- The paper demonstrates that the ability to produce harness updates is largely invariant across diverse LLM models.
- It reveals that downstream performance benefits are primarily driven by the task-solving agent’s base capability rather than the evolver’s updates.
- The study identifies peak harness-benefit in mid-tier models while exposing activation and adherence failures in weaker models.
Disentangling Harness Evolution Capabilities in LLM Agents
Problem Setting and Motivation
Self-evolving LLM agents leverage persistent, editable harness components—such as prompts, skills, memories, and tool configurations—to adapt behavior without updating model parameters. Harness evolution, driven by execution evidence, aims to upgrade agents through external artifact revision while keeping backbone weights fixed. Yet, end-to-end evaluations of agentic self-evolution conflate two distinct evolution capabilities: the ability (1) to produce useful harness updates (harness-updating), and (2) to benefit from updated harnesses in downstream task-solving (harness-benefit). This paper presents a controlled analysis to disentangle these capabilities, systematically measuring them across seven LLMs and three task benchmarks.
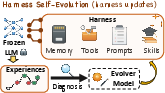
Figure 1: Overview of harness self-evolution shows the iterative update loop between task attempts, execution evidence, and harness revision.
The underlying question is whether model base capability in task-solving predicts harness evolution capabilities: which LLMs generate effective harness updates, and which maximize downstream benefit from them? This distinction is operationalized via the evolver (which proposes harness updates) and the agent (which exploits harness improvements during task-solving).
Controlled Protocol for Harness Evolution Capability Analysis
Harness evolution follows a strict protocol: at each step, the agent solves tasks using a fixed harness, collects execution evidence, and the evolver updates the harness for the next cycle. Metrics defined include:
- Base capability: agent performance using the initial harness
- Harness-updating capability: mean improvement across anchor agents due to the evolver's updates
- Harness-benefit capability: maximum gain for an agent when paired with any anchor evolver
Evaluation spans SWE-bench Verified (software engineering), MCP-Atlas (multi-server tool use), and SkillsBench (procedural, skill-based execution), with thorough in-situ pass rate measurement. Harness components are updated per benchmark constraints, and prompt templates are strictly controlled for fair comparison.
Key Empirical Findings
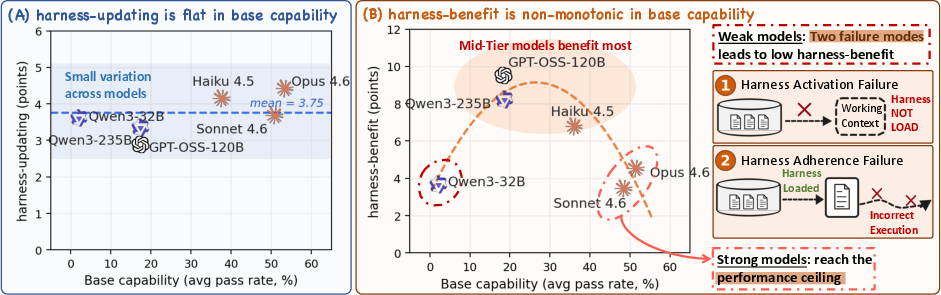
Figure 2: Overview of findings reveals flat harness-updating across base capabilities, and non-monotonic harness-benefit with maximal gains in mid-tier models.
Harness-Updating: Flat Across Capability Tiers
Experimental data demonstrate that harness-updating capability is largely invariant to the evolver's base capability. The spread between best and worst evolver is capped at approximately 3.1 percentage points on any benchmark, with no model consistently outperforming. Strikingly, Qwen3.5-9B—the smallest tested model—produces harness updates for SkillsBench yielding comparable downstream gains as those from Claude Opus 4.6, despite a substantial difference in task-solving power.
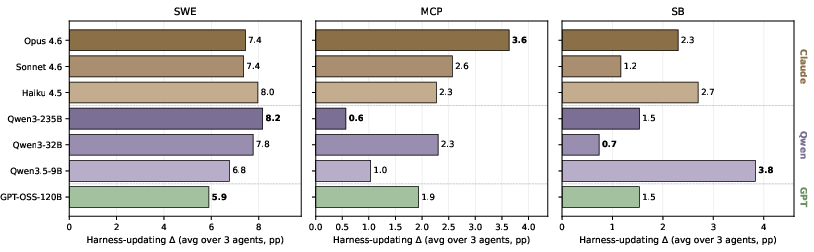
Figure 3: Harness-updating capability ($\Delta_{\text{update}$) across evolver models, showing minimal variance even between low- and high-capability LLMs.
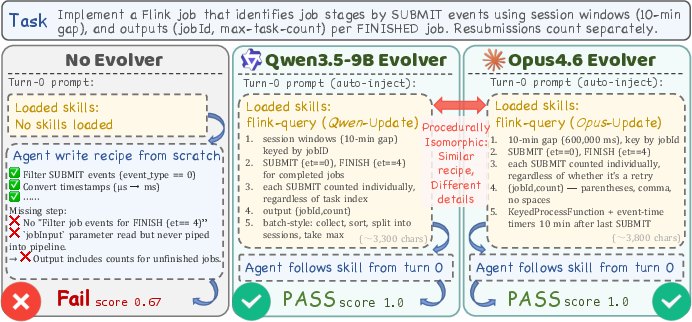
Figure 4: Skills produced by Qwen3.5-9B and Opus 4.6 are procedurally isomorphic, enabling identical downstream performance for agents.
Furthermore, downstream post-evolution scores are overwhelmingly driven by the task-solving agent's base capability, not by the identity of the evolver. Even when the weakest agent is paired with the best evolver, the strongest agent paired with the worst evolver remains superior by 18.6–35.2 percentage points.
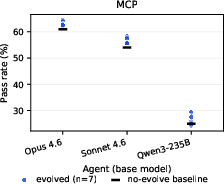
Figure 5: Post-evolution scores for MCP-Atlas anchor agents, illustrating greater between-agent variability than between-evolver variability.
Harness-Benefit: Non-Monotonic Across Capability Tiers
Harness-benefit exhibits a non-monotonic relationship with agent base capability. Mid-tier models enjoy peak gains from harness evolution, while weak-tier models benefit minimally due to (1) harness activation failure (low skill-load rates) and (2) harness adherence failure (poor instruction following, especially over long trajectories). Strong-tier models add little due to ceiling effects—their initial performance leaves little headroom.
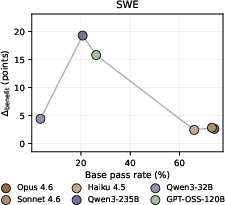
Figure 6: Harness-benefit gain ($\Delta_{\mathrm{benefit}$) versus base capability on SWE, revealing the non-monotonic pattern.

Figure 7: Two harness-benefit failure modes for Qwen3-32B: activation failure (invalid skill loading) and adherence failure (instruction protocol adherence loss).
Phase-level adherence analysis further reveals that weak-tier models suffer sharp adherence decay as task execution unfolds, with per-phase scores dropping from 0.52 (immediately after harness load) to 0.13 (final validation), while strong models maintain consistent adherence.
Practical and Theoretical Implications
The results directly inform harness self-evolution system design:
- Capability budget should preferentially be allocated to the task-solving agent, not the evolver. Scaling up the evolver yields diminishing returns, as harness-updating is not a limiting factor and agent-side base capability dominates post-evolution performance.
- Agent training must directly target harness invocation and sustained instruction following. Weak-tier models display low skill-load rates (e.g., 25.1% for Qwen3-32B vs. ≈96% for frontier models) and rapid adherence decay, underscoring the need for reliable harness activation and persistent procedural adherence over long-horizon tasks.
These findings demarcate the boundaries of model-driven evolution in modular agent systems, showing that external harness optimization is not simply a function of backbone scale or base capability.
Future Directions
Harness self-evolution, as formalized, is orthogonal to parametric fine-tuning or hybrid adaptation approaches. Extending the analysis to concurrent parameter and harness updates, richer model grids (with more families and scales), and alternative task domains would further illuminate the evolution dynamics. Harness invocation and protocol-level instruction adherence emerge as key targets for downstream agent training, with implications for robust, modular, and scalable LLM-based agent systems.
Conclusion
This paper rigorously disentangles harness-updating and harness-benefit capabilities in LLM self-evolving agents and demonstrates that the ability to produce harness updates is flat across base capability, while the benefit from updated harnesses peaks in mid-tier models and is limited by activation and adherence failures in weak agents. Harness self-evolution metrics are thus dominated by downstream agent capability, motivating future agent-centric training paradigms and protocol adherence evaluation (2605.30621).

