- The paper presents a Riemannian flow model on the unit hypersphere, avoiding the high-dimensional bottleneck of one-hot vectors.
- It employs a hyperspherical Transformer backbone with adaptive, truncated noise scheduling to enhance training stability and scalability.
- Experimental results show that the model achieves competitive performance in tasks like Sudoku reasoning, mathematical problem solving, and language modeling.
Hyperspherical Flow LLMs for Large-Vocabulary Reasoning
Introduction
"Language Modeling with Hyperspherical Flows" (2605.11125) introduces the Hyperspherical Flow LLM (S), a continuous flow-based LLM formulated on the unit hypersphere Sd−1. S provides a novel alternative to both autoregressive (AR) and discrete diffusion models, motivated by the inefficiencies of flow models operating on one-hot vectors and the limitations of factorized sampling for discrete diffusion. The key contributions include a Riemannian flow approach leveraging cosine similarity, an efficient embedding scheme that circumvents the ∣V∣-dimensional bottleneck inherent to one-hot flows, and a hyperspherical backbone (S) designed for stable and scalable training. Throughout, the work delineates the theoretical grounds for hyperspherical modeling, provides a principled approach to adaptive and truncated noise schedules, and empirically benchmarks S across Sudoku, GSM8K/TinyGSM, and OpenWebText.
Theoretical Framework: Flow Matching on Sd−1
Unlike previous Flow LLMs (FLMs) that operate in Euclidean space, S is formulated as a Riemannian Continuous Normalizing Flow (CNF) on (Sd−1)L. Token embeddings are mapped to unit-norm vectors, and noise is injected via rotations (SLERP) on the hypersphere. The conditional flow is defined by spherical linear interpolation between noise and clean embeddings, the denoiser is trained with cross-entropy, and the marginal velocity field is obtained by integrating likelihood-weighted tangent vectors toward all possible tokens.
This geometric formulation is motivated by the empirical superiority of cosine distance for token similarity, its scalable separation properties in high-dimensional space, and the tractability of closed-form velocity computations using logarithmic and exponential maps on Sd−1. Training and sampling are efficient, requiring only d-dimensional computations rather than ∣V∣-dimensional operations.
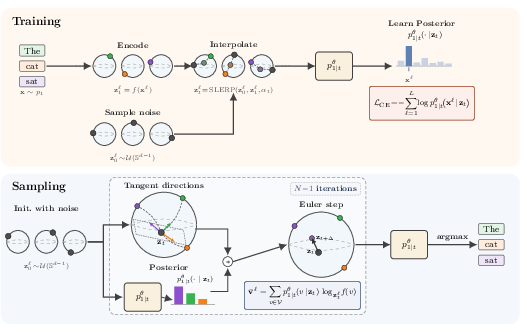
Figure 1: S overview; training embeds tokens as unit-norm vectors, noise is applied via SLERP, and sampling integrates along marginal velocity followed by argmax decoding.
Hyperspherical Backbone Architecture
S employs a Transformer variant structurally analogous to nGPT, with bidirectional attention and residual blocks parameterized as rotations. Every intermediate activation is normalized on the hypersphere, and layer outputs are interpolated with noise-conditioned gates. The output head projects normalized hidden states via row-normalized matrices, addressing the boundedness of inner products and ensuring stable cross-entropy dynamics.
This architecture yields competitive performance while reducing parameter count compared to conventional DiT backbones and enables stable training when combined with adaptive and truncated noise schedules.
Noise Scheduling: Truncation and Adaptivity
The curse of dimensionality on Sd−1 necessitates principled truncation of the noise schedule, as posteriors collapse to one-hot at low noise levels due to embedding separation. The paper introduces an analytical bound α⋆(δ), determined by the probability that noisy latents are closest to their clean embeddings given vocabulary size and embedding dimension. Consequently, S is trained mainly at higher noise levels, improving accuracy and sample quality.
Additionally, a dynamic scheduling algorithm inspired by InfoNoise reallocates training density to regions where cross-entropy loss is most informative. This adaptive schedule is empirically shown to stabilize training and does not inflate computational cost.
Experimental Evaluation
Sudoku Reasoning
Sudoku presents a global reasoning challenge requiring non-factorized joint inference. On exact match accuracy, S (using adaptive/truncated schedules) achieves competitive results with prior FLMs, outperforming AR and MDLM. Strong accuracy is observed when embedding re-normalization is omitted, demonstrating the efficacy of hyperspherical representation and adaptive learning rate decay.
GSM8K/TinyGSM Mathematical Reasoning
TinyGSM, a synthetic math dataset derived from GSM8K, represents a verifiable domain where AR excels and prior FLMs perform below 1% accuracy. S, via analytic truncation, adaptive schedules, and top-∣V∣0 velocity decoding, achieves up to ∣V∣1 accuracy, closing the gap to masked diffusion (MDLM/Duo) at standard temperature (∣V∣2). With low-temperature decoding (∣V∣3), discrete diffusion models maintain a significant advantage (∣V∣4–∣V∣5 vs ∣V∣6), illustrating a residual gap for continuous flows in compositional reasoning.
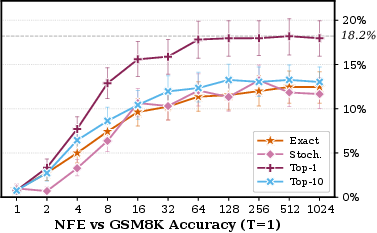
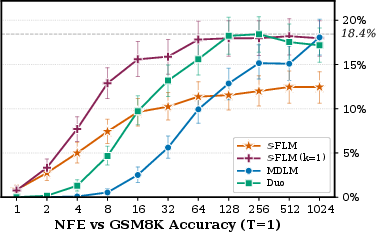
Figure 2: GSM8K accuracy for S versus MDLM and Duo at ∣V∣7, showing S—especially with top-∣V∣8 velocity—competitive at moderate NFE budgets.
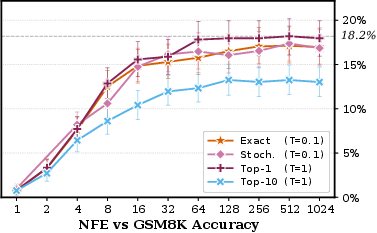
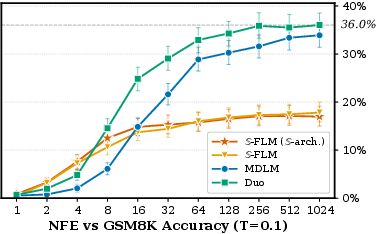
Figure 3: GSM8K accuracy under low-temperature decoding, highlighting that S and DiT plateau at half the accuracy of Duo despite competitive performance at ∣V∣9.
Ablations reveal that greedy decoding (top-Sd−10 velocity) is essential for bridging the gap at Sd−11, while stochastic and exact velocity decoding plateau lower.
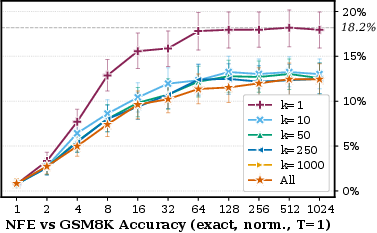
Figure 4: GSM8K accuracy sweep over top-Sd−12 velocity, indicating only Sd−13 substantially improves accuracy.
OpenWebText Language Modeling
S is evaluated on unconditional language modeling via Gen. Perplexity (PPL) and unigram entropy, covering a range of NFE and sampling temperature schedules. At high NFE, S parallels prior FLMs on the Gen. PPL/Entropy Pareto frontier. At low NFE, S's frontier remains stable whereas prior FLMs degrade, suggesting improved scalability and robustness in resource-constrained settings.
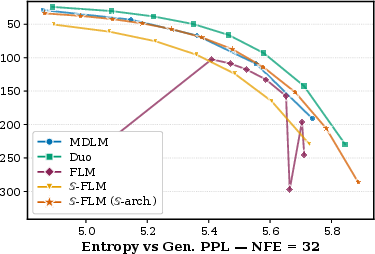
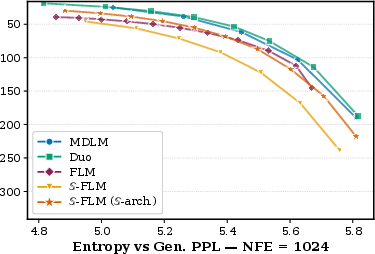
Figure 5: Gen. PPL vs. entropy tradeoff on OpenWebText; S matches FLMs at high NFE, showing greater stability at lower NFE.
Practical and Theoretical Implications
S advances continuous diffusion language modeling with a scalable geometric representation and efficient computation, avoiding the need to materialize one-hot vectors. This makes it practical for large-vocabulary settings and amenable to scaling, though the paper acknowledges that full scaling experiments are not performed. The hyperspherical approach may enable future research on contrastive representation learning, normalization, and Riemannian generative modeling.
From a theoretical perspective, S demonstrates that Riemannian flows with end-to-end learned embeddings, adaptive schedule, and hyperspherical architecture can approach—but not fully match—the reasoning accuracy of discrete diffusion or AR models in program synthesis and math. The analytical study of sampling dynamics enables principled noise schedule design, which may be relevant for other manifolds or domains.
Limitations and Future Directions
Continuous diffusion models, including S, remain quantitatively below discrete diffusion and AR models in reasoning tasks. The critical noise truncation is derived under the assumption of random embeddings, which may not reflect learned structure; improved analytic modeling could further enhance performance. Throughput optimization, improved training dynamics, and deeper integration with contrastive learning methods are promising avenues.
Figure 6: Sequence length distributions on TinyGSM, showing the efficiency of code-trained tokenizers for fixed context.
Conclusion
The paper establishes S as a theoretically sound and empirically competitive flow-based LLM leveraging hyperspherical geometry, adaptive scheduling, and normalized activations. S outperforms prior continuous FLMs across several domains, closes the gap to discrete diffusion in certain regimes, and enables efficient large-vocabulary modeling. Nevertheless, discrete diffusion and AR models retain an advantage in math reasoning and program synthesis; closing this gap remains a fundamental research challenge. The principled scheduling and hyperspherical embedding approach contribute new tools for scalable, robust, and expressive language modeling.

