- The paper introduces a joint evolution framework that co-adapts the external harness and internal policy for LLM agents based on failure diagnosis.
- It employs iterative harness tailoring and harness-conditioned policy alignment to optimize interface compatibility, yielding significant performance gains.
- Experimental results demonstrate efficiency improvements of up to 12% and highlight that paired component adaptations are key for robust agent performance.
HarnessForge: A Framework for Harness–Policy Co-evolution in Adaptive LLM Agents
Introduction
HarnessForge presents a meta-adaptive agent-evolution framework that explicitly couples the external harness and the internal policy as the basic optimization unit for LLM agents. Instead of independently adapting hand-designed agent harnesses or model policies, the framework instantiates an iterative co-evolution process in which a meta-agent tailors harness structure based on failure diagnosis and concurrently aligns the underlying policy to the evolving execution interface. This approach is motivated by the structural heterogeneity of agentic tasks, including multi-hop tool use, retrieval, web interaction, and API execution, which preclude fixed scaffolds as optimal solutions and necessitate regime-specific adaptation at both the interface and execution levels.
The core innovation is formulating LLM agent adaptation as joint evolution over harness–policy pairs, with an explicit separation between the harness (decomposed into planning, action, and memory modules) and the harness-conditioned policy (a lightweight adapter on a frozen backbone). Fault diagnostics and trajectory evidence drive targeted harness edits, while paired adapter training generates policies that reliably operate under the evolving interfaces, optimizing compatibility rather than isolated component strength.
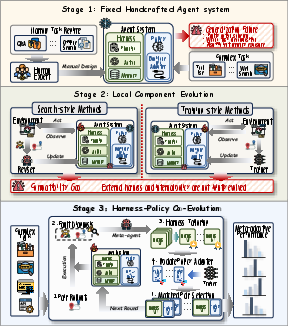
Figure 1: A three-stage paradigm for LLM agent adaptation: fixed systems, local component adaptation, and joint harness–policy co-evolution as in HarnessForge.
Methodology
HarnessForge operationalizes agent adaptation as rounds of fault-guided harness tailoring and subsequent harness-conditioned policy alignment. Each agent system is represented as a tuple (H,Rδ), where the harness H specifies the external interface (planning P, action A, memory M) and Rδ is a policy adapted to this structure. Each co-evolution round consists of three main stages:
- Fault-Guided Harness Tailoring: A meta-agent analyzes failures from rollout trajectories, localizes deficiencies to planning, action, or memory modules, and produces improvement briefs leveraging an archive of historical harnesses. Candidate harnesses are generated via structured edits and subjected to multi-criteria filtering (performance, efficiency) using staged Pareto selection.
- Harness-Conditioned Policy Alignment: For each survivor harness, a child policy is instantiated from the parent lineage and trained (typically via SFT on successful trajectories) to optimize behavior under the new interface, ensuring executable compatibility specific to the harness.
- Population Evolution and Archive Update: The survivor harness-policy pairs constitute the next generation population. All diagnostic, improvement, and selection artifacts are archived for traceable, reproducible evolution.
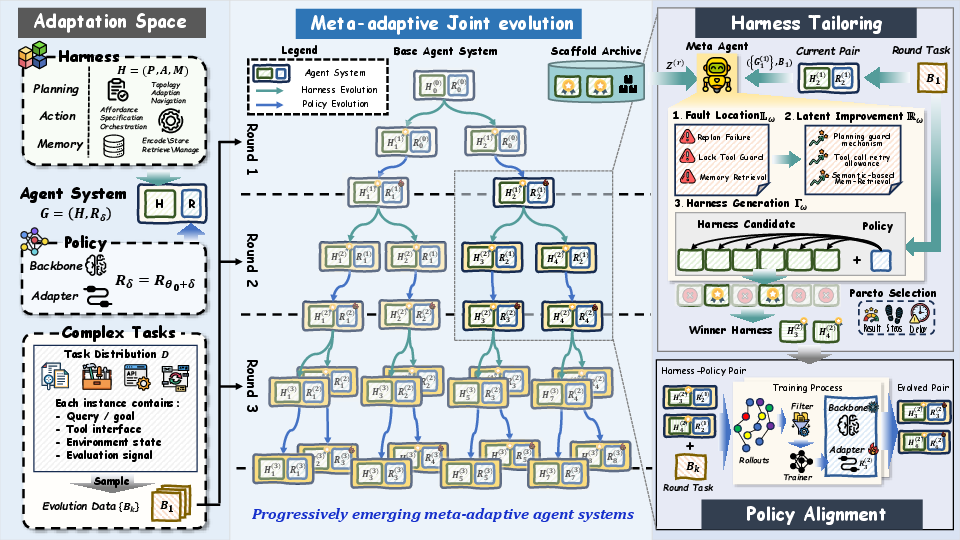
Figure 2: The HarnessForge co-evolution workflow: fault diagnosis, harness tailoring, harness-conditioned policy updating, and selection loop.
Critically, HarnessForge decouples structural harness adaptation from policy optimization and enforces population-level diversity through survivor pool maintenance, preventing convergence onto a single (potentially sub-optimal) system. All adaptations are bounded by executable interface constraints, ensuring real system deployability.
Experimental Results
HarnessForge is evaluated on a suite of agentic benchmarks—ToolHop, SearchQA, RestBench-TMDB, and API-Bank—covering both tool-augmented and knowledge-retrieval settings. Tests use Qwen3-4B and Qwen3-8B backbones, comparing against leading harness-search methods (ADAS, AFlow, AgentSquare, MaAS, MermaidFlow) and policy-training baselines (SFT, GRPO, RLOO).
The framework consistently yields the highest or near-highest scores across domains, with average gains of +3.56% over the strongest baseline and up to +12.0% improvement (TMDB, Qwen3-4B). Notably, HarnessForge is more rollout-efficient: it achieves these gains with fewer required trajectories compared to RL-style baselines that require extensive on-policy sampling.
Modular Contribution and Ablation
Ablations demonstrate that both the harness-editing and the harness-conditioned adapter training are necessary. Removing harness tailoring yields larger performance drops compared to disabling policy adaptation, and these gaps widen across evolution rounds, indicating that co-evolution (rather than isolated component optimization) is the key lever for performance.
Analysis of survivor pool size reveals that a non-trivial pool (k=2 survivors/round by default) increases both harness diversity and final task scores, whereas excessive retention dilutes selection pressure without meaningful additional benefit.
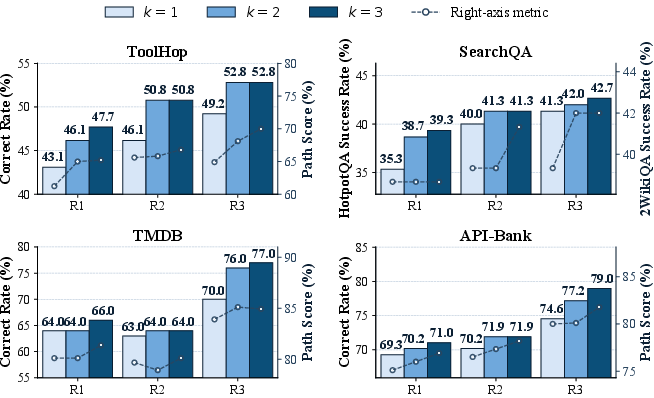
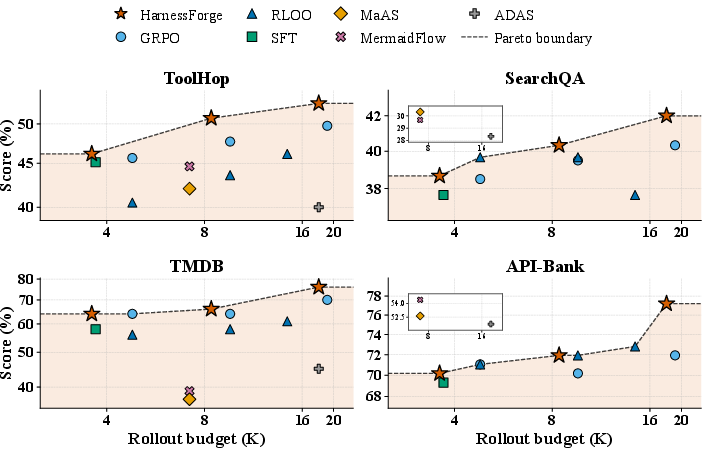
Figure 3: Sensitivity of retained harness pool size on final performance across benchmarks.
Compatibility and Specialization Analysis
Compatibility matrix analysis on API-Bank and ToolHop shows that matched harness–policy pairs always outperform cross-paired combinations: pairing an evolved harness with a non-aligned policy, or vice versa, incurs marked drops in task success rates (≥6% gaps). These findings support the hypothesis that harness-conditioned adaptation imparts specialized procedural competence not transferable to mismatched pairings, indicating that co-evolution genuinely produces system-level adaptation and not mere component improvement.
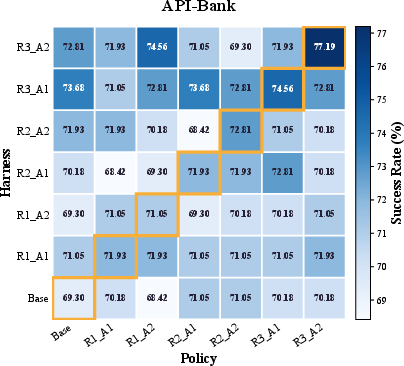
Figure 4: Compatibility matrices for harness–policy pairs (API-Bank): only matched pairs yield maximal performance.
Case Studies
Case studies reveal that HarnessForge repairs are not ad hoc answer patches but systematic module-level interface improvements. For instance, in tool-chain settings, child harnesses introduce evidence slotting or rewire multi-hop verification. In retrieval-heavy QA, query formulation is made contextually precise, and API-controlled environments benefit from improved action and endpoint orchestration. These repairs generalize beyond the triggering instance due to their structural, module-level scope.
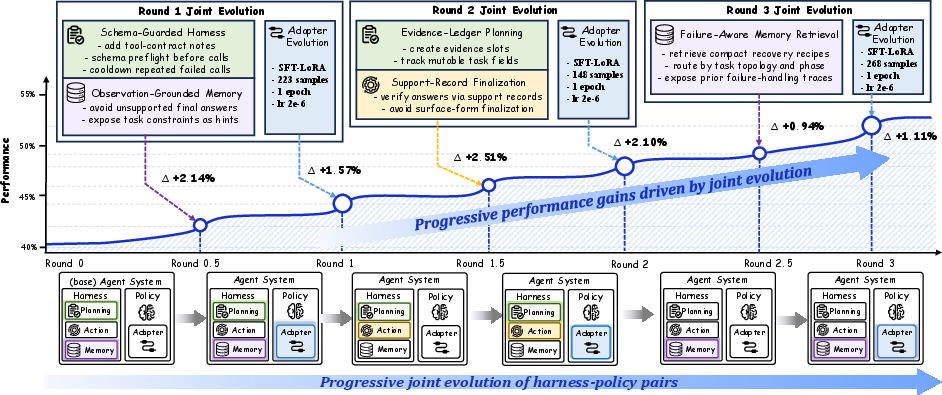
Figure 5: Representative ToolHop lineage: progression shows harness improvements (task decomposition, memory usage, planning reliability) followed by aligned policy adaptation at each round.
Practical and Theoretical Implications
HarnessForge extends the boundaries of LLM agent adaptation in several key ways:
- It demonstrates that regime-specific adaptation of LLM agents is possible through meta-level joint harness-policy optimization, directly targeting the interface–executor compatibility gap.
- Co-evolution is shown to be budget-efficient, as the system reuses rollouts for both harness evaluation and paired policy training.
- The methodology is training-objective-agnostic on the policy side: while SFT yields a favorable performance–budget tradeoff, RL-style and preference-based objectives bring additional upside at greater cost.
- The use of population-level harness diversity enables the discovery of robust, transferable procedural mechanisms, supporting future extensions to broader operator spaces and open-ended code-level harness search.
The limitations are also clear: current experiments center on resource-constrained models; transfer to frontier-scale LLMs or arbitrary harness edit spaces remains future work. Long horizon tasks induce significant rollout costs, which might be mitigated by proxy evaluators or adaptive rollout curtailment.
Conclusion
HarnessForge reframes agent-system adaptation as the co-evolution of harness–policy pairs. The framework systematically localizes failure, archives and reuses adaptation trajectories, and aligns execution via harness-conditioned policy updating. Empirical results across heterogeneous benchmarks validate the effectiveness and efficiency of this paradigm, establishing harness–policy compatibility—not isolated component upgrades—as the critical driver of adaptive agentic systems.
Future work should extend towards code-level harness search, meta-agent audits, framing adaptation for large-scale, open-ended task distributions, and exploring fully automated closed/open-source meta-agents. The framework's population-based, auditable evolution protocol makes it well-suited as a foundation for such investigations.

