- The paper demonstrates that retrieval corpus completeness is the critical factor, achieving 2–6 EM point gains compared to protocol variations.
- It finds that simple outcome-based rewards often outperform complex step-wise credit assignment methods, emphasizing model and environment synergy.
- The study underlines that proper training protocols—balancing data diversity, off-policy drift, and search budget—are essential for robust search agent performance.
Controlled Empirical Analysis of Search Agent Training: Retrieval, Reward, and Protocol
Introduction
The paper "Retrieval, Reward, and Training Protocols: What Matters in Training Search Agents?" (2605.27881) presents a systematic empirical investigation of core factors shaping the training efficacy of LLM-based search agents. Unlike prior works proposing new training algorithms or architectural tricks, this study aims to isolate and quantify the relative importance of the retrieval environment, reward/credit assignment, and practical protocol configurations such as data diversity and batch management. The analysis addresses the confounded landscape created by diverging experimental setups, corpus choices, and evaluation procedures in recent literature.
Retrieval Corpus Impact
The study identifies corpus completeness as the dominant variable governing search agent performance. The commonly used Wikipedia 2018 (Wiki-18) corpus is shown to be critically incomplete for multi-hop QA training: over 295k relevant documents are missing, rendering 37% of sample questions unanswerable via retrieval. This deficiency introduces noise, as models can guess correct answers from parametric memory without successful retrieval, contaminating reward signals and optimization trajectories. Training and evaluating with the augmented Wiki-fixed corpus (containing all required support documents) yields 2–6 EM point gains, exceeding the delta between varied training algorithms. Method rankings even invert across corpora, highlighting that corpus errors can mask or misrepresent baseline and improvement claims.
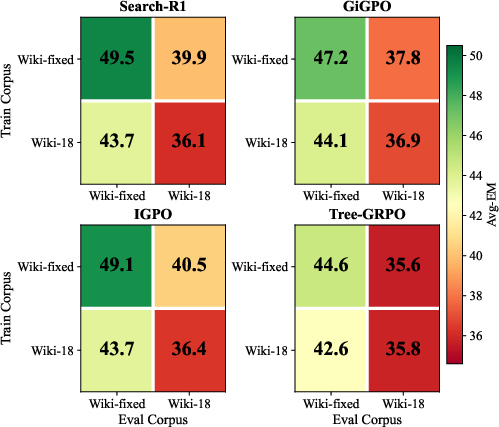
Figure 1: Corpus completeness critically boosts average Exact Match (EM) scores across benchmarks; training/evaluation on Wiki-fixed yields stronger scores than Wiki-18.
The conclusion is unequivocal: ensuring all training questions are answerable given the retrieval corpus is a fundamental prerequisite for robust policy optimization and fair algorithmic comparison.
Reward Design and Credit Assignment
The paper systematically benchmarks three step-level (process-based) credit assignment algorithms—GiGPO, IGPO, Tree-GRPO—and a trajectory-level (outcome-based) baseline, Search-R1. The outcome-based approach uses simple EM reward computed only at the conclusion of trajectories. Process-based variants attempt nuanced step-wise or structural reward assignments, exploiting grouped state similarity, information gain, and tree expansion for finer credit.
Empirical results, spanning three base models and two tool-call formats, reveal that the simplest outcome-level supervision achieves competitive or superior final EM in most configurations. Process-level methods do not robustly outperform this baseline and sometimes introduce overfitting biases to search patterns. Notably, GiGPO performs well and achieves the best result in one setting, while IGPO’s efficacy is highly contingent upon the underlying base model's reasoning and instruction-following strength.
Analysis of intermediate search behavior (average number of tool-call turns, query recall, and overlap) demonstrates that credit assignment strategies directly shape search trajectory characteristics. IGPO encourages deeper, more redundant search; GiGPO boosts per-query recall but suppresses exploration; Search-R1 and Tree-GRPO occupy intermediate modalities. However, nontrivial recall reductions and increased query redundancy are observed for trained agents relative to their untrained counterparts under several process-based methods, contradicting the assumption that step-wise heuristic reward always improves search quality.
Training Protocol: Data, Off-Policy, and Search Budget
Data Diversity
Scaling up unique data instances from repeated epochs over small sets mainly benefits training stability, not final performance. Checkpoint selection within early training stages is vital, as overtraining often leads to performance collapse regardless of data regime.
Off-Policy Degree
Increasing train batch size relative to mini-batch exacerbates off-policy drift, particularly for more powerful base models, leading to noticeable performance degradation. Keeping batches fresh and modest in size is essential for maintaining signal relevance and improvement consistency.
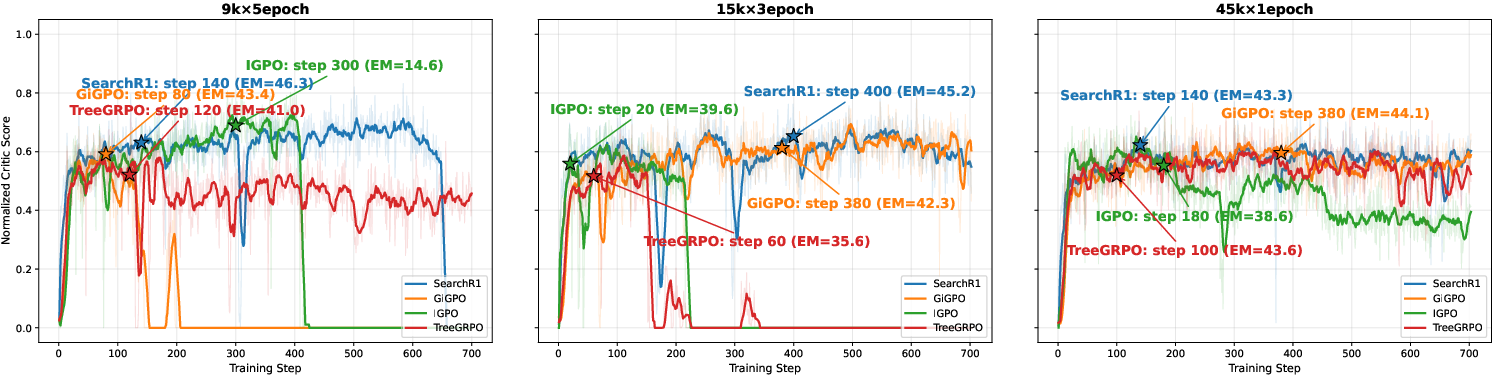
Figure 2: Training curves reveal that early checkpoint selection is key; larger unique data sets stabilize learning, but do not substantially increase final EM.
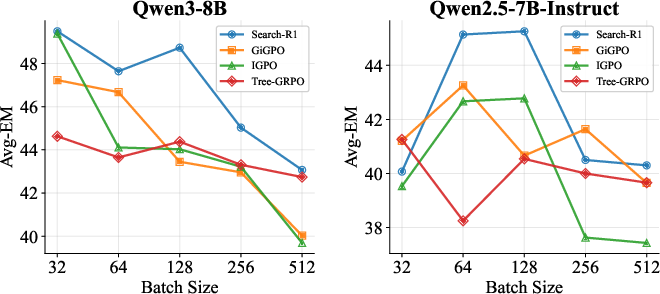
Figure 3: Larger train batch sizes reduce final EM for powerful models; off-policy drift undermines performance.
Search Budget
Scaling the maximum search turns during training/inference does not yield proportional gains and often damages performance, exhibiting a ceiling effect. Methods dependent on budget exhibit sensitivity to evaluation limits (notably Search-R1 and IGPO), while methods with shallow search trajectories (e.g., GiGPO) are less affected. The complexity limitation of conventional multi-hop QA benchmarks restricts analysis of long-horizon search behavior.
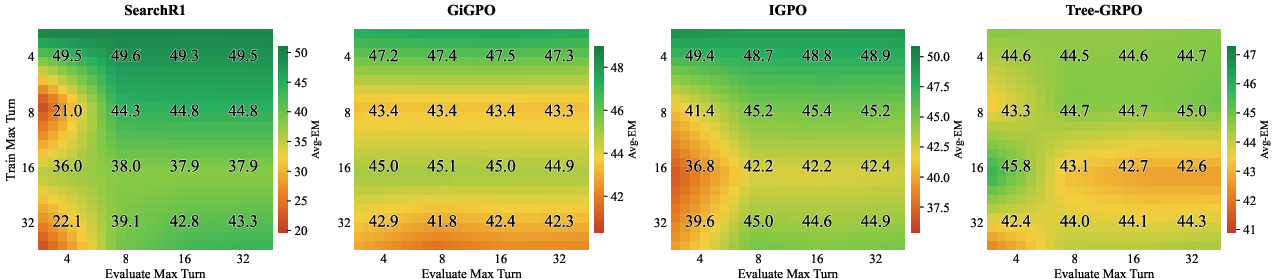
Figure 4: Search budget scaling confirms a ceiling effect; increasing turns beyond practical dataset complexity does not enhance EM.
Practical and Theoretical Implications
The results redefine the priorities of search agent research. Retrieval environment completeness—rather than training algorithm sophistication—should be the first concern when evaluating, benchmarking, or deploying search agents. Credit assignment innovations only yield their intended effects when confounding factors are controlled. Practically, the paper's guidelines simplify hyperparameter selection (data diversity, batch size, search budget) and enable cleaner algorithmic evaluation. Theoretically, the study underscores the need for harder, longer-horizon benchmarks and cautions against attributing improvements to algorithmic changes without parallel scrutiny of training setups and environment configuration.
Future Outlook
Progress in search agent research should focus on (1) standardized, fully annotated retrieval corpora, (2) benchmark suites with greater complexity demanding deep search capabilities, and (3) methodologically rigorous credit assignment evaluation under controlled conditions. The presented Wiki-fixed corpus and empirical guidelines serve as reference points for future methodological advances.
Conclusion
This paper decisively demonstrates that retrieval corpus completeness and protocol rigor are more critical than algorithmic complexity in search agent training. Outcome-based reward remains competitive against step-wise heuristics unless the latter are specifically tuned and supported by robust base models and environments. The analysis provides actionable guidelines, promotes reproducibility, and advocates for methodological standardization, laying groundwork for future advances in agentic search systems.