experience bank retains verifier-backed intermediate conclusions, error heuristics, and reusable concrete solution anchors distilled from rollouts.
- The guideline bank logs high-level strategic approaches previously attempted, enforcing diversity in subsequent exploratory rollouts.
This shared memory infrastructure yields significant synergy: it allows rollouts to exploit accumulated local evidence while systematically steering future searches away from redundant solution modes.
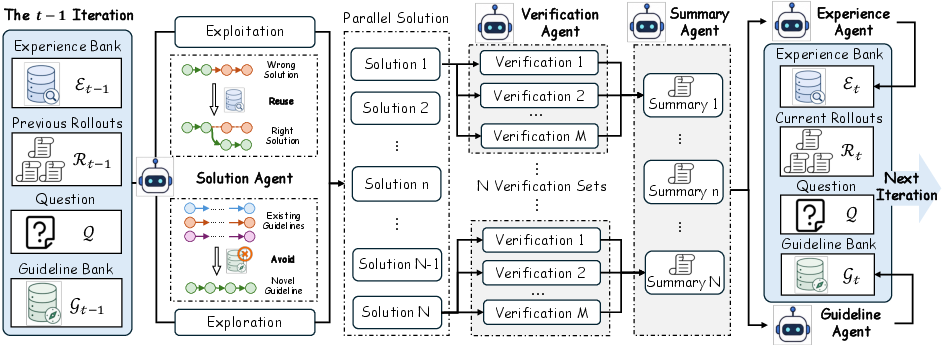
Figure 1: Overview of the TMAS architecture, highlighting parallel solution generation, independent multi-agent verification, and hierarchical memory-driven multi-iteration refinement.
Hybrid Reward RL: Aligning Agents for Robust Iterative Scaling
TMAS performance depends crucially on aligning the backbone LM to utilize memories and maintain effective iterative behavior. To that end, TMAS employs a hybrid reward RL scheme, extending standard RLVR with three signals: (1) strict correctness, (2) explicit reward for effective use of experience bank information (large bonus when a solution is only recovered when given the experience bank), and (3) directed reward for generating solution strategies not covered in the existing guideline bank—effectively incentivizing non-redundant exploration. This transforms the RL optimization landscape to cover both exploitation of reliable findings and rigorous strategy-level exploration, in contrast to prior approaches that optimize only for final answer accuracy.
Empirical Results: Robust Gains in Iterative Regimes
Experimental results on challenging benchmarks (IMO-AnswerBench-50, HLE-Math-100) demonstrate strong claims:
Ablation analyses confirm that experience and guideline modules are complementary: guidelines accelerate initial convergence by avoiding search redundancy, while the experience bank sustains accuracy growth by anchoring on validated sub-results. Sensitivity analyses show non-monotonic dependence on exploration coefficient ϵ and diminishing returns past a moderate number of parallel candidates or verifier agents.
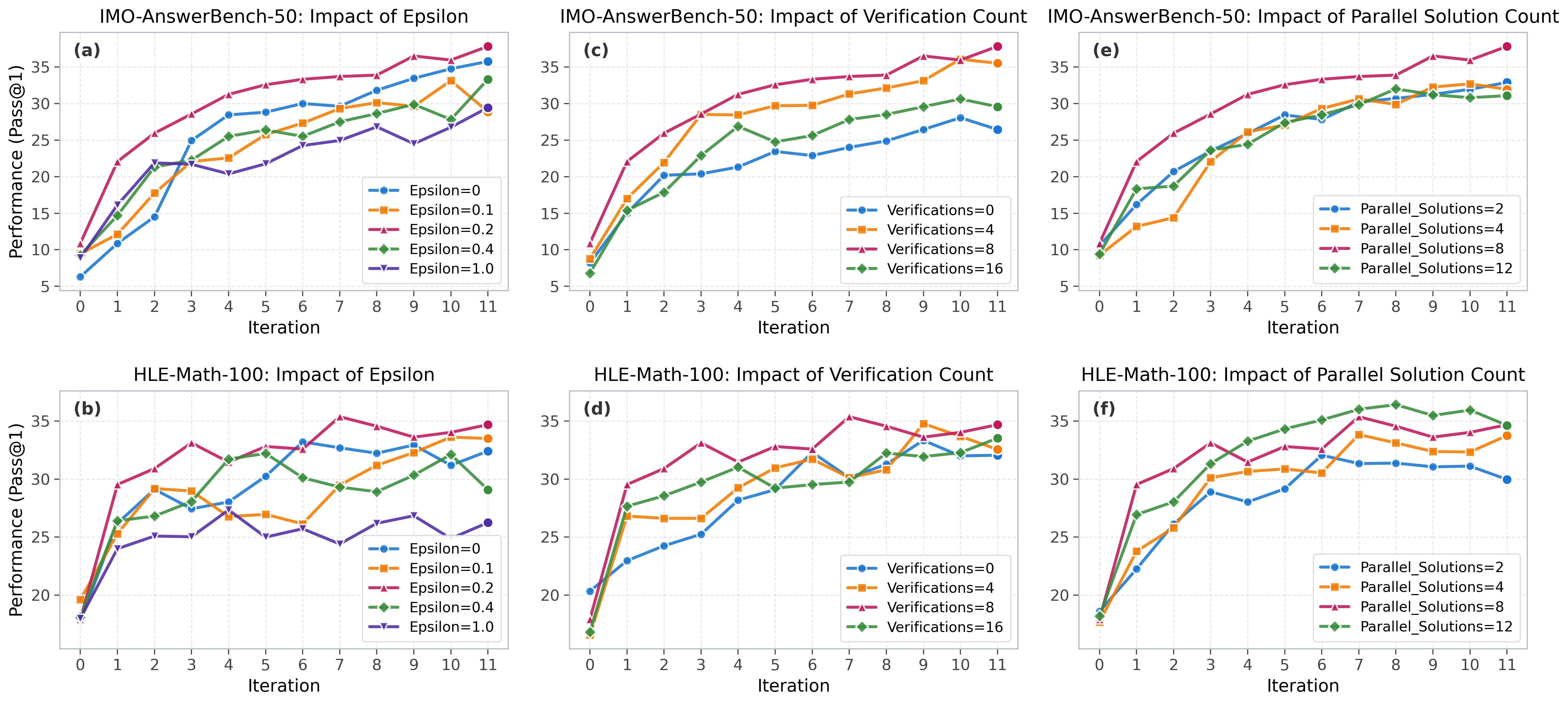
Figure 3: Sensitivity analysis of exploration, verification, and parallel solution counts in TMAS.
Analysis of Verification and Scaling Failure at the Reasoning Frontier
A key empirical finding is that, for unsolved (never-correct) benchmark problems, the verification agent assigns systematically higher scores—demonstrating a shared capability boundary between solution and verification agents derived from the same base model. The hybrid RL scheme attenuates this paradox by reducing the discriminative gap in verification scores between ever-correct and never-correct problems, but does not fully resolve it. Refinement beyond the model’s reasoning frontier remains bottlenecked by verification reliability.
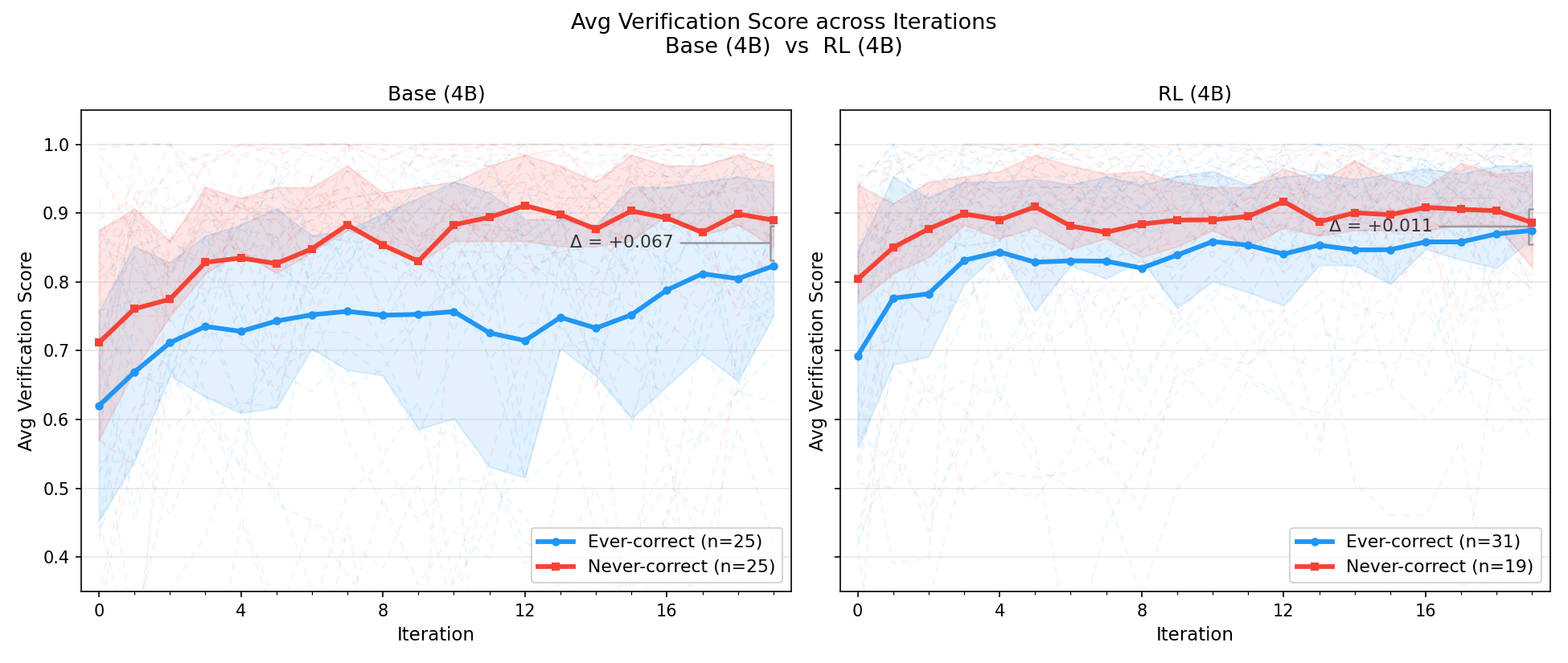
Figure 4: Verification scores of ever-correct and never-correct problem groups before and after RL; boundaries sharpen but residual indistinguishability is observed.
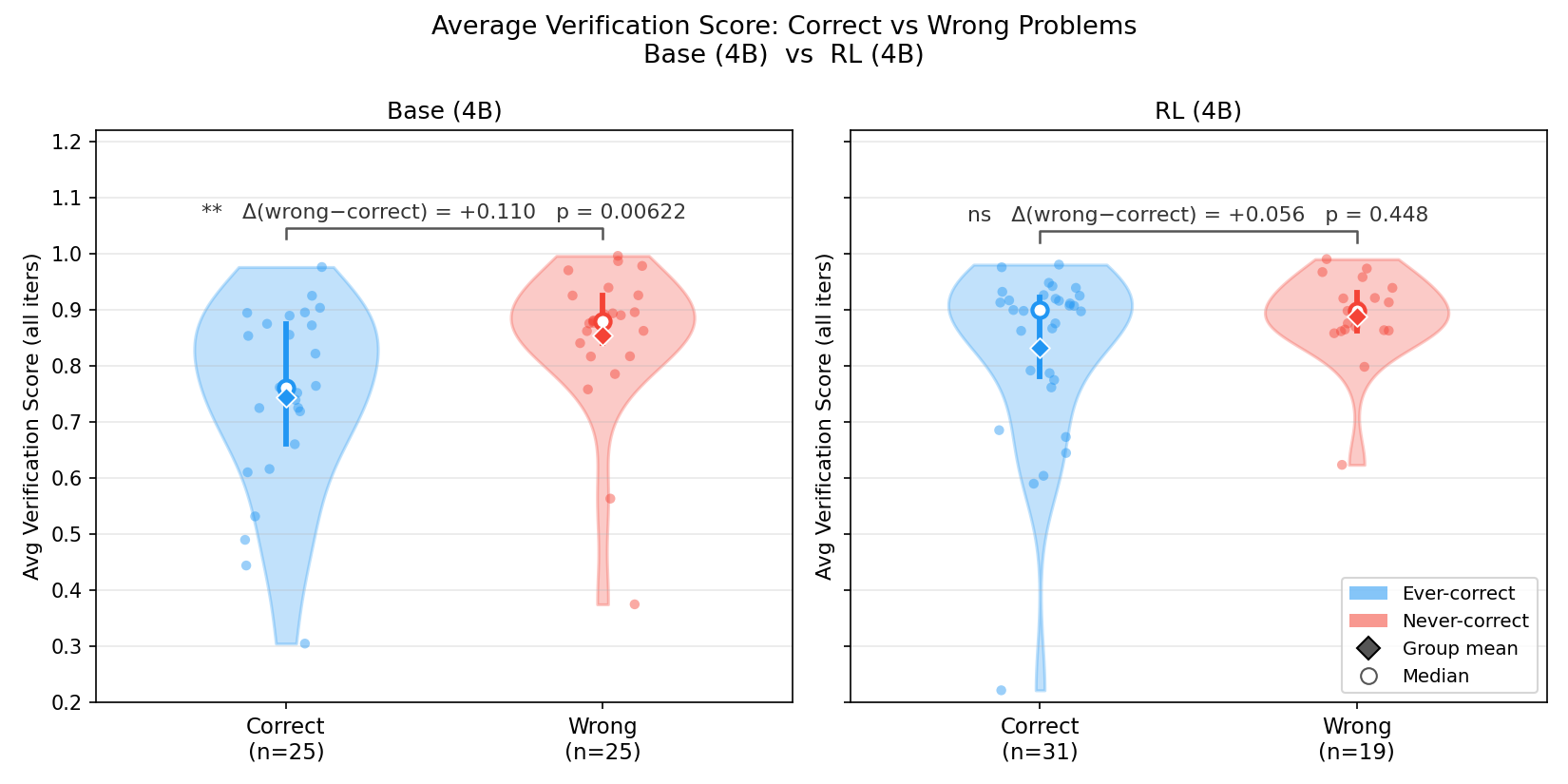
Figure 5: Post-RL narrowing of the verification score gap between correct and unsolved problems; statistical significance is eliminated but full discriminative capacity is not achieved.
Implications and Future Directions
TMAS demonstrates that formalized agent specialization, hierarchical reasoning memory, and hybrid reward protocols substantially improve the ability to harness test-time computation for LLM-based reasoning. Practically, this enables smaller models to approach the performance of much larger models through dynamic solution space traversal and reuse. Theoretically, the results highlight a remaining limitation: once both generation and verification are equally challenged, feedback becomes non-discriminative and test-time scaling converges.
Immediate research directions include:
- Decoupled, more capable verifier agents: Training verification on external process-level supervision or leveraging specialized architectures to further dissociate the solution-verification capability boundary.
- Dynamic RL data augmentation: Iteratively incorporating rollouts and memories obtained during active test-time reasoning into the RL pool, making model updating ever more reflective of practical operation.
- Application to non-math domains: Extending the TMAS framework to tasks requiring structured, long-horizon reasoning (e.g., proof construction, scientific discovery, program synthesis) with domain-specialized memory extractions.
Conclusion
TMAS establishes a robust protocol for harnessing multi-agent, memory-based iterative scaling at inference, overcoming key deficits of prior TTS approaches through explicit management of local experience and high-level strategy. Hybrid reward RL further unlocks this structure, enabling effective exploration and exploitation far beyond traditional correctness-only RL. The residual shared capability boundary between solution and verification remains the limiting trajectory for future research.
Reference: "TMAS: Scaling Test-Time Compute via Multi-Agent Synergy" (2605.10344)