Spontaneous symmetry breaking and Goldstone modes for deep information propagation
Abstract: In physical systems, whenever a continuous symmetry is spontaneously broken, the system possesses excitations called Goldstone modes, which allow coherent information propagation over long distances and times. In this work, we study deep neural networks whose internal layers are equivariant under a continuous symmetry and may therefore support analogous Goldstone-like degrees of freedom. We demonstrate, both analytically and empirically, that these degrees of freedom enable coherent signal propagation across depth and recurrent iterations, providing a mechanism for stable information flow without relying on architectural stabilizers such as residual connections or normalization. In feedforward networks, this results in improved trainability and representational diversity across layers. In recurrent settings, we demonstrate the same mechanism is valuable for long-term memory by propagating information over recurrent iterations, thereby improving performance of RNNs and GRUs on long-sequence modeling tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper borrows a big idea from physics—spontaneous symmetry breaking and Goldstone modes—to help deep neural networks move information reliably through many layers or over many time steps. The authors show that if the middle (hidden) layers of a network are built to respect a continuous symmetry (like “rotate everything by the same angle”), the network naturally creates special “easy-to-carry” signals that travel stably and don’t fade or explode. That makes very deep models easier to train and helps recurrent networks remember information over long sequences.
What questions did the researchers ask?
In simple terms, they asked:
- Can we design the internal layers of a neural network so that some information “always gets through,” even in very deep networks?
- Does using symmetry inside the network create special, protected signals (like “waves” in physics) that carry information across many layers or time steps?
- Will this make deep feedforward networks easier to train without tricks like skip connections or normalization?
- Will it help recurrent networks (RNNs, GRUs) handle very long sequences better?
How did they study it?
Building symmetry‑friendly networks
- The authors make the internal layers “equivariant” to a continuous symmetry. Equivariant means: if you transform the input in a certain way, the output changes in the matching way.
- Two examples:
- U(1) symmetry: think of every hidden unit as a tiny arrow on a circle (a complex number). If you rotate all arrows by the same angle, the layer’s output also rotates by that angle.
- O(k) symmetry: group hidden units into capsules of length k—each capsule is like a little k‑dimensional arrow. Rotating any capsule in its own space doesn’t change the network’s rules.
- The input and output layers are allowed to break the symmetry; only the internal layers must follow it. That’s important: the symmetry is used as a tool for stable information flow, not because the data itself is symmetric.
Math analysis in plain terms
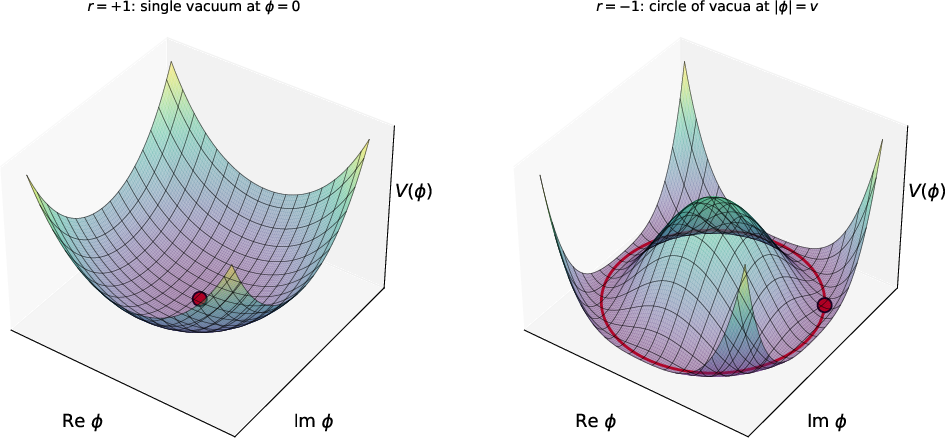
- They study what happens at initialization using a “large network” approximation (mean‑field theory). This lets them track an order parameter (a single number that summarizes the network’s state).
- Picture a marble rolling in a bowl. When the network’s weight scale is low, the marble sits at the center (everything collapses to zero—no symmetry breaking). When the weight scale is high enough, the marble settles somewhere on a ring around the center—there are many equally good choices related by rotation. That choice “breaks” the symmetry and creates a special direction (a phase or angle).
- That angle acts like a Goldstone mode—a kind of signal that can move across layers without getting squashed or blown up. In practice, it means there is a “protected lane” in the network’s input‑output sensitivity (Jacobian) that stays healthy even for deep models.
Experiments
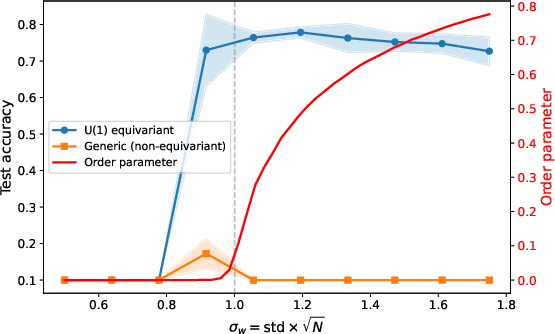
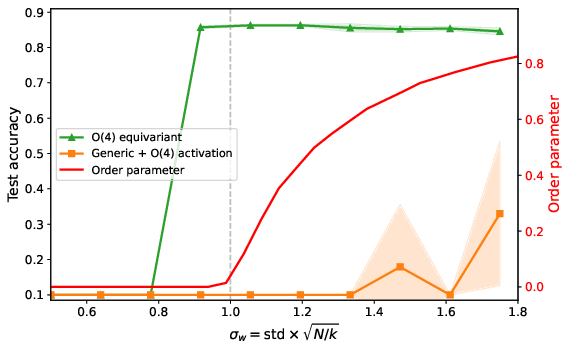
- Deep feedforward networks on Fashion‑MNIST: compare regular networks versus symmetry‑equivariant ones (U(1), O(k)) with 100 layers and no normalization or skip connections.
- Recurrent models on long‑sequence tasks:
- Variable‑delay copy task (the model must remember a short sequence after long, random delays).
- Permuted Sequential MNIST (pixels fed one by one in a random order).
- They also measure:
- The order parameter (activity size) to detect the “symmetry‑broken” phase.
- A protected component of the Jacobian (a measure of signal/gradient flow).
- The “rank” of the representation (to see if features collapse or stay diverse).
What did they find, and why is it important?
- Symmetry creates a robust information channel
- When the internal layers respect a continuous symmetry and the weights are above a threshold, the network enters a “symmetry‑broken” phase.
- In this phase, a special signal—the overall angle or “phase” of the hidden state—gets passed cleanly across many layers. This is the neural version of a Goldstone mode.
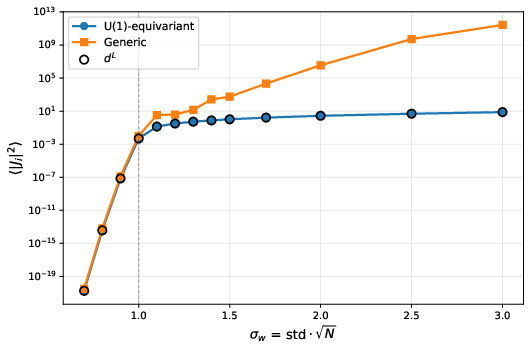
- A specific part of the input‑output Jacobian stays strong (doesn’t vanish or explode). Think of it like a permanently open lane that keeps gradients and signals flowing.
- Deep feedforward training without crutches
- Equivariant networks train well even with 100 layers and no residual connections or normalization.
- Performance improves right when the order parameter becomes non‑zero (the symmetry breaks), and it works over a wide range of weight scales—not just at the “edge of chaos.” This means less delicate tuning.
- Stronger long‑sequence memory in RNNs/GRUs
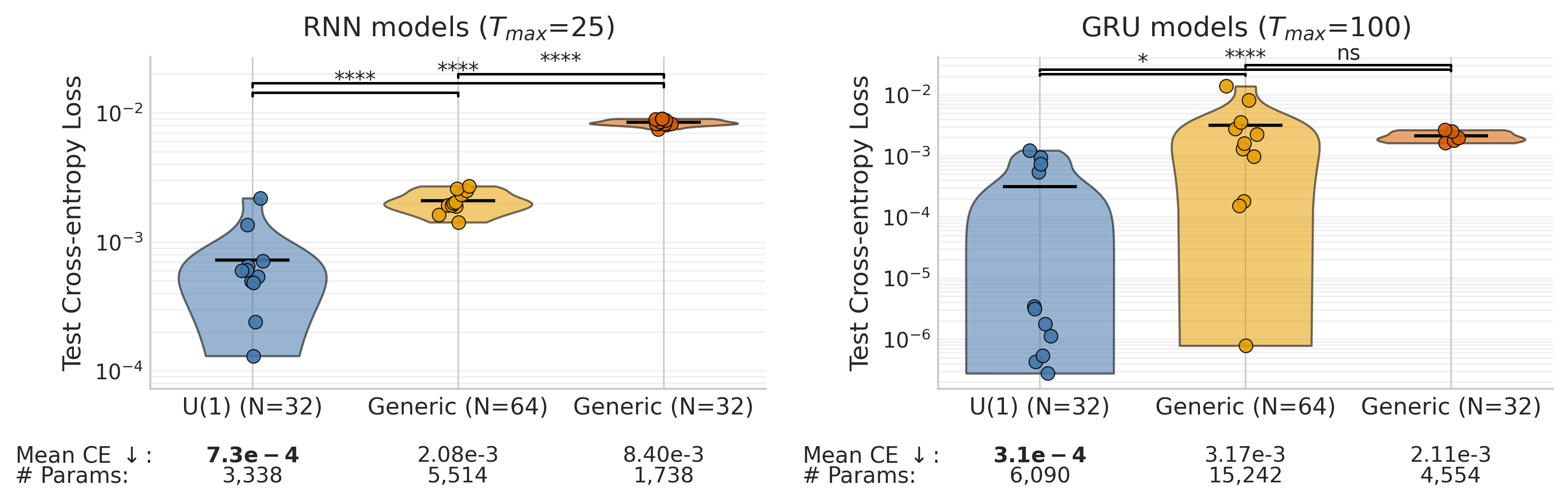
- On the variable‑delay copy task:
- U(1)‑equivariant RNNs and GRUs solved longer delays more reliably and with fewer parameters than standard models.
- For very long delays (e.g., max delay 200), only the U(1) GRU consistently solved the task in the tested settings.
- On permuted sequential MNIST:
- Equivariant RNNs and GRUs consistently beat their non‑equivariant counterparts at similar sizes.
- An O(k)‑equivariant simple RNN (no gates) reached GRU‑like accuracy, showing how powerful the symmetry channel can be.
- Bigger symmetry groups can help more
- Using O(k) symmetry (larger capsules) stores more “direction” information, which further stabilizes deep training and maintains richer representations.
- The symmetry sets a lower bound on representation rank, preventing total collapse and preserving diversity across layers.
Why this matters: these results suggest a new, physics‑inspired way to keep information alive in deep and recurrent networks—by design—rather than by careful tuning or extra architectural tricks.
What does this mean going forward?
- Symmetry as an architectural tool: Even if your data isn’t symmetric, building symmetry into the internal layers can create protected pathways for signals and gradients. This can:
- Make very deep networks easier to train without normalization or skip connections.
- Improve long‑term memory in RNNs/GRUs.
- Reduce the need for fine‑tuning at the “edge of chaos,” since there’s a wide, stable working range.
- Broader potential: This idea could combine with other long‑sequence or stable‑training designs (like modern RNNs or Transformers) to get further gains.
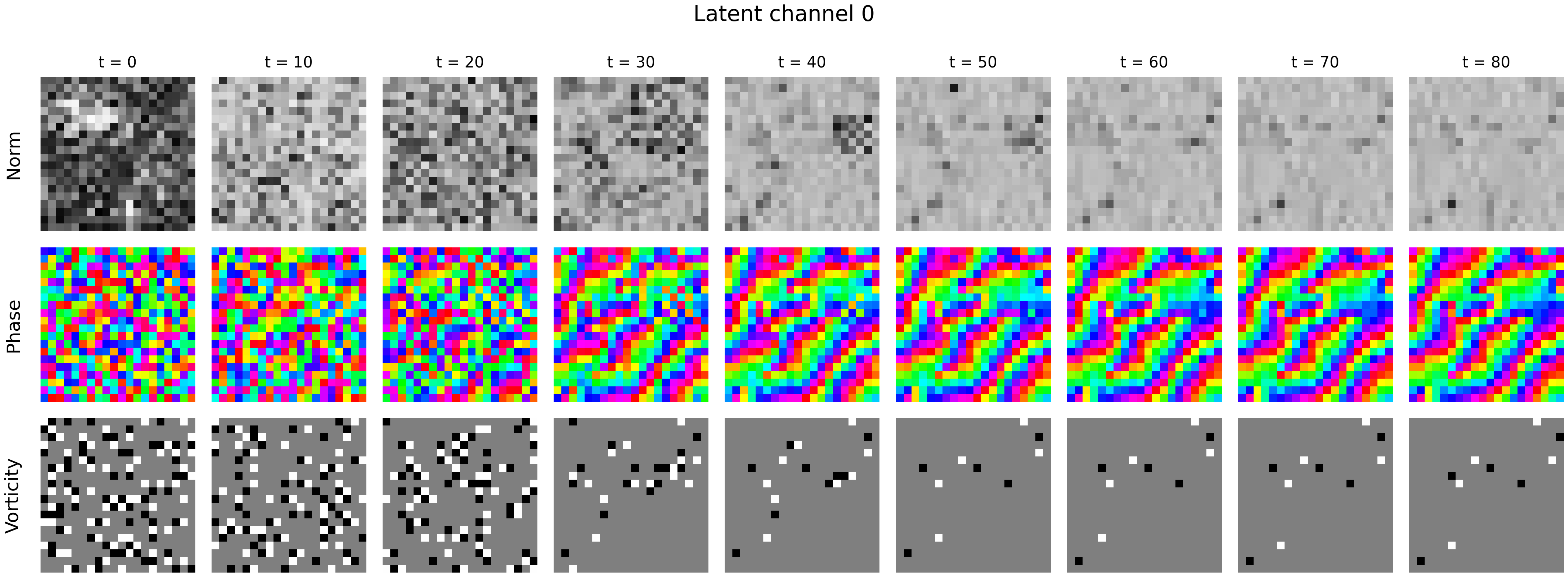
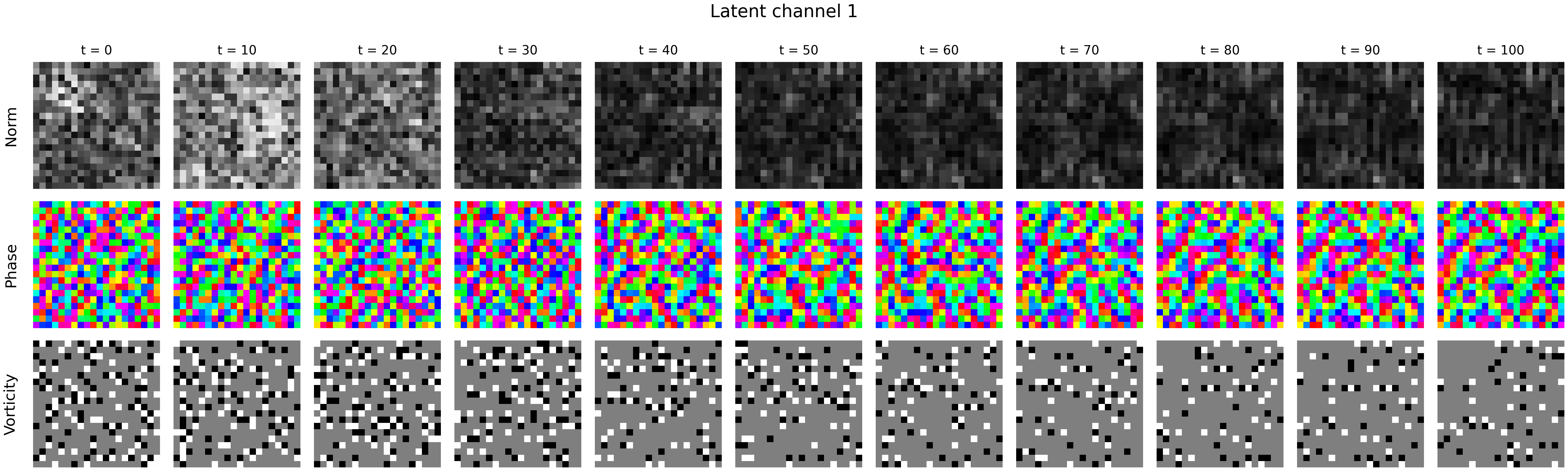
- Future directions: The authors also point to “topological defects” (other physics ideas like vortices and domain walls) as another promising way to move and store information in networks with symmetry—an exciting area for future research.
- Limitations to keep in mind: The experiments are on well‑known benchmarks and carefully controlled setups. More work is needed to test these ideas at larger scales and on diverse real‑world tasks.
In short: by borrowing the concept of spontaneous symmetry breaking from physics, the paper shows a simple, general way to keep information flowing in deep and recurrent networks—using symmetry to create a built‑in, protected signal channel that behaves like a Goldstone mode.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for follow-up work.
- Training-time theory beyond initialization: derive and validate mean-field/NTK/GP-style dynamics for , , and the protected Jacobian component under SGD (with finite step size, mini-batching, momentum, weight decay) and quantify whether SSB and Goldstone-like channels persist, strengthen, or degrade during learning.
- Finite-width effects and finite-size scaling: characterize how the SSB transition (location, sharpness) and the stability of the protected Jacobian depend on , depth , and learning time; provide finite-size scaling laws and identify minimal widths where benefits reliably appear.
- Phase boundary under realistic initializations: map how the critical line (reported at for bounded radial ) shifts with biases, nonzero input means, non-i.i.d. weights, orthogonal/He/Xavier initializations, and with common architectural elements (residual connections, normalization, gating).
- Cross-input correlation fixed point: the analysis shows with no non-trivial fixed point; identify architectural or nonlinearity modifications (e.g., alternative radial activations, coupling terms, skip/recurrence structures, noise injection) that yield to maintain non-decaying cross-input correlations at infinite depth.
- Robustness to explicit symmetry breaking: quantify how small symmetry-breaking perturbations from inputs, readouts, regularizers, or data distributions “pin” or damp the Goldstone-like channel; develop metrics for sensitivity to explicit breaking and identify regimes where benefits vanish.
- Generality across activation functions: systematically study unbounded activations (e.g., ReLU, GELU), leaky/restricted radial maps, and different gating designs to determine which activation families preserve the SSB mechanism and where the phase transition exists or disappears.
- Non-Abelian and larger groups: extend theory and experiments beyond and to non-Abelian groups (e.g., , with ), compound/product groups, and mixed representations; relate number/structure of Goldstone modes to capacity and stability, and provide design rules for group choice.
- Expressivity vs. constraint trade-offs: analyze the function class induced by constraining linear maps to (or complex-linear maps) and quantify any loss in approximation power or inductive bias mismatches relative to generic layers; identify tasks where equivariance harms performance.
- Full gradient dynamics and spectra: move beyond the protected Jacobian component to characterize the full Jacobian/Hessian spectra and Lyapunov exponents across depth/iterations; determine how many neutral/stable directions exist and how they evolve during training.
- Recurrent theory with inputs and gates: provide a principled analysis for RNNs/GRUs with input streams and gating (beyond the initialization feedforward analogy), including conditions for long-term memory, Lyapunov-neutral modes, and how gates interact with Goldstone-like channels.
- Interaction with standard stabilizers: empirically and theoretically study compatibility and interference with residual connections, LayerNorm/BatchNorm, spectral/orthogonal constraints, and initialization tricks; determine whether combinations yield additive or redundant benefits.
- Scalability and benchmarks: validate on modern, large-scale benchmarks (e.g., CIFAR-10/100, ImageNet, long-document/language modeling, long-horizon forecasting, large graphs) and contemporary architectures (CNNs, Transformers, GNNs) to assess real-world utility and limits.
- Computational and hardware costs: quantify training/inference time, memory, and numeric stability of complex weights and -capsules; assess framework support and mixed-precision behavior; provide guidelines for choosing and capsule counts under compute constraints.
- Practical design guidance: the paper lacks ablations for choosing the group, capsule size , embedding dimension, initialization scale, and learning rates; provide sensitivity analyses and heuristics for robust configuration across tasks.
- Embedding and readout choices: study how the input embedding into capsule space and the symmetry-breaking readouts impact performance and stability; compare learnable vs. fixed embeddings, tied vs. untied readouts, and their effect on the SSB channel.
- Data-dependence of the mechanism: the theory assumes generic inputs at initialization; analyze how structured, non-isotropic real data distributions and curriculum training interact with the SSB mechanism and whether they shift the effective phase boundary over training.
- Depth limits and scaling laws: provide empirical/theoretical bounds on how deep (or how many recurrent iterations) the mechanism remains effective, including how scales with width, group choice, activation, and training regime.
- Monitoring and diagnostics: develop practical estimators for , , phase , and the protected Jacobian during training on real networks (including O(k) models), and relate these metrics to training success/failure modes.
- Topological defects in spatiotemporal models: the vortex/domain-wall observations are preliminary; establish detection/quantification methods, causally test their role in computation/memory, and design architectures that use or suppress such defects as needed.
- Limits from explicit task asymmetry: since tasks/data typically lack the architectural symmetry, assess when a strong mismatch between model equivariance and task invariance degrades learning, and identify mitigation strategies (e.g., partial or learned equivariance).
- Stability under regularization and noise: evaluate how dropout, weight decay, data augmentation, label noise, and optimizer noise (e.g., AdamW) affect the SSB phase and the protected channel in both feedforward and recurrent settings.
- Formalization of “spontaneous” breaking in finite networks: provide a rigorous finite- definition and tests (e.g., susceptibility, response to infinitesimal symmetry-breaking fields), and reconcile with the fact that true SSB is subtle in finite systems.
- Multiple Goldstone modes and capacity: in , quantify how many Goldstone-like channels are functionally usable, how they interact, and how capacity scales with ; determine whether interference between modes occurs and how to exploit or avoid it.
- Relation to existing long-sequence/state-of-the-art models: systematically assess complementarity with carefully designed long-memory architectures (e.g., orthogonal/unitary RNNs, LEM, state-space models) and whether symmetry channels improve, duplicate, or hinder their mechanisms.
- Generalization and robustness: beyond small benchmarks, measure effects on test-time robustness, out-of-distribution generalization, and stability to input perturbations; determine whether the Goldstone channel encourages particular generalization behaviors or failure modes.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed with today’s tooling, using the paper’s symmetry-equivariant internal layers (e.g., U(1), O(k)), phase-preserving nonlinearities, and order-parameter–guided initialization.
- Bold: Drop-in equivariant RNN/GRU cores for long sequences (sectors: speech/audio, time-series analytics, healthcare, finance, energy, IoT)
- What it is: Replace standard recurrent cores with U(1) or O(k)–equivariant RNN/GRU cells to stabilize long-range information propagation (via Goldstone-like protected channels), improving training stability and memory over many timesteps without heavy reliance on LayerNorm, skip connections, or bespoke gating tricks.
- Tools/products/workflows:
- PyTorch/TF modules: Complex-valued U(1) RNN/GRU and real-valued O(k) RNNs where recurrent maps are A ⊗ I_k and nonlinearities are “radial” (phase- or O(k)-invariant).
- Training recipe: Initialize with σ_w > 1 (symmetry-broken regime); use magnitude-based gates for GRUs; standard optimizers.
- Monitoring: Track the protected Jacobian component dL during training to ensure signal-flow health.
- Use cases:
- Streaming ASR and keyword spotting (audio), ECG/EEG/sleep staging (healthcare), anomaly detection in sensor networks (IoT/industrial), market microstructure modeling (finance), and load/renewables forecasting (energy).
- Assumptions/dependencies: Complex ops or block-isotropic kernels available; ensure the first/last layers can break equivariance; radial activations implemented; validation that σ_w places the model in the SSB regime for the chosen nonlinearity.
- Bold: Deep MLPs without residual/normalization scaffolding for edge and embedded ML (sectors: software, on-device AI, tabular ML)
- What it is: Build very deep MLPs (≈100 layers in paper) that remain trainable by enforcing continuous symmetry in internal layers, reducing reliance on residual connections or normalization layers that complicate quantization and add latency.
- Tools/products/workflows:
- Equivariant linear blocks (complex U(1) or O(k) capsules) + radial activations; standard real-valued input/output layers.
- Quantization-friendly deployments (no LayerNorm in the core), improved portability to microcontrollers/NPUs.
- Use cases: Compact classifiers/regressors on tabular/sensor data; low-latency ranking/scoring models on device.
- Assumptions/dependencies: Benefits verified so far on mid-scale benchmarks; for large-scale tasks, expect additional engineering (regularization, data aug, optim tuning).
- Bold: Order-parameter–guided initialization and health checks (sectors: MLOps, AutoML, academia)
- What it is: Use the scalar order parameter c* at initialization (computed from the equilibrium of layerwise covariances) to choose σ_w that places the network in the SSB phase; monitor the protected Jacobian component dL during training as a stability metric.
- Tools/products/workflows:
- “c*-scanner” utility to sweep σ_w and pick values where c* > 0 (SSB) before training.
- “GoldstoneMetric” callback that logs dL and effective representation rank across layers; alerts when channels collapse.
- Use cases: Automated hyperparameter selection; early diagnosis of depth-related trainability issues; reproducible initialization policy in research.
- Assumptions/dependencies: Requires implementing the covariance estimate at init; modest compute overhead; empirical thresholds need per-architecture calibration.
- Bold: Representation-diversity floor via O(k) capsules (sectors: recommender systems, large-scale DL, vision/sequencing models)
- What it is: Prevent rank collapse in deep models by choosing capsule dimension k (O(k) symmetry), which imposes a guaranteed minimum effective rank per layer, preserving representation diversity.
- Tools/products/workflows:
- O(k)-equivariant linear maps implemented as A ⊗ I_k; radial blockwise nonlinearities.
- Hyperparameterization: select k to set a target “rank floor” for deep stacks.
- Use cases: Very deep towers in recommenders; stable feature hierarchies in deep MLP/Conv/RNN blocks; curriculum learning where rank diversity is critical.
- Assumptions/dependencies: Slight parameter/memory increase from capsule structure; performance trade-offs require tuning k and width.
- Bold: Teaching and reproducible research modules (sectors: academia/education)
- What it is: Course labs and open-source repos demonstrating spontaneous symmetry breaking, c*, and Goldstone-protected signal flow in DL.
- Tools/products/workflows:
- Ready-to-run notebooks for U(1)/O(k) MLPs, RNNs/GRUs; visualization of phase coherence φℓ and rank floors.
- Assumptions/dependencies: None beyond standard DL frameworks; useful immediately for pedagogy.
Long-Term Applications
These concepts are promising but require further research, scale-up studies, or ecosystem support.
- Bold: Long-context, streaming alternatives or complements to Transformers (sectors: speech/NLP, on-device assistants)
- Vision: Equivariant RNN/GRU/SSM backbones that maintain long memory with low latency and smaller footprints, enabling on-device, streaming ASR/translation and lightweight assistants.
- Potential products: Phase-coded memory RNN stacks; hybrid attention–equivariant RNNs that offload long-term storage to Goldstone channels.
- Assumptions/dependencies: Demonstrations at LLM/ASR scale; integration with attention; convergence and stability under large-batch training.
- Bold: Spatiotemporal forecasting with ConvRNNs and symmetry-protected memory (sectors: robotics, autonomy, climate/weather, video analytics)
- Vision: ConvRNNs endowed with U(1)/O(k) equivariance to stabilize multi-step predictions; exploration of topological defects (e.g., vortices) as robust, localized memory carriers.
- Potential products: Edge-deployable nowcasting modules; predictive maintenance from high-dimensional sensor grids; robust perception stacks in autonomy.
- Assumptions/dependencies: Empirical validation on real-world datasets; principled read/write interfaces to defect-like structures; integration with differentiable simulators.
- Bold: Hardware–software co-design for complex-valued and block-isotropic neural ops (sectors: semiconductor/accelerators, systems)
- Vision: Accelerator kernels and compiler support for complex matmul, magnitude-phase activations, and A ⊗ I_k ops; ONNX and vendor library primitives.
- Potential products: DSP/edge NPUs with native complex arithmetic; libraries exposing capsule-wise isotropic transforms and radial activations.
- Assumptions/dependencies: Vendor roadmap alignment; enough adoption to justify kernel development; standardized numerics for complex DL.
- Bold: Continual and lifelong learning with phase-coded memory (sectors: robotics, personalized AI)
- Vision: Use Goldstone-protected directions to encode stable “memory slots” (e.g., phases) that are robust to interference, mitigating catastrophic forgetting in sequential tasks.
- Potential products: Agents with persistent internal memory across tasks; personalized on-device models that retain user-specific patterns over time.
- Assumptions/dependencies: Write/read mechanisms for phase channels; compatibility with replay/regularization methods; theoretical guarantees on interference.
- Bold: Graph neural networks with symmetry-broken attractors to resist oversmoothing (sectors: drug discovery, recommendation, social/knowledge graphs)
- Vision: Equivariant internal updates introducing non-unique late-time attractors and rank floors to maintain node-level distinctions across many layers/iterations.
- Potential products: Deep message-passing stacks that remain expressive at scale; improved training stability on large graphs.
- Assumptions/dependencies: Group/action design suitable for graphs; benchmarks on molecular and large-scale industrial graphs; interplay with positional encodings.
- Bold: Explainability and health monitoring via symmetry-aware signals (sectors: regulated AI, safety, finance/health)
- Vision: Use c*, φℓ (relative phase), and the protected Jacobian dL as interpretable, physics-grounded indicators of capacity, drift, and stability in deployed models.
- Potential products: Monitoring dashboards and alarms tied to symmetry metrics; model cards reporting SSB regime/health.
- Assumptions/dependencies: Calibration across domains; regulator acceptance of new metrics; standardization of logging APIs.
- Bold: Greener AI via simpler cores (policy/industry sustainability)
- Vision: Reduced reliance on normalization and residual scaffolding in deep cores can simplify inference graphs and improve energy efficiency, especially on edge devices.
- Potential products: Procurement guidelines or best practices recommending symmetry-equipped cores for long-sequence/on-device workloads.
- Assumptions/dependencies: Independent lifecycle and energy audits; reproducible gains at production scale; toolchain maturity.
Cross-cutting assumptions and dependencies
- Task generality: Current evidence covers Fashion-MNIST and sequence benchmarks (copy task, permuted sMNIST). Scaling to large, noisy, real-world tasks is promising but unproven.
- Design constraints: Internal layers must remain strictly equivariant; input/output layers may break symmetry. Radial activations and proper σ_w initialization (SSB: σ_w > 1 for tanh-like nonlinearities) are essential.
- Interoperability: Complex-valued training and O(k) capsules require framework support and careful numerical handling; mixed-precision and quantization paths may need adaptation.
- Tuning: The symmetry group choice (U(1) vs. O(k)), capsule size k, and σ_w need validation per domain; empirical recipes for c* estimation and dL monitoring should be productized.
- Optimization: While protected channels help, standard concerns (regularization, optimization schedules, data augmentation) still apply at scale.
Glossary
- Capsule: A small group of coordinates that transforms together under a symmetry, treated as a single unit in the network. "with counting capsules (: has $2N$ real coordinates; : has )"
- Covariance matrix: A matrix collecting pairwise covariances between activations (or inputs), capturing their joint variability and phase relations. "and can construct the covariance matrix:"
- Diagonal subgroup: The subgroup consisting of simultaneous, identical actions from multiple copies of a symmetry group; arises after breaking a product symmetry to common rotations. "to a diagonal subgroup"
- Edge of chaos: A critical regime between ordered and chaotic dynamics where deep signal propagation is sustained. "i.e. to the {\it edge of chaos}, at which diverges."
- Effective rank: A measure of the dimensional diversity of representations, indicating how many directions carry significant variance. "the effective rank of the representation"
- Equilibrium statistical mechanics: The study of macroscopic properties of systems at equilibrium, often used to describe phases, order, and phase transitions. "we have borrowed the terminology from equilibrium statistical mechanics in physics"
- Equivariance: A property of a mapping that commutes with a group action: transforming the input and then applying the map is equivalent to applying the map and then transforming the output. "we use -equivariance only as a tool for propagating and processing information."
- Gaussian process: A stochastic process where any finite set of variables has a joint Gaussian distribution; used here to describe activation distributions at large width. "In the large- limit it is well-known that this evolution is given by a Gaussian process"
- Goldstone modes: Long-lived excitations arising from spontaneously broken continuous symmetries, enabling coherent, low-dissipation propagation. "excitations called Goldstone modes, which allow coherent information propagation over long distances and times."
- Hedgehogs (monopoles): Point-like topological defects in vector fields where directions radiate outward, analogous to magnetic monopoles in field theory. "hedgehogs (monopoles)"
- Jacobian: The matrix of all first-order partial derivatives of the input–output map; components indicate how input perturbations affect outputs. "a certain component of the Jacobian of the input-output map"
- Large-N limit: An analytical regime where the number of units (or dimensions) goes to infinity, simplifying dynamics via law-of-large-numbers effects. "In the large- limit it is well-known that this evolution is given by a Gaussian process"
- Long-range order: A phase property where correlations persist over large distances; in physics, often synonymous with spontaneous symmetry breaking. "equivalent to the idea of {\it long-range order}"
- Mean-field (theory): An approximation method replacing interactions with their average effect to derive tractable evolution equations. "Comparison of mean-field result for "
- O(k) (orthogonal group): The group of k×k real orthogonal transformations preserving Euclidean norms; used to define rotationally equivariant capsules. ": Here we consider a which divides and we consider as a direct sum of blocks of -dimensions each, each of which is acted on by the matrix."
- Order parameter: A quantity that distinguishes phases by being zero in one phase and nonzero in another, signaling symmetry breaking. "The order parameter which distinguishes these two phases is:"
- Permutation symmetry: Invariance under reordering of elements (e.g., tokens or features), relevant in architectures like transformers. "translational or permutation symmetry respectively."
- Phase transition: A qualitative change in system behavior as a parameter varies, such as the onset of symmetry breaking. "Note clear phase transition at ."
- Representation (of a group): A concrete linear action of a group on a vector space, specifying how activations transform under symmetry. "transforms under some representation of "
- Spontaneous symmetry breaking (SSB): A phenomenon where the dynamics are symmetric but the selected state is not, producing degenerate minima and Goldstone modes. "This is the {\bf symmetry spontaneously broken phase}."
- Stochastic path integrals: Analytical tools integrating over random trajectories to derive macroscopic dynamics of stochastic systems. "using the tools of stochastic path integrals."
- Symmetry unbroken phase: A regime where activations collapse to a symmetry-invariant state (e.g., zero), so the symmetry acts trivially. "{\bf Symmetry unbroken phase:} here we have "
- Thermodynamic limit: The limit of infinite system size where phase transitions become sharp and self-averaging holds. "with sharp transitions happening in the thermodynamic limit"
- Topological defects: Stable, localized structures (e.g., vortices, domain walls) protected by topology in symmetry-broken phases. "{\it topological defects}, localized objects such as vortices, domain walls and hedgehogs (monopoles)"
- Translational invariance: Invariance under shifts in space or time, often enforced by convolutional or recurrent architectures. "locality and translational invariance in space and time respectively."
- U(1) (unitary group): The group of complex phase rotations, here acting as a global phase symmetry on complex-valued capsules. ": in this case it is convenient to consider the representation space to be "
- Vortices: Circulation-like topological defects with winding phase, common in 2D fields and here observed as long-lived structures. "we see long-lived vortices emerging"
Collections
Sign up for free to add this paper to one or more collections.