- The paper presents a harness architecture that externalizes state to offload routine tasks, enabling RL policies to focus solely on high-level semantic decisions.
- Experimental results demonstrate substantial recall gains and improved transfer performance across diverse benchmarks, validating the approach.
- Ablation studies confirm the critical role of components like evidence graphs, deduplication, and budget tracking in maintaining efficient stateful retrieval.
Reinforcement Learning for Search Agents via State-Externalizing Harnesses: Harness-1
Introduction
Harness-1 addresses the central limitation in agentic retrieval: conventional retrieval agent training entangles semantic decision-making (what and how to search, what to curate, what to verify) with context bookkeeping and state management. Most prior RL formulations overburden the policy with reconstructing the search state from raw growing transcripts, significantly impeding trainability and generalization. Harness-1 introduces a stateful harness that externalizes the working memory, offloading routine bookkeeping (candidate pools, curation, evidence graphs, verification records, deduplication, budget-tracking) into the environment and exposing only the semantic decisions to the policy. The approach leverages a 20B search subagent trained via RL over this interface.
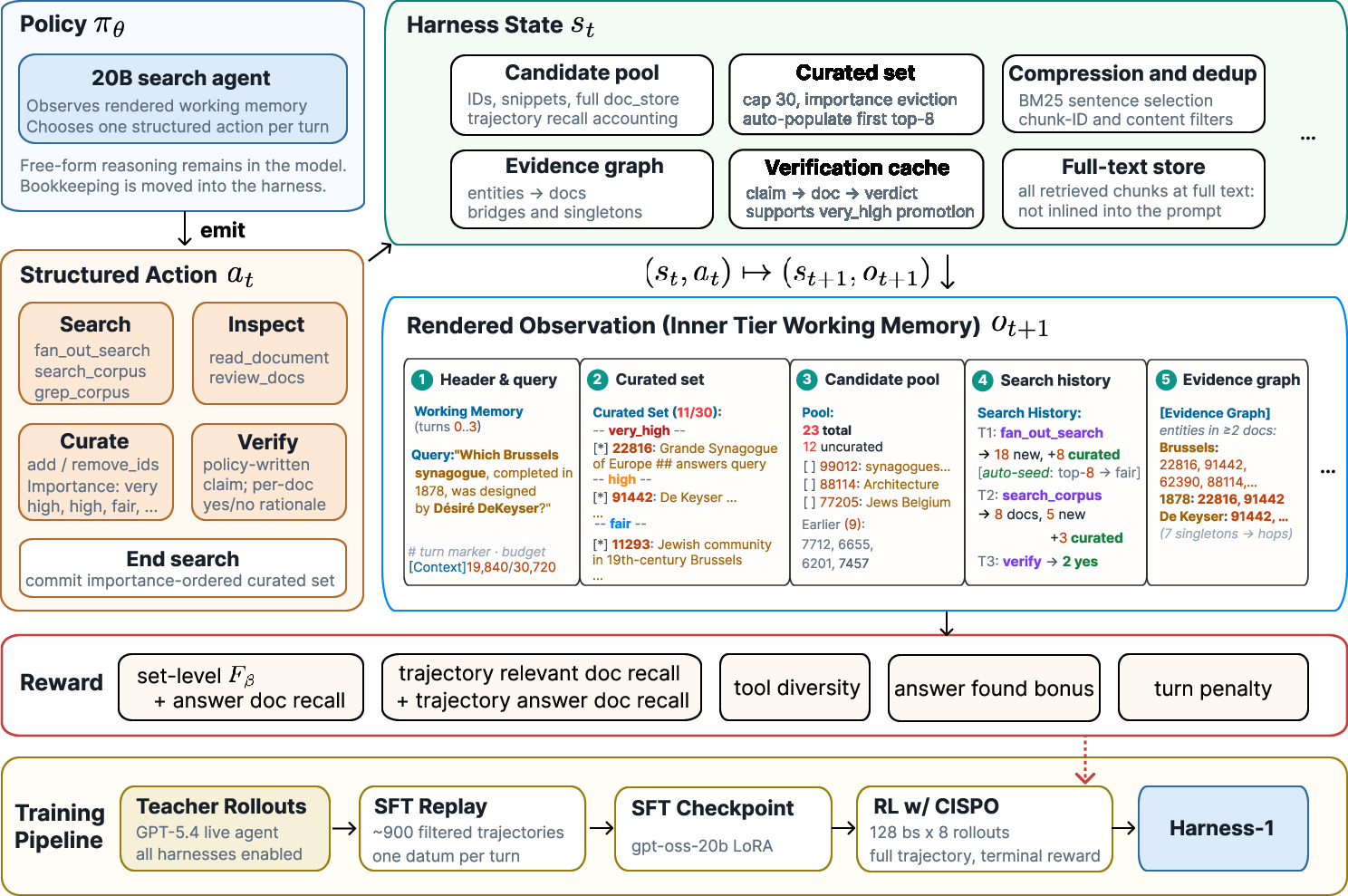
Figure 1: The policy acts over semantic decisions, and the harness externalizes state for search, curation, evidence graphs, verification, deduplication, and budget management.
Harness-1 Architecture and Cognitive Offloading
The core contribution of Harness-1 is the explicit separation between policy and harness responsibilities. The harness manages a structured working memory with the following elements: compressed/deduplicated candidate pools, an editable curated set with importance tags, an evidence entity graph, verification records, a full-text memory store, search history, and budget markers. The agent's action space is restricted to high-level semantic edits: searching, curation (with multi-level importance tagging), verification (with claims checked via an external verifier), and termination.
This division of labor implements a principle of cognitive offloading, enabling the policy to reason and act over a stable, compact state representation, while the environment handles context maintenance and information preservation. The evidence graph summarizes cross-document structure, enabling bridge reasoning steps (critical for multi-hop QA and transfer) without requiring the policy to re-read long transcripts. Result summaries, auto-seeding on first successful search, and budget-aware rendering further ensure early reward signal and efficient exploration.
Training Procedure and RL Compatibility
Harness-1 is trained in two stages: SFT on curated trajectories generated by a strong teacher (GPT-5.4) within the harness, and on-policy RL (CISPO) on SEC-family benchmarks with reward shaping for search coverage, answer evidence selection, tool usage diversity, and compactness. Reward is only terminal, combining recall and final-answer coverage, answer-miss penalties, tool diversity bonuses, and turn penalties. This decoupled scheme makes RL tractable: SFT imparts interface discipline; RL optimizes search/curation strategy over explicit state.
Ablation studies demonstrate that removing harness components (evidence graphs, importance tags, compression, verification, auto-seeding) produces sharp drops in curated recall and final-answer recall, with the trained policy regressing to shallow, search-heavy behaviors. With all harness mechanisms disabled, recall drops by 12.2% relative, confirming that the learning dynamics are fundamentally altered by the harness architecture.
Experimental Results
Harness-1 is evaluated on eight diverse retrieval benchmarks (web, finance, patents, multi-hop QA), comparing against a suite of open and proprietary competitive agents. It achieves the highest average curated recall (0.730) among open agents, outperforming the next-strongest open subagent by +11.4 points, and remains competitive with much larger frontier retrievers (e.g., Opus-4.6, Sonnet-4.6, GPT-5.4).
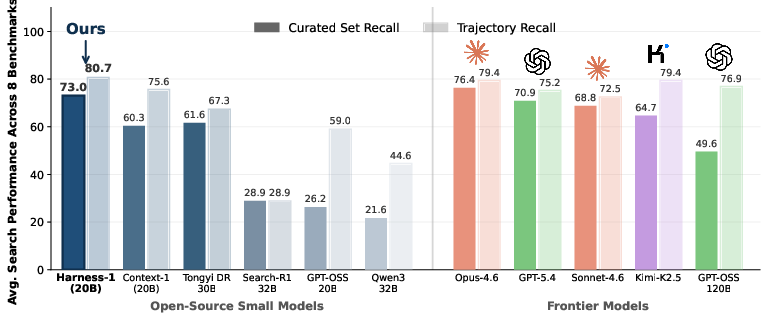
Figure 2: Averaged retrieval performance across eight benchmarks; Harness-1 achieves substantial recall gains over open peers and approaches frontier-agent performance at smaller model scale.
The most salient result is the stronger gain on held-out transfer benchmarks (+17.0 points mean over the next-best open subagent) relative to in-domain tasks (+7.9 points), indicating that the policy is not memorizing domain heuristics but is instead acquiring transferable operations over explicit search state. This is direct evidence for the harness-induced generalization mechanism. This transfer pattern is not attributable to data scale, as Harness-1 uses less SFT/RL data than some baselines.
Component ablations at inference time show that stateful mechanisms are not merely architectural optimizations: their removal collapses learning to undirected search and degrades answer-bearing recall and curation. Notably, content-fingerprint deduplication, while designed for token budget efficiency, slightly lowers recall in some benchmarks with near-duplicate qrels—demonstrating the precision of the harness-policy interface tradeoffs.
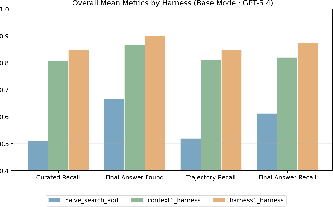
Figure 3: Richer harness designs monotonically improve retrieval metrics, with a +4 point recall gain observed on inducing Harness-1’s stateful harness atop the same LLM (GPT-5.4).
Downstream Answer Accuracy and RAG Modularity
When Harness-1’s curated sets are passed to frozen frontier generators (GPT-5.4, Sonnet-4.6, Opus-4.6, Kimi-K2.5) in a modular RAG pipeline, answer accuracy improves correspondingly (Figure 4). Because generators are blind to search trajectory details, any variation in answer quality originates solely from the curated evidence set. This confirms that harness-driven retrieval improvements translate directly to system-level downstream metrics—even in generator-agnostic settings.
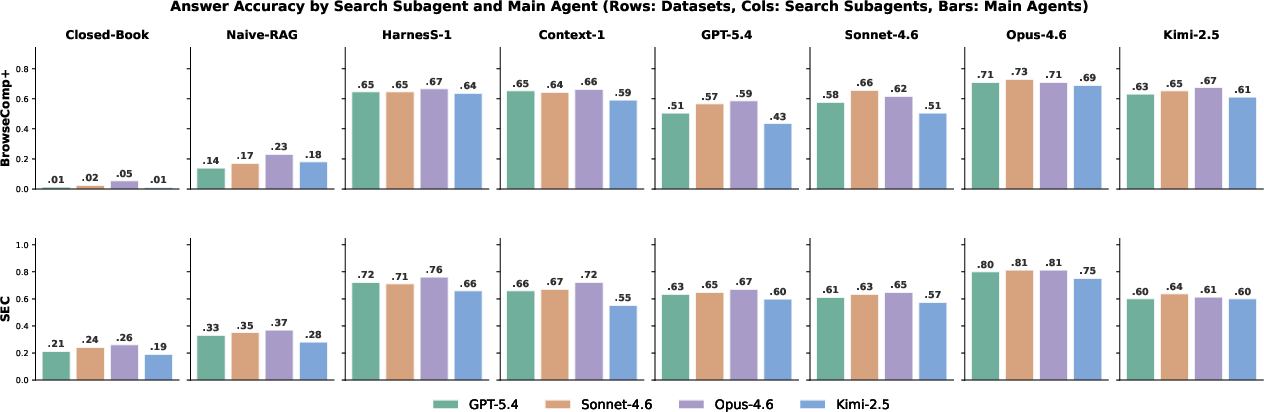
Figure 4: Modular RAG answer accuracy tracks curated recall, demonstrating that better harness-aided retrieval directly improves downstream extracting-answer performance across generators and benchmarks.
Analysis, Practical Implications, and Future Directions
Harness-1’s results reinforce the thesis that careful division of labor between semantic RL policy and environment-side state maintenance is essential for scalable agentic retrieval. The harness architecture yields policies that are more robust, data-efficient, and cross-domain transferable—even at smaller model scales—mitigating the context-dependency and sparsity issues that plague transcript-based RL. The evidence graph, importance-tagged curation, deduplication, and budget shaping mechanisms make explicit what was previously latent, simplifying both policy learning and interpretability.
Practically, Harness-1 demonstrates that environment-side harness engineering can unlock substantial performance and transfer gains for open-domain retrieval agents, without scaling model or data requirements aggressively. The harness design also facilitates modular RAG deployment, improves auditability, and offers architectural transparency for integrating retrieval agents into downstream pipelines.
For future work, the authors outline replacing the regex-based evidence graph with more sophisticated learned/structured entity and relation linking, integrating uncertainty-aware state propagation, and further automating harness engineering (potentially using meta-optimization frameworks or automated harness synthesis). More generally, this work positions stateful harnesses—and their principled engineering—as a core research direction for RL-based agent architectures.
Conclusion
Harness-1 establishes the importance of state-externalizing harnesses for RL-based search agent training. By offloading routine bookkeeping to an environment-side harness and confining the policy to semantic decisions over explicit state, Harness-1 achieves leading open-agent retrieval performance and superior transferability. Its architectural choices and empirical results highlight the necessity of harness engineering in scalable and generalizable retrieval agents—both as an enabler of RL trainability and as a modulator of downstream system behavior.