Spend Less, Fit Better: Budget-Efficient Scaling Law Fitting via Active Experiment Selection
Abstract: Scaling laws are used to plan multi-million-dollar training runs, but fitting those laws can itself cost millions. In modern large-scale workflows, assembling a sufficiently informative set of pilot experiments is already a major budget-allocation problem rather than a routine preprocessing step. We formulate scaling-law fitting as budget-aware sequential experimental design: given a finite pool of runnable experiments with heterogeneous costs, choose which runs to execute so as to maximize extrapolation accuracy in a high-cost target region. We then propose an uncertainty-aware method for sequentially allocating experimental budget toward the runs most useful for target-region extrapolation. Across a diverse benchmark of scaling-law tasks, our method consistently outperforms classical design-based baselines, and often approaches the performance of fitting on the full experimental set while using only about 10% of the total training budget. Our code is available at https://github.com/PlanarG/active-sl.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making big AI training projects cheaper and smarter. It focuses on “scaling laws,” which are simple math rules that predict how a model’s performance changes as you grow things like model size, data, or compute. Companies often use scaling laws to plan huge (and very expensive) training runs. The twist is: even building those scaling laws can cost a lot, because you have to run many smaller “pilot” trainings first. This paper shows how to choose a small number of the most useful pilot runs so you can spend less money while still fitting a scaling law that predicts well at large, expensive scales.
What questions were the researchers trying to answer?
- Given a limited budget and a list of possible pilot experiments (each with a different price tag), which ones should we run to best predict performance in the big, expensive settings we actually care about?
- Can we actively and sequentially pick the next experiment that teaches us the most about those large-scale predictions, instead of guessing or following simple rules?
- Will this careful experiment selection approach beat standard methods and save a lot of money?
How did they approach the problem?
Think of planning a road trip into unknown territory (the big, expensive training runs). You can’t afford to drive everywhere, so you first take a few short “scouting trips” (small pilot runs) to learn the lay of the land and predict what the long road will be like. The paper turns this into a step-by-step decision process:
- Start with a menu of pilot experiments You have a fixed list of possible experiments (like different model sizes, data amounts, learning rates, etc.). Each one has a cost.
- Aim at a target region You care most about predicting performance in the “target region,” which is the big, high-cost area where you’ll actually train later. You won’t run many pilots there because it’s too expensive, but you want excellent predictions there.
- Keep multiple “plausible stories” in mind Early on, several different scaling-law curves might fit the small amount of data you’ve seen. The authors call these different “basins” (think: multiple believable explanations for the same early evidence).
- Measure uncertainty where it matters
The method estimates:
- “Within-basin” uncertainty: how fuzzy each plausible curve is when predicting the target region.
- “Between-basin” disagreement: how much the plausible curves disagree with each other in the target region.
- Pick the next experiment that reduces uncertainty per dollar For each candidate experiment, the method asks: “If we ran this experiment, how much would it reduce what we don’t know about the target region?” It then divides this gain by the experiment’s cost. The experiment with the biggest “uncertainty reduction per dollar” is chosen next.
- Repeat until the budget runs out After each run, update what you’ve learned, re-check uncertainty, and pick the next best experiment. This is called “active” or “sequential” experiment selection.
In everyday terms: they choose the next “practice run” that teaches the most about how things will work at the expensive, full scale—while carefully watching the budget.
Key ideas in the method (in simple terms)
- Keep several likely curves, not just one, because early data can be misleading.
- Focus learning on the large, expensive settings (the target region), since that’s where decisions matter most.
- Balance value and price: prefer experiments that reduce uncertainty a lot for a reasonable cost.
How did they test it?
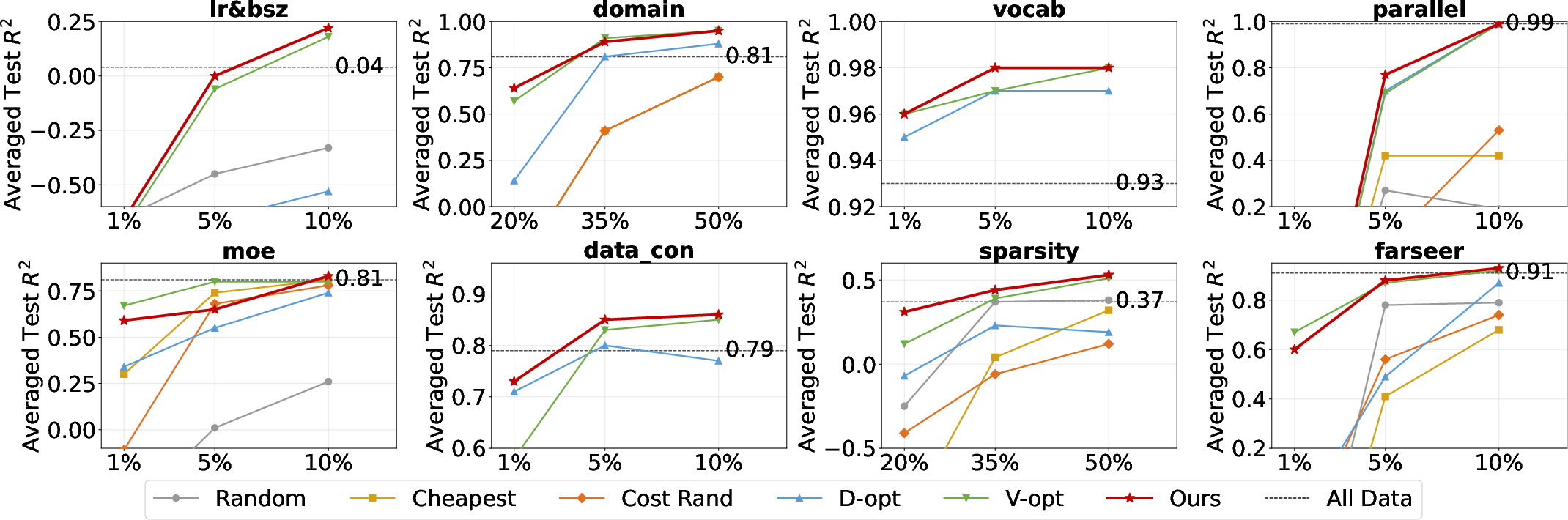
They built a benchmark with 8 different types of scaling problems (like tuning learning rate and batch size, choosing vocabulary size, using mixture-of-experts, sparsity, and more). In total, they tried 65 different scaling-law setups. They compared their method against:
- Simple strategies like random choice or always picking the cheapest experiments.
- Classic design methods (known in statistics) that try to pick points to best learn parameters or reduce prediction error, but typically use just one local approximation.
They measured how accurate predictions were in the target (large, expensive) region for very small budgets (like 1%, 5%, or 10% of the total possible pilot costs).
What did they find?
- Their method usually beat the baseline methods, especially when the budget was very tight (like 1% or 5% of total pilot cost).
- With about 10% of the total pilot budget, their approach often got close to the accuracy you’d get if you used all the data (which could cost 10 times more).
- Sometimes their method even did better than “using all the data.” That sounds odd, but here’s why: if the math formula (the scaling law) doesn’t perfectly match reality, adding lots of cheap, small-scale points can pull the fit in the wrong direction for predicting big, expensive settings. Carefully chosen points that teach you about the target region can be better than “everything.”
- An “ablation” (a test to see which parts matter) showed that both kinds of uncertainty help:
- Reducing fuzziness within one plausible curve is very important.
- Reducing disagreement between different plausible curves also helps, especially when many explanations are still possible.
Why does this matter?
- Saves serious money: Fitting scaling laws can cost a lot on its own. This method helps you learn the most while spending a lot less (often around 10% of the usual budget).
- Better planning: If you can predict big, expensive runs accurately, you can plan training more confidently and avoid waste.
- Works across many settings: It’s not tied to one specific problem. It applies to various decisions in LLMs, like hyperparameters, data choices, architectures (e.g., mixture-of-experts), sparsity, and even inference-time decisions.
- Changes how we think about scaling laws: It shows that building scaling laws isn’t just a modeling problem—it’s also about smart experiment design and budget allocation.
In short, the paper offers a practical way to “spend less, fit better” by actively choosing the most informative pilot runs, aiming predictions right where they matter most.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains uncertain or unexplored in the paper, phrased to guide concrete follow-up research.
- Assumption of a correct parametric law: The method assumes a fixed parametric scaling law
y=f(x;θ); there is no mechanism to detect or adapt to misspecification, nor to select among competing law families during design. - Noise model simplification: Observation noise is modeled as homoskedastic Gaussian with fixed
σ^2; heteroskedastic, heavy-tailed, or scale-dependent variability common in large-scale training is not modeled or estimated from replicates. - No replication strategy: The design does not consider allocating budget to repeated runs to empirically estimate noise and instability, which may be critical for reliable uncertainty quantification at large scale.
- Posterior approximation limitations: The posterior over
θis approximated by a mixture of local Gaussian basins via Laplace-like local fits; robustness under strong nonlinearity, non-identifiability, flat directions, or highly multimodal landscapes is untested. - Basin discovery and weighting: There is no principled method for selecting the number of basins
K, covering all plausible basins, or assigning mixture weightsw_kbeyond local refits; sensitivity to initialization and missed modes is not analyzed. - Local linearization accuracy: The acquisition relies on Jacobians and local linearization around each basin; accuracy for far extrapolation to the target region or in highly nonlinear laws is not quantified or improved via higher-order approximations.
- Myopic (greedy) design: The sequential selection is one-step myopic; potential benefits of non-myopic/lookahead design (e.g., rollout, tree search, approximate dynamic programming) or theoretical regret bounds are not explored.
- Batched/parallel design: Many real workflows run experiments concurrently; the method does not provide a batched acquisition strategy that accounts for parallel execution and delayed feedback.
- Cost model realism: Costs use simple proxies (e.g.,
6ND,NE); real-world cost variability (system effects, scheduling, failures, preemption) and uncertainty in cost estimates are not modeled. - Unknown or evolving targets: The target region
𝒳_taris assumed known and fixed; practical settings often have evolving targets or multiple downstream objectives, which the current acquisition does not accommodate. - Utility alignment with decisions: The acquisition optimizes target-region MSPE, not downstream decision quality (e.g., probability of selecting the best final configuration, expected regret, or compute-optimal allocation); decision-aware utilities are not studied.
- Multi-objective outcomes: The framework handles a single scalar
y; real deployments track multiple metrics (e.g., loss, perplexity, downstream tasks, efficiency), trade-offs, and constraints, which are not incorporated. - Constraints and feasibility: Hard constraints (stability limits, memory, hardware availability) and safety constraints (avoiding catastrophic runs) are not integrated into the design.
- Continuous design spaces: The method assumes a finite, pre-specified candidate pool; extending to continuous design (e.g., continuous LR/BSZ ranges) with on-the-fly proposal generation is not addressed.
- Candidate pool expansion: How to expand or refine the candidate set adaptively (e.g., by proposing new hyperparameter combinations that are not pre-enumerated) remains open.
- Hyperparameter sensitivity: Key meta-parameters (e.g., cost exponent
α, warm-start size2.5p, number of initializations) are fixed; sensitivity analyses and adaptive schemes for setting them are absent. - Computational overhead: The cost and scalability of repeated multi-start refitting, basin estimation, Jacobian evaluations over
|𝒳_tar|, and quadrature for each candidate are not quantified relative to training costs, especially under tight budgets. - Scalability with law dimensionality: Empirical scaling and failure modes as parameter dimension
pgrows (e.g.,p≈29in “domain”) are not systematically analyzed. - Calibration of uncertainty: Predictive uncertainty calibration (e.g., coverage of credible intervals on
𝒳_tar) is not evaluated; only point-accuracy (R^2) is reported. - Heteroskedastic target weighting: The MSPE over
𝒳_taruses uniform averaging; practical planners might weight target points by importance, risk, or cost—this is not supported. - Robustness to distribution shift: Potential mismatch between the candidate pool and target region (covariate shift) is acknowledged empirically but not explicitly modeled or corrected in the acquisition.
- Model selection within the loop: There is no mechanism to compare or switch law families during the sequential design based on predictive performance on
𝒳_tar. - Comparison to Bayesian OED: The paper adapts D-opt/V-opt but does not compare against scalable goal-oriented Bayesian OED (e.g., EIG on predictions) or provide computationally efficient approximations thereof for this setting.
- Multi-fidelity experiments: The method assumes full-fidelity runs; leveraging partial training, truncated runs, proxy metrics, or learning-curve extrapolation for cheaper information is left unexplored.
- Non-stationary training dynamics: Training instabilities (e.g., divergence at certain LR/BSZ pairs) and non-stationary effects over training duration are not modeled in the design or law.
- Early stopping and failure handling: The framework does not plan for early termination, failure probability, or adaptive stopping criteria to save budget.
- Decision-theoretic end-to-end evaluation: Beyond
R^2, there is no end-to-end assessment of how the method affects final training choices and realized downstream performance under fixed global budgets. - Theoretical guarantees: There are no consistency, sample-efficiency, or approximation guarantees for the acquisition’s target MSPE reduction, nor bounds under misspecification.
- Generalization beyond benchmarks: External validity to real industrial-scale pipelines with nontrivial resource constraints, scheduling, and changing objectives is not demonstrated.
- Extension to non-differentiable laws: The acquisition requires differentiability of
fw.r.t.θ; handling piecewise or non-differentiable forms (often used in practice) is not discussed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with the method and code released in the paper, along with likely sectors, potential tools/products/workflows, and key assumptions/dependencies.
- Active pilot-run selection for LLM pretraining and finetuning
- Sectors: software/AI, cloud, enterprise ML
- Tools/products/workflows:
- Integrate “active scaling-law designer” into MLOps platforms (e.g., Ray Tune, Weights & Biases, MLflow) to sequentially choose the next training run that maximizes target-region extrapolation accuracy per dollar.
- FinOps dashboards showing expected error reduction per cost and recommended next runs; compute-optimal training planners (Chinchilla-style) that require far fewer pilots.
- Workflow: define a candidate pool (model/data size, LR/BSZ grid, etc.), specify a target region (e.g., 1B params at 100B tokens), set a budget; the selector proposes runs iteratively until the budget is exhausted.
- Assumptions/dependencies: a parametric scaling-law family is specified; a finite candidate set is enumerated; cost proxies (e.g., FLOPs) are available; observations are approximately Gaussian noise; differentiable models for Jacobians; enough initializations to identify plausible basins.
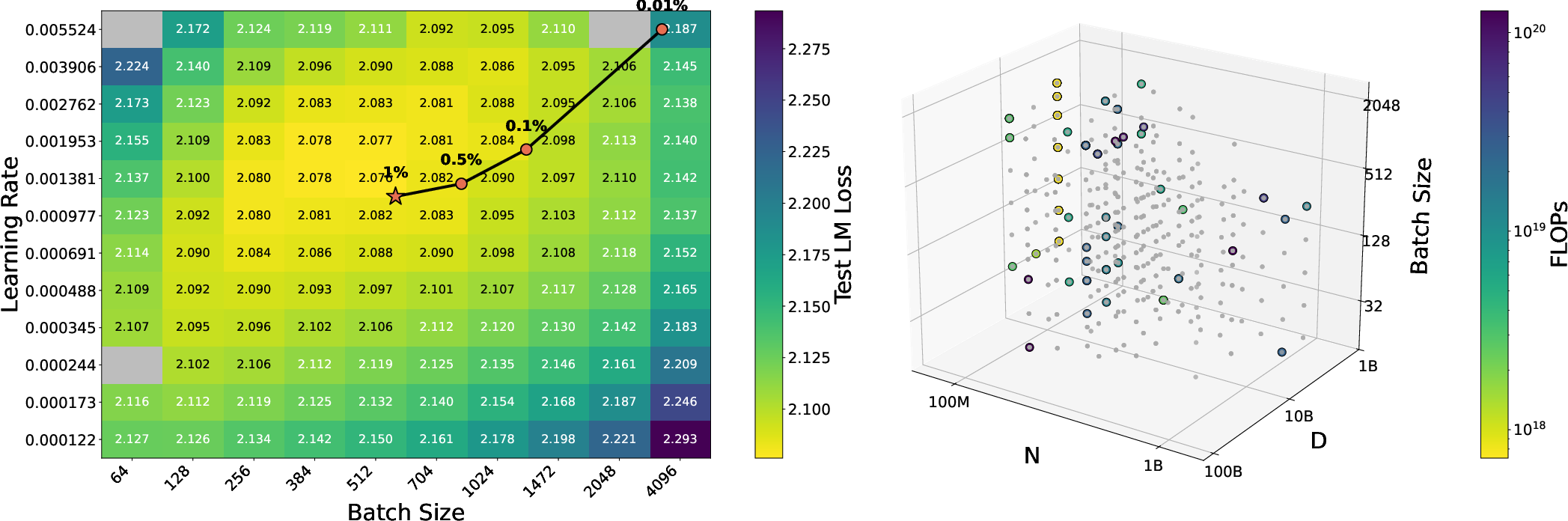
- Cost-efficient hyperparameter surfaces for dense LLM training (e.g., LR–batch size, sequence length–batch size)
- Sectors: software/AI
- Tools/products/workflows:
- “Hyperparameter surface explorer” that reaches near-optimal LR/BSZ regimes using ~1–10% of the traditional pilot budget.
- Assumptions/dependencies: viable LR/BSZ ranges; the chosen scaling-law form captures the dominant curvature in the target region.
- Data-mixing and token allocation planning (domain mixtures, dataset sizes)
- Sectors: education, enterprise AI, content platforms
- Tools/products/workflows:
- “Data allocation autopilot” that selects a small number of mixtures and token counts to accurately extrapolate to large-scale target mixes; reduced labeling/curation costs.
- Assumptions/dependencies: stable relationship between domain mix and loss in the modeled family; accurate cost accounting for data procurement and training.
- Vocabulary size and tokenization studies
- Sectors: software/AI
- Tools/products/workflows:
- “Tokenizer budget optimizer” that recommends a small set of vocab sizes to run and then predicts the optimal vocab for target scale.
- Assumptions/dependencies: parametric law includes vocab-size dependence; tokenizer training costs and their impact on compute are known.
- Mixture-of-Experts (MoE) and sparsity trade-off exploration
- Sectors: software/AI, energy (efficiency), hardware
- Tools/products/workflows:
- “Sparse/MoE planner” to select few expert-count/sparsity configurations that best extrapolate performance at target compute.
- Assumptions/dependencies: cost proxy reflects routing/sparsity overheads; law family captures nonlinearity from sparse activations.
- Inference-time scaling optimization (e.g., best-of-n, decoding parameters) with minimal trials
- Sectors: software/AI, consumer apps
- Tools/products/workflows:
- “Inference budget tuner” that uses a handful of runs to predict utility of large n or decoding schedules for production SLAs.
- Assumptions/dependencies: stable mapping between inference parameters and quality; target region is well-defined (e.g., latency/quality frontier).
- HPC/Scientific simulation experiment design under compute budgets
- Sectors: energy (grid simulations), climate, materials science, aerospace
- Tools/products/workflows:
- Apply the acquisition function to select simulation points that maximize prediction accuracy in high-fidelity regimes; embedded into workflow engines (e.g., Slurm/Kubernetes plugins).
- Assumptions/dependencies: a parametric response surface is available; simulation outputs are differentiable or can be locally linearized.
- Budget- and carbon-aware experimentation for sustainability
- Sectors: cross-sector, ESG
- Tools/products/workflows:
- “Green-experiments” mode that allocates runs by expected error reduction per kgCO2e; reporting modules for CO2 savings versus baselines.
- Assumptions/dependencies: reliable carbon-intensity estimates for compute; cost model aligns with carbon proxies.
- Grant proposal and internal budgeting support for AI R&D
- Sectors: academia, industry R&D
- Tools/products/workflows:
- Pilot-justification calculators that translate a fixed budget into predicted target-region accuracy; portfolio scenarios to choose among law families.
- Assumptions/dependencies: candidate pools and target regions scoped in advance; institutional cost constraints known.
- Robust A/B test planning for model variants (architectures, optimizers)
- Sectors: software/AI
- Tools/products/workflows:
- Use the acquisition score to pick the next variant-scale pair to compare under tight budgets; reduces misallocation to uninformative scales.
- Assumptions/dependencies: shared parametric form or comparable response surfaces across variants; comparable evaluation metrics.
Long-Term Applications
These opportunities require further research, scaling, or ecosystem development before routine deployment.
- End-to-end “training autopilot” that jointly selects pilots and schedules full-scale training runs
- Sectors: software/AI, cloud
- Potential products/workflows:
- Closed-loop orchestration combining active selection, live cost telemetry, and automatic escalation from pilot to deployment training.
- Additional needs: robust online cost estimation; dynamic nonstationary modeling (e.g., shifting data quality); safety/rollback policies.
- Generalized optimal experimental design for nonparametric or meta-learned scaling laws
- Sectors: software/AI, scientific computing
- Potential products/workflows:
- Replace parametric forms with neural surrogates or Gaussian processes; acquisition optimized for target-region predictive metrics.
- Additional needs: uncertainty quantification for flexible models; scalable posterior approximations beyond local linearizations.
- Cross-org compute marketplaces optimizing “expected accuracy per dollar”
- Sectors: cloud, policy, finance
- Potential products/workflows:
- Market mechanisms or procurement tools where experiment proposals are scored by utility-per-cost to allocate shared HPC/AI cycles.
- Additional needs: standardized cost/utility reporting; governance and auditability; privacy-preserving disclosure of candidate pools.
- Regulatory and funding guidelines for safe, efficient large-scale AI experimentation
- Sectors: policy, public sector, NGOs
- Potential products/workflows:
- Best-practice frameworks that require budget-aware design to minimize unnecessary compute and emissions; review tools for grant panels.
- Additional needs: consensus on accepted cost proxies, carbon accounting, and uncertainty metrics; sector-specific benchmarks.
- Multi-objective design (accuracy, robustness, fairness, safety) for pilot selection
- Sectors: healthcare, finance, public sector AI
- Potential products/workflows:
- Acquisition functions that trade off target-region error with fairness or robustness metrics; selective pilots to probe worst-case behaviors.
- Additional needs: validated multi-objective scaling laws; domain-specific constraints and guardrails.
- Hardware- and scheduler-aware acquisition in heterogeneous clusters
- Sectors: hardware, cloud
- Potential products/workflows:
- Acquisition that accounts for memory bandwidth, interconnect topology, spot pricing, and failure risk to schedule the most informative runs.
- Additional needs: joint cost models combining time, reliability, and monetary cost; interfaces with cluster schedulers.
- Real-time inference optimization in production with user-feedback loops
- Sectors: consumer apps, enterprise SaaS
- Potential products/workflows:
- Continuously choose low-cost probing configurations to predict quality at high-cost inference settings, then adapt policies in real time.
- Additional needs: streaming feedback integration; safe exploration constraints; latency-aware acquisition.
- Application to costly physical-world experimentation (robotics, manufacturing, biotech)
- Sectors: robotics, manufacturing, healthcare/biotech
- Potential products/workflows:
- Use target-aware, cost-weighted acquisition to select minimal real-world trials that extrapolate to production scales or human-in-the-loop settings.
- Additional needs: reliable cost and risk models for physical trials; robust noise models beyond Gaussian; safety constraints.
- Standardized “scaling-law design” curricula and benchmarks across domains
- Sectors: academia, education
- Potential products/workflows:
- Courseware and public benchmarks for budget-aware design in ML and experimental sciences; shared libraries interoperable with DOE toolkits.
- Additional needs: domain-tailored law families; community datasets and reproducibility standards.
- Organization-wide FinOps for AI with carbon/compute SLAs
- Sectors: enterprise IT/finance, ESG
- Potential products/workflows:
- Corporate policies and tools that require active design for any compute-intensive ML project, tracked against budget and emissions SLAs.
- Additional needs: integration with accounting systems; verifiable reporting; cultural adoption.
Notes on feasibility dependencies common to many applications:
- The approach presumes a reasonably specified parametric scaling-law family and differentiability for Jacobian-based utilities. Severe misspecification reduces reliability.
- Accurate, comparable cost proxies are essential; misestimated costs distort acquisition.
- Defining the target region is critical; poor target specification leads to irrelevant acquisitions.
- The mixture-of-Gaussians basin approximation relies on multiple restarts and local posterior approximations; insufficient initializations or highly chaotic landscapes can degrade performance.
- While selection overhead is small relative to pilot training costs, extremely tight latency constraints may need lighter-weight approximations.
Glossary
- Ablation study: An analysis that removes or isolates components of a method to assess their contributions to performance. "Ablation study of the acquisition function."
- Acquisition function: A scoring rule used to prioritize which experiment to run next based on expected utility. "To understand which parts of our acquisition function are responsible for the observed gains"
- Basin: A locally optimal region in parameter space corresponding to one plausible fit of the model. "We call each locally optimal fit of the scaling law a basin."
- Bayesian optimal experimental design: A framework that selects experiments by maximizing expected utility under a posterior over model parameters. "Bayesian optimal experimental design addresses parameter uncertainty by optimizing expected utility under a posterior distribution"
- Budget-aware sequential experimental design: Experiment selection that accounts for costs while choosing a sequence of runs to maximize downstream accuracy. "We formulate scaling-law fitting as budget-aware sequential experimental design"
- Candidate pool: The predefined finite set of runnable configurations from which experiments can be selected. "we consider a candidate pool"
- Chinchilla-style compute-optimal training: A training regimen that balances model and data scale to achieve optimal performance for a fixed compute budget. "Chinchilla-style compute-optimal training was derived from an extensive empirical study"
- Compositional mixture laws: Scaling-law forms that combine multiple components or regimes into a composite predictive relationship. "compositional mixture laws"
- Cost-aware score: A utility measure that normalizes expected benefit by experiment cost to guide selection. "we rank candidates by the cost-aware score"
- D-optimality (D-opt): A design criterion that seeks experiments maximizing the determinant of the information matrix, reducing overall parameter volume of uncertainty. "D-opt selects the candidate that maximizes the increase in a D-optimality objective"
- Extrapolation: Predicting performance in a regime beyond observed data, typically at larger scales. "maximize extrapolation accuracy in a high-cost target region."
- Fisher information matrix: A matrix capturing how sensitive model predictions are to parameters, used to quantify information in designs. "with criteria such as D-optimality and A-optimality defined through the Fisher information matrix"
- FLOPs: Floating point operations; a proxy for compute cost used to measure training budget. "using only a small fraction of the original fitting FLOPs"
- Gaussian noise: Random noise assumed to be normally distributed, added to model outputs. "and noise ."
- Jacobian: The matrix of first derivatives of model predictions with respect to parameters, used to propagate uncertainty. "is the Jacobian of evaluated at ."
- L-BFGS-B: A limited-memory quasi-Newton optimization algorithm that handles bound constraints. "using L-BFGS-B from 64 initialization points."
- Local linearization: Approximating a nonlinear model by its first-order Taylor expansion around a current parameter estimate. "both D-opt and V-opt locally linearize the nonlinear scaling law"
- Mean squared prediction error (MSPE): The average squared deviation of predicted values from their mean or truth over a region of interest. "We use the target-region mean squared prediction error"
- Mixture-of-experts architectures: Models that route inputs to different expert subnetworks, combining their outputs. "mixture-of-experts architectures"
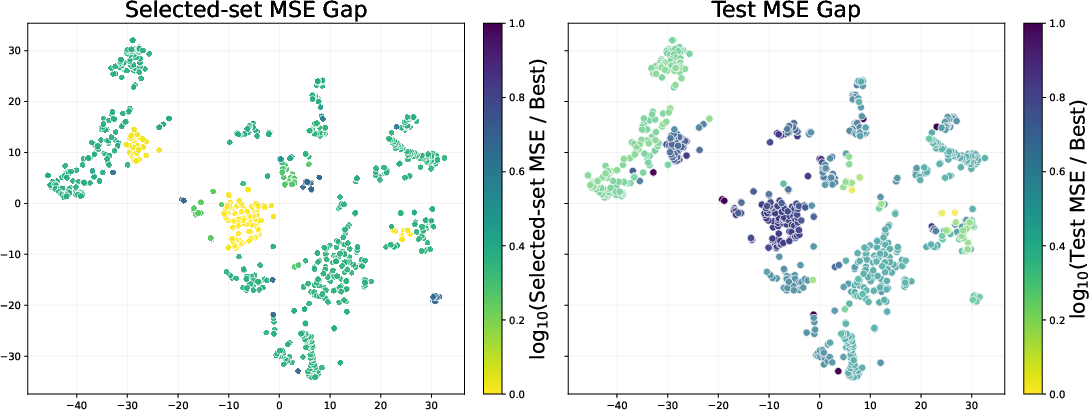
- Model misspecification: A mismatch between the chosen model family and the true data-generating process. "Under model misspecification, adding more training points can even hurt extrapolation"
- Numerical quadrature: A technique for approximating integrals by weighted sums, used here to compute expected utilities. "we evaluate it efficiently using numerical quadrature."
- Posterior (distribution): The probability distribution over parameters after observing data. "approximate the posterior: "
- Predictive distribution: The distribution of possible outcomes for a new experiment given current data and parameter uncertainty. "The predictive distribution is the scalar mixture"
- Predictive variance: The variance of model predictions over a set or region, reflecting uncertainty in outputs. "reduce predictive variance over the target region."
- Power laws: Functional relationships where a quantity scales as a power of another, often used in scaling-law modeling. "classical power laws"
- R2: The coefficient of determination measuring how well predictions explain variance in outcomes. "Performance is measured by target-region "
- Response surfaces (hyperparameter response surfaces): Models of performance as a function of hyperparameters across a design space. "hyperparameter response surfaces"
- Scaling laws: Parametric relationships linking model performance to variables like model size, data, or compute. "Scaling laws have become a central tool for analyzing and planning large-scale LLM training"
- Sequential design: An iterative procedure that selects experiments one at a time based on current results. "We now describe our sequential design strategy"
- Target region: The high-cost, large-scale configuration space where accurate predictions are most needed. "a held-out target region for evaluation."
- t-SNE: A nonlinear dimensionality reduction method for visualizing high-dimensional data. "using t-SNE visualization"
- V-optimality (V-opt): A design criterion that seeks experiments minimizing average predictive variance over a target set. "V-opt selects the candidate that maximizes a V-optimality objective"
- Warm-start: An initialization technique that begins from a reasonable starting set or parameter values to stabilize subsequent optimization. "a short warm-start phase before the first criterion-based acquisition step"
Collections
Sign up for free to add this paper to one or more collections.