Towards Retrieving Interaction Spaces for Agentic Search
Abstract: Retrieval for search agents is still inherited from non-agentic information retrieval: a retriever ranks the corpus and the agent reads a small set of returned documents. Recent direct corpus interaction (DCI) work shows that agents can instead interact with the raw corpus through shell tools such as grep and file reads. But unbounded interaction does not scale: every broad shell command is a scan over the whole corpus, and latency degrades sharply as the corpus grows. We argue that the role of retrieval for agentic search is not just to select documents that fit in the LLM context window, but to construct an interaction space: a bounded subset of the corpus the agent can explore with associated tools. Two design consequences follow. The space needs a boundary supplied by retrieval, and the objects within it should be processed for interaction. As a proof of concept, we propose RISE (Retrieving Interaction SpacE): we use BM25 to construct the interaction space; meanwhile, its documents are processed during indexing for shell-style navigation. On BrowseComp-Plus, RISE matches the pure-shell DCI baseline at 78% accuracy with gpt-5.4-mini at roughly one quarter of the per-query cost. At 1M documents, RISE-BM25 reaches 81% on gpt-5.4-mini, whereas DCI on gpt-5.4-nano degrades to 60% with 33 of 100 wall-clock failures.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI search agents to work smarter with huge collections of text. Instead of giving the AI either:
- a tiny handful of snippets to read, or
- unlimited, slow access to the entire library,
the authors propose a middle ground called an interaction space. Think of it like giving the AI a fenced-off part of a giant library—big enough to explore, but small enough to search quickly—and stocking it with tools that make it easy to jump to the right parts of documents.
What questions did the researchers ask?
In simple terms, they asked:
- How should an AI’s “search” step work when the AI is an active agent that explores, checks, and reasons over many pieces of information?
- Can we make a fast, affordable system that still lets the AI explore, without scanning the entire corpus every time?
- If we build a bounded workspace for the AI, and prepare documents so they’re easier to navigate, will the agent get better answers faster and more reliably?
How did they do it?
They built a system called RISE (Retrieving Interaction SpacE). Here’s the approach using everyday analogies:
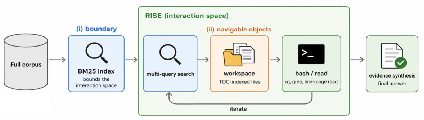
- Building a fenced playground (the interaction space):
- The AI first runs a keyword search (BM25; think of it like a strong, classic search engine) to pick out a set of likely relevant documents from the whole library.
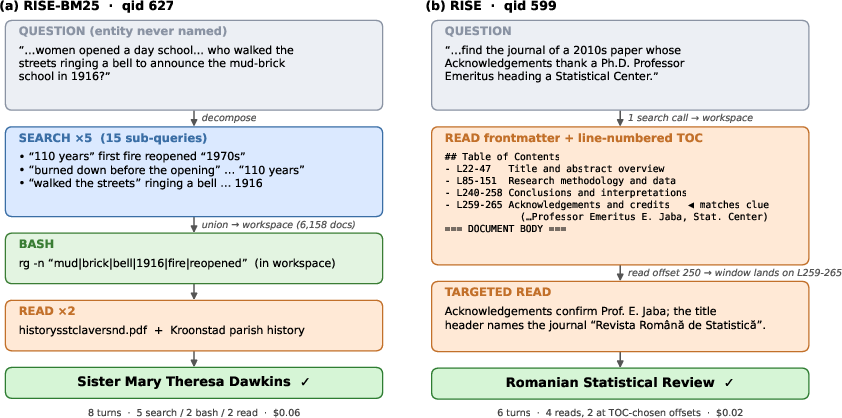
- Those documents are copied into a per-question workspace—a shared folder the AI can freely explore with simple tools (like ‘grep’ to search inside files, or ‘cat’ to read lines). The key idea: the AI can revisit and re-search this folder as much as it wants without touching the massive outside library.
- Making the “toys” easier to use (navigable documents):
- The team preprocesses each document once to add a line-numbered table of contents (TOC). Imagine every book now has a detailed, clickable chapter list with page ranges so the agent can jump straight to the section it needs, instead of reading the whole thing.
- Importantly, the original text stays intact for exact quoting and checking, so the AI can verify facts.
- Two versions for testing:
- RISE: has both the bounded workspace and the enhanced documents with TOCs.
- RISE-BM25: only the bounded workspace (no TOCs), to test how much the document processing helps.
They tested on a tough benchmark called BrowseComp-Plus: challenging questions where the AI must search a fixed collection (so every method is compared fairly) and then be judged on answer correctness.
What did they find?
Here are the main takeaways and why they matter:
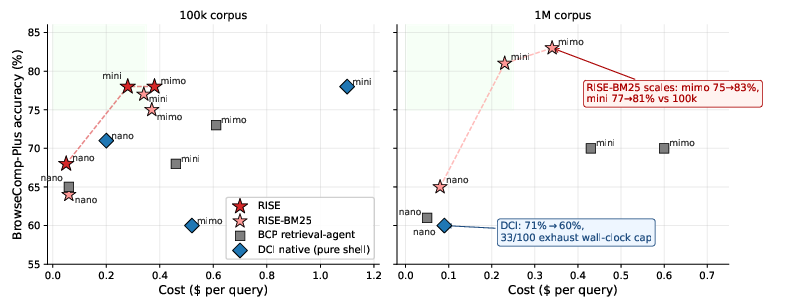
- RISE matched the accuracy of a powerful “search the entire library with shell tools” baseline but at about one-quarter the cost.
- With a small, capable model (gpt-5.4-mini), both RISE and the full-corpus baseline hit 78% accuracy.
- But RISE cost roughly $0.28 per question versus about$1.10 for the full-corpus approach. That’s much cheaper for similar quality.
- RISE stays stable as the library gets 10× bigger; the full-corpus approach breaks down.
- With 1 million documents, the RISE-BM25 setup (just the bounded workspace) stayed strong (around 81% for the mini model).
- The “search everything” baseline dropped to about 60% and hit many timeouts. Why? Because broad commands over the whole library become painfully slow as the collection grows.
- Preprocessing documents helps, but the boundary matters most.
- Adding the TOC (RISE vs. RISE-BM25) gives a small but consistent boost (about 1–4 percentage points at the tested scale).
- The biggest win comes from creating the bounded workspace in the first place. It keeps exploration focused and fast.
- The agent can still explore and verify.
- Unlike snippet-only systems (which only feed small slices into the AI’s prompt), the interaction space lets the agent browse, search within files, and jump to exact sections—keeping exploration flexible while controlling cost and time.
Why does this matter?
- Smarter search for AI agents: The paper shows that retrieval shouldn’t just hand over a few snippets. It should build a right-sized “play area” where the agent can think, test ideas, and verify facts.
- Scales to big libraries: By bounding where the agent explores and making documents easier to navigate, the system stays fast and accurate even as the corpus grows huge.
- Practical and affordable: Similar accuracy at a fraction of the cost means this design is more usable in real applications—like research assistants, enterprise search, or education tools—where time and money matter.
Simple limitations and what’s next
- They used one classic search method (BM25) and one kind of document processing (a line-numbered TOC). Other search models and other ways to structure documents (like section graphs or paragraph anchors) could make things even better.
- The TOC processing was only applied at the smaller scale (100k documents), not the full 1 million, mainly due to preprocessing cost.
- Tests were on one tough benchmark and 100 questions, so the exact numbers may shift elsewhere. The overall message—build an interaction space—should still hold.
Bottom line
Giving an AI a well-chosen, bounded workspace to explore—and preparing documents so it can jump straight to the right parts—beats both tiny-snippet feeding and full-library scanning. RISE shows this middle path can be accurate, fast, and cost-effective, pointing the way to better search agents that think and verify like real researchers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of unresolved issues that future work could address.
- Definition and metrics for “interaction space quality”: no formal criteria or task-agnostic metrics exist to evaluate whether a bounded workspace is “good” (e.g., recall@workspace, navigability, redundancy, sub-document hit rate, evidence path length, or decision latency per verified fact).
- Adaptive boundary construction: is fixed per sub-query; there is no policy to adapt over time based on uncertainty, residual information need, or diminishing returns, nor to allocate unevenly across sub-queries.
- Pruning and maintenance of the workspace: the workspace grows monotonically with no eviction, deduplication, or clustering; policies for pruning low-yield files, merging near-duplicates, or compressing stale areas are unexplored.
- Retriever choice and hybridization: only BM25 is used; the effects of dense, late-interaction, or hybrid retrievers on workspace recall, size, and tool-call efficiency remain untested.
- In-workspace re-ranking: after import, there is no learned (or lexical) re-ranking of workspace files to prioritize inspection; the impact of lightweight intra-workspace re-ranking or prioritization queues is unknown.
- Query planning and decomposition: how to train or guide the agent to generate sub-queries that maximize workspace utility (coverage vs. redundancy) is not studied; no analysis of failure cases in query decomposition.
- Cross-turn boundary refinement: the system lacks mechanisms for using inspection feedback (e.g., “noisy grep results”) to refine subsequent retrieval calls or adjust the workspace boundary dynamically.
- On-demand vs. offline document processing: TOCs are created offline; the trade-offs and policies for on-demand TOC generation (e.g., after initial evidence suggests a file is promising) are not evaluated.
- Alternate metadata schemes: only line-numbered TOCs are tested; comparative studies of section graphs, paragraph anchors, learned jump-pointers, or symbolic indices (e.g., per-entity offsets) are missing.
- TOC quality and robustness: there is no quantitative assessment of TOC anchor precision/recall, coverage of salient sections, anchor drift on noisy HTML/PDF, or the downstream impact of TOC errors on navigation and accuracy.
- Multi-format documents: handling of PDFs, HTML with complex DOM, code repos, tables, and figures is unaddressed; how structure extraction differs by format and its effect on shell navigation is open.
- Evidence fidelity vs. compression: the paper argues against summarization but does not explore non-destructive compression (e.g., skip indices, byte/line offset indexes, or per-section inverted lists) that preserve verbatim verification while accelerating jumps.
- Caching and memoization: repeated bash/rg queries across turns or across queries are not cached; strategies for per-workspace or global result caching, or reuse of prior interaction spaces for similar queries, are unexplored.
- Latency breakdown and systems profiling: beyond wall-clock caps, there is no detailed decomposition of time spent in retrieval, I/O, shell processing, and model calls, nor sensitivity to storage (SSD vs. HDD) or filesystem layout.
- Scaling beyond 1M and distributed setups: behavior on 10M+ documents, remote/object stores, and distributed or sharded workspaces (with federated shell operations) is unknown.
- Hardware dependence of baselines: DCI may degrade due to I/O; experiments on faster disks/servers or with specialized search backends (e.g., ripgrep with prebuilt indices) are missing, leaving baseline comparisons partially confounded by hardware.
- Equalized budget comparisons: DCI is evaluated with larger budgets but still hits caps; results under matched turn and wall-clock budgets (and vice versa) are not reported, limiting causal attribution.
- 1M-corpus comparisons for larger models: DCI at 1M is run only for nano; the absence of mimo/mini DCI results at 1M leaves scaling conclusions incomplete across model tiers.
- Workspace-local indexing: there is no attempt to build a lightweight per-workspace index (lexical or vector) to support fast sub-document retrieval without full scans; the accuracy–latency trade-off of such local indices is unknown.
- Tool interface breadth: only bash/rg and line-range read are available; the potential of richer tools (e.g., HTML DOM navigation, citation resolvers, table extractors, PDF text locators) to improve efficiency is untested.
- Agent training to use the interface: agents are not trained (e.g., RL or supervised finetuning) to optimize workspace shaping or TOC usage; whether training improves tool allocation, sub-query planning, or verification behavior is unknown.
- Usage analytics of TOCs: there is no aggregate measurement of how often agents consult TOCs, jump via anchors, or avoid full-file reads; correlations between TOC usage and answer quality/cost are absent.
- Safety and sandboxing: executing shell tools on corpora raises security risks; sandboxing policies, path sanitization, and defenses against prompt-injected commands are not discussed.
- Domain, language, and modality generalization: evaluations are limited to BrowseComp-Plus (English, browsing-style); performance on scientific corpora, code, multilingual documents, or multimodal sources is untested.
- Factuality and hallucination control: the claim that verbatim grounding aids verification is plausible but unmeasured; no metrics on citation correctness, evidence consistency, or hallucination reduction are reported.
- Coverage diagnostics comparability: gold_R and cov_mean are not comparable across architectures; a standardized, interface-agnostic evidence coverage metric is missing.
- Statistical power and variance: only 100 queries are used; confidence intervals, bootstrap variance, and significance testing for the observed gains are not provided.
- Hyperparameter sensitivity: effects of preview size, output truncation thresholds, read length limits, subprocess timeouts, and tool-call caps on accuracy, cost, and failure modes are not systematically ablated.
- Economic modeling of preprocessing: the trade-off between one-time TOC costs and per-query savings is not analyzed; break-even analyses across corpus sizes, query volumes, and cloud pricing are needed.
- Incremental corpus updates: how to maintain TOCs and workspace indices under frequent corpus changes (adds/deletes/edits) is unaddressed; policies for invalidation and refresh are open.
- Workspace semantics beyond filesystems: alternative representations (graph-of-documents, key–value stores, columnar stores) for interaction spaces and their tool ecosystems are not explored.
- Cross-document reasoning aids: support for linking entities across files (e.g., entity indexes, citation graphs) to reduce grep-based triage is missing.
- Reproducibility of LLM-generated structure: the offline TOC generation uses an LLM; the sensitivity to sampling temperature, seeds, and model drift over time (and its impact on anchors) is not reported.
- Benchmarking for interaction spaces: current benchmarks assume snippet-based retrieval; a dedicated benchmark (tasks + metrics) to assess interaction-space construction, navigation, and verification efficiency is needed.
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s core idea—retrieval as a constructor of an interaction space—together with its concrete instantiation, RISE (BM25-bounded workspace plus document-level in-place metadata for shell-style navigation). Each item notes the sector, what could be built, how it would work operationally, and key dependencies or assumptions.
Immediate Applications
- Enterprise knowledge-base assistants (software, IT, support)
- What: Deploy agentic assistants that investigate tickets, SOPs, and internal docs by building a per-query “workspace” and navigating it with shell tools rather than over-injecting snippets.
- How: Use
BM25to import top-K documents per sub-query into a workspace; augment documents with line-numberedTOCanchors; inspect viarg/grep,read(line ranges), andcat. Integrate with internal search portals or service desks (e.g., Jira, ServiceNow). - Why RISE helps: Evidence-grounded answers with reduced latency/cost vs unbounded DCI; scalable to 1M+ docs without degrading latency significantly.
- Assumptions/dependencies: Unix-like shell environment or equivalent; decent lexical recall on internal corpora; offline TOC processing (~$0.0014/doc at 100k scale) and storage of structured counterparts.
- Developer codebase exploration assistants (software engineering)
- What: Agent tools for refactor planning, API usage discovery, and incident retrospectives that traverse code and docs inside a bounded workspace.
- How: Treat repositories (code + docs) as the corpus;
BM25on filenames, function names, and comments; per-query workspace populated viasearch(...); code files pre-processed with section anchors (e.g., class/function headers) for fast targeted reads. - Why RISE helps: Avoids repo-scale grep scans; keeps exploration local and re-traversable, improving cost and responsiveness.
- Assumptions/dependencies: Robust tokenization of code symbols; reliable anchor generation for code (could use ctags or LSP data instead of LLMs).
- Legal e-discovery triage and audit prep (legal, compliance)
- What: Triage large document sets (emails, contracts, memos) for initial relevance screening and evidence gathering with verifiable citations.
- How: Use
BM25to bound candidate sets per hypothesis; navigate with TOC anchors (sections, clauses, exhibits) to pull line-ranged evidence; produce provenance-rich briefs. - Why RISE helps: Verbatim-grounded, revisitable evidence without overwhelming LLM context windows.
- Assumptions/dependencies: Quality OCR for scanned PDFs; robust anchor generation for contracts (e.g., clause detection models); on-prem deployment for confidentiality.
- Scientific literature review copilots (academia/biomedical)
- What: Assist researchers in multi-hop literature reviews and systematic evidence checks across large corpora (preprints, PDFs).
- How: Import high-recall candidate sets via multiple sub-queries; jump to method/results sections using TOC anchors; verify facts with targeted
readoperations and collect precise citations. - Why RISE helps: Maintains verifiable, targeted reads that scale better than full-document ingestion in context; matches DCI accuracy at lower cost.
- Assumptions/dependencies: PDF-to-text fidelity; domain-specific sectioning (e.g., IMRaD); IR indexing for biomedical terms (lexical BM25 is competitive for keywordy queries).
- Customer support knowledge search (customer experience)
- What: Guided troubleshooting that navigates solution articles and logs within a bounded workspace to surface precise fixes.
- How: Multi-query
BM25over KBs + logs; use TOC anchors to land in “Troubleshooting” or “Known Issues” sections; executergwithin the workspace for error codes. - Why RISE helps: Localizes shell scans to relevant files; reduces hallucinations by verifying exact error messages/steps.
- Assumptions/dependencies: Logs text availability; latency budgets for shell calls; privacy controls for sensitive logs.
- Internal policy and compliance navigator (enterprise governance)
- What: Assist teams in mapping internal policies against external regulations (e.g., SOC2, HIPAA) with pinpointed cross-references.
- How: Create a workspace of candidate policies/regulations; anchor headings/sections; issue targeted reads to compare scope, definitions, and controls.
- Why RISE helps: Structured navigation reduces document-scale reads; outputs verifiable side-by-side evidence.
- Assumptions/dependencies: Accurate section anchors for legal/regulatory text; periodic re-indexing for updates.
- Editorial research and fact checking (media)
- What: Rapid verification of facts across archives while preserving quotations and provenance.
- How: High-recall imports across archives; use TOC anchors to jump to quotes or attributions; compile line-ranged evidence for editorial notes.
- Why RISE helps: Ensures grounded citations; avoids slow full-archive scans.
- Assumptions/dependencies: Archive indexing; OCR for historical scans; newsroom workflows for provenance capture.
- On-device personal knowledge management (daily life, privacy)
- What: Local agent to explore personal documents (notes, PDFs, emails) with verifiable snippets and fast navigation.
- How: Build per-query workspace from indexed personal files; pre-process with lightweight TOC anchors (or rule-based headers); navigate via local
rg/grepwithout cloud calls. - Why RISE helps: Efficient, privacy-preserving search with clear evidence windows and minimal context injection.
- Assumptions/dependencies: Adequate local indexing and storage; OS-specific shell tooling (Windows PowerShell/
findstralternatives).
- Product requirements and bug triage assistant (product/engineering)
- What: Correlate feature requests, design docs, and bug reports to accelerate root-cause analysis and scope decisions.
- How: Multi-query
BM25imports across tickets/specs; navigate to “Known Issues”/“Workarounds” anchors; verify stack traces or error strings with targeted reads. - Why RISE helps: Reduces tool-call budgets and triage latency compared with unbounded shell scans across monorepos + docs.
- Assumptions/dependencies: Good lexical signals in tickets; de-duplication in workspaces to keep shell ops fast.
- FOIA/public records research assistants (government/policy)
- What: Help analysts navigate large document dumps with auditable evidence.
- How: Build bounded workspaces for each query/topic; process docs with anchors for headings/dates/entities; extract line-ranged evidence with provenance.
- Why RISE helps: Traceable, re-explorable workspaces that scale better than snippet-only or full-corpus approaches.
- Assumptions/dependencies: Heterogeneous formats require robust pre-processing; transparent logging for chain-of-custody.
- Domain-specific RAG enhancement (“Workspace-RAG”) (software tooling)
- What: Augment existing RAG systems to return a re-explorable workspace (outside the context) rather than only snippets.
- How: Introduce a
search(...)tool that hardlinks top-K hits; let the agent iteratebash+readwithin the workspace; maintain provenance and reduce context churn. - Why RISE helps: Better cost/accuracy trade-off and robustness at scale; simpler failure modes than unbounded DCI.
- Assumptions/dependencies: IR index availability; agent harness that exposes shell tools safely; rate limits on tool calls.
- Training data curation and quality control (ML ops)
- What: Curate and verify training examples from large corpora with precise provenance and section-level access.
- How: Use high-recall imports per concept; verify URLs/sections via anchors; automatically collect line-ranged grounding for dataset entries.
- Why RISE helps: Efficient verification loops; reduces hallucinated or mislabeled samples.
- Assumptions/dependencies: Stable pre-processing; storage for structured variants of the corpus.
Long-Term Applications
- Standards for “interaction-space” retrieval outputs (IR benchmarks, tooling)
- What: New benchmarks and APIs that define retrieval outputs as bounded, re-explorable workspaces with structured objects.
- How: Extend evaluation suites beyond ranked lists to measure workspace quality (coverage, navigability, re-traversal efficiency).
- Dependencies: Community consensus; shared formats for metadata (anchors, section graphs).
- Richer in-place metadata (section graphs, paragraph anchors, learned navigation hints)
- What: More expressive structural overlays to enable jump-to-evidence without reading entire files.
- How: Use hierarchical graphs, paragraph-level anchors, or model-learned “navigation hints” to guide shell tools.
- Dependencies: More robust, low-cost generation pipelines; evaluation of brittleness across genres and languages.
- Hybrid and learned retrievers for workspace construction (IR evolution)
- What: Replace pure
BM25with dense or hybrid retrievers tuned for agent traces (AgentIR/Agentic-R style). - How: Train retrievers on agent reasoning traces to populate higher-quality workspaces (precision/recall balance).
- Dependencies: Task-specific training data; latency constraints for candidate-set construction; memory and index management.
- What: Replace pure
- Cross-modal and heterogeneous corpora (multimedia manuals, tables, code, PDFs)
- What: Apply interaction spaces to mixed media (figures, CAD schematics, tables) with navigable anchors.
- How: Multimodal OCR/parsing; anchors for figure captions/table rows; tools to “jump” to sub-elements.
- Dependencies: Reliable multimodal parsing; new shell-like tools for non-text modalities.
- Regulated sectors research copilots (healthcare, finance, pharma)
- What: Evidence-grounded agents for clinical guidelines, pharmacovigilance, or financial compliance reviews.
- How: Workspace per inquiry with strict provenance; section-level reads on SOPs, labeling, regulatory guidance; audit logs by design.
- Dependencies: High-quality de-identification; validation against domain benchmarks; rigorous governance frameworks.
- Multi-agent collaboration on shared workspaces (collab research, ops)
- What: Teams of agents (or agent + human) co-exploring a shared interaction space with persistent state and provenance.
- How: Shared filesystem-backed workspaces; role-specific sub-queries; consensus-building on evidence.
- Dependencies: Concurrency control, versioning, and access-policy enforcement.
- Cloud-native “workspace-as-a-service” platforms (SaaS)
- What: Hosted services that manage indexing, workspace construction, and secure shell-tool access over enterprise data.
- How: Virtualized filesystems over object stores (e.g., S3); scalable
BM25/hybrid indexing; sandboxed command execution; billing per query. - Dependencies: Strong isolation for shell tools; data residency/compliance; predictable SLAs at scale.
- Edge and offline agents for constrained environments (field ops, defense, energy)
- What: Agents running on-device to navigate large manuals or logs without internet.
- How: Pre-indexed corpora with compact anchors; local
rg/grepand line-range reads; low-resource models. - Dependencies: Efficient indexing pipelines; storage/compute constraints; robust parsing of PDF/manuals.
- Curriculum and pedagogy assistants (education)
- What: Structured exploration of textbooks and readings with verifiable, section-level references for assignments.
- How: TOC-anchoring across course materials; student queries build bounded workspaces; targeted reads for citations.
- Dependencies: Licensing and formatting of content; fairness and guardrails for assessment contexts.
- Compliance-by-construction workflows (policy/enterprise governance)
- What: End-to-end pipelines where every agent assertion is tied to a reproducible line-range read within a workspace.
- How: Policy checks implemented as sequences of imports, shell inspections, and targeted reads with logs for auditors.
- Dependencies: Process certification; integration into GRC systems; continuous corpus updates and re-indexing.
- Robustness and fairness auditing for agentic systems (safety)
- What: Use workspaces to systematically probe agent behaviors and bias by controlling candidate sets and evidence presentation.
- How: Synthetic corpora with controlled anchors; analysis of navigation traces and evidence selection.
- Dependencies: Audit datasets and instrumentation; standardized metrics beyond accuracy (coverage, navigability).
Notes on feasibility and assumptions across applications:
- Retrieval quality: The paper uses
BM25deliberately; swapping or augmenting with dense/hybrid retrievers can improve recall but adds engineering complexity. - Document processing cost: TOC metadata is generated once; reported cost (~$0.0014/doc at 100k scale) is low but scales linearly with corpus size and may require batching infrastructure.
- Shell tooling: The approach assumes safe, sandboxed access to shell-like tools; environments without Unix-like shells need equivalents (e.g., PowerShell cmdlets).
- Data formats: Non-text and poorly OCR’d documents reduce anchor reliability; sector-specific parsers (PDF, code, contracts) can mitigate this.
- Security/governance: Workspaces should inherit data-permission models; all shell operations must be logged for auditability in regulated settings.
- Generalization: Results are reported on BrowseComp-Plus (100 queries); while the interface is broadly applicable, performance may vary with domain, language, and query style.
Overall, RISE’s “interaction space” reframing is immediately deployable in many enterprise and research contexts where lexical search is strong and shell tools are available, and it opens a pathway to longer-term products and standards that treat retrieval outputs as navigable workspaces rather than one-off snippets or entire corpora.
Glossary
- bash: A Unix shell and command language used here as a tool for file inspection within the agent’s workspace. "the agent uses bash (running standard utilities such as rg, grep, cat)"
- BM25: A classic lexical ranking function in information retrieval used to retrieve relevant documents based on term frequency and inverse document frequency. "we use BM25 to construct the interaction space"
- bm25s: An efficient implementation/variant of BM25 providing faster lexical search with eager sparse scoring. "Both RISE and RISE-BM25 use bm25s~\citep{lu2024bm25s} defaults ()"
- BrowseComp-Plus: A fixed-corpus benchmark for evaluating deep research/browsing agents with transparent retrieval comparisons. "On BrowseComp-Plus, RISE matches the pure-shell DCI baseline at accuracy"
- context window: The maximum span of tokens that a LLM can attend to in a single prompt, limiting how much evidence can be directly read. "select documents that fit in the LLM context window"
- Deep research agents: Agentic systems designed for multi-turn, long-horizon search and synthesis over large corpora. "AgentIR argues that deep research agents expose useful reasoning traces before search calls"
- Dense retrieval: Retrieval methods that use learned dense vector embeddings to match queries and documents in embedding space. "keyword-oriented agent queries can make strong lexical baselines competitive with dense retrieval"
- Deterministic postprocessor: A non-stochastic post-processing step that validates and inserts structure according to exact rules. "a deterministic postprocessor validates each anchor by exact substring match"
- Direct corpus interaction (DCI): An interface where agents operate over the full raw corpus using shell tools, without a prior retrieval-bound candidate set. "Direct corpus interaction (DCI)~\citep{li2026dci} gives the agent shell tools over the raw corpus filesystem"
- Evidence-coverage diagnostics: Metrics that measure whether gold/relevant documents are retrieved and actually surfaced to the agent. "We also report two evidence-coverage diagnostics: gold_R, whether gold documents appear in the BM25 candidate union, and cov_mean, whether gold documents are surfaced to the agent through reads or shell output."
- FineWeb-Edu distractors: Additional documents from the FineWeb-Edu dataset added as non-relevant items to stress-test retrieval and scaling. "adds 900,000 fixed-seed FineWeb-Edu distractors"
- filesystem-workspace variant: An interface where retrieval returns a bounded set of files that the agent navigates like a filesystem using shell tools. "RISE sits in this third class as a filesystem-workspace variant"
- gold_R: A recall-style metric indicating whether gold documents occur in the retrieved candidate set. "gold_R, whether gold documents appear in the BM25 candidate union"
- hardlinked: A filesystem operation creating an additional directory entry pointing to the same inode, used here to import retrieved files into the workspace without copying. "and the union is hardlinked into "
- hierarchical section graphs: Structured representations of document sections enabling hierarchical navigation to relevant spans. "Other forms of in-place metadata would also satisfy (ii): hierarchical section graphs, paragraph-level anchors, or learned navigation hints"
- hybrid alternatives: Retrieval approaches that combine multiple retrieval paradigms (e.g., lexical and dense). "including dense, late-interaction, or hybrid alternatives."
- idf statistics: Corpus-level inverse document frequency statistics that influence lexical retrieval scoring. "Adding 900k distractors shifts the corpus idf statistics"
- indexing-time document processing: Preprocessing applied at indexing time to add structure that facilitates efficient, targeted interaction at inference time. "the indexing-time document processing provides a smaller additional improvement."
- in-place structural metadata: Additional structural markers inserted into documents (without removing text) to enable direct jumps to sub-document spans. "but in-place structural metadata that lets shell tools jump to relevant spans without document-scale reads."
- interaction space: A bounded subset of the corpus returned by retrieval that the agent can explore with tools outside the context window. "construct an interaction space: a bounded subset of the corpus the agent can explore with associated tools."
- late-interaction: Retrieval models that defer interaction (e.g., token-level matching) to later stages for more precise re-ranking or matching. "including dense, late-interaction, or hybrid alternatives."
- lexical search: Retrieval based on exact or term-based matching signals (e.g., BM25) rather than learned embeddings. "lexical search inside an agent loop is a strong primitive"
- line-numbered table of contents (TOC): A generated, line-indexed list of document sections used to navigate directly to relevant spans. "a line-numbered table of contents (TOC) with section anchors prepended to the body text."
- line-range reads: Reads that return only a specified range of lines from a file to minimize unnecessary I/O. "line-range reads with a 2000-line default"
- LLM-as-judge: An evaluation protocol where an LLM assesses the correctness of another model’s answers. "All answers are judged with an LLM-as-judge protocol"
- OpenAI Batch API: A batching API used here to generate document structure cheaply at scale. "via the OpenAI Batch API"
- paragraph-level anchors: Markers inserted at paragraph granularity to allow direct navigation to specific paragraphs. "hierarchical section graphs, paragraph-level anchors, or learned navigation hints"
- parametric model: A model whose knowledge is stored in its parameters, as opposed to non-parametric external memory or indices. "RAG introduced the now-standard pattern of coupling a parametric model with an external retrieval index"
- RAG (Retrieval-augmented generation): A framework that augments LLM generation with external retrieval for knowledge-intensive tasks. "RAG introduced the now-standard pattern of coupling a parametric model with an external retrieval index"
- ReAct-style search agents: Agents that interleave reasoning (chain-of-thought) with actions (e.g., search) in a loop. "ReAct-style search agents"
- re-rankers: Models that take an initial set of retrieved candidates and produce a refined ranking, often with more expensive scoring. "comparing retrieval units, retrievers, re-rankers, and query transformations."
- retrieval-time chunking: Splitting documents into chunks at retrieval time to deliver only small pieces into context, potentially restricting re-exploration. "It is not retrieval-time chunking or snippet delivery"
- section anchors: Verbatim anchor strings inserted before section starts to enable targeted navigation. "with section anchors prepended to the body text."
- shell tools: Command-line utilities (e.g., grep, rg, cat) used by the agent to search and inspect files. "through shell tools such as grep and file reads."
- snippet retrieval: A retrieval paradigm that returns small text fragments for immediate context consumption, rather than navigable files. "as in snippet retrieval"
- tool-result truncation and compaction: Runtime strategies that shorten and compress tool outputs to fit constraints like token limits or latency. "which applies tool-result truncation and compaction."
- wall-clock cap: A time limit on how long an individual query/trajectory is allowed to run. "a one-hour per-query wall-clock cap"
- wall-clock failures: Failures where runs exceed the allowed real-time limit rather than model-call limits. "33 of 100 wall-clock failures."
- working directory: The per-query directory that stores the imported candidate files and serves as the agent’s navigable workspace. "a per-query working directory the agent treats as a filesystem."
- read (tool): An agent tool that returns a specified slice of a file by line numbers for verification. "and read (returning line-numbered slices of a file)"
Collections
Sign up for free to add this paper to one or more collections.