QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
Abstract: Deep research agents extend the role of search engines from retrieving keyword-matched pages to synthesizing knowledge, fundamentally changing how humans interact with information. However, frontier systems remain proprietary, while existing open agents often generalize poorly across different task types, leaving unclear how to train a broadly capable deep research agent. We release QUEST, a family of open models (ranging from 2B to 35B) that serve as general-purpose deep research agents designed to handle a wide range of long-horizon search tasks, with strong capabilities in fact seeking, citation grounding, and report synthesis. To build QUEST, we propose an effective training recipe combining mid-training, supervised fine-tuning, and reinforcement learning. Central to this recipe is a curated data synthesis pipeline based on unified rubric trees, which applies to different task types and enables synthesizing training data with verifiable rewards without human annotation. In addition, QUEST incorporates a built-in context management mechanism that enables effective long-horizon reasoning and knowledge synthesis. Using only 8K synthesized tasks, QUEST approaches or even surpasses frontier closed-source agents across eight deep research benchmarks spanning diverse task types, and achieves the best overall performance among recent open-weight agents. We released everything: models, data, and training scripts.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Quest: Training Deep Research AI with Fully Synthetic Tasks — Explained Simply
What is this paper about? (Overview)
The paper introduces Quest, a set of AI “research assistants” that can:
- find precise facts on the web,
- back up claims with trustworthy citations, and
- write clear, well-structured reports.
The special thing about Quest is how it is trained. Instead of relying on expensive or secret datasets, the authors create their own high-quality “practice tasks” and grading checklists entirely with AI. They also share an open, reproducible recipe so others can build similar agents.
What questions were the researchers trying to answer?
In simple terms, they asked:
- How can we train one AI agent to do three things well: find hard-to-locate facts, support claims with citations, and write good reports?
- Can we build all the training tasks and grading standards automatically (synthetically) and still get strong results?
- How do we help the AI remember and manage lots of information over long research sessions?
- Which training steps (practice, imitation, and reward-based learning) matter most?
- Can smaller models (that run on modest computers) still perform well?
How did they do it? (Methods in everyday language)
Think of training Quest like coaching a student for a school research project.
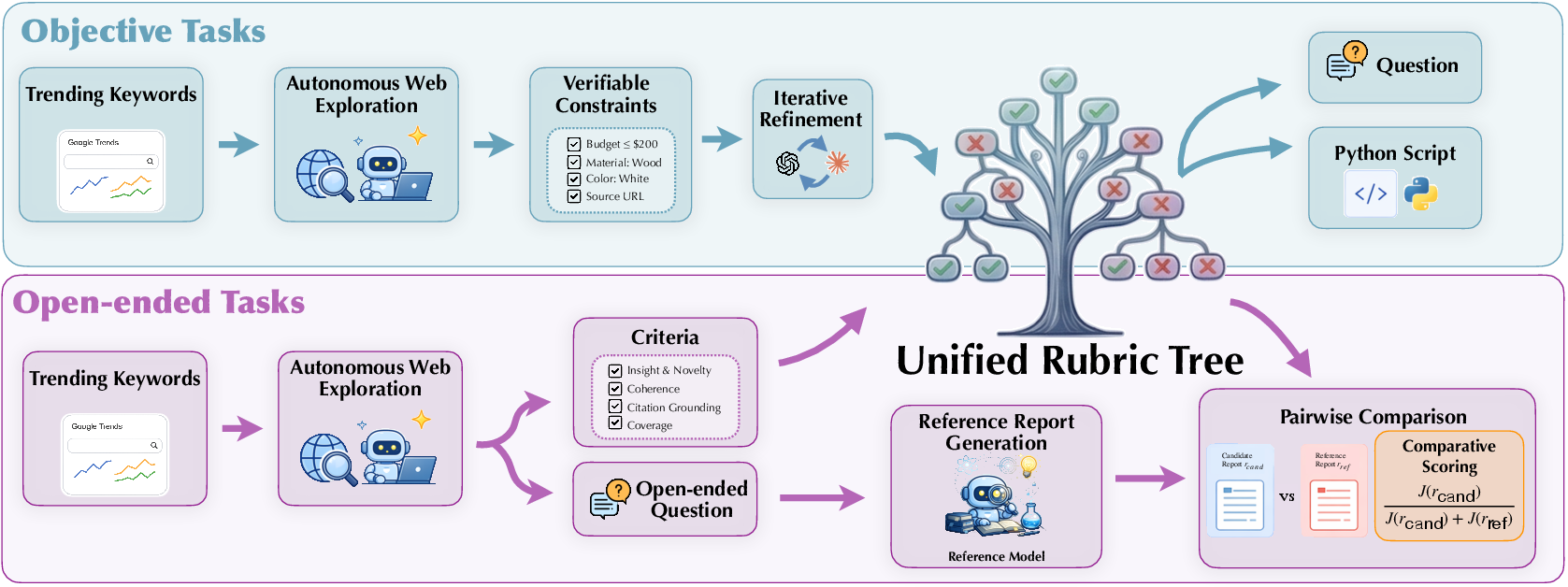
- Synthetic tasks and a “rubric tree”:
- Instead of giving the student a single “correct answer,” the coaches make a tree-like checklist (a rubric) for each task. Each leaf of the tree is a small, checkable rule (like “include a source for this claim” or “compare A and B”).
- There are two kinds of tasks:
- Objective tasks: questions with clear, checkable answers (like “Which outbreak caused more deaths?”).
- Open-ended tasks: prompts asking for a thoughtful report (like assessing a company’s new product), judged on clarity, completeness, insight, and following instructions.
- The team uses strong helper AIs to generate both the tasks and their rubrics, then to grade answers automatically. For open-ended tasks, the AI grader compares the candidate report to a reference report and scores both under the rubric (so it’s like a judge comparing two essays using the same checklist).
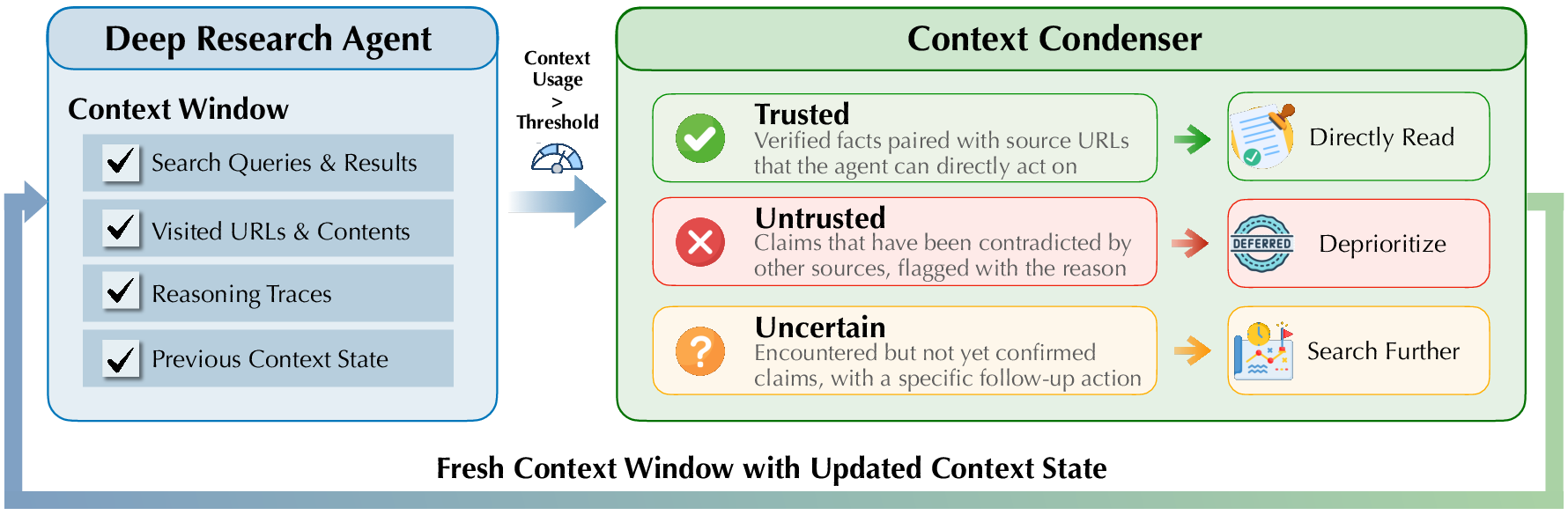
- Managing long research sessions (Context State):
- When a student’s notes get too long and messy, they pause to tidy up. Quest does the same with a “Context Condenser.”
- It compresses the whole history into a structured “Context State” (a tidy JSON) with three buckets:
- Trusted: facts that were verified with sources.
- Untrusted: claims contradicted by other sources.
- Uncertain: things that need follow-up, including suggested next searches or links.
- This lets the agent keep working for a long time without forgetting what matters.
- Training recipe (three stages, like training drills):
- summarize long histories into the Context State, and
- extract only relevant info from messy web pages (ignore ads, menus, etc.).
- 2) Supervised Fine-Tuning (SFT): Imitation learning. The model watches a “teacher” solve tasks (searching, reading pages, writing, citing) and learns to follow those steps.
- 3) Reinforcement Learning (RL): Feedback-based practice. The model gets rewards for:
- meeting the rubric (doing what the checklist asks), and
- citing facts that actually match the linked sources (fact-check reward).
- The fact-check reward only helps if the content itself is good—so it can’t “game” the system by adding perfect citations to a bad answer.
- Tool use and efficiency:
- Quest can use tools like web search, visiting pages (with smart summaries), Google Scholar, and a Python interpreter.
- To keep training fast and affordable, they cache (save) search results and web pages, and run grading in parallel so the system doesn’t waste time waiting.
What did they find, and why is it important?
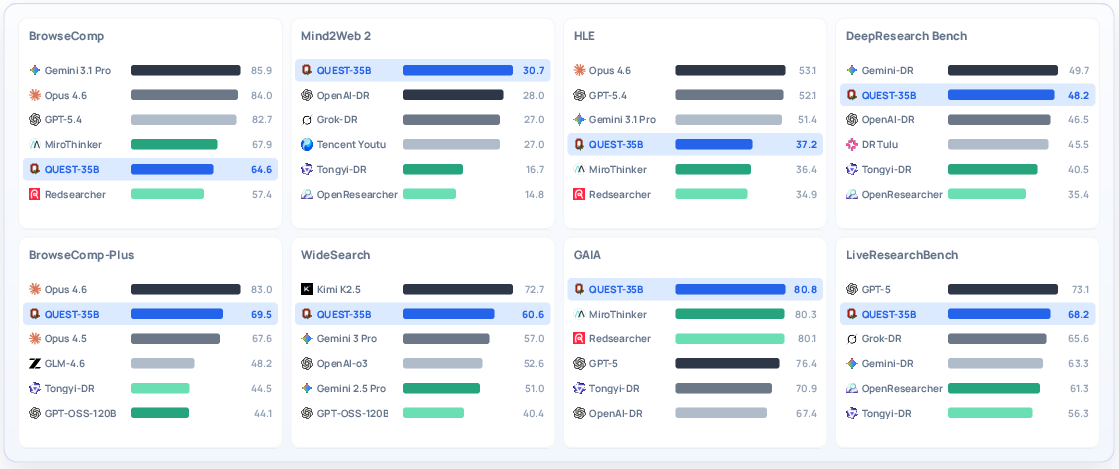
- Strong performance across 8 benchmarks:
- Quest’s largest model (35B parameters) performed very well at:
- finding facts (e.g., 64.6% on BrowseComp),
- grounding claims with citations (30.7% on Mind2Web 2), and
- writing reports (48.2% on DeepResearch Bench).
- On some tests, it even matched or beat well-known proprietary systems like OpenAI DeepResearch.
- The combination of all three training stages works best:
- Imitation alone (SFT) helped on many factual tasks but could hurt open-ended writing quality.
- Adding Mid-Training (practice drills) improved results further.
- Adding Reinforcement Learning (rubric and fact-check rewards) gave the biggest boost to open-ended report writing and citation quality.
- Together (MT + SFT + RL) gave the best overall performance.
- Small models can still be useful:
- Even the 2B and 4B versions learned good research habits. That’s promising for running privacy-friendly agents on local machines in areas like healthcare or law.
- The rubric approach matters:
- Using tree-shaped checklists and automated grading gave the model fine-grained feedback. This made it better at the three core skills: fact-finding, citation grounding, and report synthesis.
What does this mean for the future? (Implications)
- Reproducible, open path to research agents:
- The paper provides an open, end-to-end recipe for building capable research AIs without secret datasets. That helps the community improve and verify these systems.
- Better, more trustworthy AI answers:
- Because Quest learns to cite and fact-check itself, it’s more likely to give reliable, up-to-date answers—useful for students, journalists, and researchers.
- Longer, smarter research sessions:
- The Context State idea shows how an AI can work through long tasks without getting overwhelmed, keeping track of what’s known, uncertain, or disputed.
- Accessible and privacy-friendly options:
- Smaller Quest models open the door to capable research assistants that run locally, keeping sensitive information on your own device.
In short, Quest shows how to train AI to do real research work—search widely, check facts, and write clearly—using entirely synthetic practice tasks and a clear, open training process.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up work:
- Dependence on proprietary LLMs for core pipeline steps (task/rubric generation, evaluation scripts, context condenser, fact-checker/judge): reproducibility, licensing, and stability risks if those services change; need to quantify how much performance degrades when replacing them with open models.
- Quality and robustness of fully synthetic rubric trees: lack of human auditing rates, error analysis, or inter-annotator agreement benchmarks to verify rubric correctness, node coverage, and evaluability (especially for open-ended criteria).
- Vulnerability of rubric-tree and LLM-judge evaluation to reward hacking: no adversarial tests showing whether models can exploit stylistic cues, citation padding, or rubric-specific loopholes to inflate scores without substantive improvements.
- Reference-report bias in open-ended evaluation: the candidate is scored relative to a single synthesized reference; the sensitivity to reference quality/variance, and benefits of multiple references or cross-judge normalization, are unstudied.
- Judge reliability and variance: no measurement of inter-judge agreement, calibration, or score variance across prompts/runs; missing confidence intervals for evaluation metrics that rely on LLM judgments.
- Fact-checking reward reliability: “supported/unsupported/unknown” labels come from an LLM; no ground-truthing against human fact-checkers, nor analysis of false positives/negatives on nuanced claims.
- Potential gaming of fact-checking rewards: current design ignores “unknown” citations; models may learn to cite sources that are hard to verify to avoid penalties; strategies to penalize unverifiable citations are not investigated.
- Source credibility modeling: “trusted” entries rely on consistency with cited URLs, but there is no mechanism to assess source reliability or handle misinformation, paywalled content, or partisan outlets.
- Temporal robustness and web drift: extensive caching improves training efficiency, but the impact of page changes, link rot, and evolving SERPs on both training and evaluation fidelity is not analyzed.
- Context Condenser dependency and failure modes: condenser uses GPT-5-mini at inference; there is no ablation showing how condenser quality, condensation thresholds, or mis-summarization affect downstream performance and error propagation.
- Epistemic-state management validation: the trusted/untrusted/uncertain buckets are a central design choice, but no ablations show their individual contribution, transitions between states, or resilience to misclassification.
- Credit assignment across long trajectories: session-level GRPO with rollout-level rewards may dilute credit for early decisions; alternative temporal credit assignment schemes (e.g., stepwise or node-level rewards) are not explored.
- Excluding KL penalty in RL: potential for distributional drift, verbosity, or tool overuse is not quantified; no comparison to KL-regularized setups to balance stability vs. performance.
- Post-RL performance regressions on HLE/GAIA: the hypothesized “alignment tax” is not substantiated with analyses of reasoning depth, tool choices, or report style changes; mitigation strategies (e.g., multi-objective RL) are untested.
- Data scale and coverage: Quest-8K’s size and topic selection via Google Trends may bias toward contemporary, popular topics; the domain coverage, long-tail generalization, and benefits of scaling to larger, more diverse synthetic sets remain unclear.
- Overlap and contamination checks: no audit of possible overlap between synthesized tasks and benchmark content, especially given live web use and trending-topic seeds.
- Human evaluation: no human-rated assessment of report helpfulness, faithfulness, or citation quality complements LLM-based metrics; user-centric evaluations (e.g., task success, satisfaction) are absent.
- Real-world deployment metrics: latency, tool-call counts, API costs, and energy usage at inference are not reported; trade-offs between performance and cost under different tool budgets are unexplored.
- Safety and ethical considerations: no discussion of guardrails for harmful content, privacy-sensitive data, prompt injection, or browsing safety; empirical red-teaming for web-agent security is missing.
- Multilingual and multimodal generalization: experiments are limited to English and text (GAIA-Text); support for non-English tasks, images, PDFs, tables, and interactive web forms is left unaddressed.
- Tool ecosystem limitations: only Google Search, Visit (HTML summarization), Python, and Google Scholar are used; capabilities for structured data sources, APIs, spreadsheets, or form interactions are not assessed.
- Inline citation format generality: the imposed inline-URL style may not generalize to domains requiring formal citation formats; no evaluation of citation presentation preferences or robustness to format changes.
- Sensitivity to rubric weighting and discretization: open-ended rewards discretize pairwise scores into bins; effects of threshold choice and weighting noise on RL stability and policy behavior are not analyzed.
- Scaling behavior claims for small models: the paper asserts promising performance for 2B–9B models but provides limited quantitative breakdowns, compute budgets, or accuracy vs. cost scaling curves.
- Teacher–student bias: SFT trajectories depend on Tongyi-DR and GPT-5.2-polished reports; the extent to which Quest inherits teacher biases or errors, and whether it surpasses the teacher on teacher-similar tasks, is not examined.
- Fairness of baseline comparisons: some baselines are re-run under the authors’ tool infrastructure; sensitivity of results to tool chains, context policies (e.g., discard-all), and SERP differences is not evaluated.
- Robustness to evaluation design choices: the discard-all strategy is used for certain benchmarks to align with prior work; broader effects of alternative context policies on reported scores are not studied.
- Dataset and artifacts release clarity: it is unclear whether all rubric trees, evaluation scripts, and synthesized tasks (including open-ended references) are released and under what licenses; reproducibility may hinge on access to proprietary services.
- Long-horizon failure analysis: no qualitative categorization of errors (e.g., premature stopping, citing weak sources, losing subgoals) or task segments where the agent struggles; such analyses would guide targeted improvements.
- Periodic re-verification of “trusted” entries: the system reuses trusted claims without re-checking; policies for re-validation over long sessions or when sources change are not defined.
- Generalization to interactive tasks: the agent does not handle authentication, pagination, or dynamic web apps; extending and evaluating on such tasks remains open.
Practical Applications
Overview
Based on the paper “Quest: Training Frontier Deep Research Agents with Fully Synthetic Tasks,” the following lists distill practical applications that leverage Quest’s key contributions: rubric-tree–driven synthetic data and rewards, a structured context management system (Context State JSON with trusted/untrusted/uncertain entries and a Context Condenser), a three-stage training recipe (mid-training, SFT, RL) emphasizing citation grounding and report synthesis, and a scalable tool+infrastructure stack (search/visit tools, caching, asynchronous RL).
Each application indicates relevant sectors, potential tools/workflows/products, and key assumptions or dependencies that could impact feasibility.
Immediate Applications
These can be deployed now with the released open models (2B–35B), dataset, code, and the described tool stack.
- Enterprise research copilot for evidence-grounded reports
- Sectors: software, media, consulting, retail, manufacturing
- What it does: Autonomously gathers market/competitor intel and synthesizes citation-backed briefs; preserves a structured epistemic trace (trusted/untrusted/uncertain facts).
- Tools/workflows: Quest-35B or smaller on-prem variant; Google Search + Visit tool; inline citation output; Context State memory for long-horizon projects.
- Assumptions/dependencies: Web/API access (Serper, Jina) and content usage rights; governance over source credibility; sufficient compute for 35B or use 2B/4B for on-device scenarios; internal policy for storing/processing web content.
- Regulatory and compliance memo generator
- Sectors: finance, healthcare, energy, telecom
- What it does: Drafts audit-ready, rubric-scored memos that reference current regs/guidance with inline citations; uses rubric trees to enforce coverage (e.g., “instruction following,” “comprehensiveness”).
- Tools/workflows: Quest + domain-specific rubric trees; optional Google Scholar mode for citations to primary/regulator sources; Context State to track verification status.
- Assumptions/dependencies: Accurate, up-to-date regulatory sources; domain rubric customization; human review and compliance signoff; model risk management.
- Legal and IP research triage
- Sectors: legal services, corporate IP
- What it does: Collects and organizes case law, statutes, and prior art with source-backed summaries; flags conflicts and uncertainties in Context State.
- Tools/workflows: Quest with legal rubrics (coverage, jurisdiction, precedent relevance); integration with legal databases if permitted; inline-cited briefs.
- Assumptions/dependencies: Access to licensed legal databases; strict human-in-the-loop validation; jurisdiction-specific constraints on AI use.
- Scholarly literature review assistant
- Sectors: academia, R&D in biotech/materials/CS
- What it does: Conducts literature searches (Google Scholar), synthesizes findings into structured, citation-supported reviews; uses rubrics to ensure coverage/insight/readability.
- Tools/workflows: Scholar tool + Visit; inline citations; Context State to manage long reviews and avoid redundancy.
- Assumptions/dependencies: Paywalled content access; source credibility filtering (preprints vs peer-reviewed); advisor/PI approval workflows.
- Newsroom fact-checking and claim verification
- Sectors: media, public communications, NGOs
- What it does: Extracts claim–source pairs from stories, labels support status, and produces transparent, citation-backed verdicts; maintains untrusted/uncertain entries for follow-up.
- Tools/workflows: Fact-checking reward–aligned behaviors; trusted-source whitelists; newsroom rubrics (e.g., timeliness, corroboration).
- Assumptions/dependencies: Editorial standards; curated source lists; handling of dynamic or updated web pages.
- Customer support/knowledge-base synthesis
- Sectors: software, hardware, SaaS
- What it does: Aggregates FAQs, release notes, and docs into up-to-date, citation-grounded help articles; highlights conflicting/obsolete info.
- Tools/workflows: Quest + Visit; Context State for ongoing knowledge maintenance; inline-cited drafts for review.
- Assumptions/dependencies: Permission to crawl internal docs; review workflow; version control for documentation.
- Domain agent development using synthetic rubric-tree data
- Sectors: software/AI, enterprise AI teams
- What it does: Quickly bootstraps domain-specific agents using Quest’s pipeline to generate tasks, rubrics, and evaluators (objective or open-ended).
- Tools/workflows: “Rubric-tree” data synthesis recipes; evaluation script generation; RL with rubric-based and fact-checking rewards.
- Assumptions/dependencies: Access to a capable judge/generator LLM (paper uses Claude/GPT variants); prompt auditing; alignment of synthetic tasks with real-world distributions.
- Agent memory and context management module
- Sectors: software/AI platforms
- What it does: Drops in Context State JSON and Context Condenser as a memory subsystem for any long-horizon tool-using agent (beyond web research).
- Tools/workflows: Reusable memory SDK; session-based training/inference; resume-from-state workflows.
- Assumptions/dependencies: Integration with existing agent frameworks; tuning condensation thresholds; privacy policies for storing state.
- Cost-efficient tool-using agent infrastructure
- Sectors: AI infrastructure, MLOps
- What it does: Implements search/visit caching and fully asynchronous rollout–evaluation–training for RL to cut cost and latency in agent training/eval.
- Tools/workflows: Dual-cache (exact + semantic FAISS), async evaluators (Ray actors), timeout control.
- Assumptions/dependencies: Cache storage and invalidation strategy; API ToS compliance; internal reliability engineering.
- Education aids with transparent sourcing
- Sectors: education
- What it does: Generates reading lists, topic overviews, and essay outlines with verifiable citations and rubric-based coverage/readability checks.
- Tools/workflows: Student/teacher rubrics; inline citations; school IT policies for web access.
- Assumptions/dependencies: Academic integrity standards; preventing overreliance; safeguarding from low-quality sources.
Long-Term Applications
These require additional research, scaling, domain validation, or compliance approvals.
- PRISMA-grade automated systematic reviews and evidence synthesis
- Sectors: healthcare, public health
- What it could do: End-to-end literature screening, data extraction, bias assessment, and GRADE synthesis with auditable citation trails.
- Dependencies: Verified integration with medical databases; clinical validation; regulatory/IRB approval; robust de-duplication and bias controls.
- Court-admissible legal drafting with provenance
- Sectors: legal
- What it could do: Drafts motions/briefs with fully auditable evidence chains; conflicts and uncertainties systematically tracked.
- Dependencies: Jurisdictional standards for AI-generated content; bar rules; human attorney oversight; contractual database access.
- Regulated financial research automation
- Sectors: finance
- What it could do: Generates sell-side–style reports, risk/regulatory analyses, and impact assessments with structured, auditable rubrics.
- Dependencies: Model risk management (SR 11-7), compliance signoff, data entitlements, monitoring for drift and disclosure requirements.
- Government policy briefs and RIA at scale
- Sectors: government, public policy, NGOs
- What it could do: Automated generation of evidence-backed policy briefs and Regulatory Impact Analyses; transparent assumptions and source trails.
- Dependencies: Vetting by policy analysts; authoritative source catalogs; addressing judge-model bias in open-ended scoring.
- Living science maps and knowledge graphs with trust signals
- Sectors: academia, pharma, materials, energy
- What it could do: Continuously updated maps of topics with trust-weighted edges (trusted/untrusted/uncertain) and automatic change detection.
- Dependencies: Robust change-tracking for web content; deduplication; cross-source conflict resolution; UI/UX for analysts.
- Enterprise-wide secure research agents (on-prem/private data)
- Sectors: all regulated industries
- What it could do: Private deployment of 2B–9B Quest variants to research across intranet + licensed corpora with no data egress.
- Dependencies: On-prem search/visit equivalents; compute budget; security audits; domain-specific SFT/RL; latency constraints.
- Multimodal deep research
- Sectors: healthcare (radiology), manufacturing (specs), energy (satellite imagery), media
- What it could do: Incorporates PDFs, tables, figures, and images into long-horizon, citation-grounded research.
- Dependencies: Multimodal toolchain (OCR, table parsers, PDF renderers); new rubrics for multimodal correctness; model extensions.
- Cross-lingual research agents
- Sectors: global enterprises, international NGOs
- What it could do: Research across languages with source attribution and language-aware reliability scoring.
- Dependencies: Multilingual models and rubrics; cross-lingual retrieval; source credibility catalogs by locale.
- Safety-grade evaluation harnesses using rubrics
- Sectors: AI safety, certification bodies
- What it could do: Standardized rubric-tree evaluators for complex tasks as certification tests (report synthesis, citation discipline, verification).
- Dependencies: High-trust judge models or non-LLM verifiers; adversarial stress tests; reproducibility standards.
- Productized platforms and tools
- RubricTree Studio: GUI + APIs to author, validate, and version rubric trees and evaluation scripts for new domains.
- Context State Memory SDK: Drop-in memory for agent frameworks (e.g., LangChain, LlamaIndex) with trusted/untrusted/uncertain knowledge slots.
- Domain Quest variants: Pretrained checkpoints for verticals (biomed, legal, finance) with curated rubrics and source catalogs.
- Dependencies: Sustained maintenance; licensing for base models; customer data governance and audit trails.
- Autonomy in complex operational agents
- Sectors: software automation, “software robotics”
- What it could do: Reuse Context State’s epistemic tracking for long-horizon planning agents (e.g., IT ops incident investigations), enabling “what’s known vs. pending vs. contradicted” reasoning.
- Dependencies: Domain tools integration; safety interlocks; post-incident audits; task-specific rubrics for operational correctness.
Cross-cutting assumptions and risks
- Source reliability and licensing: Requires curation and policy to avoid low-credibility or unauthorized sources; dynamic pages may change post-citation.
- Judge model quality and bias: Open-ended scoring hinges on judge LLMs; domain-specific calibration and auditing are needed.
- Alignment tax: RL tuned for research/reporting may trade off some general reasoning; mitigate with multi-objective training.
- Compute and latency: 35B models need significant resources; smaller models or distillation may be needed for edge/on-prem.
- Tool/API availability: Serper/Jina/Scholar access and ToS compliance; resilient caching and invalidation.
- Human-in-the-loop: High-stakes use cases (healthcare, finance, legal) require expert oversight and documented review workflows.
Glossary
- Advantage: In policy gradient methods, the normalized excess reward used to weight updates for a rollout. "The advantage for each rollout is computed by normalizing its reward within the group:"
- Alignment tax: A reduction in general capabilities that can occur when a model is aligned to particular behaviors or objectives. "this specialization may partially weaken the model's general reasoning capability, a phenomenon similar to the alignment tax~\citep{ouyang2022traininglanguagemodelsfollow}."
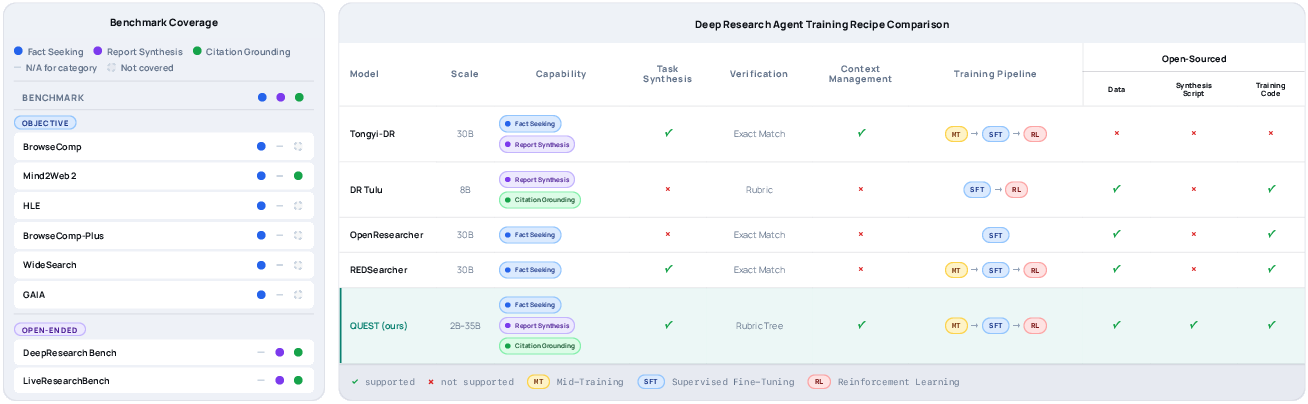
- BrowseComp: A benchmark that focuses on multi-hop web search for obscure factual questions. "fact seeking (e.g., BrowseComp), citation grounding (e.g., Mind2Web 2), and report synthesis (e.g., DeepResearch Bench)."
- BrowseComp-Plus: An extension of BrowseComp with stricter evaluation constraints, often used with specific context-handling policies. "For BrowseComp and BrowseComp-Plus, following prior work~\citep{anthropic2025claude45opus, team2026kimi,chu2026redsearcher}, we adopt the discard-all strategy for context management."
- Citation grounding: The practice of backing claims with verifiable, up-to-date sources within the response. "Another shared capability across both objective tasks and open-ended tasks is citation grounding: the agent must support its claims with reliable, up-to-date, and verifiable citations."
- Context Condenser: A model that compresses long interaction histories into a structured summary for continued reasoning. "context management is triggered once the context window usage exceeds a threshold, using a Context Condenser model cond."
- Context management: Techniques for controlling, summarizing, or resetting context to handle long-horizon interactions without overflow. "we adopt the discard-all strategy for context management."
- Context State: A structured JSON store of trusted, untrusted, and uncertain information accumulated during a trajectory. "Specifically, we use a structured JSON object, called Context State, to store the agent's history context."
- Context summarization: The process of compressing long histories into a structured state for continued use. "1) Context Summarization. Given a long history context, the model is required to produce a structured Context State JSON of the form described in Section~\ref{sec:memory}."
- Context window: The maximum token capacity of the model’s input buffer that limits how much context can be attended to at once. "As the context window fills with raw search results, visited pages, and intermediate reasoning traces, the agent's ability to attend to what matters most begins to degrade."
- Deep research agents: Autonomous systems that plan, browse, verify, and synthesize information across the web to answer complex queries. "Deep research agents~\citep{openai_dr, gemini_dr, team2025tongyi} push this paradigm further: given a complex information-seeking task, they can decompose it into intermediate goals, execute web queries, examine external sources, and synthesize citation-backed responses."
- DeepResearch Bench: An open-ended benchmark emphasizing report synthesis evaluated by multi-criteria rubrics. "Open-ended tasks require a further capability, report synthesis, as exemplified by DeepResearch Bench~\citep{du2025deepresearch}."
- Discard-all strategy: A policy that drops prior context between steps to avoid context-window overflow during evaluation. "we adopt the discard-all strategy for context management."
- Epistemic state: The agent’s internal representation of what is known, uncertain, or distrusted. "This structured state encodes the agent's epistemic state, allowing the resumed agent to distinguish between what it knows, doubts, and still needs to verify."
- Evaluation protocol: The procedure or script that maps a response to a quantitative score according to the rubric. "Given an agent's response to the query, the evaluation protocol maps the response to a score in according to the rubric tree."
- FAISS: A library for fast similarity search over dense vectors, used here for semantic cache lookups. "the query is passed to the FAISS retrieval system~\citep{johnson2019billion} for semantic similarity search"
- Fact-checking reward: A reward term that scores whether cited claims are supported by the referenced sources. "we add a fact-checking reward to encourage the agent to ground its responses in verifiable sources through its inline citations."
- Fact seeking: Locating specific factual information, often requiring multi-hop web search. "fact seeking (e.g., BrowseComp)"
- Fully asynchronous policy optimization: An RL training setup where rollout, evaluation, and updates proceed concurrently to reduce pipeline stalls. "VERL's fully asynchronous policy optimization framework~\citep{sheng2024hybridflow}"
- GAIA: A benchmark for general agent tasks; here the text-only variant is used. "GAIA~\citep{mialon2023gaia}"
- GRPO-style outcome-based reinforcement tuning: A policy optimization approach that normalizes rewards within a group of rollouts to compute advantages. "In the RL stage, we use GRPO-style outcome-based reinforcement tuning~\citep{guo2025deepseekr1}."
- Humanity's Last Exam (HLE): A benchmark assessing broad knowledge and reasoning; evaluated here in text-only mode. "Humanity's Last Exam (HLE;~\citep{phan2025humanity})"
- Inline citation format: A response style where each factual claim includes its supporting URL inline. "we standardize all outputs into an inline citation format, where each factual claim is directly annotated with the URL of its supporting source."
- KL penalty: A regularization term penalizing divergence from a reference policy during RL-based tuning. "We then optimize the policy using the standard GRPO objective~\citep{shao2024deepseekmath}, excluding the KL penalty."
- LiveResearchBench: A live, user-centric benchmark for evaluating open-ended research agent performance. "LiveResearchBench (LRB;~\citep{wang2026liveresearchbenchlivebenchmarkusercentric})."
- Mid-training (MT): An intermediate post-training stage teaching auxiliary skills like context summarization and extraction. "Quest training pipeline includes three stages: mid-training (MT), supervised fine-tuning (SFT), and reinforcement learning (RL)."
- Mind2Web 2: A benchmark emphasizing constraint satisfaction and citation-backed verification in web tasks. "Mind2Web 2~\citep{gou2025mind2web2} exemplifies this setting, as its evaluation relies on explicit constraints and citation-backed verification."
- Open-weight models: Models whose parameters are publicly available for use, analysis, and fine-tuning. "developing deep research agents using open-weight models, data, and training strategies~\citep{team2025tongyi, li2025websailor, li2026openresearcherfullyopenpipeline, shao2025drtulureinforcementlearning}."
- Pairwise normalization rule: A rule comparing candidate and reference reports to normalize rubric-based scores. "The evaluation protocol of an open-ended task consists of three components: a reference report, a rubric-based judge, and a pairwise normalization rule."
- RACE score: The reported aggregate metric for DRB results in this paper. "For DRB, we report the RACE score."
- Report synthesis: Producing coherent, structured reports by aggregating information from multiple sources. "Open-ended tasks require a further capability, report synthesis, as exemplified by DeepResearch Bench~\citep{du2025deepresearch}."
- Retrieval-augmented generation (RAG): Generating responses conditioned on documents retrieved from external sources. "retrieval-augmented generation (RAG) systems~\citep{lewis2020retrieval,gao2023retrieval} retrieve relevant documents and condition LLM responses on them."
- Rubric tree: A hierarchical decomposition of evaluation criteria that can be automatically verified and aggregated. "At the core of our synthesis pipeline is a rubric tree introduced in Mind2Web 2~\citep{gou2025mind2web2}: a hierarchical decomposition of the constraints that a valid answer should satisfy."
- Rubric-based judge: An LLM evaluator that scores candidate and reference reports under rubric criteria. "The evaluation protocol of an open-ended task consists of three components: a reference report, a rubric-based judge, and a pairwise normalization rule."
- Session-level training: Training on contiguous interaction segments between context condensation events to match inference conditions. "We provide more discussion about the advantages of session-level training in Appendix~\ref{app:session-level-training}."
- Supervised fine-tuning (SFT): Imitation learning on high-quality trajectories via next-token prediction. "Quest training pipeline includes three stages: mid-training (MT), supervised fine-tuning (SFT), and reinforcement learning (RL)."
- Trajectory: The full sequence of tool calls, observations, and model actions taken to solve a task. "we retain the generated trajectory as an SFT target for this query."
- VERL: A framework enabling fully asynchronous rollout and training for LLM RL. "Built on top of VERL's fully asynchronous policy optimization framework~\citep{sheng2024hybridflow}, which decouples rollout and training, we further extend the pipeline by making evaluation fully asynchronous."
- WideSearch: A benchmark targeting broad, agentic search tasks. "WideSearch~\citep{wong2025widesearchbenchmarkingagenticbroad}"
- Reflection-based retry strategy: A technique that uses evaluation feedback to prompt the model to attempt the task again. "we apply a reflection-based retry strategy~\citep{zhang2025ee}: the fine-grained evaluation result from the protocol is injected into the prompt as a hint, and traj\ is prompted to attempt the query again."
- Relevant Information Extraction: Extracting goal-relevant content from raw HTML while filtering noise. "2) Relevant Information Extraction. Given a raw HTML page and an extraction goal, the model is required to produce a goal-relevant summary that filters out navigation elements, advertisements, and off-topic content."
Collections
Sign up for free to add this paper to one or more collections.