- The paper demonstrates a framework that automates high-cost LLM experiment configuration via an RL-trained agent leveraging cross-fidelity reasoning.
- It introduces LLMConfig-Gym, an offline RL environment supporting diverse, multi-fidelity LLM tasks to efficiently explore and optimize configuration spaces.
- Results show near-zero regret and significant scalability improvements, outperforming classical baselines and meta-learning methods.
Automating LLM Experiment Configuration via Agentic Cross-Fidelity Reasoning: AutoLLMResearch
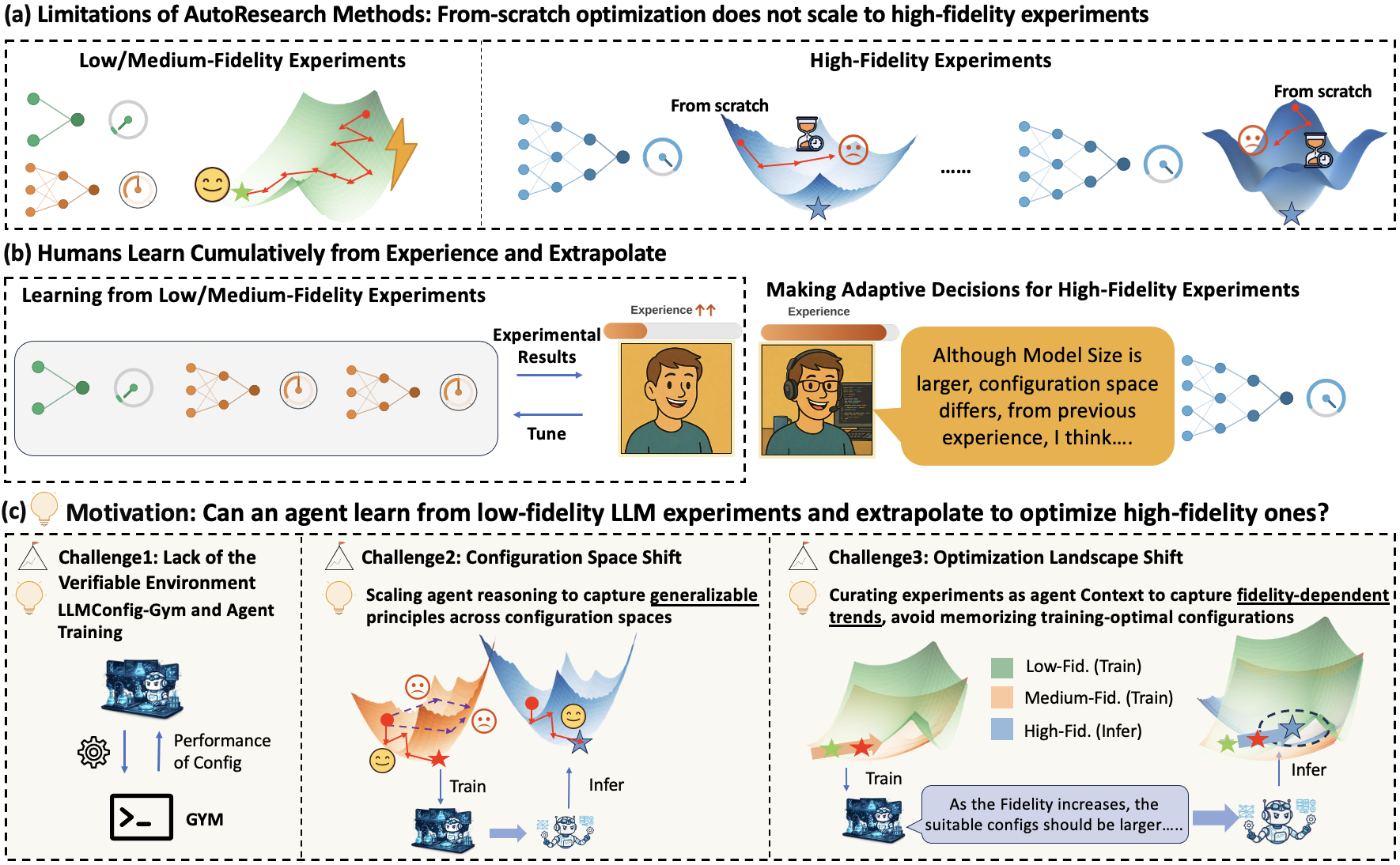
Motivation and Problem Statement
AutoLLMResearch (2605.11518) systematically addresses a critical yet previously neglected problem: configuration automation for large-scale LLM experiments with high computational costs. As LLMs become increasingly central to various applications, their optimal configuration—spanning architecture search, hyperparameter tuning, RL post-training, and data mixture selection—becomes vital for efficient deployment and maximal performance. Classical HPO tools, Bayesian optimization, and recent LLM-based prompt agents assume low-cost environments with unlimited iterations, a paradigm infeasible at LLM scale where each trial incurs prohibitive GPU hours.
Three domain-specific challenges are identified:
Framework Architecture: LLMConfig-Gym and Agentic Training Pipeline
The proposed solution consists of two principal components:
LLMConfig-Gym
LLMConfig-Gym is an offline, lookup-based RL environment exposing four representative LLM configuration tasks:
- Model architecture search (HW-GPT-Bench).
- Pretraining hyperparameter tuning (Step Law).
- RL GRPO tuning hyperparameters (extensive grid search on multiple datasets and backbone sizes).
- Data mixture selection (ADMIRE IFT Runs with Tülu-3/Qwen2.5).
The Gym supports multi-fidelity task splits and rapid queries, facilitating agent learning from verified historical outcomes across large discrete configuration spaces.
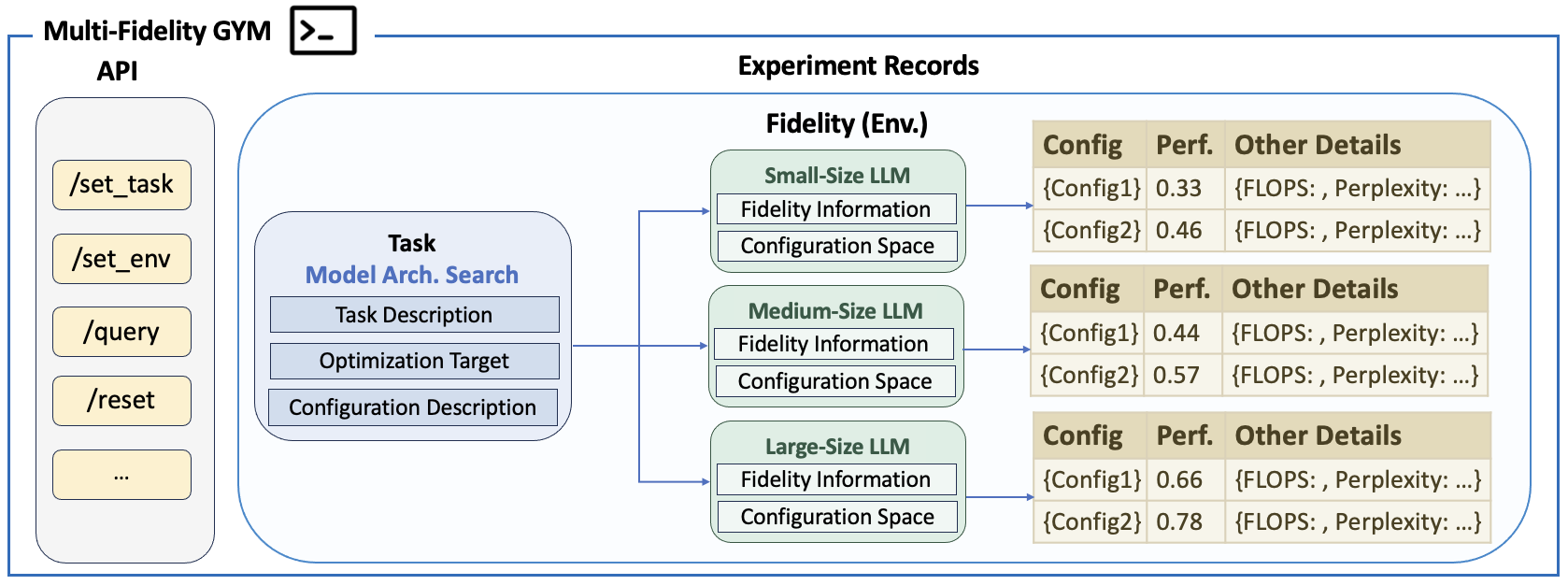
Figure 2: LLMConfig-Gym overview. A unified, lookup-table-based Gym organized by Task → Fidelity → Experiment.
Structured Agent Training Pipeline
Configuration research is cast as a long-horizon MDP, where the agent, implemented as a fine-tuned LLM, iteratively "thinks" (proposes configurations via text reasoning) and "executes" (queries the Gym to observe performance).
The training pipeline comprises:
Quantitative Evaluation
Extensive experiments on all Gym tasks demonstrate that the RL-trained agent achieves consistently lower regret under strict budget constraints compared to classical baselines (random search, Top-K warm start), meta-training approaches (NAP, MetaBO), and prompt-based LLM agents (OpenAI O4-mini, Gemini, GPT-5).
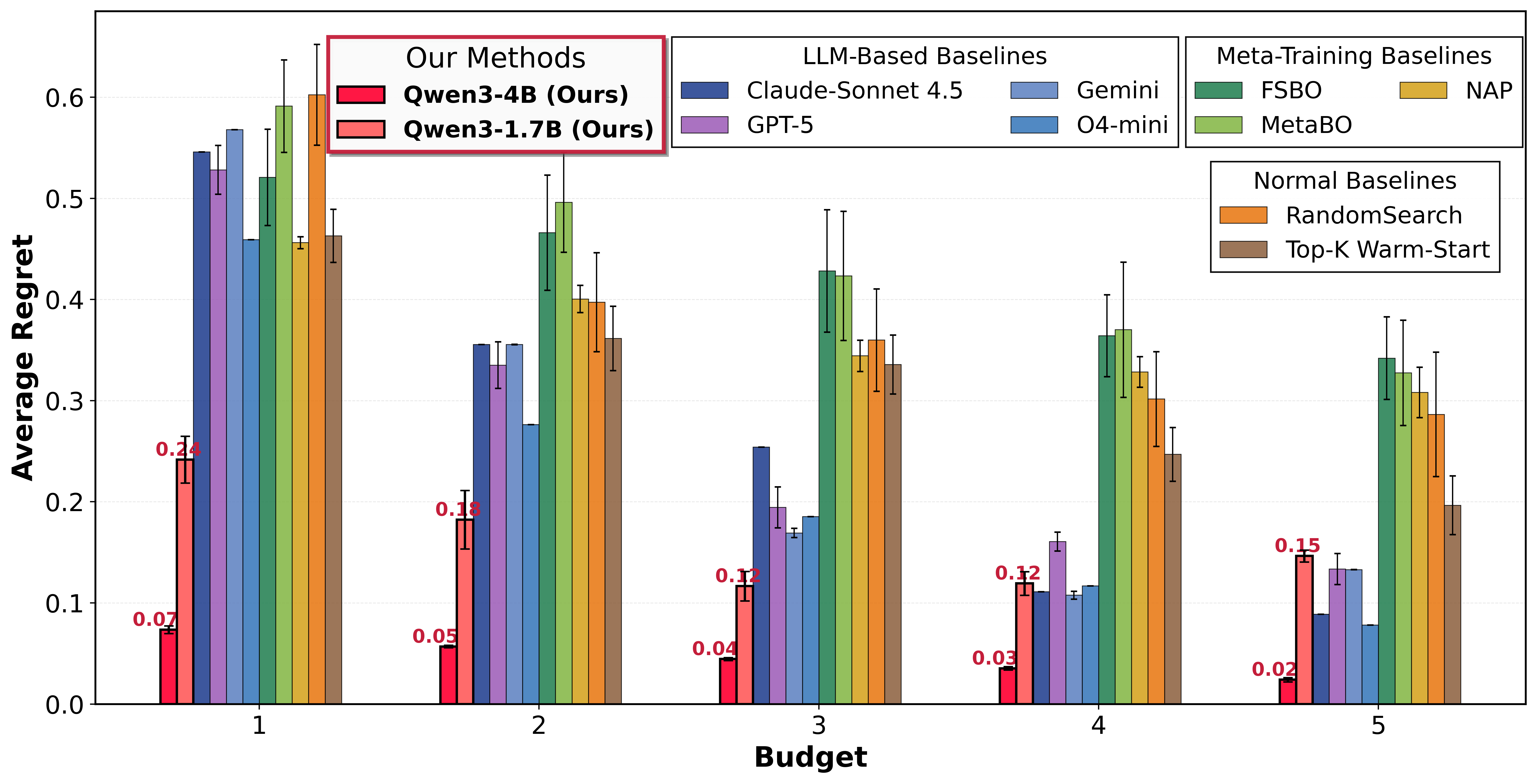
Figure 4: Overall performance comparison across all tasks and budget constraints. Our method achieves the lowest regret across different settings, demonstrating its effectiveness.
Notably:
- Configuration space shift (Tasks 1, 4): The trained agent achieves near-zero regret (e.g., ∼0.01) even when the test space is disjoint from training, a scenario where meta-learning collapses.
- Optimization landscape shift (Tasks 2, 3): RL-trained agents avoid over-extrapolation and adapt to shifted optima, outperforming both prompt-based and distributional meta-learners.
Interpretability: Reasoning and Transfer Mechanisms
Detailed case studies trace the evolution of agent reasoning:
Optimization trajectory analysis shows the RL-trained agent rapidly prunes the search region, leveraging text-based reasoning to concentrate exploration near global optima from the outset—contrasting with erratic or misdirected search by baselines.
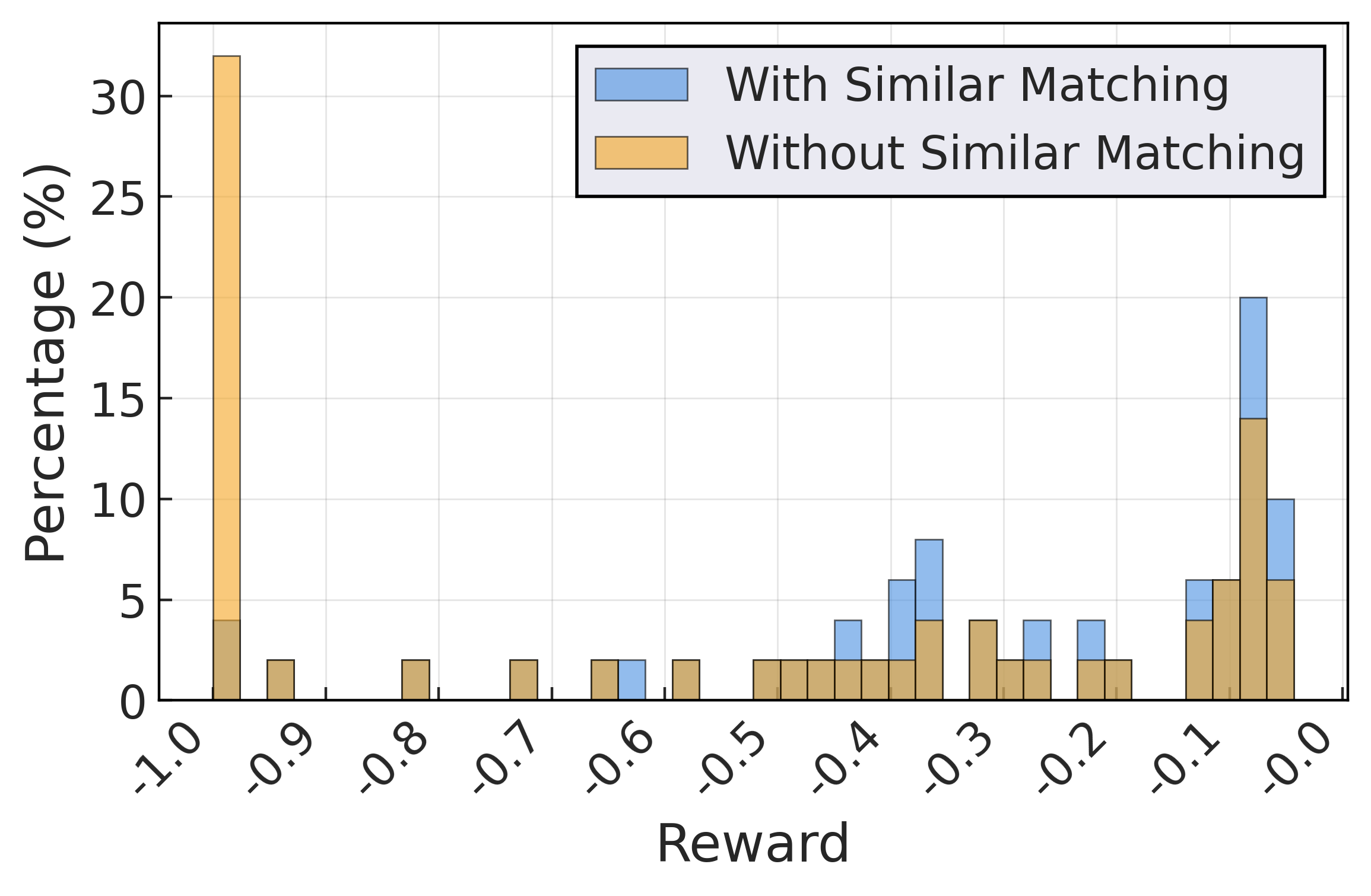
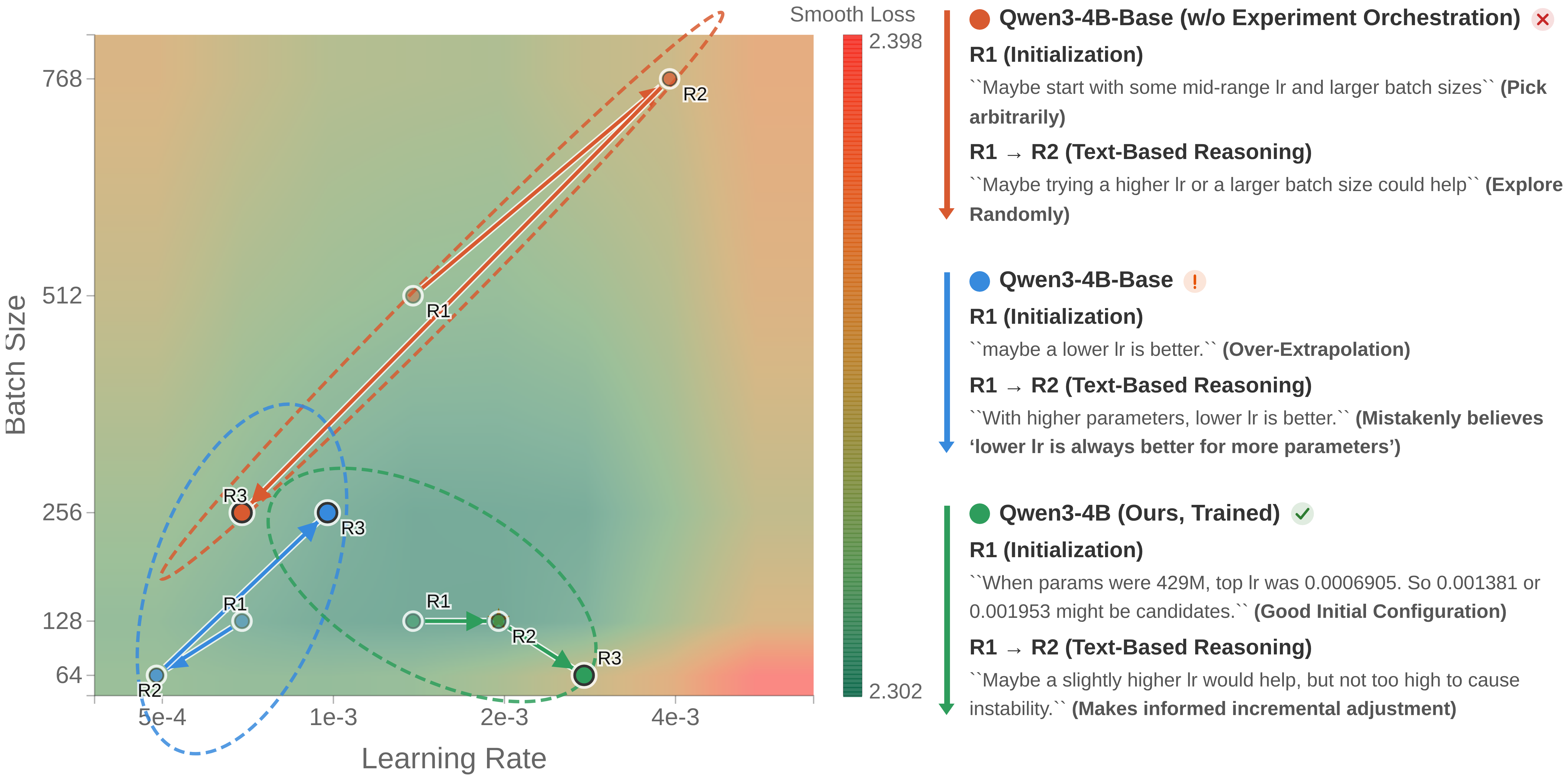
Figure 6: Optimization trajectories and reward densification via most-similar matching. RL-trained agent search concentrates around global optima; matching converts format errors into valid queries, stabilizing RL training.
Robustness, Scalability, and Practical Implications
The cost analysis demonstrates substantial amortized gains: as the number of high-fidelity tasks increases, upfront meta-training cost is quickly offset, yielding a 3.6× reduction in cumulative GPU hours at K=30 tasks.
In stress-tested settings with sparse training coverage or reversed optimal regions, RL-based cross-fidelity agents degrade gracefully and recover faster than baseline meta-learners, confirming robustness to adversarial regimes.
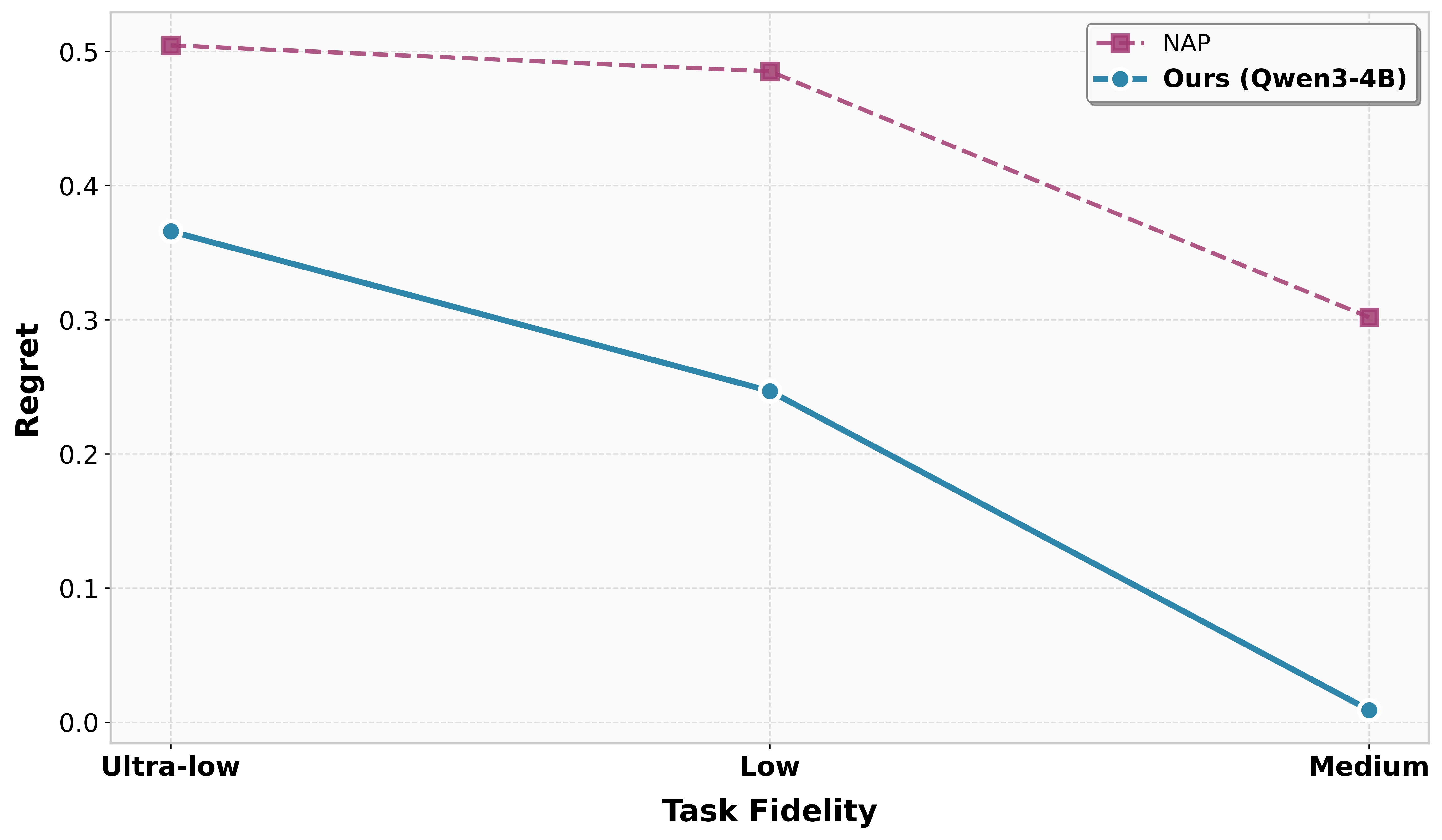
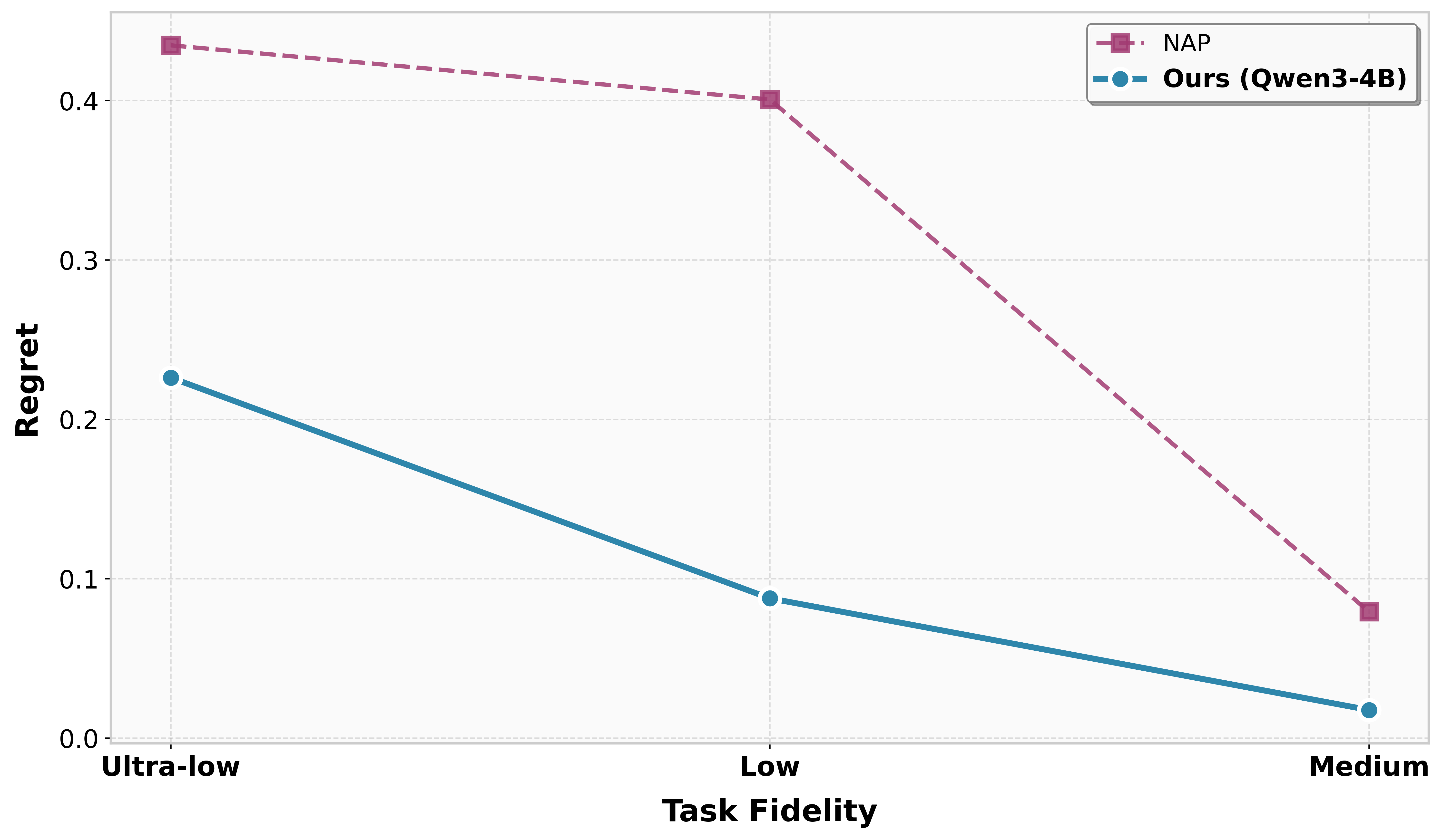
Figure 7: Sparse coverage experiment, showing the agent's regret declines steeply as coverage grows, outperforming NAP across regimes.
Training Dynamics and RL Stabilization
Quantitative monitoring shows regret (mean@3) dropping consistently on held-out test sets, critic score rising, and invalid outputs decreasing over RL training steps. Most-similar configuration matching reduces rate of format violations (32\% → negligible), densifying reward.
Figure 8: Training dynamics across all four tasks, showing improvement in regret, critic scores, and response length over training steps.
Optimization Landscapes
Multi-fidelity task landscapes are visualized, revealing rugged search spaces with multiple local minima and shifting optima—a context where classical and prompt methods fail to generalize, but RL-trained agents adaptively locate high-performing regions.
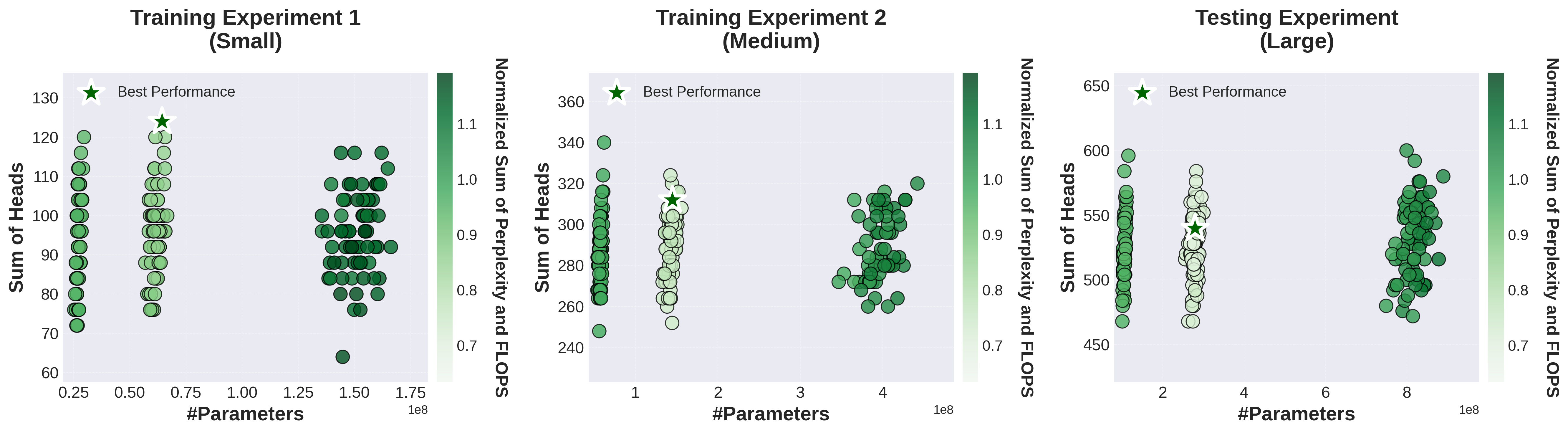
Figure 9: Optimization landscape for model architecture configuration, illustrating ruggedness and local minima.
Theoretical Implications and Future Directions
AutoLLMResearch provides a formal framework for cumulative, cross-fidelity experiential learning in scientific agentic optimization, and is a concrete advancement towards recursive self-improvement paradigms. The decoupling of knowledge accumulation from expensive experiment execution opens avenues for scalable agent-driven research in other domains (materials science, biology, etc.), where cheap proxy experiments can inform and accelerate high-fidelity exploration.
Potential directions include expanding Gym tasks, enabling multi-objective optimization, and integrating deeper recursive design strategies to automate future LLM training and configuration workflows.
Conclusion
AutoLLMResearch establishes a robust methodology for automating high-cost LLM configuration tasks by training agents that accumulate transferable principles from low-fidelity experiments. The resulting RL-trained LLM agents exhibit strong cross-fidelity generalization, interpretability, and practical scalability, outperforming conventional baselines on multiple axes and informing future trajectories in agent-driven scientific discovery.