How to Train Your Deep Research Agent? Prompt, Reward, and Policy Optimization in Search-R1
Abstract: Deep Research agents tackle knowledge-intensive tasks through multi-round retrieval and decision-oriented generation. While reinforcement learning (RL) has been shown to improve performance in this paradigm, its contributions remain underexplored. To fully understand the role of RL, we conduct a systematic study along three decoupled dimensions: prompt template, reward function, and policy optimization. Our study reveals that: 1) the Fast Thinking template yields greater stability and better performance than the Slow Thinking template used in prior work; 2) the F1-based reward underperforms the EM due to training collapse driven by answer avoidance; this can be mitigated by incorporating action-level penalties, ultimately surpassing EM; 3) REINFORCE outperforms PPO while requiring fewer search actions, whereas GRPO shows the poorest stability among policy optimization methods. Building on these insights, we then introduce Search-R1++, a strong baseline that improves the performance of Search-R1 from 0.403 to 0.442 (Qwen2.5-7B) and 0.289 to 0.331 (Qwen2.5-3B). We hope that our findings can pave the way for more principled and reliable RL training strategies in Deep Research systems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how to better train “Deep Research” AI agents—systems that answer hard questions by repeatedly searching the web, reading results, and then deciding what to do next. The authors test how different training choices affect three things: how accurate the agent’s answers are, how stable the training is (no weird breakdowns), and how much effort it takes (how many searches it makes).
What questions were the researchers asking?
The team focused on three simple but important questions:
- Prompts: What kind of instructions should we give the AI—short and direct, or step-by-step with lots of thinking notes?
- Rewards: How should we “grade” the AI’s answers so it learns the right habits?
- Training rules: Which training algorithm helps the AI learn best and most efficiently?
How did they study it?
Think of the agent like a student doing a scavenger hunt online:
- Prompts are the instructions the student sees. The team compared:
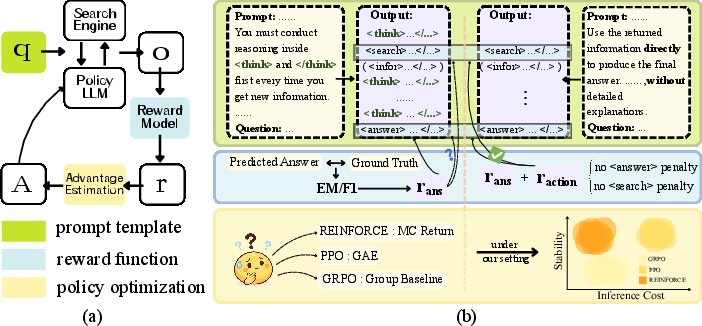
- Fast Thinking: brief, direct instructions—search when needed, then answer.
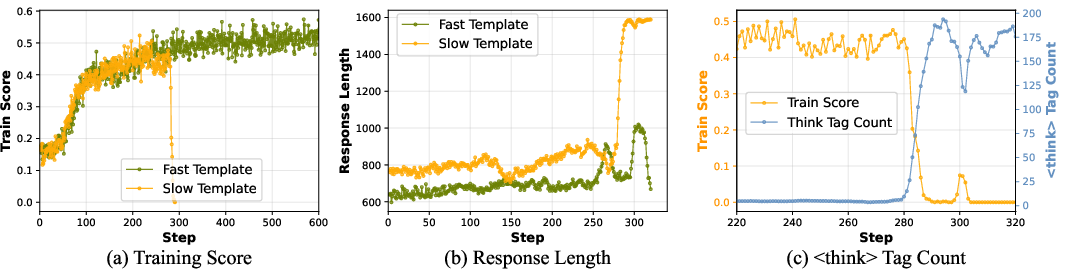
- Slow Thinking: instructions that force the student to “think out loud” between every step with special > tags. > > - Rewards are how the student gets points: > - EM (Exact Match): full points only if the answer matches exactly. > - F1: partial credit for being close (like getting the right words, even if not perfect). > - F1+: like F1, but with small penalties if the student never searches or never answers (to discourage avoidance). > > - Training rules are the coaching styles: > - REINFORCE: a simple, older coaching method. > - PPO: a more complex, popular coaching method. > - GRPO: a method that compares a group of attempts. > > They kept the tasks, data, and search tools the same and measured: > > - Accuracy (how often answers were right), > > - Stability (whether training stayed on track or broke down), > > - Cost (how many searches the agent used per question). > > They tried this with two sizes of the same model (a “7B” larger one and a “3B” smaller one) on several well-known question-answering datasets. > > ## What did they find? > > ### 1) Prompts: Shorter, more direct instructions worked better > > - The Fast Thinking prompt (short, direct: search when needed, then answer) led to more stable training and better accuracy than Slow Thinking (which forces the model to write many <think> notes). > > - Why? With Slow Thinking, the model started spamming <think>… tags (like writing “I’m thinking… I’m thinking…” over and over) instead of making decisions. This “overthinking” grew out of control and caused training to collapse.
- Bottom line: Less forced “thinking text” led to better learning and more reliable behavior.
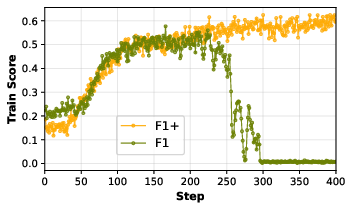
2) Rewards: F1 alone caused “answer avoidance,” but F1 with small penalties (F1+) was best
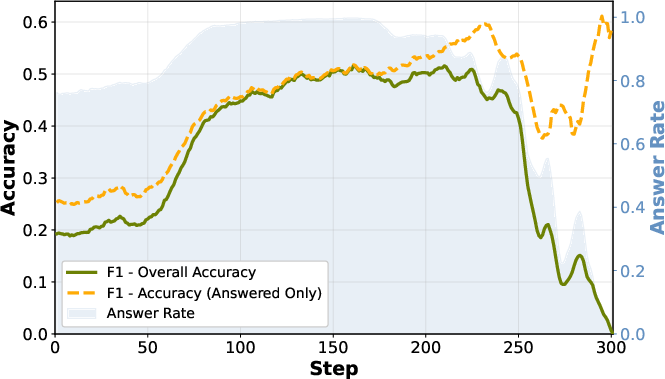
- Training with F1 (partial credit) was surprisingly unstable and often worse than EM (exact match). The model learned a bad habit: it avoided giving answers at all, because a blank or safe response didn’t get punished more than a wrong answer.
- The fix: F1+ adds tiny penalties when the model never searches or never answers. This stopped the avoidance behavior and made training stable again.
- With F1+, performance beat both plain F1 and EM. So the best grading scheme was “partial credit” plus small penalties for not trying.
3) Training rules: REINFORCE was the most effective and efficient
- REINFORCE (the simple method) gave the best overall accuracy and used fewer searches per question.
- PPO did okay but tended to use a lot of searches even when not needed (it didn’t adapt well to easy questions).
- GRPO was the least stable (more likely to break during training).
- In short: the simplest coaching method performed best and was more efficient.
An improved system: Search-R1++
Using all three insights together (Fast Thinking + REINFORCE + F1+), the authors built a stronger agent called Search-R1++. It clearly beat the previous baseline (Search-R1):
- On the larger model, average accuracy went from about 40% to 44%.
- On the smaller model, from about 29% to 33%.
Why does this matter?
- More reliable research agents: The study shows how to avoid common training failures (like endless “thinking” or refusing to answer).
- Better use of computing: Using fewer searches means faster, cheaper systems.
- Practical guidance: It’s not always about fancier methods—clear prompts, well-designed rewards, and a simple training rule can outperform more complex setups.
- Future impact: These guidelines can help build AI agents that are better at gathering evidence, making decisions, and answering questions in the real world—useful for tasks like homework help, fact-checking, and research assistance.
Key takeaways for a 14-year-old
- Don’t force the AI to “think out loud” too much; it can get stuck overthinking.
- Give partial credit, but make sure the AI doesn’t get away with not trying.
- A simple coaching method (REINFORCE) was the best teacher here.
- Putting these together made a smarter, steadier, and more efficient research agent.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Upon reviewing the research paper, several areas were identified where further investigation could enhance understanding and improve upon the current findings:
- Knowledge Gaps:
- The paper primarily evaluates the Fast Thinking and Slow Thinking templates but does not investigate how these templates interact with different data types or task categories, such as creative writing or programming tasks, unlike those focused on here.
- Limited exploration on the impact of model size on the effectiveness of the Fast Thinking versus Slow Thinking templates; further research could explore this in the context of varied model architectures.
- Limitations:
- The study is restricted to select datasets and does not address the generalizability of the findings across other diverse datasets, especially those that include non-English languages or domain-specific knowledge.
- The reward functions evaluated (EM vs F1) lack a side-by-side comparison with other potential reward metrics like BLEU, Rouge, or human judgment that might capture more nuanced aspects of language generation quality.
- The computational cost and time efficiency analysis of different policy optimization methods is not addressed, which could be pivotal for practical applications in resource-constrained settings.
- Open Questions:
- How do the identified strategies for stabilizing training and improving accuracy scale with even larger model sizes or when applied to models with fundamentally different architectures (e.g., multimodal models)?
- What are the implications of these findings on real-world applications, such as in chatbot development, where user interaction and feedback might present more variable and less deterministic input conditions?
- Could there be auxiliary techniques or modifications in hyperparameters that might mitigate the observed training collapse without redesigning the prompt templates or reward functions?
Evaluating these unexplored aspects may provide a deeper understanding and more robust solutions in the domain of reinforcement learning for Deep Research agents.
Glossary
- Action-level penalties: Small negative rewards applied when the agent omits key actions (e.g., search or answer) to discourage avoidance behaviors. "this can be mitigated by incorporating action-level penalties, ultimately surpassing EM;"
- Advantage estimation: Computing how much better an action is compared to a baseline, used in policy gradient methods to reduce variance. "PPO depends on a learned critic for advantage estimation."
- Answer avoidance: A failure mode where the policy learns to withhold final answers rather than risk incorrect ones. "training collapse driven by answer avoidance"
- Baseline (policy gradient): A reference value used to reduce variance in gradient estimates; if noisy, it destabilizes training. "makes the baseline noisy, leading to training instability."
- Critic (learned critic): A value model estimating expected returns, used by actor-critic methods like PPO. "PPO depends on a learned critic for advantage estimation."
- Deep Research agents: Systems that solve knowledge-intensive tasks via iterative retrieval, evidence aggregation, and decision-oriented generation. "Deep Research agents tackle knowledge-intensive tasks through multi-round retrieval and decision-oriented generation."
- E5 (retriever): A text embedding model used to retrieve relevant passages for question answering. "Retrieval uses E5 on 2018 Wikipedia, retrieving top-3 relevant passages."
- Exact Match (EM): An evaluation and training reward that gives credit only for answers that exactly match the ground truth. "current Deep Research systems have shifted from Exact Match (EM) rewards"
- F1 score: The harmonic mean of precision and recall over tokens, used as an outcome-based reward and evaluation metric. "to near-standard reliance on F1 scores"
- F1+ reward: An augmented F1-based reward that adds penalties for skipping search or answer actions to stabilize training. "F1+ denotes F1 reward augmented with penalties."
- Fast Thinking template: A prompt design that encourages direct search and answer decisions without lengthy explicit reasoning. "the Fast Thinking template yields greater stability and better performance than the Slow Thinking template used in prior work;"
- GRPO: An RL algorithm that uses group-relative advantages; observed to be less stable in this setting. "GRPO shows the poorest stability among policy optimization methods."
- Group averaging (GRPO): Averaging returns within a sampled group to form a baseline for advantage calculation. "with GRPO employing group averaging."
- Long-horizon interactive behaviors: Extended sequences of decisions and interactions requiring planning over many steps. "optimizes long-horizon interactive behaviors under sparse feedback"
- Open-domain QA: Question answering where answers may come from any external source, typically requiring retrieval. "open-domain QA and long-document summarization"
- Pearson correlation: A statistic measuring linear correlation between two variables. "we compute the Pearson correlation between the number of > tags and the immediate reward"
Policy optimization: The process of updating a policy’s parameters to maximize expected reward. "prompt template, reward function, and policy optimization."
- PPO (Proximal Policy Optimization): An on-policy RL algorithm using a clipped objective and a learned critic. "REINFORCE outperforms PPO while requiring fewer search actions"
- ReAct: A training-free agent paradigm that interleaves reasoning and acting via structured prompts. "ReAct, a training-free agent using the identical inference pipeline as ours for direct inference."
- REINFORCE: A Monte Carlo policy gradient algorithm that optimizes directly from returns without a learned critic. "REINFORCE outperforms PPO while requiring fewer search actions"
- Reinforcement learning (RL): Learning by interacting with an environment to maximize cumulative reward. "While reinforcement learning (RL) has been shown to improve performance in this paradigm"
- Reward hacking: Exploiting the reward function to achieve high scores without performing the intended behavior. "While explicitly forcing actions carries a theoretical risk of reward hacking"
- Search-R1: A representative RL-driven Deep Research baseline architecture used for controlled comparisons. "Search-R1~\citep{jin2025search} serves as a representative baseline for RL-driven Deep Research."
- Search-R1++: An improved baseline using the Fast Thinking template and REINFORCE with F1+ rewards. "we then introduce Search-R1++, a strong baseline that improves the performance of Search-R1"
- SFT (Supervised Fine-Tuning): Training that imitates labeled or rule-generated trajectories, relying on dense expert signals. "dense expert search trajectories that SFT depends on"
- Slow Thinking template: A prompt design that mandates explicit reasoning segments (think tags) before each action. "the Slow Thinking template used in prior work"
- Sparse feedback: Infrequent or delayed reward signals that make credit assignment harder. "under sparse feedback"
- Sparse reward structures: Tasks/environments where rewards are rare, complicating value estimation and exploration. "Under the sparse reward structures typical of PPO"
- Think tags (<think>): Special prompt markers indicating explicit reasoning blocks in the agent’s output. "dedicated <think> tags guiding model reasoning"
- Training collapse: Degenerate training dynamics where performance suddenly drops due to learned pathological behaviors. "training collapse driven by answer avoidance"
- Value function: The expected cumulative return from a state (or state-action), used for critic estimation. "fitting an accurate value function over long trajectories is challenging."
Practical Applications
Based on the paper, "How to Train Your Deep Research Agent? Prompt, Reward, and Policy Optimization in Search-R1," here is an analysis of its practical, real-world applications derived from its findings, methods, and innovations:
Immediate Applications
- Industry (Software Development)
- Workflow Optimization: The insights regarding prompt templates and reward functions can immediately inform the development of efficient AI-driven research agents in software design workflows. Leveraging the Fast Thinking template could enhance stability and performance in decision-making tasks, optimizing internal R&D processes.
- Education
- AI Tutoring Systems: Applying the Fast Thinking template and optimized reward functions to AI tutoring systems can improve the adaptability and efficiency of educational software used for personalized learning experiences.
- Energy Sector
- Data Retrieval and Analysis: The multi-round retrieval methods can be applied in energy management systems for efficient data analysis and decision-making. This can optimize resource allocations and predict energy consumption patterns with improved speed and accuracy.
Long-Term Applications
- Academia
- Research Automation: Continued exploration of the REINFORCE algorithm and F1+ reward structure could automate and improve research data aggregation and analysis, enhancing academic research efforts across various disciplines through AI-augmented literature reviews.
- Public Policy
- Policy Analysis Tools: Developing sophisticated AI agents based on this research could aid in complex policy analysis by interacting with multi-source data to provide comprehensive insights, though it requires significant scaling and adaptation to specific policy domains.
- Finance
- Automated Financial Advising: With further refinement, the methodologies discussed could contribute to creating AI-driven financial advising systems that offer more accurate and customized financial plans through efficient data retrieval and decision-making algorithms.
Assumptions and Dependencies
- The successful implementation of these applications depends on the availability of robust computational infrastructure capable of supporting advanced AI models.
- Adoption in sectors like finance and policy will require addressing ethical, data privacy, and regulatory compliance issues.
- The effectiveness of the reward augmentation approach (F1+) might vary across different domains and needs comprehensive empirical validation.
By categorizing the applications into immediate and long-term, it is clear which areas can benefit directly from the current state of research and which require further development and scaling.
Collections
Sign up for free to add this paper to one or more collections.